LLM预训练
网上大量预训练代码都是封装了trainer-deepspeed后的结果,看了也不了解其中所用技术的优化点在哪。本文从最基础的训练过程开始,层层加码并对比。
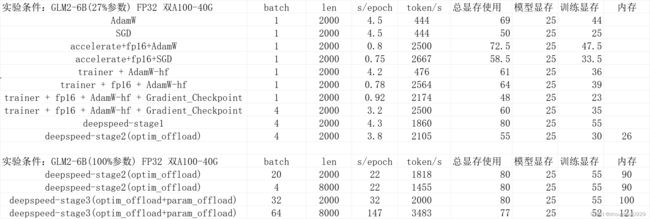
基础版本
1.代码
from transformers import AutoModel,AutoTokenizer
from torch.utils.data import Dataset, DataLoader
# 模型加载
model_path = "xxx/glm2" # 你的模型路径
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True,torch_dtype=torch.float32,device_map="auto")
# 使用一半参数测试
for k,v in model.named_parameters():
no_grad_layer = list(range(0,27,2))
no_grad_layer = [str(i) for i in no_grad_layer]
name_list = k.split(".")
if len(name_list) >= 4 and name_list[3] in no_grad_layer:
v.requires_grad=False
# dataset
example = ["text1","text2","text3"]
class GenerateDataset(Dataset):
def __init__(self, example):
super(GenerateDataset, self).__init__()
self.example = example
def __getitem__(self, item):
return self.example[item]
def __len__(self):
return len(self.example)
ds = GenerateDataset(example)
# dataloader+coll_fn
def pretrain_fn(context):
input_ids = []
label_ids = []
max_len = 2000
context_ids = tokenizer(context,add_special_tokens=False)["input_ids"]
target_ids = tokenizer(context,add_special_tokens=False)["input_ids"]
for c_ids, t_ids in zip(context_ids, target_ids):
length = len(c_ids)
if length >= max_len:
c_ids = c_ids[:max_len - 1] + [2]
t_ids = t_ids[:max_len - 1] + [2]
else:
c_ids = c_ids + [2] * (max_len - length)
t_ids = t_ids + [-100] * (max_len - length)
input_ids.append(c_ids)
label_ids.append(t_ids)
return {"input_ids":torch.LongTensor(input_ids),"labels":torch.LongTensor(label_ids)}
dl = DataLoader(ds, batch_size=1,collate_fn=pretrain_fn)
# 优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
# 训练
for batch in tqdm(dl):
optimizer.zero_grad()
out=model(input_ids=batch["input_ids"], labels=batch["labels"])
loss = out.loss
print(loss)
loss.backward()
optimizer.step()
# print(loss.item)
2.有几个注意事项:
1.torch_dtype=torch.float32,如果用了fp16,模型参数和损失直接变为nan,训练过程出错。用accelerate和trainer会报ValueError: Attempting to unscale FP16 gradients.
0%| | 0/1615 [00:00<?, ?it/s]tensor(11.4844, dtype=torch.float16, grad_fn=<ToCopyBackward0>)
0%| | 1/1615 [00:04<1:54:59, 4.27s/it]tensor(nan, dtype=torch.float16, grad_fn=<ToCopyBackward0>)
0%| | 2/1615 [00:04<50:53, 1.89s/it]tensor(nan, dtype=torch.float16, grad_fn=<ToCopyBackward0>)
ValueError: Attempting to unscale FP16 gradients.
2.优化器SGD/Adamw,6B模型全参数训练时候,如果用Adamw会爆显存(batch=1,文本长度20),用SGD则不会。实际llm没看到用SGD做优化器,这里只是提一嘴。
Accelerate 版本
# 加载model optimizer dataloader 后,加入以下代码
from accelerate import Accelerator
accelerator = Accelerator(mixed_precision="fp16")
device = accelerator.device
model, optimizer, dl = accelerator.prepare(model, optimizer, dl)
# 原来的loss.backward()替换为accelerator.backward(loss)
# loss.backward()
accelerator.backward(loss)
Trainer 版本
原代码的dataloader optimizer 和训练代码都不用了
train_args = TrainingArguments(save_strategy="epoch",
log_level="debug",
output_dir="./saved_checkpoint/",
per_device_train_batch_size=4,
gradient_accumulation_steps=1, # 梯度累积步数
num_train_epochs=1,
learning_rate=1e-5,
fp16=True, # 是否使用fp16
logging_steps=1,
warmup_steps=50,
optim="adamw_hf", # 指定优化器
gradient_checkpointing=True, # 梯度检查点
)
trainer = Trainer(model=model,train_dataset=ds,args=train_args, data_collator=pretrain_fn)
trainer.train()
需要注意的时:如果gradient_checkpointing=True,则需要加上下面的代码
model.enable_input_require_grads()
# 或者 直接修改模型embedding参数的requires_grad
for k,v in model.named_parameters():
if k == "transformer.embedding.word_embeddings.weight":
v.requires_grad = True
Trainer + DeepSpeed
修改train_args, 其他不变
train_args = TrainingArguments(save_strategy="steps",
save_steps=40,
log_level="debug",
output_dir="./test_lora/",
per_device_train_batch_size=2,
gradient_accumulation_steps=2,
num_train_epochs=10,
learning_rate=1e-6,
fp16=True,
logging_steps=1,
warmup_steps=10,
optim="adamw_hf",
gradient_checkpointing=True,
deepspeed="./notebooks/deepspeed-stage2.json" # 加入ds路径
)
stage-2参数
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 20,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
stage-3参数
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 20,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
启动命令
deepspeed pretrain.py --seepspeed ./notebooks/deepspeed-stage2.json