Postgresql源码(85)查询执行——表达式解析器分析(select 1+1如何执行)
相关
《Postgresql源码(61)查询执行——最外层Portal模块》
《Postgresql源码(62)查询执行——子模块ProcessUtility》
《Postgresql源码(63)查询执行——子模块Executor(1)》
《Postgresql源码(64)查询执行——子模块Executor(2)执行前的数据结构和执行过程》
…
…
《Postgresql源码(85)查询执行——表达式解析器分析(select 1+1如何执行)》
《Postgresql源码(113)表达式JIT计算简单分析》
总结
- 表达式解析器执行可以简化为两步:
- ExecInitExpr:
- 准备ExprState结构记录执行需要的全部信息
- 记录Step数组,每一个为一个工作单元ExprEvalStep
- 每一个工作单元ExprEvalStep记录了该步的执行结果、内部有大union记录了该步骤执行需要的信息
- 每一个工作单元ExprEvalStep记录了自己在ExecInterpExpr函数中,需要跳转到什么位置处理自己
- ExecEvalExprSwitchContext
- 核心函数ExecInterpExpr:函数使用GOTO替代了递归遍历,所以会看到很多宏可读性较差
- 流程:每次拿出一个工作单元ExprEvalStep,goto到
ExprEvalStep->opcode记录的位置进行处理 - 流程:处理后,++偏移到steps数组下一个位置,goto到
ExprEvalStep->opcode记录的位置进行处理
- ExecInitExpr:
-
调试技巧备忘
- 进入ExecInterpExpr后,
p *state可以查看当前执行的所有数据 - 其中
p state->steps_len:要执行几步,最后一步为空,表示结束p state->steps[0]:可以打印0步的信息,但无法确认是什么类型的stepp/x state->steps[0]->opcode:打印当前步骤的标记位置0x7252bf
p reverse_dispatch_table:打印所有标记位置对应的op枚举型{opcode = 0x7252bf
- 用0x7252bf找到EEOP_FUNCEXPR_STRICT类型,在ExecInterpExpr中搜索即可找到处理分支
- 进入ExecInterpExpr后,
-
xxx__walker函数
- 功能:递归遍历表达式执行树
- 实现:函数内会递归进入各种各样的node类型,要截取函数感兴趣的node类型处理并返回
- 实现:如果没有发现感兴趣的节点,最后调用expression_tree_walker(…,xxx__walker,…)并把自己作为参数传入,expression_tree_walker在内部递归树时,新节点会递归进入
xxx__walker处理。
ps. PG对表达式执行做了大量优化,文章最后摘录了优化设计思想,DFS到BFS的经典优化过程。
正文:
待分析SQL:select 1+1
- evaluate_expr:优化器入口,进入表达式解析器。
- CreateExecutorState
- fix_opfuncids
- ExecInitExpr
- ExecEvalExprSwitchContext
1 CreateExecutorState
输入:无
输出:EState
功能:构造通用estate结构用于后面调用执行器模块
2 fix_opfuncids
输入:FuncExpr
expr -> FuncExpr
{ xpr = {type = T_FuncExpr},
funcid = 177,
funcresulttype = 23,
funcretset = false,
funcvariadic = false,
funcformat = COERCE_EXPLICIT_CALL,
funccollid = 0,
inputcollid = 0,
args = 0x2a49548,
location = -1
}
args -> List
{ xpr = {type = T_Const},
consttype = 23, consttypmod = -1, constcollid = 0, constlen = 4,
constvalue = 1, constisnull = false, constbyval = true, location = 7 }
{ xpr = {type = T_Const},
consttype = 23, consttypmod = -1, constcollid = 0, constlen = 4,
constvalue = 1, constisnull = false, constbyval = true, location = 9 }
输出:无
功能:递归遍历所有节点,包括FuncExpr和FuncExpr->args链表上的所有元素。当前用例场景无操作返回。
-
对于其他操作符可能有配置,例如fix_opfuncids_walker->set_opfuncid会在pg_operator中取oprcode出来赋值。
-
pg_operator的oprcode表示当前操作符的处理函数的oid,关联pg_proc。
fix_opfuncids
fix_opfuncids_walker
expression_tree_walker_impl 传入 FuncExpr
case T_FuncExpr:
LIST_WALK(expr->args)
expression_tree_walker_impl 【递归】传入 FuncExpr-->args
fix_opfuncids_walker 【递归】传入 FuncExpr-->args list的第一个元素
expression_tree_walker_impl
3 ExecInitExpr
输入:FuncExpr
输出:ExprState
功能:构造ExprState
数据结构
ExprState
typedef struct ExprState
{
NodeTag type;
uint8 flags; /* bitmask of EEO_FLAG_* bits, see above */
/*
* Storage for result value of a scalar expression, or for individual
* column results within expressions built by ExecBuildProjectionInfo().
*/
#define FIELDNO_EXPRSTATE_RESNULL 2
bool resnull;
#define FIELDNO_EXPRSTATE_RESVALUE 3
Datum resvalue;
/*
* If projecting a tuple result, this slot holds the result; else NULL.
*/
#define FIELDNO_EXPRSTATE_RESULTSLOT 4
TupleTableSlot *resultslot;
/*
* Instructions to compute expression's return value.
*/
struct ExprEvalStep *steps;
/*
* Function that actually evaluates the expression. This can be set to
* different values depending on the complexity of the expression.
*/
ExprStateEvalFunc evalfunc;
/* original expression tree, for debugging only */
Expr *expr;
/* private state for an evalfunc */
void *evalfunc_private;
/*
* XXX: following fields only needed during "compilation" (ExecInitExpr);
* could be thrown away afterwards.
*/
int steps_len; /* number of steps currently */
int steps_alloc; /* allocated length of steps array */
#define FIELDNO_EXPRSTATE_PARENT 11
struct PlanState *parent; /* parent PlanState node, if any */
ParamListInfo ext_params; /* for compiling PARAM_EXTERN nodes */
Datum *innermost_caseval;
bool *innermost_casenull;
Datum *innermost_domainval;
bool *innermost_domainnull;
} ExprState;
ExprEvalStep
typedef struct ExprEvalStep
{
/*
* Instruction to be executed. During instruction preparation this is an
* enum ExprEvalOp, but later it can be changed to some other type, e.g. a
* pointer for computed goto (that's why it's an intptr_t).
*/
intptr_t opcode;
/* where to store the result of this step */
Datum *resvalue;
bool *resnull;
/*
* Inline data for the operation. Inline data is faster to access, but
* also bloats the size of all instructions. The union should be kept to
* no more than 40 bytes on 64-bit systems (so that the entire struct is
* no more than 64 bytes, a single cacheline on common systems).
*/
union
{
...
struct
{
/* constant's value */
Datum value;
bool isnull;
} constval;
...
} d;
} ExprEvalStep;
流程
ExecInitExpr
-
ExecInitExprSlots
-
ExecInitExprRec
-
ExecInitFunc:构造函数结构放入scratch(ExprEvalStep)当前ExprEvalStep状态

-
ExprEvalPushStep:ExprState中申请16个位置用来放ExprEvalStep

-
-
ExprEvalPushStep:推一个空的Step上去作为结尾

-
ExecReadyExpr:准备一个编译完的表达式来执行
-
ExecReadyInterpretedExpr
- ExecInitInterpreter:初始化表达式解析器,用三个空值调入ExecInterpExpr函数,用ExecInterpExpr函数内定义好的dispatch_table赋给全局变量dispatch_table。dispatch_table是一个指针数组在函数进入时初始化的,记录了所有ExecInterpExpr函数内的label地址(goto需要使用)。


- ExecInitInterpreter还需要遍历dispatch_table构造reverse_dispatch_table,把dispatch_table的裸数据做下包装

- ExecInitInterpreter:初始化表达式解析器,用三个空值调入ExecInterpExpr函数,用ExecInterpExpr函数内定义好的dispatch_table赋给全局变量dispatch_table。dispatch_table是一个指针数组在函数进入时初始化的,记录了所有ExecInterpExpr函数内的label地址(goto需要使用)。
-
ExecReadyInterpretedExpr继续
- 第一次运行要给ExecInterpExprStillValid入口state->evalfunc = ExecInterpExprStillValid
- 把之前Step中的opcode直接用dispatch_table的地址做替换,便于直接跳转。
-
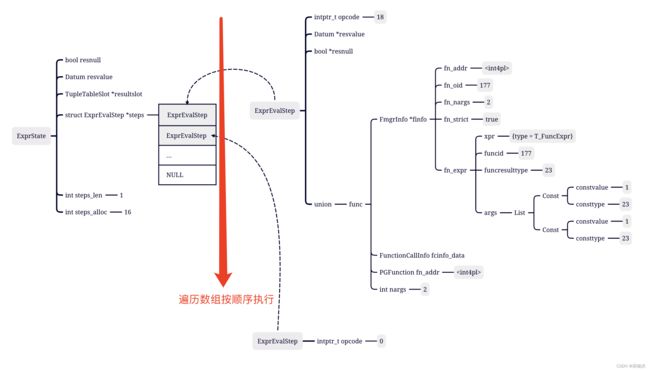
exprstate最终形态
{
type = T_ExprState,
flags = 6 '\006',
resnull = false,
resvalue = 0,
resultslot = 0x0,
// 数组两个元组,记录了运行的两步,最后一步永远是None
steps = 0x2b11168,
// 第一次执行必须是ExecInterpExprStillValid
evalfunc = 0x72717e <ExecInterpExprStillValid>,
// FuncExpr
expr = 0x2a495e8,
// 真正入口,ExecInterpExprStillValid完了就走这里干活
evalfunc_private = 0x7249dc <ExecInterpExpr>,
// 两步
steps_len = 2,
// 预备了16步的空间
steps_alloc = 16,
parent = 0x0,
ext_params = 0x0,
innermost_caseval = 0x0,
innermost_casenull = 0x0,
innermost_domainval = 0x0,
innermost_domainnull = 0x0}
4 ExecInitExpr
ExecEvalExprSwitchContext
ExecInterpExprStillValid
ExecInterpExpr
ExecInterpExpr函数用宏支持两种执行模式:递归Switch或GOTO,默认GCC使用GOTO方式运行。
进入ExecInterpExpr后第一步ExprEvalStep op = state->steps;,从state中取出steps数组,拿到ExprEvalStep
#define EEO_DISPATCH() goto *((void *) op->opcode)
宏EEO_DISPATCH或直接跳转到处理逻辑上
ExecInterpExpr
...
...
...
EEO_CASE(EEOP_FUNCEXPR_STRICT)
{
FunctionCallInfo fcinfo = op->d.func.fcinfo_data;
NullableDatum *args = fcinfo->args;
int nargs = op->d.func.nargs;
Datum d;
/* strict function, so check for NULL args */
for (int argno = 0; argno < nargs; argno++)
{
if (args[argno].isnull)
{
*op->resnull = true;
goto strictfail;
}
}
fcinfo->isnull = false;
d = op->d.func.fn_addr(fcinfo);
*op->resvalue = d;
*op->resnull = fcinfo->isnull;
strictfail:
EEO_NEXT();
}
表达式解析器优化commit
讨论邮件列表:https://postgr.es/m/[email protected]
Faster expression evaluation and targetlist projection.
This replaces the old, recursive tree-walk based evaluation, with non-recursive, opcode dispatch based, expression evaluation.
Projection is now implemented as part of expression evaluation.
This both leads to significant performance improvements, and makes future just-in-time compilation of expressions easier.
更快的表达式评估和目标列表投影。
这用非递归的、基于操作码分派的表达式求值取代了旧的、基于递归树遍历的求值。
投影现在作为表达式评估的一部分实现。
这既可以显着提高性能,也可以使将来的表达式即时编译变得更容易。
The speed gains primarily come from:
- non-recursive implementation reduces stack usage / overhead
- simple sub-expressions are implemented with a single jump, without function calls
- sharing some state between different sub-expressions
- reduced amount of indirect/hard to predict memory accesses by laying out operation metadata sequentially; including the avoidance of nearly all of the previously used linked lists
- more code has been moved to expression initialization, avoiding constant re-checks at evaluation time
速度增益主要来自:
- 非递归实现减少堆栈使用/开销
- 简单的子表达式通过单次跳转实现,无需函数调用
- 在不同的子表达式之间共享一些状态
- 通过按顺序排列操作元数据来减少间接/难以预测的内存访问量; 包括避免几乎所有以前使用的链表
- 更多代码已移至表达式初始化,避免在评估时不断重新检查
Future just-in-time compilation (JIT) has become easier, as demonstrated by released patches intended to be merged in a later release, for primarily two reasons: Firstly, due to a stricter split between expression initialization and evaluation, less code has to be handled by the JIT. Secondly, due to the non-recursive nature of the generated "instructions", less performance-critical code-paths can easily be shared between interpreted and compiled evaluation.
未来的即时编译 (JIT) 已经变得更加容易,正如旨在在以后的版本中合并的已发布补丁所证明的那样,主要有两个原因:首先,由于表达式初始化和评估之间的划分更加严格,因此需要更少的代码 由 JIT 处理。 其次,由于生成的“指令”的非递归性质,对性能不太重要的代码路径可以很容易地在解释和编译评估之间共享。
The new framework allows for significant future optimizations. E.g.:
- basic infrastructure for to later reduce the per executor-startup overhead of expression evaluation, by caching state in prepared statements. That'd be helpful in OLTPish scenarios where initialization overhead is measurable.
- optimizing the generated "code". A number of proposals for potential work has already been made.
- optimizing the interpreter. Similarly a number of proposals have been made here too.
新框架允许在未来进行重大优化。 例如。:
- 用于稍后通过在准备好的语句中缓存状态来减少表达式评估的每个执行程序启动开销的基本基础架构。 这在初始化开销是可测量的 OLTP 场景中很有帮助。
- 优化生成的“代码”。 已经提出了一些关于潜在工作的建议。
- 优化解释器。 同样,这里也提出了一些建议。
The move of logic into the expression initialization step leads to some backward-incompatible changes:
- Function permission checks are now done during expression initialization, whereas previously they were done during execution. In edge cases this can lead to errors being raised that previously wouldn't have been, e.g. a NULL array being coerced to a different array type previously didn't perform checks.
- The set of domain constraints to be checked, is now evaluated once during expression initialization, previously it was re-built every time a domain check was evaluated. For normal queries this doesn't change much, but e.g. for plpgsql functions, which caches ExprStates, the old set could stick around longer. The behavior around might still change.
将逻辑转移到表达式初始化步骤会导致一些向后不兼容的更改:
- 函数权限检查现在在表达式初始化期间完成,而以前它们是在执行期间完成的。 在边缘情况下,这可能会导致出现以前不会出现的错误,例如 一个 NULL 数组被强制转换为不同的数组类型,以前没有执行检查。
- 要检查的域约束集现在在表达式初始化期间评估一次,以前每次评估域检查时都会重新构建。 对于普通查询,这并没有太大变化,但是例如 对于缓存 ExprStates 的 plpgsql 函数,旧集合可能会保留更长时间。 周围的行为可能仍然会改变。