elasticsearch(三)-- 理解ES的索引操作
一、前言
上一章我们主要学习了es的几个客户端,那么我们后面也主要通过kibana客户端、HighLevelClient高级客户端这两个来学习es.
这一章的学习我们主要是学习一些Elasticsearch的基础操作,主要是深入一些概念,比如索引的具体操作,映射的相关语法,对数据类型,文档的操作。那么主要的DSL代码的实践都将在kibana客户端上实践。
二、索引操作
本节主要介绍索引的相关操作,涉及创建、删除、关闭和打开索引,以及索引别名的操作。其中,索引别名的操作在生产环境中使用比较广泛,可以和关闭或删除索引配合使用。在生产环境中使用索引时,一定要慎重操作,因为稍有不慎就会导致数据的丢失或异常。
2.1.、创建索引
使用ES构建搜索引擎的第一步是创建索引。在创建索引时,可以按照实际需求对索引进行主分片和副分片设置。ES创建索引的请求类型为PUT,其请求形式如下:
PUT /${index_name}
{
"settings": {
...
},
"mappings": {
...
}
}
其中:变量index_name就是创建的目标索引名称;可以在settings子句内部填写索引相关的设置项,如主分片个数和副分片个数等;可以在mappings子句内部填写数据组织结构,即数据映射。
在第一章中曾介绍过创建索引hotel的语句,但是当时的主分片个数使用的是系统默认值(默认值为5)并且没有使用副分片个数(默认值0)。假设设置主分片个数为15,副分片个数为2,则响应的DSL如下:
PUT /person
{
"settings": {
"number_of_shards": 15 #指定主分片个数
, "number_of_replicas": 2 #指定副分片个数
},
"mappings": {
"properties": {
"name":{
"type": "text"
},
"city":{
"type": "keyword"
},
"age":{
"type": "integer"
}
}
}
}
2.2、删除索引
ES中删除索引的请求类型是DELETE,其请求类型如下:
DELETE ${index_name}
其中,${index_name}就是将要被删除的索引的名称,例如执行下面的删除命令
DELETE /person
返回信息如下图:

通过返回信息可知,目标索引hotel已经被删除。
2.3、关闭索引
在有些场景下,某个索引暂时不使用,但是后期可能又会使用,这里的使用是指数据写入和数据搜索。这个索引在某一段时间内属于冷数据或者归档数据,这时可以使用索引的关闭功能。索引关闭时,只能通过ES的API或者监控工具看到索引的元数据信息,但是此时该索引不能写入和搜索数据,待该索引被打开后,才能写入和搜索数据。
先把索引person关闭,请求形式如下:
POST /person/_close
此时可以尝试将数据写入:
POST /person/_doc/001
{
"name":"mbw",
"city":"上海",
"age":"22"
}
ES返回信息如下:
{
"error" : {
"root_cause" : [
{
"type" : "index_closed_exception", #提示异常类型为索引已经关闭
"reason" : "closed",
"index_uuid" : "t1MKYReSRg2iU5KaXPaoOQ",
"index" : "person" #当前索引名称
}
],
"type" : "index_closed_exception",
"reason" : "closed",
"index_uuid" : "t1MKYReSRg2iU5KaXPaoOQ",
"index" : "person"
},
"status" : 400
}
根据上面的信息可知,索引关闭时写入数据将会报错。
下面可以尝试进行数据搜索:
GET /person/_search
{
"query": {
"match": {
"name": "孟博文"
}
}
}
ES返回的信息和进行写入请求时的返回信息是一样的,印证了索引在关闭时不能提供搜索服务的规定。
2.4、打开索引
索引关闭后,需要开启读写服务时可以将其设置为打开状态。下面的示例是把出于关闭状态的hotel索引设置为打开状态
POST /person/_open
索引被打开后,就可以对其进行读写操作了,例如下面是打开person索引后进行搜索操作:
2.5、索引别名
顾名思义,别名是指给一个或者多个索引定义另外一个名称,使索引别名和索引之间可以建立某种逻辑关系。
可以用别名表示别名和索引之间的包含关系。例如,我们建立了1月、2月、3月的用户入住酒店的日志索引,假设当前日期是4月1日,需要搜索过去的3个月的日志索引,如果分别去3个索引中进行搜索,这种编码方案比较低效。此时可以创建一个别名last_three_month,设置前面的3个索引的别名为last_three_month,然后在last_three_month中进行搜索即可。如下图所示,last_three_month包含january_log,february_log,march_log 3个索引,用户请求在last_three_month中进行搜索时,ES会在上述3个索引中进行搜索。
下面进行代码展示,首先依次建立january_log,february_log,march_log 3个索引。这里只展示创建january_log的DSL,因为这3个索引除了索引名称不一样,其他参数都是一样的,所以另外两个就不做赘述:
PUT /january_log
{
"mappings": {
"properties": {
"uid":{
"type": "keyword"
},
"hotel_id":{
"type": "keyword"
},
"check_in_date":{
"type": "keyword"
}
}
}
}
下面分别在3个索引中写入同一用户在不同月份的入住记录,DSL如下:
POST /january_log/_doc/001
{
"uid":"001",
"hotel_id":"92772",
"check_in_date":"2022-01-05"
}
POST /february_log/_doc/001
{
"uid":"001",
"hotel_id":"33224",
"check_in_date":"2022-02-07"
}
POST /march_log/_doc/001
{
"uid":"001",
"hotel_id":"82772",
"check_in_date":"2022-03-08"
}
现在建立别名last_three_month,设置上面3个新建的索引的别名统一为last_three_month,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"add": { #为索引january_log建立别名last_three_month
"index": "january_log",
"alias": "last_three_month",
}
},
{
"add": { #为索引february_log建立别名last_three_month
"index": "february_log",
"alias": "last_three_month"
}
},
{
"add": { #为索引march_log建立别名last_three_month
"index": "march_log",
"alias": "last_three_month"
}
}
]
}
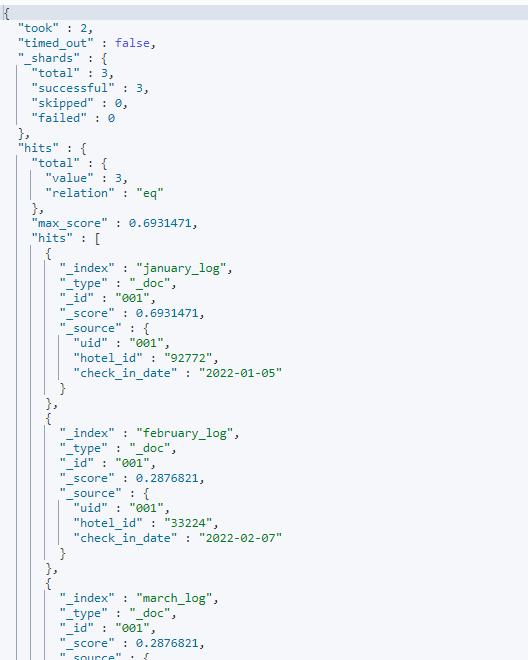
其中创建索引PUT /_aliases是创建别名的固定用法,此时,我们可以把这个别名看作是一个索引,这个索引包含了上面三个月入住记录的索引,我们同样也可以通过别名去搜索。比如搜索uid为001的用户的入住记录,搜索的DSL如下:
GET /last_three_month/_search
{
"query": {
"term": {
"uid": {
"value": "001"
}
}
}
}
返回结果如下:
而且我们同样可以对别名索引进行关闭打开的操作,例如执行如下操作:
POST /last_three_month/_close
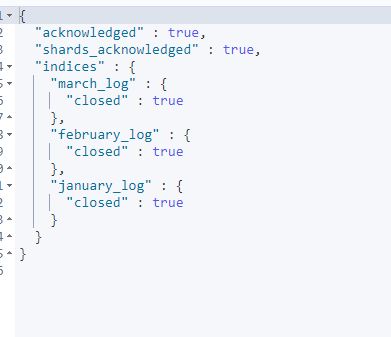
可以看见它将别名包含的三个索引同时关闭。此时对别名亦或是三个索引的读写操作均无法进行。打开后才可以操作,这一点和索引本身的打开关闭也是一模一样的。
从上面搜索或者关闭别名索引的操作结果可知,当请求搜索别名last_three_month的数据时,ES将请求转发到了january_log,february_log,march_log 3个索引中。
需要指出的是,在默认情况下,当一个别名只指向一个索引时,写入数据的请求指向这个别名,如果这个别名指向多个索引,就像上面的例子,则写入数据的请求是不可以指向这个别名的,因为别名并不知道该将这个写入请求转发给哪个索引处理。例如,向last_three_month中写入一条数据:
POST /last_three_month/_doc/002
{
"uid":"002",
"hotel_id":"92773",
"check_in_date":"2022-01-11"
}
es报错提示如下:

根据上面的报错信息可知,ES不能确定向last_three_month写入数据时的转发对象,这种情况需要在别名设置时,将想要写入的目标索引的is_write_index属性值设置为true来指定该索引可用于执行数据写入操作,例如设置january_log为数据写入转发对象,对应的DSL如下:
POST /_aliases
{
"actions": [
{
"add": {
"index": "january_log",
"alias": "last_three_month",
"is_write_index":true
}
},
{
"add": {
"index": "february_log",
"alias": "last_three_month"
}
},
{
"add": {
"index": "march_log",
"alias": "last_three_month"
}
}
]
}
此时可以再向别名last_three_month中写入上面举例的数据,ES返回结果如下:
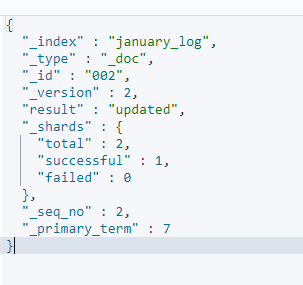
可以看到诗实际被写入的索引就是我们刚才设置别名时通过is_write_index指定的索引,但是is_write_index只能设置一次,不能在多个索引下面同时设置,否则会报错,例如:
POST /_aliases
{
"actions": [
{
"add": {
"index": "january_log",
"alias": "last_three_month",
"is_write_index":true
}
},
{
"add": {
"index": "february_log",
"alias": "last_three_month",
"is_write_index":true
}
},
{
"add": {
"index": "march_log",
"alias": "last_three_month"
}
}
]
}
ES报错如下:
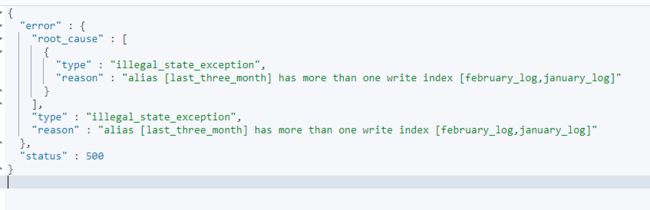
2.6、通过别名表示索引之间的替代关系
引入别名之后,还可以同别名表示索引之间的替代关系。这种关系一般是在某个索引被创建后,有些参数是不能更改的,例如主分片的个数,但随着业务发展,索引中的数据增多,需要更改索引参数进行优化。我们需要平滑地解决该问题,既要更改索引的设置,又不能改变索引名称,这时就可以使用索引别名。
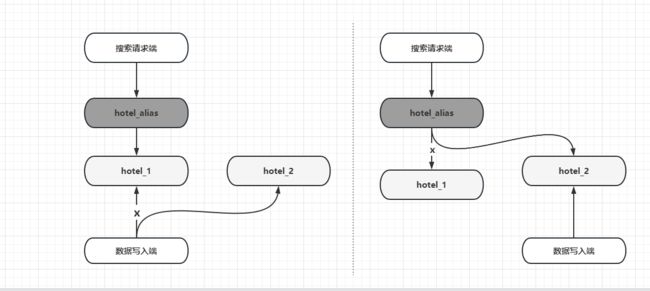
假设一个酒店的搜索别名设置为hotel_alias,初期创建索引hotel_1时,主分片个数设置为5,然后设置hotel_1的别名为hotel_alias,,此时客户端使用索引别名hotel_alias进行搜索请求,请求只会转发到索引hotel_1中。假设突然一下这个酒店成了网红酒店,索引中的数据急剧增长,索引分片需要将其扩展成为10个分片的索引来分担搜索压力。但是我们知道一个索引在创建后,主分片个数已经不能更改,因此只能考虑使用索引替换来完成索引的扩展。这时可以创建一个索引hotel_2,除了将其主分片个数设置为10外,其他设置与hotel_1相同。当hotel_2的索引和数据均准备好后,移除别名hotel_alias和hotel_1的关系,然后设置新创建的hotel_2的别名为hotel_alias.此时客户端不做任何改动,继续使用别名索引hotel_alias进行搜索请求时,该请求会转发给索引hotel_2,如果服务稳定,将hotel_1索引删除即可。此时借助别名就完成了一次索引替换工作。如下图所示,左边hotel_alias索引别名暂时指向hotel_1,hotel_2做好了数据准备;右边图中hotel_alias索引指向hotel2,完成了索引的扩展切换。
下面进行代码演示,首先建立索引hotel_1,设置其主分片个数为5,其他信息与创建索引时保持一致:
PUT /hotel_1
{
"settings": {
"number_of_shards": 5
, "number_of_replicas": 2
},
"mappings": {
"properties": {
"name":{
"type": "text"
},
"city":{
"type": "keyword"
},
"price":{
"type": "double"
}
}
}
}
在数据写入端向hotel_1写入搜索数据,请求的DSL如下:
POST /hotel_1/_doc/001
{
"name":"mbw酒店",
"city":"成都",
"price":"1145.14"
}
建立别名hotel_alias,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"add": {
"index": "hotel_1",
"alias": "hotel_alias"
}
}
]
}
在搜索请求端使用hotel_alias进行搜索,假设在name字段中搜索"mbw",搜索的DSL如下:
GET /hotel_alias/_search
{
"query": {
"match": {
"name": "mbw"
}
}
}
ES返回的数据如下图
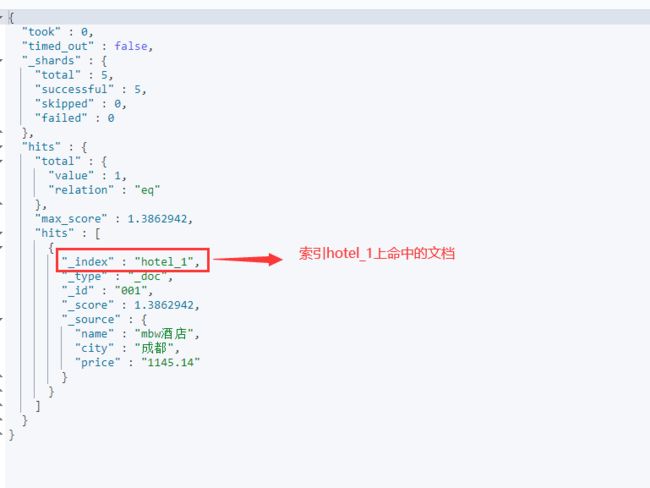
通过搜索结果可以看出,因为只有索引hotel_1的别名为hotel_alias,所以向索引别名hotel_alias发起搜索请求时ES会将搜索请求全部转发给索引hotel_1.
假设过一段时间后酒店索引的分片需要扩展。通过变更索引的方式可以完成扩展。建立索引hotel_2,并设置主分片个数为10,副分片个数为2,请求的DSL如下:
PUT /hotel_2
{
"settings": {
"number_of_shards": 10
, "number_of_replicas": 2
},
"mappings": {
"properties": {
"name":{
"type": "text"
},
"city":{
"type": "keyword"
},
"price":{
"type": "double"
}
}
}
}
在数据写入端向索引hotel_2中写入和索引hotel_1一样的数据,请求的DSL如下:
POST /hotel_2/_doc/001
{
"name":"mbw酒店",
"city":"成都",
"price":"1145.14"
}
或者我们可以使用另一个迁移的命令,将索引hotel_1的数据迁移至hotel_2,这个当然是最好的解决方式,因为正式环境我们的数据肯定不止一条。
命令格式如下:
POST _reindex
{
"source": {
"index": "old_index",
"size":1000 #可选,每次批量提交1000个,可以提高效率,建议每次提交5-15M的数据
"query": {} # 可选, 不写的默认是全量数据迁移 写上条件就是选择性迁移数据
},
"dest": {
"index": "new_index"
}
}
那这里由于我们只有1条数据,所以就直接向hotel_2插入那一条数据即可。
此时hotel_2中的数据已经准备完毕,现在变更别名设置,删除hotel_1的索引别名,设置索引hotel_2的别名为hotel_alias,请求的DSL如下:
POST /_aliases
{
"actions": [
{
"remove": { #删除索引hotel_1的别名hotel_alias
"index": "hotel_1",
"alias": "hotel_alias"
}
},
{
"add": { #增加索引hotel_1的别名hotel_alias
"index": "hotel_2",
"alias": "hotel_alias"
}
}
]
}
再执行前面的搜索,返回结果如下:
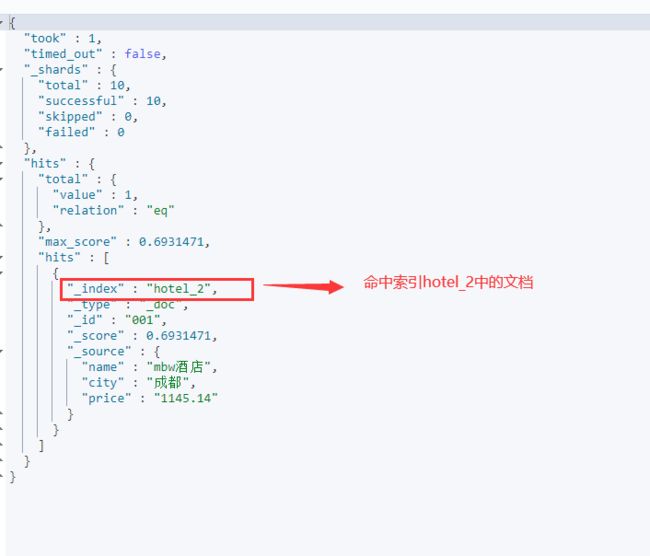
通过搜索结果可以看出,请求hotel_alias索引进行搜索时,搜索已经从转发给hotel_1变更为转发给hotel_2.因此,索引别名在这种需要变更索引的情况下,搜索端不需要任何变更即可完成切换,这在实际的生产环境中是非常方便的。