go语言基础精修(尚硅谷笔记)
针对很多人的反馈,我对文章进行了质量改进和分章发布。其中第13到15章因为不是go语言特有的机制就没记录。分章文章目录如下,需要的可以点进分章详细学习不需要每次都要往下翻很久。
第一二章:go语言学习方向与golang概述
第三章:变量
第四章:运算符
第五章:程序流程控制
第六章:函数、包和错误处理
第七章:数组和切片
第八章:排序和查找
第九章:map
第十章:面向对象编程
第十一章:文件操作
第十二章:单元测试
第十六章:goroutine和channel
第十七和十八章:反射和TCP编程
一、Golang的学习方向
1.1 Go的学习方向
Go语言,可以简单写成Golang(lang是language)
- 区块链研发工程师
- Go服务器端/游戏软件工程师
- Golang分布式/云计算软件工程师
1.2 Go的应用领域
- 区块链应用
- 后端服务器应用
- 云计算、云服务后台应用
1.3 学习方法介绍
二、golang概述
2.1 Google创造Golang的原因
- 计算机硬件技术更新频繁,性能提高很快。目前主流的编程语言发展明显落后于硬件,不能合理利用多核多CPU的优势提升软件系统性能。
- 软件系统复杂度越来越高,维护成本越来越高,目前缺乏一个足够简洁高效的编程语言。
- 【现有的编程语言:1.风格不统一 2.计算能力不够 3.处理大并发不够好】
- 企业运行维护很多c/c++的项目,c/c++程序运行速度虽然很快,但是编译速度确很慢,同时还存在内存泄漏的一些列的困扰需要解决。
2.2 Go语言特性
Go语言保证了既能达到静态编译语言的安全和性能,又达到了动态语言开发维护的高效率,使用一个表达式来形容Go语言:Go=C+Python,说明Go语言既有C静态语言程序的运行速度,又能达到Python动态语言的快速开发。
- 从C语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等,也保留了和C语言一样的编译执行方式及弱化的指针
- 引入包的概念,用于组织程序结构,Go语言的一个文件都要归属于一个包,而不能单独存在。
- 垃圾回收机制,内存自动回收,不需要开发人员管理
- 天然并发(重要特点)
- 从语言层面支持并发,实现简单
- goroutine,轻量级线程,可实现大并发处理,高效利用多核。
- 基于CPS并发模型(Communicating Sequential Processes)实现
- 吸收了管道通信机制,形成Go语言特有的管道channel通过管道channel,可以实现不同的goroute之间的互相通信。
- 函数可以返回多个值。举例
//写一个函数,实现同时返回 和,差
func getSumAndSub(n1 int,n2 int)(int,int){
sum := n1 + n2
sub := n1 - n2
return sum,sub
}
7.新的创新:比如切片slice、延时执行defer
2.3 下载配置
略
2.4 goland创建第一个go程序
goland新建go mould
创建mian文件夹,在main下创建文件test.go
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
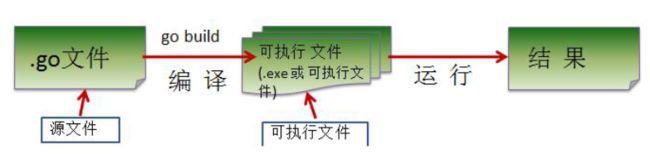
- 直接golang点击绿色三角形运行

- 命令行先编译后运行(windows下编译生成.exe文件)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FqSymeZ4-1669084586567)(C:\Users\ZHAI\AppData\Roaming\Typora\typora-user-images\image-20221113163223102.png)]
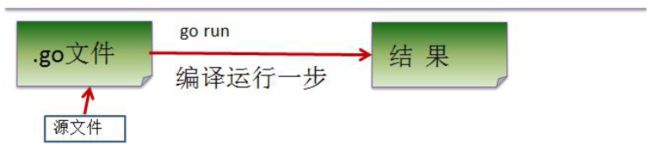
- 命令行go run 直接运行(需要有go的环境)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zU8VGRfe-1669084586569)(C:\Users\ZHAI\AppData\Roaming\Typora\typora-user-images\image-20221113163248769.png)]
- 两种执行流程的方式区别
- 1 ) 如果我们先编译生成了可执行文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上,仍然可以运行
- 2.) 如果我们是直接 gorun go源代码,那么如果要在另外一个机器上这么运行,也需要go开发 环境,否则无法执行。
- 3 ) 在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了 很多。
2.5 注意事项
1 ) Go源文件以 “go” 为扩展名。
2.) Go应用程序的执行入口是main()函数。 这个是和其它编程语言(比如java/c)
3 ) Go语言严格区分大小写。
4 ) Go方法由一条条语句构成,每个语句后不需要分号(Go语言会在每行后自动加分号),这也体现出Golang的简洁性。
5 ) Go编译器是一行行进行编译的,因此我们一行就写一条语句,不能把多条语句写在同一个,否 则报错
6 ) go语言定义的变量或者 import 的包如果没有使用到,代码不能编译通过。
7 ) 大括号都是成对出现的,缺一不可。
2.6 注释
1 ) 行注释
- 基本语法: // 注释内容
2.) 块注释(多行注释)
- 基本语法
/*
注释内容
*/
- 使用细节
- 1 ) 对于行注释和块注释,被注释的文字,不会被Go编译器执行。
- 2.) 块注释里面不允许有块注释嵌套 [注意一下]
2.7 规范的代码风格
1 ) Go官方推荐使用行注释来注释整个方法和语句。
2 ) 使用一次 tab 操作,实现缩进,默认整体向右边移动,时候用 shift+tab 整体向左移
3)或者使用 gofmt 来进行格式化
- gofmt xxxx.go 只是把个格式化的代码输出
- gofmt -w xxxx.go 把格式化的代码替换掉原文件里的代码
4 ) 运算符两边习惯性各加一个空格。比如: 2.+ 4 * 5 。
5)Go语言的代码风格.
package main
import"fmt"
func main(){
fmt.Println("hello,world!")
}
上面的写法是正确的.
package main
import"fmt"
funcmain()
{
fmt.Println("hello,world!")
}
上面的写法不是正确,Go语言不允许这样编写。 【Go语言不允许这样写,是错误的!】
6 ) 一行最长不超过 80 个字符,超过的请使用换行展示,尽量保持格式优雅
2.8 GOLANG 官方编程指南
说明: Golang 官方网站 https://golang.org
-
点击的tour-> 选择 简体中文就可以进入中文版的 Go编程指南 。
-
Golang 官方标准库API文档, https://golang.org/pkg (opens new window)可以查看Golang所有包下的函数和使用
-
解释术语:API
api : applicationprograminterface:应用程序编程接口。
就是我们Go的各个包的各个函数。
-
Golang 中文网 在线标准库文档: https://studygolang.com/pkgdoc(opens new window)
-
Golang的包和源文件和函数的关系简图
2.9 DOS的常用指令(window下)
Dos: DiskOperatingSystem 磁盘操作系统
查看当前目录
dir
转换到其他盘符例如d盘
d:
切换到当前盘符其他目录下
cd
切换到上一级
cd ..
切换到根目录
cd \
新建目录
md 目录名1 目录名2
删除空目录
rd 空目录名
删除目录以及下面的子目录和文件,不带询问
rd /q/s 目录名
删除目录以及下面的子目录和文件,带询问
rd /s 目录名
新建或追加内容到文件
文件名.后缀
复制文件
copy 文件名1 地址\文件名2
移动文件
move 文件名 地址
删除指定文件
del 文件名
删除指定文件
del *.txt
退出
exit
2.10 总结
-
Go语言的SDK是什么?
SDK 就是软件开发工具包。我们做Go开发,首先需要先安装并配置好sdk.
-
Golang环境变量配置及其作用。
GOROOT: 指定gosdk 安装目录。
Path: 指令 sdk\bin 目录:go.exe godoc.exe gofmt.exe
GOPATH: 就是golang工作目录:我们的所有项目的源码都这个目录下。
-
Golang程序的编写、编译、运行步骤是什么? 能否一步执行?
编写:就是写源码
编译:gobuild 源码 =》 生成一个二进制的可执行文件
运行: 1. 对可执行文件运行 xx.exe ./可执行文件 2…gorun 源码
-
Golang程序编写的规则。
1 ) go文件的后缀 .go
2.) go程序区分大小写
3 ) go的语句后,不需要带分号
4 ) go定义的变量,或者import 包,必须使用,如果没有使用就会报错
5 ) go中,不要把多条语句放在同一行。否则报错
6 ) go中的大括号成对出现,而且风格
三、变量
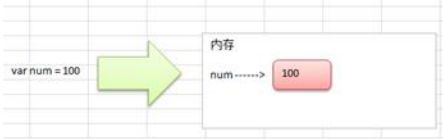
变量相当于内存中一个数据存储空间的表示,你可以把变量看做是一个房间的门牌号,通过门牌号我们可以找到房间,同样的道理,通过变量名可以访问到变量(值)。
Golang的变量如果没有赋初值,编译器会使用默认值, 比如 int 默认值 0 string默认值为空串, 小数默认为 0
- 声明变量
基本语法: var 变量名 数据类型
var a int//这就是声明了一个变量,一个变量名是a
var num1 float32 //这也声明了一个变量,表示一个单精度类型的小数,变量名是num1
- 初始变量
在声明变量的时候,就给值。
var a int = 45 //这就是初始化变量a
var b = 400 //如果声明时就直接赋值,可省略数据类型
b := 400 //类型推导
- 给变量赋值
var num int //默认0
num = 780 //给变量赋值
3.1 整形
1 ) Golang各整数类型分:有符号和无符号,intuint 的大小和系统有关。
2 ) Golang的整型默认声明为 int 型
//整型的使用细节
var n1 = 100 // ? n1 是什么类型
//这里我们给介绍一下如何查看某个变量的数据类型
//fmt.Printf() 可以用于做格式化输出。
fmt.Printf("n1 的 类型 %T \n", n1)
3.) 如何在程序查看某个变量的字节大小和数据类型 (使用较多)
//如何在程序查看某个变量的占用字节大小和数据类型 (使用较多)
var n2 int64 = 10
//unsafe.Sizeof(n1) 是unsafe包的一个函数,可以返回n1变量占用的字节数
fmt.Printf("n2 的 类型 %T n2占用的字节数是 %d ", n2, unsafe.Sizeof(n2))
4 ) Golang程序中整型变量在使用时,遵守保小不保大的原则,即:在保证程序正确运行下,尽量 使用占用空间小的数据类型。【如:年龄】
var age byte = 90
3.) 浮点型常量有两种表示形式
十进制数形式:如: 5.12 . 512 (必须有小数点)
科学计数法形式:如: 5. 1234 e 2 = 5. 12 * 10 的 2 次方 5. 12 E- 2 = 5. 12 / 10 的 2 次方
package main
import (
"fmt"
)
//演示golang中小数类型使用
func main() {
//十进制数形式:如:5.12 .512 (必须有小数点)
num6 := 5.12
num7 := .123 //=> 0.123
fmt.Println("num6=", num6, "num7=", num7)
//科学计数法形式
num8 := 5.1234e2 // ? 5.1234 * 10的2次方
num9 := 5.1234E2 // ? 5.1234 * 10的2次方 shift+alt+向下的箭头
num10 := 5.1234E-2 // ? 5.1234 / 10的2次方 0.051234
fmt.Println("num8=", num8, "num9=", num9, "num10=", num10)
}
通常情况下,应该使用 float 64 ,因为它比float 32 更精确。[开发中,推荐使用 float 64
3.2 字符类型
1 ) 字符型 存储到 计算机中,需要将字符对应的码值(整数)找出来
存储:字符—>对应码值---->二进制–>存储
读取:二进制----> 码值 ---->字符 --> 读取
2 ) 字符和码值的对应关系是通过字符编码表决定的(是规定好)
3.) Go语言的编码都统一成了utf- 8 。非常的方便,很统一,再也没有编码乱码的困扰了
注意:
1 ) Go语言的字符串的字节使用UTF- 8 编码标识Unicode文本,这样Golang统一使用UTF- 8 编码,中文 乱码问题不会再困扰程序员。
2 ) 字符串一旦赋值了,字符串就不能修改了:在Go中字符串是不可变的。
3.3 数据类型转换
Golang 和java/c 不同,Go 在不同类型的变量之间赋值时需要显式转换。也就是说Golang中数据类型不能自动转换。
3.3.1 基本语法
表达式 T(v) 将值 v 转换为类型 T
T : 就是数据类型,比如 int 32 ,int 64 ,float 32 等等
v : 就是需要转换的变量
被转换的是变量存储的数据(即值),变量本身的数据类型并没有变化!
package main
import (
"fmt"
)
//演示golang中基本数据类型的转换
func main() {
var i int32 = 100
//希望将 i => float
var n1 float32 = float32(i)
var n2 int8 = int8(i)
var n3 int64 = int64(i) //低精度->高精度
fmt.Printf("i=%v n1=%v n2=%v n3=%v \n", i ,n1, n2, n3)
//被转换的是变量存储的数据(即值),变量本身的数据类型并没有变化
fmt.Printf("i type is %T\n", i) // int32
}
在转换中,比如将 int 64 转成 int 8 【- 128 - – 127 】 ,编译时不会报错,只是转换的结果是按 溢出处理,和我们希望的结果不一样。 因此在转换时,需要考虑范围.
3.3.2 基本数据类型和string的转换
方式 1 :fmt.Sprintf(“%参数”, 表达式)
参数需要和表达式的数据类型相匹配
fmt.Sprintf() 会返回转换后的字符串
案例演示
package main
import (
"fmt"
_ "unsafe"
"strconv"
)
//演示golang中基本数据练习转成string使用
func main() {
var num1 int = 99
var num2 float64 = 23.456
var b bool = true
var myChar byte = 'h'
var str string //空的str
//使用第一种方式来转换 fmt.Sprintf方法
str = fmt.Sprintf("%d", num1)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%f", num2)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%t", b)
fmt.Printf("str type %T str=%q\n", str, str)
str = fmt.Sprintf("%c", myChar)
fmt.Printf("str type %T str=%q\n", str, str)
}
方式 2 :使用strconv 包的函数
package main
import (
"fmt"
_ "unsafe"
"strconv"
)
//演示golang中基本数据练习转成string使用
func main() {
//第二种方式 strconv 函数
var num3 int = 99
var num4 float64 = 23.456
var b2 bool = true
str = strconv.FormatInt(int64(num3), 10)
fmt.Printf("str type %T str=%q\n", str, str)
// strconv.FormatFloat(num4, 'f', 10, 64)
// 说明: 'f' 格式 10:表示小数位保留10位 64 :表示这个小数是float64
str = strconv.FormatFloat(num4, 'f', 10, 64)
fmt.Printf("str type %T str=%q\n", str, str)
str = strconv.FormatBool(b2)
fmt.Printf("str type %T str=%q\n", str, str)
//strconv包中有一个函数Itoa
var num5 int64 = 4567
str = strconv.Itoa(int(num5))
fmt.Printf("str type %T str=%q\n", str, str)
}
3.3.3 string类型转基本数据类型
使用时strconv包的函数
func ParseBool(str string)(value bool,err error)
func ParseFloat(s string,bitSize int)(f float64,err error)
func ParseInt(s string,base int,bitSize int)(i int64,err error)
func ParseUint(s string,b int,bitSize int)(n uint64,err error)
package main
import (
"fmt"
"strconv"
)
//演示golang中string转成基本数据类型
func main() {
var str string = "true"
var b bool
// b, _ = strconv.ParseBool(str)
// 说明
// 1. strconv.ParseBool(str) 函数会返回两个值 (value bool, err error)
// 2. 因为我只想获取到 value bool ,不想获取 err 所以我使用_忽略
b , _ = strconv.ParseBool(str)
fmt.Printf("b type %T b=%v\n", b, b)
var str2 string = "1234590"
var n1 int64
var n2 int
n1, _ = strconv.ParseInt(str2, 10, 64)
n2 = int(n1)
fmt.Printf("n1 type %T n1=%v\n", n1, n1)
fmt.Printf("n2 type %T n2=%v\n", n2, n2)
var str3 string = "123.456"
var f1 float64
f1, _ = strconv.ParseFloat(str3, 64)
fmt.Printf("f1 type %T f1=%v\n", f1, f1)
}
3.4 标识符命名
1 ) 由 26 个英文字母大小写, 0 - 9 ,_ 组成
2 ) 数字不可以开头。var num int //ok var 3num int//error
3.) Golang中严格区分大小写。
var num int
var Num int
复制代码
说明:在golang中,num 和 Num 是两个不同的变量
4 ) 标识符不能包含空格。
var ab c int = 30 //错误
5 ) 下划线"_"本身在Go中是一个特殊的标识符,称为空标识符。可以代表任何其它的标识符,但是它对应的值会被忽略(比如:忽略某个返回值)。所以仅能被作为占位符使用,不能作为标识符使用
var _ int = 40 //error
fmt.Println(_)
6 ) 不能以系统保留关键字作为标识符(一共有 25 个),比如 break,if 等等.
注意事项
1 ) 包名:保持package的名字和目录保持一致,尽量采取有意义的包名,简短,有意义,不要和标准库不要冲突 fmt
2 ) 变量名、函数名、常量名:采用驼峰法
举例:
var stuName string = “tom” 形式:xxxYyyyyZzzz.
var goodPrice float 32 = 1234. 5
3.) 如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用 ( 注:可以简单的理解成,首字母大写是公开的,首字母小写是私有的),在golang没有public,private 等关键字。
3.5 系统保留字
在go中,为了简化代码编译过程中对代码的解析,其定义的保留关键字只有25个。
| break | default | func | interface | select |
|---|---|---|---|---|
| case | defer | go | map | struct |
| chan | else | goto | package | switch |
| const | fallthrough | if | range | type |
| continue | for | import | return | var |
3.6 系统预定义标识符
除了保留关键字外,Go还提供了36个预定义的标识符,其包括基本数据类型和系统内嵌函数
| append | bool | byte | cap | close | complex |
|---|---|---|---|---|---|
| complex64 | complex128 | unit16 | copy | false | float32 |
| float64 | imag | int | int8 | int16 | uint32 |
| int32 | int64 | iota | len | make | new |
| nil | panic | uint64 | println | real | |
| recover | string | true | uint | uint8 | uintprt |
四、运算符
4.1 算术运算符的一览表
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| + | 正号 | +3 | 3 |
| - | 负号 | -4 | -4 |
| + | 加 | 5+5 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 3*4 | 12 |
| / | 除 | 5/5 | 1 |
| % | 取模(取余) | 7%5 | 2 |
| ++ | 自增 | a=2 a++ | a=3 |
| – | 自减 | a=2 a– | a=1 |
| + | 字符串相加 | “he”+“llo” | “hello” |
注意:
1)Golang的自增自减只能当做一个独立语言使用时,不能这样使用。
2)Golang 的++ 和 – 只能写在变量的后面,不能写在变量的前面,即:只有 a++a-- 没有 ++a --a
package main
import (
_ "fmt"
)
func main() {
//在golang中,++ 和 -- 只能独立使用.
var i int = 8
var a int
i++ // 独立使用,正确
++i // 错误,前++
a = i++ //错误,i++只能独立使用
a = i-- //错误, i--只能独立使用
if i++ > 0 { //错误
fmt.Println("ok")
}
}
4.2 面试题
package main
import (
"fmt"
)
func main() {
//有两个变量,a和b,要求将其进行交换,但是不允许使用中间变量,最终打印结果
var a int = 10
var b int = 20
a = a + b //
b = a - b // b = a + b - b ==> b = a
a = a - b // a = a + b - a ==> a = b
fmt.Printf("a=%v b=%v", a, b)
}
4.3 特别说明
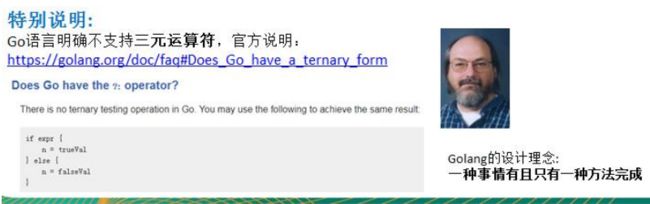
举例说明,如果在golang中实现三元运算的效果
package main
import (
"fmt"
)
func main() {
var n int
var i int = 10
var j int = 12
//传统的三元运算
//n = i > j ? i : j
if i > j {
n = i
} else {
n = j
}
fmt.Println("n=", n) // 12
}
4.4 从键盘输入
1 ) 导入fmt包
2 ) 调用fmt包的 fmt.Scanln () 或者 fmt.Scanf ()

package main
import (
"fmt"
)
func main() {
//要求:可以从控制台接收用户信息,【姓名,年龄,薪水, 是否通过考试 】。
//方式1 fmt.Scanln
//1先声明需要的变量
var name string
var age byte
var sal float32
var isPass bool
fmt.Println("请输入姓名 ")
//当程序执行到 fmt.Scanln(&name),程序会停止在这里,等待用户输入,并回车
fmt.Scanln(&name)
fmt.Println("请输入年龄 ")
fmt.Scanln(&age)
fmt.Println("请输入薪水 ")
fmt.Scanln(&sal)
fmt.Println("请输入是否通过考试 ")
fmt.Scanln(&isPass)
fmt.Printf("名字是 %v \n 年龄是 %v \n 薪水是 %v \n 是否通过考试 %v \n", name, age, sal, isPass)
}
package main
import (
"fmt"
)
func main() {
//要求:可以从控制台接收用户信息,【姓名,年龄,薪水, 是否通过考试 】。
//方式2:fmt.Scanf,可以按指定的格式输入
fmt.Println("请输入你的姓名,年龄,薪水, 是否通过考试, 使用空格隔开")
fmt.Scanf("%s %d %f %t", &name, &age, &sal, &isPass)
fmt.Printf("名字是 %v \n年龄是 %v \n 薪水是 %v \n 是否通过考试 %v \n", name, age, sal, isPass)
}
五、程序流程控制
5.1 单分支控制
package main
import (
"fmt"
)
func main() {
//请大家看个案例[ifDemo.go]:
//编写一个程序,可以输入人的年龄,如果该同志的年龄大于18岁,则输出 "你年龄大
//于18,要对自己的行为负责!"
//分析
//1.年龄 ==> var age int
//2.从控制台接收一个输入 fmt.Scanln(&age)
//3.if判断
var age int
fmt.Println("请输入年龄:")
fmt.Scanln(&age)
if age > 18 {
fmt.Println("你年龄大于18,要对自己的行为负责!")
}
//golang支持在if中,直接定义一个变量,比如下面
if age := 20; age > 18 {
fmt.Println("你年龄大于18,要对自己的行为负责!")
}
}
5.2 双分支控制
if 条件表达式{
执行代码块1
}else{
执行代码块2
}
package main
import (
"fmt"
)
func main() {
var x int = 4
if x > 2
fmt.Println("ok")
else
fmt.Println("hello")
//编译错误,if没有{}
}
package main
import (
"fmt"
)
func main() {
var x int = 4
if x > 2{
fmt.Println("ok")
}
else{
fmt.Println("hello")
}
//编译错误,else不能换行
}
5.3 多分支控制
if 条件表达式1{
执行代码块1
}else if 条件表达式2{
执行代码块2
}
......
else{
执行代码块n
}
5.4 switch分支控制
1 ) switch 语句用于基于不同条件执行不同动作,每一个 case 分支都是唯一的,从上到下逐一测 试,直到匹配为止。
2 ) 匹配项后面也不需要再加 break
switch 表达式{
case 表达式1,表达式2,..:
语句块1
fallthrough//穿透 如果有这个则会继续执行下面的case
case 表达式3,表达式4,..:
语句块2
...
default://没有任何case匹配 折执行default 不是必须的
语句块
}
使用细节
1 ) case/switch后是一个表达式( 即:常量值、变量、一个有返回值的函数等都可以)
2 ) case后的各个表达式的值的数据类型,必须和 switch 的表达式数据类型一致
package main
import (
"fmt"
)
func main() {
var n1 int32 = 20
var n2 int64 = 20
switch n1 { //错误,原因是n2和n1数据类型不一致
case n2:
fmt.Println("ok1")
default:
fmt.Println("没有匹配到...")
}
}
3 ) case后面可以带多个表达式,使用逗号间隔。比如 case 表达式 1 , 表达式 2 …
package main
import (
"fmt"
)
func main() {
var n1 int32 = 51
var n2 int32 = 20
switch n1 {
case n2, 10, 5 : // case 后面可以有多个表达式
fmt.Println("ok1")
case 90 :
fmt.Println("ok2~")
}
}
4 ) case后面的表达式如果是常量值(字面量),则要求不能重复
package main
import (
"fmt"
)
func main() {
var n1 int32 = 51
var n2 int32 = 20
switch n1 {
case n2, 10, 5 : // case 后面可以有多个表达式
fmt.Println("ok1")
case 5 : //错误,前面已经有常量5了,不能重复
fmt.Println("ok2~")
default:
fmt.Println("没有匹配到...")
}
}
5.) case后面不需要带break, 程序匹配到一个case后就会执行对应的代码块,然后退出switch,如果一个都匹配不到,则执行 default
6 ) default 语句不是必须的.
7 ) switch 后也可以不带表达式,类似 if–else分支来使用。【案例演示】
package main
import (
"fmt"
)
func main() {
//switch 后也可以不带表达式,类似 if --else分支来使用。【案例演示】
var age int = 10
switch {
case age == 10 :
fmt.Println("age == 10")
case age == 20 :
fmt.Println("age == 20")
default :
fmt.Println("没有匹配到")
}
//case 中也可以对 范围进行判断
var score int = 90
switch {
case score > 90 :
fmt.Println("成绩优秀..")
case score >=70 && score <= 90 :
fmt.Println("成绩优良...")
case score >= 60 && score < 70 :
fmt.Println("成绩及格...")
default :
fmt.Println("不及格")
}
}
8 ) switch 后也可以直接声明/定义一个变量,分号结束,不推荐。 【案例演示】
package main
import (
"fmt"
)
func main() {
//switch 后也可以直接声明/定义一个变量,分号结束,不推荐
switch grade := 90; { // 在golang中,可以这样写
case grade > 90 :
fmt.Println("成绩优秀~..")
case grade >=70 && grade <= 90 :
fmt.Println("成绩优良~...")
case grade >= 60 && grade < 70 :
fmt.Println("成绩及格~...")
default :
fmt.Println("不及格~")
}
}
9 ) switch 穿透-fallthrough ,如果在case语句块后增加fallthrough,则会继续执行下一个case,也 叫switch穿透
package main
import (
"fmt"
)
func main() {
//switch 的穿透 fallthrought
var num int = 10
switch num {
case 10:
fmt.Println("ok1")
fallthrough //默认只能穿透一层
case 20:
fmt.Println("ok2")
fallthrough
case 30:
fmt.Println("ok3")
default:
fmt.Println("没有匹配到..")
}
}
10 ) TypeSwitch:switch 语句还可以被用于 type-switch 来判断某个 interface 变量中实际指向的变量类型
package main
import (
"fmt"
)
func main() {
var x interface{}
var y = 10.0
x = y
switch x := x.(type) {
case nil:
fmt.Println("x 的类型:%T",i)
case int:
fmt.Println("x 是int型")
case float64:
fmt.Println("x 是float型")
case func(int) float:
fmt.Println("x 是func(int) float") case bool, string:
fmt.Println("x 是bool 或 string型") default:
fmt.Println("未知型..")
}
}
5.5 for循环
1)基本语法
for 循环变量初始化; 循环条件; 循环变量迭代 {
循环操作(语句)
}
2)for循环的第二种使用方式
for 循环判断条件 {
//循环执行语句
}
将变量初始化和变量迭代写到其它位置
案例演示:
package main
import (
"fmt"
)
func main(){
//for循环的第二种写法
j := 1 //循环变量初始化
for j <= 10 { //循环条件
fmt.Println("你好,Golang Roadmap~", j)
j++ //循环变量迭代
}
}
3 ) for循环的第三种使用方式
for {
//循环执行语句
}
上面的写法等价 for;;{} 是一个无限循环, 通常需要配合 break 语句使用
package main
import (
"fmt"
)
func main(){
//for循环的第三种写法, 这种写法通常会配合break使用
k := 1
for { // 这里也等价 for ; ; {
if k <= 10 {
fmt.Println("你好,Golang Roadmap~", k)
} else {
break //break就是跳出这个for循环
}
k++
}
}
4 ) Golang 提供 for-range的方式,可以方便遍历字符串和数组(注: 数组的遍历,我们放到讲数组 的时候再讲解) ,案例说明如何遍历字符串。 字符串遍历方式 1 - 传统方式
package main
import (
"fmt"
)
func main(){
//字符串遍历方式1-传统方式
var str string = "hello,world!北京"
for i := 0; i < len(str); i++ {
fmt.Printf("%c \n", str[i]) //使用到下标...
}
}
字符串遍历方式 2 - for-range
package main
import (
"fmt"
)
func main(){
//字符串遍历方式2-for-range
str = "abc~ok上海"
for index, val := range str {
fmt.Printf("index=%d, val=%c \n", index, val)
}
}
如果我们的字符串含有中文,那么传统的遍历字符串方式,就是错误,会出现乱码。原因是传统的对字符串的遍历是按照字节来遍历,而一个汉字在utf 8 编码是对应 3 个字节。
如何解决 需要要将 str 转成 []rune切片
package main
import (
"fmt"
)
func main(){
//字符串遍历方式1-传统方式
var str string = "hello,world!北京"
str2 := []rune(str) // 就是把 str 转成 []rune
for i := 0; i < len(str2); i++ {
fmt.Printf("%c \n", str2[i]) //使用到下标...
}
}
对应for-range遍历方式而言,是按照字符方式遍历。因此如果有字符串有中文,也是ok
5.6 WHILE和DO…WHILE的实现
Go语言没有while和do…while语法,这一点需要同学们注意一下,如果我们需要使用类似其它语言(比如 java/c 的 while 和 do…while),可以通过 for 循环来实现其使用效果。
while循环的实现
循环变量初始化
for{
if循环条件表达式{
break//跳出for循环
}
循环操作语句
循环变量迭代
}
说明上图
1 ) for循环是一个无限循环
2 ) break 语句就是跳出for循环
使用上面的while实现完成输出 10 句”hello,wrold”
package main
import "fmt"
func main(){
//使用while方式输出10句 "hello,world"
//循环变量初始化
var i int = 1
for {
if i > 10 { //循环条件
break // 跳出for循环,结束for循环
}
fmt.Println("hello,world", i)
i++ //循环变量的迭代
}
fmt.Println("i=", i)
}
do…while的实现
循环变量初始化
for{
循环操作语句
循环变量迭代
if循环条件表达式{
break//跳出for循环
}
}
对上图的说明
1 ) 上面的循环是先执行,在判断,因此至少执行一次。
2 ) 当循环条件成立后,就会执行break,break就是跳出for循环,结束循环.
六、函数、包和错误处理
6.1 函数概念
不用函数的弊端
1)写法可以完成功能, 但是代码冗余
2 ) 同时不利于代码维护
概念:为完成某一功能的程序指令(语句)的集合,称为函数。
在Go中,函数分为: 自定义函数、系统函数
基本语法
//函数的基本语法
func 函数名(形参列表)(返回值列表){ // 形参名在前 形参类型在后
执行语句..
return 返回值列表
}
- 形参列表:表示函数的输入
- 函数中的语句:表示为了实现某一功能代码块
- 函数可以有返回值,也可以没有
案例
package main
import (
"fmt"
)
func cal(n1 float64, n2 float64, operator byte) float64 {
var res float64
switch operator {
case '+':
res = n1 + n2
case '-':
res = n1 - n2
case '*':
res = n1 * n2
case '/':
res = n1 / n2
default:
fmt.Println("操作符号错误...")
}
return res
}
func main() {
//请大家完成这样一个需求:
//输入两个数,再输入一个运算符(+,-,*,/),得到结果.。
//分析思路....
var n1 float64 = 1.2
var n2 float64 = 2.3
var operator byte = '+'
result := cal(n1, n2 , operator)
fmt.Println("result~=", result)
}
6.2 包的概念
包的本质实际上就是创建不同的文件夹,来存放程序文件。
说明:go的每一个文件都是属于一个包的,也就是说go是以包的形式来管理文件和项目目录结构的
包的三大作用
- 区分相同名字的函数、变量等标识符
- 当程序文件很多时,可以很好的管理项目
- 控制函数、变量等访问范围,即作用域
打包基本语法
package 包名
引入包的基本语法
import"包的路径"
注意事项
1 ) 在给一个文件打包时,该包对应一个文件夹,比如这里的 utils 文件夹对应的包名就是utils,文件的包名通常和文件所在的文件夹名一致,一般为小写字母。
2 ) 当一个文件要使用其它包函数或变量时,需要先引入对应的包
-
引入方式 1 :import “包名”
-
引入方式 2 :
import ( "包名" "包名" ) -
package 指令在 文件第一行,然后是 import 指令。
-
在import 包时,路径从 $GOPATH的 src 下开始,不用带src, 编译器会自动从src下开始引入
3 ) 为了让其它包的文件,可以访问到本包的函数,则该函数名的首字母需要大写,类似其它语言的public,这样才能跨包访问。比如 utils.go 的
//为了让其它包的文件使用Cal函数,需要将C大小类似其它语言的public
func Cal(n1 float64, n2 float64, operator byte) float64 {....
4 ) 在访问其它包函数,变量时,其语法是 包名.函数名, 比如这里的 main.go文件中
utils.Cal(n1, n2 , operator)
5 ) 如果包名较长,Go支持给包取别名, 注意细节:取别名后,原来的包名就不能使用了
package main
import (
"fmt"
util "go_code/chapter06/fundemo01/utils"
)
说明: 如果给包取了别名,则需要使用别名来访问该包的函数和变量。
6.) 在同一包下,不能有相同的函数名(也不能有相同的全局变量名),否则报重复定义
7 ) 如果你要编译成一个可执行程序文件,就需要将这个包声明为 main, 即 packagemain.这个就 是一个语法规范,如果你是写一个库 ,包名可以自定义
6.3 函数的调用机制
( 1 ) 在调用一个函数时,会给该函数分配一个新的空间,编译器会通过自身的处理让这个新的空间和其它的栈的空间区分开来
( 2 ) 在每个函数对应的栈中,数据空间是独立的,不会混淆
( 3 ) 当一个函数调用完毕(执行完毕)后,程序会销毁这个函数对应的栈空间。
6.4 return
基本语法和说明
// Go函数支持返回多个值,这一点是其他编程语言没有的
func 函数名(形参列表)(返回值类型列表){
语句
return 返回值列表
}
1.如果返回多个值,在接收时,希望忽略某个返回值,则使用_符号表示占位忽略
2.如果返回值只有一个,返回值类型列表可以不写()
6.5 函数递归调用
一个函数在函数体内又调用了本身,我们称为递归调用
函数递归需要遵守的重要原则:
1 ) 执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
2 ) 函数的局部变量是独立的,不会相互影响
3 ) 递归必须向退出递归的条件逼近,否则就是无限递归,死龟了:)
4 ) 当一个函数执行完毕,或者遇到return,就会返回,遵守谁调用,就将结果返回给谁,同时当函数执行完毕或者返回时,该函数本身也会被系统销毁
题 1 :斐波那契数
请使用递归的方式,求出斐波那契数 1 , 1 , 2 , 3 , 5 , 8 , 13
给你一个整数n,求出它的斐波那契数是多少?
package main
import (
"fmt"
)
/*
请使用递归的方式,求出斐波那契数1,1,2,3,5,8,13...
给你一个整数n,求出它的斐波那契数是多少?
*/
func fbn(n int) int {
if (n == 1 || n == 2) {
return 1
} else {
return fbn(n - 1) + fbn(n - 2)
}
}
func main() {
res := fbn(3)
//测试
fmt.Println("res=", res)
fmt.Println("res=", fbn(4)) // 3
fmt.Println("res=", fbn(5)) // 5
fmt.Println("res=", fbn(6)) // 8
}
6.6 函数注意事项
1 ) 函数的形参列表可以是多个,返回值列表也可以是多个。
2 ) 形参列表和返回值列表的数据类型可以是值类型和引用类型。
3 ) 函数的命名遵循标识符命名规范,首字母不能是数字,首字母大写该函数可以被本包文件和其它包文件使用,类似public, 首字母小写,只能被本包文件使用,其它包文件不能使用,类似privat
4 ) 函数中的变量是局部的,函数外不生效
package main
import (
"fmt"
)
//函数中的变量是局部的,函数外不生效
func test(){
//n1 是 test函数的局部变量,只能在test中使用
var n1 int = 10
}
func main() {
fmt.Println("n1=", n1) //报错,这里不能使用n1
}
5 ) 基本数据类型和数组默认都是值传递的,即进行值拷贝。在函数内修改,不会影响到原来的值。
package main
import (
"fmt"
)
func test02(n1 int){
n1 = n1 + 10
fmt.Println("test02() n1=", n1)
}
func main() {
num := 20
test02(num)
fmt.Println("main() num=", num)
}
6.) 如果希望函数内的变量能修改函数外的变量(指的是默认以值传递的方式的数据类型),可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用 。
package main
import (
"fmt"
)
// n1 就是 *int 类型
func test03(n1 *int) {
fmt.Printf("n1的地址 %v\n",&n1)
*n1 = *n1 + 10
fmt.Println("test03() n1= ", *n1) // 30
}
func main() {
num := 20
fmt.Printf("num的地址=%v\n", &num)
test03(&num)
fmt.Println("main() num= ", num) // 30
}
7 ) Go函数不支持函数重载
package main
import (
"fmt"
)
//有两个test02不支持重载
func test02(n1 int) {
n1 = n1 + 10
fmt.Println("test02() n1= ", n1)
}
//有两个test02不支持重载
func test02(n1 int , n2 int) {
}
func main() {
}
8 ) 在Go中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
package main
import (
"fmt"
)
//在Go中,函数也是一种数据类型,
//可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
func getSum(n1 int, n2 int) int {
return n1 + n2
}
func main() {
a := getSum
fmt.Printf("a的类型%T, getSum类型是%T\n", a, getSum)
res := a(10, 40) // 等价 res := getSum(10, 40)
fmt.Println("res=", res)
}
9 ) 函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
package main
import (
"fmt"
)
//在Go中,函数也是一种数据类型,
//可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
func getSum(n1 int, n2 int) int {
return n1 + n2
}
//函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
func myFun(funvar func(int, int) int, num1 int, num2 int ) int {
return funvar(num1, num2)
}
func main() {
//看案例
res2 := myFun(getSum, 50, 60)
fmt.Println("res2=", res2)
}
10 ) 为了简化数据类型定义,Go支持自定义数据类型
基本语法:type 自定义数据类型名 数据类型 // 理解: 相当于一个别名
package main
import (
"fmt"
)
//在Go中,函数也是一种数据类型,
//可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数调用
func getSum(n1 int, n2 int) int {
return n1 + n2
}
//函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
func myFun(funvar func(int, int) int, num1 int, num2 int ) int {
return funvar(num1, num2)
}
//再加一个案例
//这时 myFun 就是 func(int, int) int类型
type myFunType func(int, int) int
//函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
func myFun2(funvar myFunType, num1 int, num2 int ) int {
return funvar(num1, num2)
}
func main() {
// 给int取了别名 , 在go中 myInt 和 int 虽然都是int类型,但是go认为myInt和int两个类型
type myInt int
var num1 myInt //
var num2 int
num1 = 40
num2 = int(num1) //各位,注意这里依然需要显示转换,go认为myInt和int两个类型
fmt.Println("num1=", num1, "num2=",num2)
//看案例
res3 := myFun2(getSum, 500, 600)
fmt.Println("res3=", res3)
}
11 )支持对函数返回值命名
package main
import (
"fmt"
)
//支持对函数返回值命名
func getSumAndSub(n1 int, n2 int) (sum int, sub int){
sub = n1 - n2
sum = n1 + n2
return
}
func main() {
//看案例
a1, b1 := getSumAndSub(1, 2)
fmt.Printf("a=%v b=%v\n", a1, b1)
}
12 ) 使用 _ 标识符,忽略返回值
13 ) Go支持可变参数
//支持0到多个参数
func sum(args...int){
}
//支持1到多个参数
func sum(n1 int,args... int) sum int{
}
说明:
- args是slice切片,通过args[index]可以访问到各个值
- 案例演示:编写一个函数sum,可以求出1到多个int的和
- 如果一个函数的形参列表中有可变的参数,则可变参数需要放到形参列表的最后
6.7 init()函数
每一个源文件都可以包含一个 init 函数,该函数会在main函数执行前,被Go运行框架调用,也 就是说init会在main函数前被调用。
package main
import (
"fmt"
)
func init() {
fmt.Println("init()")
}
func main() {
fmt.Println("main()")
}
输出的结果是:
init()
main()
注意事项
1 ) 如果一个文件同时包含全局变量定义, init 函数和 main 函数,则执行的流程全局变量定义 - >init函数 - >main 函数
package main
import (
"fmt"
)
var age = test()
//为了看到全局变量是先被初始化的,我们这里先写函数
func test() int {
fmt.Println("test()")//1
return 90
}
// init函数,通常可以在init函数中完成初始化工作
func init() {
fmt.Println("init()")//2
}
func main() {
fmt.Println("main()...age=",age)//3
}
2 ) init函数最主要的作用,就是完成一些初始化的工作
package utils
import "fmt"
var Age int
var Name string
//Age 和 Name 全局变量,我们需要在main.go 使用
//但是我们需要初始化Age 和 Name
//init 函数完成初始化工作
func init() {
fmt.Println("utils 包的 init()...")
Age = 100
Name = "tom~"
}
3 ) 细节说明: 面试题:案例如果main.go 和 utils.go 都含有 变量定义,init函数时,执行的流程又是怎么样的呢?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uy8nemEv-1669084586574)(C:\Users\ZHAI\AppData\Roaming\Typora\typora-user-images\image-20221114155116255.png)]
6.8 匿名函数
Go支持匿名函数,匿名函数就是没有名字的函数,如果我们某个函数只是希望使用一次,可以考 虑使用匿名函数,匿名函数也可以实现多次调用。
匿名函数使用方式 1
在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次。 【案例演示】
package main
import (
"fmt"
)
func main() {
//在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次
//案例演示,求两个数的和, 使用匿名函数的方式完成
res1 := func (n1 int, n2 int) int {
return n1 + n2
}(10, 20)
fmt.Println("res1=", res1)
}
匿名函数使用方式 2
将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
package main
import (
"fmt"
)
func main() {
//将匿名函数func (n1 int, n2 int) int赋给 a变量
//则a 的数据类型就是函数类型 ,此时,我们可以通过a完成调用
a := func (n1 int, n2 int) int {
return n1 - n2
}
res2 := a(10, 30)
fmt.Println("res2=", res2)
res3 := a(90, 30)
fmt.Println("res3=", res3)
}
全局匿名函数
如果将匿名函数赋给一个全局变量,那么这个匿名函数,就成为一个全局匿名函数,可以在程序有效。
package main
import (
"fmt"
)
var (
//fun1就是一个全局匿名函数
Fun1 = func (n1 int, n2 int) int {
return n1 * n2
}
)
func main() {
//全局匿名函数的使用
res4 := Fun1(4, 9)
fmt.Println("res4=", res4)
}
6.9 **闭包
基本介绍:闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
闭包让你可以在一个内层函数中访问到其外层函数的作用域。
可简单理解为:有权访问另一个函数作用域内变量的函数都是闭包。
package main
import (
"fmt"
)
//累加器
func AddUpper() func (int) int {
var n int = 10
return func (x int) int {
n = n + x
return n
}
}
func main() {
//使用前面的代码
f := AddUpper()
fmt.Println(f(1))// 11
fmt.Println(f(2))// 13
fmt.Println(f(3))// 16
}
对上面代码的说明和总结
1 ) AddUpper 是一个函数,返回的数据类型是 fun(int)int
2 ) 闭包的说明
var n int = 10
return func (x int) int {
n = n + x
return n
}
返回的是一个匿名函数, 但是这个匿名函数引用到函数外的n,因此这个匿名函数就和n形成一个整体,构成闭包。
6.9.1使用案例
1 ) 编写一个函数 makeSuffix(suffixstring) 可以接收一个文件后缀名(比如.jpg),并返回一个闭包
2 ) 调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg),则返回 文件名.jpg, 如果已经有.jpg后缀,则返回原文件名。
3 ) 要求使用闭包的方式完成
4 ) strings.HasSuffix, 该函数可以判断某个字符串是否有指定的后缀。
package main
import (
"fmt"
"strings"
)
//
// 1)编写一个函数 makeSuffix(suffix string) 可以接收一个文件后缀名(比如.jpg),并返回一个闭包
// 2)调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg) ,则返回 文件名.jpg , 如果已经有.jpg后缀,则返回原文件名。
// 3)要求使用闭包的方式完成
// 4)strings.HasSuffix , 该函数可以判断某个字符串是否有指定的后缀。
func makeSuffix(suffix string) func (string) string {
return func (name string) string {
//如果 name 没有指定后缀,则加上,否则就返回原来的名字
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func makeSuffix2(suffix string, name string) string {
//如果 name 没有指定后缀,则加上,否则就返回原来的名字
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
func main() {
//测试makeSuffix 的使用
//返回一个闭包
f2 := makeSuffix(".jpg") //如果使用闭包完成,好处是只需要传入一次后缀。
fmt.Println("文件名处理后=", f2("winter")) // winter.jgp
fmt.Println("文件名处理后=", f2("bird.jpg")) // bird.jpg
fmt.Println("文件名处理后=", makeSuffix2("jpg", "winter")) // winter.jgp
fmt.Println("文件名处理后=", makeSuffix2("jpg", "bird.jpg")) // bird.jpg
}
上面代码的总结和说明:
1 ) 返回的匿名函数和 makeSuffix(suffixstring) 的 suffix 变量 组合成一个闭包,因为 返回的函数引用到suffix这个变量
2 ) 我们体会一下闭包的好处,如果使用传统的方法,也可以轻松实现这个功能,但是传统方法需要每次都传入 后缀名,比如 .jpg,而闭包因为可以保留上次引用的某个值,所以我们传入一次就可以反复使用。(以面向对象思想理解闭包----------外部整体 像一个类,先传入的.jpg 像设置类里的一个public属性,再向返回函数传参 像调用类的成员函数,此时成员函数可以调用类里已设置的属性。)
6.9.2 闭包经典使用场景
1、return一个内部函数,读取内部函数的变量;
2、函数作为参数
3、IIFE(自执行函数)
5、使用回调函数就是在使用闭包
6、将外部函数创建的变量值始终保持在内存中;(会出现内存泄漏)
6.9.3 使用闭包注意点
因为使用闭包会包含其他函数的作用域,会比其他函数占据更多的内存空间,不会在调用结束之后被垃圾回收机制(简称GC机制)回收,多度使用闭包会过度占用内存,造成内存泄漏。
6.9.4 闭包相关面试题
1、简述什么是闭包,闭包的作用是什么?写出一个简单的闭包例子。
2、闭包会造成内存泄漏吗?
会,因为使用闭包会包含其他函数的作用域,会比其他函数占据更多的内存空间,不会在调用结束之后被垃圾回收机制回收,多度使用闭包会过度占用内存,造成内存泄漏。
3、for循环和闭包(必刷题)
6.10 defer
在函数中,程序员经常需要创建资源(比如:数据库连接、文件句柄、锁等) ,为了在函数执行完毕后,及时的释放资源,Go的设计者提供defer(延时机制)。defer 最主要的价值是在,当函数执行完毕后,可以及时的释放函数创建的资源。看下模拟代码。
package main
import (
"fmt"
)
func sum(n1 int, n2 int) int {
//当执行到defer时,暂时不执行,会将defer后面的语句压入到独立的栈(defer栈)
//当函数执行完毕后,再从defer栈,按照先入后出的方式出栈,执行
defer fmt.Println("ok1 n1=", n1) //defer 3. ok1 n1 = 10
defer fmt.Println("ok2 n2=", n2) //defer 2. ok2 n2= 20
res := n1 + n2 // res = 30
fmt.Println("ok3 res=", res) // 1. ok3 res= 30
return res
}
func main() {
res := sum(10, 20)
fmt.Println("res=", res) // 4. res= 30
}
执行后,输出的结果:
ok3 res= 30
ok2 n2= 20
ok1 n1 = 10
res= 30
注意事项
1 ) 当go执行到一个defer时,不会立即执行defer后的语句,而是将defer 后的语句压入到一个栈中[我为了讲课方便,暂时称该栈为defer栈],然后继续执行函数下一个语句。
2 ) 当函数执行完毕后,在从defer栈中,依次从栈顶取出语句执行(注:遵守栈 先入后出的机制),所以同学们看到前面案例输出的顺序。
3 ) 在defer 将语句放入到栈时,也会将相关的值拷贝同时入栈。
defer使用
1 ) 在golang编程中的通常做法是,创建资源后,比如(打开了文件,获取了数据库的链接,或者是锁资源), 可以执行 defer file.Close() defer connect.Close()
2 ) 在defer后,可以继续使用创建资源.
3 ) 当函数完毕后,系统会依次从defer栈中,取出语句,关闭资源.
4 ) 这种机制,非常简洁,程序员不用再为在什么时机关闭资源而烦心。
6.11 函数传递方式
传递方式分类
1 ) 值传递
2 ) 引用传递
其实,不管是值传递还是引用传递,传递给函数的都是变量的副本,不同的是,值传递的是值的拷贝,引用传递的是地址的拷贝,一般来说,地址拷贝效率高,因为数据量小,而值拷贝决定拷贝的数据大小,数据越大,效率越低。
值类型和引用类型
1 ) 值类型:基本数据类型 int 系列,float 系列,bool,string 、数组和结构体struct
2 ) 引用类型:指针、slice切片、map、管道chan、interface 等都是引用类型
各自的特点
1 ) 值类型默认是值传递:变量直接存储值,内存通常在栈中分配。
2 ) 引用类型默认是引用传递:变量存储的是一个地址,这个地址对应的空间才真正存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,改地址对应的数据空间就成为一个垃圾,由GC来回收。

3 ) 如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用 。
6.12 变量作用域
1 ) 函数内部声明/定义的变量叫局部变量,作用域仅限于函数内部
2 ) 函数外部声明/定义的变量叫全局变量,作用域在整个包都有效,如果其首字母为大写,则作用域在整个程序有效
3 ) 如果变量是在一个代码块,比如 for/if中,那么这个变量的的作用域就在该代码块
6.13 字符串常用系统函数
1 ) 统计字符串的长度,按字节 len(str)
2 ) 字符串遍历,同时处理有中文的问题 r:=[]rune(str)
3 ) 字符串转整数: n,err:=strconv.Atoi(" 12 ")
4 ) 整数转字符串 str=strconv.Itoa( 12345 )
5 ) 字符串 转 []byte: varbytes=[]byte(“hello go”)
6.) []byte 转 字符串:str=string([]byte{ 97 , 98 , 99 })
7 ) 10 进制转 2 , 8 , 16.进制: str=strconv.FormatInt( 123 , 2 )// 2 - > 8 , 16
8 ) 查找子串是否在指定的字符串中:strings.Contains(“seafood”,“foo”)//true
9 ) 统计一个字符串有几个指定的子串 : strings.Count(“ceheese”,“e”)// 4
10 ) 不区分大小写的字符串比较(==是区分字母大小写的):fmt.Println(strings.EqualFold(“abc”,“Abc”))//true
11 )返回子串在字符串第一次出现的index值,如果没有返回- 1 :strings.Index(“NLT_abc”,“abc”)// 4
12 ) 返回子串在字符串最后一次出现的index,如没有返回- 1 :strings.LastIndex(“gogolang”,“go”)
13 ) 将指定的子串替换成 另外一个子串:strings.Replace(“gogohello”,“go”,“go语言”,n)n可以指定你希望替换几个,如果n=- 1 表示全部替换
14 ) 按照指定的某个字符,为分割标识,将一个字符串拆分成字符串数组:strings.Split(“hello,wrold,ok”,“,”)
15 ) 将字符串的字母进行大小写的转换:strings.ToLower(“Go”)//gostrings.ToUpper(“Go”)//GO
16.) 将字符串左右两边的空格去掉: strings.TrimSpace("tnalonegopherntrn ")
17 ) 将字符串左右两边指定的字符去掉 : strings.Trim(“!hello!”,“!”) //[“hello”]//将左右两边! 和 ""去掉
18 ) 将字符串左边指定的字符去掉 : strings.TrimLeft(“!hello!”,“!”) //[“hello”]//将左边! 和 " "去掉
19 ) 将字符串右边指定的字符去掉 :strings.TrimRight(“!hello!”,“!”) //[“hello”]//将右边! 和 " "去掉
20 ) 判断字符串是否以指定的字符串开头:strings.HasPrefix("ftp:// 192. 168. 10. 1 ",“ftp”)//true
21 ) 判断字符串是否以指定的字符串结束:strings.HasSuffix(“NLT_abc.jpg”,“abc”)//false
6.14 时间和日期相关函数
1 ) 时间和日期相关函数,需要导入 time包
2 ) time.Time 类型,用于表示时间
package main
import (
"fmt"
"time"
)
func main() {
//看看日期和时间相关函数和方法使用
//1. 获取当前时间
now := time.Now()
fmt.Printf("now=%v now type=%T\n", now, now)
}
3 ) 如何获取到部分的日期信息
package main
import (
"fmt"
"time"
)
func main() {
//看看日期和时间相关函数和方法使用
//1. 获取当前时间
now := time.Now()
fmt.Printf("now=%v now type=%T\n", now, now)
//2.通过now可以获取到年月日,时分秒
fmt.Printf("年=%v\n", now.Year())
fmt.Printf("月=%v\n", now.Month())
fmt.Printf("月=%v\n", int(now.Month()))
fmt.Printf("日=%v\n", now.Day())
fmt.Printf("时=%v\n", now.Hour())
fmt.Printf("分=%v\n", now.Minute())
fmt.Printf("秒=%v\n", now.Second())
}
4 ) 格式化日期时间
方式 1 : 就是使用Printf 或者 SPrintf
package main
import (
"fmt"
"time"
)
func main() {
//格式化日期时间
fmt.Printf("当前年月日 %d-%d-%d %d:%d:%d \n", now.Year(),
now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())
dateStr := fmt.Sprintf("当前年月日 %d-%d-%d %d:%d:%d \n", now.Year(),
now.Month(), now.Day(), now.Hour(), now.Minute(), now.Second())
fmt.Printf("dateStr=%v\n", dateStr)
}
方式二: 使用 time.Format() 方法完成:
package main
import (
"fmt"
"time"
)
func main() {
//格式化日期时间的第二种方式
fmt.Printf(now.Format("2006-01-02 15:04:05"))
fmt.Println()
fmt.Printf(now.Format("2006-01-02"))
fmt.Println()
fmt.Printf(now.Format("15:04:05"))
fmt.Println()
fmt.Printf(now.Format("2006"))
fmt.Println()
}
5 ) 时间的常量
const(
Nanosecond Duration= 1 //纳秒
Microsecond = 1000 *Nanosecond //微秒
Millisecond = 1000 *Microsecond//毫秒
Second = 1000 *Millisecond//秒
Minute = 60 *Second//分钟
Hour = 60 *Minute//小时
)
常量的作用:在程序中可用于获取指定时间单位的时间,比如想得到 100 毫秒
100 *time.Millisecond
7 ) time的Unix和UnixNano的方法

编写一段代码来统计 函数test 03 执行的时间
package main
import (
"fmt"
"time"
"strconv"
)
func test03() {
str := ""
for i := 0; i < 100000; i++ {
str += "hello" + strconv.Itoa(i)
}
}
func main() {
//在执行test03前,先获取到当前的unix时间戳
start := time.Now().Unix()
test03()
end := time.Now().Unix()
fmt.Printf("执行test03()耗费时间为%v秒\n", end-start)
}
6.15 系统函数
1 ) len:用来求长度,比如string、array、slice、map、channel
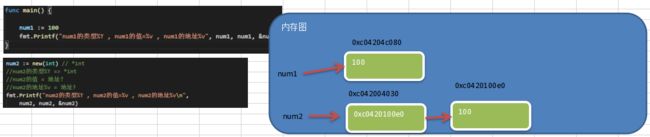
2 ) new:用来分配内存,主要用来分配值类型,比如int、float 32 ,struct返回的是指针
package main
import (
"fmt"
)
func main() {
num1 := 100
fmt.Printf("num1的类型%T , num1的值=%v , num1的地址%v\n", num1, num1, &num1)
num2 := new(int) // *int
//num2的类型%T => *int
//num2的值 = 地址 0xc04204c098 (这个地址是系统分配)
//num2的地址%v = 地址 0xc04206a020 (这个地址是系统分配)
//num2指向的值 = 100
*num2 = 100
fmt.Printf("num2的类型%T , num2的值=%v , num2的地址%v\n num2这个指针,指向的值=%v",
num2, num2, &num2, *num2)
}
上面代码对应的内存分析图:
3 ) make:用来分配内存,主要用来分配引用类型,比如channel、map、slice。
6.16 错误处理
1 ) 在默认情况下,当发生错误后(panic),程序就会退出(崩溃.)
2 ) 如果我们希望:当发生错误后,可以捕获到错误,并进行处理,保证程序可以继续执行。还可以在捕获到错误后,给管理员一个提示(邮件,短信。。。)
基本说明
1 ) Go语言追求简洁优雅,所以,Go语言不支持传统的 trycatchfinally 这种处理。
2 ) Go中引入的处理方式为: defer , panic , recover
3 ) 这几个异常的使用场景可以这么简单描述:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理
package main
import (
"fmt"
"time"
)
func test() {
//使用defer + recover 来捕获和处理异常
defer func() {
err := recover() // recover()内置函数,可以捕获到异常
if err != nil { // 说明捕获到错误
fmt.Println("err=", err)
}
}()
num1 := 10
num2 := 0
res := num1 / num2
fmt.Println("res=", res)
}
func main() {
//测试
test()
for {
fmt.Println("main()下面的代码...")
time.Sleep(time.Second)
}
}
自定义错误
Go程序中,也支持自定义错误, 使用errors.New 和 panic 内置函数。
1 ) errors.New(“错误说明”), 会返回一个error类型的值,表示一个错误
2 ) panic内置函数 ,接收一个interface{}类型的值(也就是任何值了)作为参数。可以接收error类型的变量,输出错误信息,并退出程序.
package main
import (
"fmt"
_ "time"
"errors"
)
//函数去读取以配置文件init.conf的信息
//如果文件名传入不正确,我们就返回一个自定义的错误
func readConf(name string) (err error) {
if name == "config.ini" {
//读取...
return nil
} else {
//返回一个自定义错误
return errors.New("读取文件错误..")
}
}
func test02() {
err := readConf("config2.ini")
if err != nil {
//如果读取文件发送错误,就输出这个错误,并终止程序
panic(err)
}
fmt.Println("test02()继续执行....")
}
func main() {
//测试自定义错误的使用
test02()
fmt.Println("main()下面的代码...")
}
七、数组和切片
数组可以存放多个同一类型数据。数组也是一种数据类型,在Go中,数组是值类型。
7.1 数组的定义
var 数组名 [数组大小]数据类型
var a [5]int// 数组名 [长度]数据类型
赋初值 a[0]= 1 a[1]= 30 .
7.2 数组在内存布局(*)数组地址连续
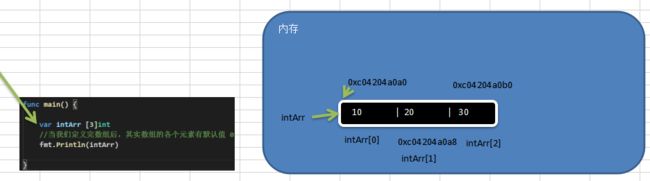
对上图的总结:
1 ) 数组的地址可以通过数组名来获取 &intArr
2 ) 数组的第一个元素的地址,就是数组的首地址
3 ) 数组的各个元素的地址间隔是依据数组的类型决定,比如int 64 - > 8 int 32 - > 4
7.3 初始化数组的方式
package main
import (
"fmt"
)
func main() {
//初始化数组的方式
var numArr01 [3]int = [3]int{1, 2, 3}
fmt.Println("numArr01=", numArr01)
var numArr02 = [3]int{5, 6, 7}
fmt.Println("numArr02=", numArr02)
//这里的 [...] 是规定的写法由go推导数组大小
var numArr03 = [...]int{8, 9, 10}
fmt.Println("numArr03=", numArr03)
var numArr04 = [...]int{1: 800, 0: 900, 2:999}
fmt.Println("numArr04=", numArr04)
f := [...] int{0: 1, 4: 1, 9: 1} // [1 0 0 0 1 0 0 0 0 1]
fmt.Println(f)
e := [5] int{4: 100} // [0 0 0 0 100]
fmt.Println(e)
//类型推导
strArr05 := [...]string{1: "tom", 0: "jack", 2:"mary"}
fmt.Println("strArr05=", strArr05)
}
7.4 数组遍历
1)方式1:for(;;;)遍历数组
2)方式2:for-range结构遍历
for index,value :=range array01{
}
1.index数组的下标
2.value该下标对应的值
3.他们都是for循环内可见的局部变量
4.如果不想使用下标index,可以替换为"_"
5.index和value的名称不是固定的。可以自己改变
for-range的案例
package main
import (
"fmt"
)
func main() {
//演示for-range遍历数组
heroes := [...]string{"宋江", "吴用", "卢俊义"}
//使用常规的方式遍历,我不写了..
for i, v := range heroes {
fmt.Printf("i=%v v=%v\n", i , v)
fmt.Printf("heroes[%d]=%v\n", i, heroes[i])
}
for _, v := range heroes {
fmt.Printf("元素的值=%v\n", v)
}
}
7.5 数组使用注意事项
1 ) 数组是多个相同类型数据的组合,一个数组一旦声明/定义了,其长度是固定的, 不能动态变化。否则报越界
2 ) 数组中的元素可以是任何数据类型,包括值类型和引用类型,但是不能混用。
3 ) 数组创建后,如果没有赋值,有默认值(零值)
- 数值类型数组:默认值为 0
- 字符串数组: 默认值为 “”
- bool数组: 默认值为 false
5 ) 使用数组的步骤 1. 声明数组并开辟空间 2 给数组各个元素赋值(默认零值) 3 使用数组
6 ) Go的数组属值类型, 在默认情况下是值传递, 因此会进行值拷贝。数组间不会相互影响
7 ) 如想在其它函数中,去修改原来的数组,可以使用引用传递(指针方式)
package main
import (
"fmt"
)
//函数
func test02(arr *[3]int) {
fmt.Printf("arr指针的地址=%p", &arr)
(*arr)[0] = 88 //!!
}
func main() {
arr := [3]int{11, 22, 33}
fmt.Printf("arr 的地址=%p", &arr)
test02(&arr)
fmt.Println("main arr=", arr)
}
10 ) 长度是数组类型的一部分,在传递函数参数时 需要考虑数组的长度,看下面案例
//题1
package main
import (
"fmt"
)
//默认值拷贝
func modify(arr []int) {
arr[0] = 100
fmt.Println("modify的arr",arr)
}
func main() {
var arr = [...]int{1,2,3}
modify(arr)
}
//编译错误,因为不能把[3]int 传递给[]int
//题2
package main
import (
"fmt"
)
//默认值拷贝
func modify(arr [4]int) {
arr[0] = 100
fmt.Println("modify的arr",arr)
}
func main() {
var arr = [...]int{1,2,3}
modify(arr)
}
//编译错误,因为不能把[3]int 传递给[4]int
7.6 切片的定义
1 ) 切片的英文是slice
2 ) 切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵守引用传递的机制。
3 ) 切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度len(slice)都一样。
4 ) 切片的长度是可以变化的,因此切片是一个可以动态变化数组。
5 ) 切片定义的基本语法:
var 切片名 []类型
//比如:vara[]int
package main
import (
"fmt"
)
func main() {
//演示切片的基本使用
var intArr [5]int = [...]int{1, 22, 33, 66, 99}
//声明/定义一个切片
//slice := intArr[1:3]
//1. slice 就是切片名
//2. intArr[1:3] 表示 slice 引用到intArr这个数组
//3. 引用intArr数组的起始下标为 1 , 最后的下标为3(但是不包含3)
slice := intArr[1:3]
fmt.Println("intArr=", intArr) //[1 22 33 66 99]
fmt.Println("slice 的元素是 =", slice) // 22, 33
fmt.Println("slice 的元素个数 =", len(slice)) // 2
fmt.Println("slice 的容量 =", cap(slice)) //4 切片的容量是可以动态变化
}
7.7 切片的内存形式
我们画图分析一下切片在内存中是如何布局的,这个是一个非常重要的知识点:(以前面的案例来分析)

1 .slice的确是一个引用类型
2 .slice 从底层来说,其实就是一个数据结构(struct结构体)
type slice struct{
ptr *[ 2 ]int
len int
cap int
}
7.8 切片的使用
- 方式 1
第一种方式:定义一个切片,然后让切片去引用一个已经创建好的数组,比如前面的案例就是这样的。
- 方式 2
第二种方式:通过 make 来创建切片.
基本语法:
var 切片名 []type = make([]type,len,[cap])
参数说明:type: 就是数据类型 len: 大小 cap :指定切片容量,可选,如果你分配了 cap, 则要求 cap>=len.
案例演示:
package main
import (
"fmt"
)
func main() {
var slice []float64 = make([]float64, 5, 10)
slice[1] = 10
slice[3] = 20
fmt.Println(slice)
fmt.Println("slice的size=", len(slice))
fmt.Println("slice的cap=", cap(slice))
}
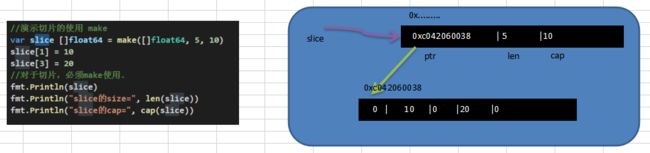
对上面代码的小结:
1 ) 通过make方式创建切片可以指定切片的大小和容量
2 ) 如果没有给切片的各个元素赋值,那么就会使用默认值[int,float=> 0 string=>”” bool=> false]
3 ) 通过make方式创建的切片对应的数组是由make底层维护,对外不可见,即只能通过slice去访问各个元素.
- 方式 3
第 3 种方式:定义一个切片,直接就指定具体数组,使用原理类似make的方式
案例演示:
package main
import (
"fmt"
)
func main() {
var strSlice []string = []string{"tom", "jack", "mary"}
fmt.Println("strSlice=", strSlice)
fmt.Println("strSlice的size=", len(strSlice))
fmt.Println("strSlice的cap=", cap(strSlice))
}
方式 1 和方式 2 的区别**(面试)**
方式1是直接引用数组,这个数组是事先存在的,程序员是可见的
方式2是通过make来创建切片,make也会创建一个数组,是由切片在底层进行维护,程序员是看不见的。make创建切片的示意图:
7.9 切片使用注意事项
1)从数组引用切片规则左闭合右开,即
切片初始化时 varslice=arr[startIndex:endIndex]
从arr数组下标为startIndex,取到 下标为endIndex的元素(不含arr[endIndex])。
2 ) 切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者make一 个空间供切片来使用
3 ) 切片可以继续切片
4 ) 用append内置函数,可以对切片进行动态追加
package main
import (
"fmt"
)
func main() {
//使用常规的for循环遍历切片
var arr [5]int = [...]int{10, 20, 30, 40, 50}
//slice := arr[1:4] // 20, 30, 40
slice := arr[1:4]
for i := 0; i < len(slice); i++ {
fmt.Printf("slice[%v]=%v ", i, slice[i])
}
fmt.Println()
//使用for--range 方式遍历切片
for i, v := range slice {
fmt.Printf("i=%v v=%v \n", i, v)
}
slice2 := slice[1:2] // slice [ 20, 30, 40] [30]
slice2[0] = 100 // 因为arr , slice 和slice2 指向的数据空间是同一个,因此slice2[0]=100,其它的都变化
fmt.Println("slice2=", slice2)
fmt.Println("slice=", slice)
fmt.Println("arr=", arr)
fmt.Println()
//用append内置函数,可以对切片进行动态追加
var slice3 []int = []int{100, 200, 300}
//通过append直接给slice3追加具体的元素
slice3 = append(slice3, 400, 500, 600)
fmt.Println("slice3", slice3) //100, 200, 300,400, 500, 600
//通过append将切片slice3追加给slice3
slice3 = append(slice3, slice3...) // 100, 200, 300,400, 500, 600 100, 200, 300,400, 500, 600
fmt.Println("slice3", slice3)
}
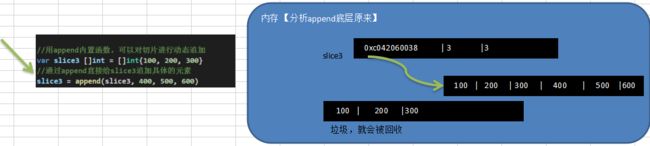
切片 append 操作的底层原理分析:
- 切片append操作的本质就是对数组扩容
- go底层会创建一下新的数组newArr(安装扩容后大小)
- 将slice原来包含的元素拷贝到新的数组newArr
- slice 重新引用到newArr
- 注意newArr是在底层来维护的,程序员不可见.
5)切片的拷贝操作
切片使用copy内置函数完成拷贝,举例说明
package main
import (
"fmt"
)
func main() {
//切片的拷贝操作
//切片使用copy内置函数完成拷贝,举例说明
fmt.Println()
var slice4 []int = []int{1, 2, 3, 4, 5}
var slice5 = make([]int, 10)
copy(slice5, slice4)
fmt.Println("slice4=", slice4) // 1, 2, 3, 4, 5
fmt.Println("slice5=", slice5) // 1, 2, 3, 4, 5, 0 , 0 ,0,0,0
}
- ( 1 ) copy(para 1 ,para 2 ) 参数的数据类型是切片
- ( 2 ) 按照上面的代码来看,slice 4 和slice 5 的数据空间是独立,相互不影响,也就是说 slice 4 [ 0 ]= 999 ,slice 5 [ 0 ] 仍然是 1,所以是值复制
7.10 string和slice
1 ) string底层是一个byte数组,因此string也可以进行切片处理
3 ) string是不可变的,也就说不能通过 str[ 0 ]=‘z’ 方式来修改字符串
//string是不可变的,也就说不能通过 str[0] = 'z' 方式来修改字符串
str[0] = 'z' [编译不会通过,报错,原因是string是不可变]
4 ) 如果需要修改字符串,可以先将string->[]byte/ 或者 []rune-> 修改 -> 重写转成string
package main
import (
"fmt"
)
func main() {
//如果需要修改字符串,可以先将string -> []byte / 或者 []rune -> 修改 -> 重写转成string
//"hello@atguigu" =>改成 "zello@atguigu"
str := "hello@atguigu"
arr1 := []byte(str)
arr1[0] = 'z'
str = string(arr1)
fmt.Println("str=", str)
}
package main
import (
"fmt"
)
func main() {
//如果需要修改字符串,可以先将string -> []byte / 或者 []rune -> 修改 -> 重写转成string
//"hello@atguigu" =>改成 "zello@atguigu"
str := "hello@atguigu"
// 细节,我们转成[]byte后,可以处理英文和数字,但是不能处理中文
// 原因是 []byte 字节来处理 ,而一个汉字,是3个字节,因此就会出现乱码
// 解决方法是 将 string 转成 []rune 即可, 因为 []rune是按字符处理,兼容汉字
arr1 := []rune(str)
arr1[0] = '北'
str = string(arr1)
fmt.Println("str=", str)
}
八、排序和查找
8.1 排序
排序的分类:
(1)内部排序:
指将需要处理的所有数据都加载到内部存储器中进行排序。包括(交换式排序法、选择式排序法和插入式排序法)
(2)外部排序法:
数据量过大,无法全部加载到内存中,需要借助外部存储进行排序。包括(合并排序法和直接合并排序法)
-
冒泡排序思路

-
冒泡排序实现
package main import ( "fmt" ) //冒泡排序 func BubbleSort(arr *[5]int) { fmt.Println("排序前arr=", (*arr)) temp := 0 //临时变量(用于做交换) //冒泡排序..一步一步推导出来的 for i :=0; i < len(*arr) - 1; i++ { for j := 0; j < len(*arr) - 1 - i; j++ { if (*arr)[j] > (*arr)[j + 1] { //交换 temp = (*arr)[j] (*arr)[j] = (*arr)[j + 1] (*arr)[j + 1] = temp } } } fmt.Println("排序后arr=", (*arr)) } func main() { //定义数组 arr := [5]int{24,69,80,57,13} //将数组传递给一个函数,完成排序 BubbleSort(&arr) fmt.Println("main arr=", arr) //有序? 是有序的 }
8.2 查找
1 ) 顺序查找
2 ) 二分查找(该数组是有序)
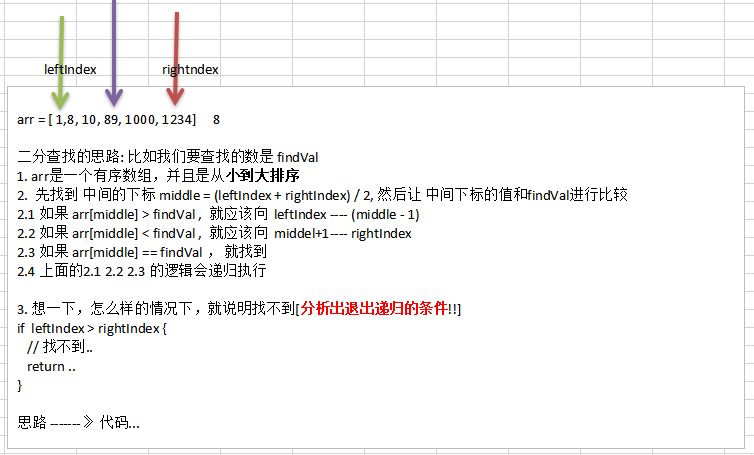
请对一个有序数组进行二分查找 { 1 , 8., 10 , 89 , 1000 , 1234 } ,输入一个数看看该数组是否存在此数,并且求出下标,如果没有就提示"没有这个数"。【会使用到递归】
- 二分查找思路
-
实现
package main import ( "fmt" ) //二分查找的函数 /* 二分查找的思路: 比如我们要查找的数是 findVal 1. arr是一个有序数组,并且是从小到大排序 2. 先找到 中间的下标 middle = (leftIndex + rightIndex) / 2, 然后让 中间下标的值和findVal进行比较 2.1 如果 arr[middle] > findVal , 就应该向 leftIndex ---- (middle - 1) 2.2 如果 arr[middle] < findVal , 就应该向 middel+1---- rightIndex 2.3 如果 arr[middle] == findVal , 就找到 2.4 上面的2.1 2.2 2.3 的逻辑会递归执行 3. 想一下,怎么样的情况下,就说明找不到[分析出退出递归的条件!!] if leftIndex > rightIndex { // 找不到.. return .. } */ func BinaryFind(arr *[6]int, leftIndex int, rightIndex int, findVal int) { //判断leftIndex 是否大于 rightIndex if leftIndex > rightIndex { fmt.Println("找不到") return } //先找到 中间的下标 middle := (leftIndex + rightIndex) / 2 if (*arr)[middle] > findVal { //说明我们要查找的数,应该在 leftIndex --- middel-1 BinaryFind(arr, leftIndex, middle - 1, findVal) } else if (*arr)[middle] < findVal { //说明我们要查找的数,应该在 middel+1 --- rightIndex BinaryFind(arr, middle + 1, rightIndex, findVal) } else { //找到了 fmt.Printf("找到了,下标为%v \n", middle) } } func main() { arr := [6]int{1,8, 10, 89, 1000, 1234} //测试一把 BinaryFind(&arr, 0, len(arr) - 1, -6) }
8.3 多维数组
- 语法:var 数组名 大小类型
- 比如:var arr[ 2 ][ 3 ]int , 再赋值。
- 使用演示
- 二维数组在内存的存在形式(重点)
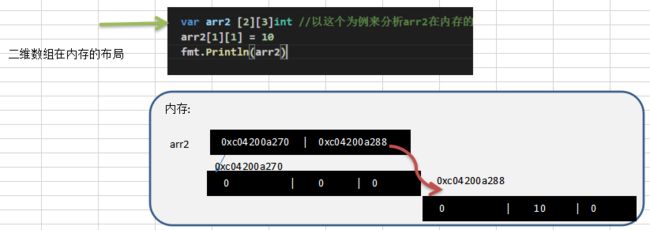
-
初始化
var 数组名 [大小][大小]类型 =[大小][大小]类型{{初值},{初值}} -
使用演示
package main import ( "fmt" ) func main() { arr3 := [2][3]int{{1,2,3}, {4,5,6}} fmt.Println("arr3=", arr3) } -
说明:二维数组在声明/定义时也对应有四种写法 和一维数组类似
var 数组名 [大小][大小]类型 =[大小][大小]类型 { { 初值 },{ 初值 } } var 数组名 [大小][大小]类型 =[...][大小]类型{{初值},{初值}} var 数组名 = [大小][大小]类型{{初值},{初值}} var 数组名 = [...][大小]类型{{初值},{初值}}
8.4 二维数组遍历
- 双层for循环完成遍历
- for-range方式完成遍历
package main
import (
"fmt"
)
func main() {
//演示二维数组的遍历
var arr3 = [2][3]int{{1,2,3}, {4,5,6}}
//for循环来遍历
for i := 0; i < len(arr3); i++ {
for j := 0; j < len(arr3[i]); j++ {
fmt.Printf("%v\t", arr3[i][j])
}
fmt.Println()
}
//for-range来遍历二维数组
for i, v := range arr3 {
for j, v2 := range v {
fmt.Printf("arr3[%v][%v]=%v \t",i, j, v2)
}
fmt.Println()
}
}
九、map
9.1 map概述
-
map是key-value数据结构,又称为字段或者关联数组。类似其它编程语言的集合,在编程中是经常使用到
-
基本语法
var map 变量名 map[keytype]valuetype -
key可以是什么类型
golang中的map,的 key 可以是很多种类型,比如 bool, 数字,string, 指针,channel, 还可以是只包含前面几个类型的 接口, 结构体, 数组
通常 key 为 int 、 string
注意:slice, map 还有 function 不可以,因为这几个没法用 ==来判断
- value可以是什么类型
valuetype的类型和key基本一样,不再赘述了
通常为: 数字(整数,浮点数),string,map,struct
9.2 map声明
-
map声明的举例:
var a map[string]string var a map[string]int var a map[int]string var a map[string]map[string]string注意:声明是不会分配内存的,初始化需要make ,分配内存后才能赋值和使用。
案例演示:
package main
import (
"fmt"
)
func main() {
//map的声明和注意事项
var a map[string]string
//在使用map前,需要先make , make的作用就是给map分配数据空间
a = make(map[string]string, 10)
a["no1"] = "宋江" //ok?
a["no2"] = "吴用" //ok?
a["no1"] = "武松" //ok?
a["no3"] = "吴用" //ok?
fmt.Println(a)
}
- 对上面代码的说明
1 ) map在使用前一定要make
2 ) map的key是不能重复,如果重复了,则以最后这个key-value为准
3 ) map的value是可以相同的.
4 ) map的 key-value是无序
5 ) make内置函数数目
9.3 map的使用
方式 1
package main
import (
"fmt"
)
func main() {
//第一种使用方式
var a map[string]string
//在使用map前,需要先make , make的作用就是给map分配数据空间
a = make(map[string]string, 10)
a["no1"] = "宋江" //ok?
a["no2"] = "吴用" //ok?
a["no1"] = "武松" //ok?
a["no3"] = "吴用" //ok?
fmt.Println(a)
}
方式 2
package main
import (
"fmt"
)
func main() {
//第二种方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities)
}
方式 3
package main
import (
"fmt"
)
func main() {
//第三种方式
heroes := map[string]string{
"hero1" : "宋江",
"hero2" : "卢俊义",
"hero3" : "吴用",
}
heroes["hero4"] = "林冲"
fmt.Println("heroes=", heroes)
}
9.4 map操作
- map增改
map[“key”]=value//如果 key 还没有,就是增加,如果 key 存在就是修改。
- map删除:
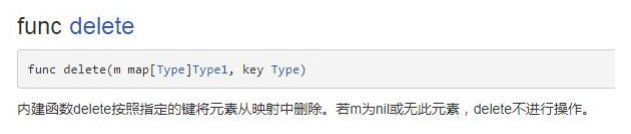
说明:delete(map,“key”) ,delete是一个内置函数,如果key存在,就删除该key-value,如果key不存在,不操作,但是也不会报错
package main
import (
"fmt"
)
func main() {
//第二种方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities) // map[no1:北京 no2:天津 no3:上海]
//演示删除
delete(cities, "no1")
fmt.Println(cities) // map[no2:天津 no3:上海]
//当delete指定的key不存在时,删除不会操作,也不会报错
delete(cities, "no4")
fmt.Println(cities) // map[no2:天津 no3:上海]
}
细节
如果我们要删除map的所有key,没有一个专门的方法一次删除,可以遍历一下key,逐个删除或者 map=make(…),make一个新的,让原来的成为垃圾,被gc回收
package main
import (
"fmt"
)
func main() {
//第二种方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities)
//如果希望一次性删除所有的key
//1. 遍历所有的key,如何逐一删除 [遍历]
//2. 直接make一个新的空间
cities = make(map[string]string)
fmt.Println(cities)
}
- map 查找
package main
import (
"fmt"
)
func main() {
//第二种方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
fmt.Println(cities)
//演示map的查找
val, ok := cities["no2"]
if ok {
fmt.Printf("有no1 key 值为%v\n", val)
} else {
fmt.Printf("没有no1 key\n")
}
}
- map遍历
map的遍历使用 for-range 的结构遍历
复杂案例
package main
import (
"fmt"
)
func main() {
//使用for-range遍历map
//第二种方式
cities := make(map[string]string)
cities["no1"] = "北京"
cities["no2"] = "天津"
cities["no3"] = "上海"
for k, v := range cities {
fmt.Printf("k=%v v=%v\n", k, v)
}
fmt.Println("cities 有", len(cities), " 对 key-value")
//使用for-range遍历一个结构比较复杂的map
studentmap := make(map[string]map[string]string)
studentmap["stu01"] = make(map[string]string, 3)
studentmap["stu01"]["name"] = "tom"
studentmap["stu01"]["sex"] = "男"
studentmap["stu01"]["address"] = "北京长安街~"
studentmap["stu02"] = make(map[string]string, 3) //这句话不能少!!
studentmap["stu02"]["name"] = "mary"
studentmap["stu02"]["sex"] = "女"
studentmap["stu02"]["address"] = "上海黄浦江~"
for k1, v1 := range studentmap {
fmt.Println("k1=", k1)
for k2, v2 := range v1 {
fmt.Printf("\t k2=%v v2=%v\n", k2, v2)
}
fmt.Println()
}
}
map的长度:len()
9.5 map切片
切片的数据类型如果是 map ,则我们称为 sliceofmap, map 切片,这样使用则 map 个数就可以动态变化了。
-
案例演示
要求:使用一个map来记录monster的信息 name 和 age, 也就是说一个monster对应一个map,并且妖怪的个数可以动态的增加=> map 切片
package main
import (
"fmt"
)
func main() {
//演示map切片的使用
/*
要求:使用一个map来记录monster的信息 name 和 age, 也就是说一个
monster对应一个map,并且妖怪的个数可以动态的增加=>map切片
*/
//1. 声明一个map切片
var monsters []map[string]string
monsters = make([]map[string]string, 2) //准备放入两个妖怪
//2. 增加第一个妖怪的信息
if monsters[0] == nil {
monsters[0] = make(map[string]string, 2)
monsters[0]["name"] = "牛魔王"
monsters[0]["age"] = "500"
}
if monsters[1] == nil {
monsters[1] = make(map[string]string, 2)
monsters[1]["name"] = "玉兔精"
monsters[1]["age"] = "400"
}
// 下面这个写法越界。
// if monsters[2] == nil {
// monsters[2] = make(map[string]string, 2)
// monsters[2]["name"] = "狐狸精"
// monsters[2]["age"] = "300"
// }
//这里我们需要使用到切片的append函数,可以动态的增加monster
//1. 先定义个monster信息
newMonster := map[string]string{
"name" : "新的妖怪~火云邪神",
"age" : "200",
}
monsters = append(monsters, newMonster)
fmt.Println(monsters)
}
9.6 map排序
1 ) golang中没有一个专门的方法针对map的key进行排序
2 ) golang中的map默认是无序的,注意也不是按照添加的顺序存放的,你每次遍历,得到的输出可能不一样.
3 ) golang中map的排序,是先将key进行排序,然后根据key值遍历输出即可
package main
import (
"fmt"
"sort"
)
func main() {
//map的排序
map1 := make(map[int]int, 10)
map1[10] = 100
map1[1] = 13
map1[4] = 56
map1[8] = 90
fmt.Println(map1)
//如果按照map的key的顺序进行排序输出
//1. 先将map的key 放入到 切片中
//2. 对切片排序
//3. 遍历切片,然后按照key来输出map的值
var keys []int
for k, _ := range map1 {
keys = append(keys, k)
}
//排序
sort.Ints(keys)
fmt.Println(keys)
for _, k := range keys{
fmt.Printf("map1[%v]=%v \n", k, map1[k])
}
}
9.7 map使用细节
1 ) map是引用类型,遵守引用类型传递的机制,在一个函数接收map,修改后,会直接修改原来的map
package main
import (
"fmt"
)
func modify(map1 map[int]int) {
map1[10] = 900
}
func main() {
//map是引用类型,遵守引用类型传递的机制,在一个函数接收map,
//修改后,会直接修改原来的map
map1 := make(map[int]int, 2)
map1[1] = 90
map1[2] = 88
map1[10] = 1
map1[20] = 2
modify(map1)
// 看看结果, map1[10] = 900 ,说明map是引用类型
fmt.Println(map1)
}
2 ) map的容量达到后,再想map增加元素,会自动扩容,并不会发生panic,也就是说map 能动态的增长 键值对(key-value)
3 ) map的 value 也经常使用 struct 类型,更适合管理复杂的数据(比前面value是一个map更好),比如value为 Student结构体
package main
import (
"fmt"
)
func modify(map1 map[int]int) {
map1[10] = 900
}
//定义一个学生结构体
type Stu struct {
Name string
Age int
Address string
}
func main() {
//map的value 也经常使用struct 类型,
//更适合管理复杂的数据(比前面value是一个map更好),
//比如value为 Student结构体
//1.map 的 key 为 学生的学号,是唯一的
//2.map 的 value为结构体,包含学生的 名字,年龄, 地址
students := make(map[string]Stu, 10)
//创建2个学生
stu1 := Stu{"tom", 18, "北京"}
stu2 := Stu{"mary", 28, "上海"}
students["no1"] = stu1
students["no2"] = stu2
fmt.Println(students)
//遍历各个学生信息
for k, v := range students {
fmt.Printf("学生的编号是%v \n", k)
fmt.Printf("学生的名字是%v \n", v.Name)
fmt.Printf("学生的年龄是%v \n", v.Age)
fmt.Printf("学生的地址是%v \n", v.Address)
fmt.Println()
}
}
十、面向对象编程
10.1 go面向对象编程说明
1 ) Golang也支持面向对象编程(OOP),但是和传统的面向对象编程有区别,并不是纯粹的面向对象语言。所以我们说Golang支持面向对象编程特性是比较准确的。
2 ) Golang没有类(class),Go语言的结构体(struct)和其它编程语言的类(class)有同等的地位,你可以理解Golang是基于struct来实现OOP特性的。
3 ) Golang面向对象编程非常简洁,去掉了传统OOP语言的继承、方法重载、构造函数和析构函数、隐藏的this指针等等
4 ) Golang仍然有面向对象编程的继承,封装和多态的特性,只是实现的方式和其它OOP语言不一样,比如继承 :Golang没有extends 关键字,继承是通过匿名字段来实现。
5 ) Golang面向对象(OOP)很优雅,OOP本身就是语言类型系统(typesystem)的一部分,通过接口(interface)关联,耦合性低,也非常灵活。也就是说在Golang中面向接口编程是非常重要的特性。
代码演示
package main
import (
"fmt"
)
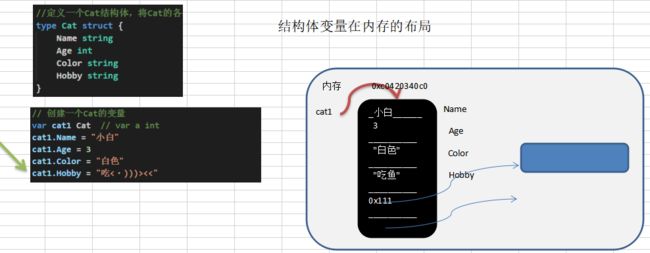
//定义一个Cat结构体,将Cat的各个字段/属性信息,放入到Cat结构体进行管理
type Cat struct {
Name string
Age int
Color string
Hobby string
Scores [3]int // 字段是数组...
}
func main() {
// 张老太养了20只猫猫:一只名字叫小白,今年3岁,白色。还有一只叫小花,
// 今年100岁,花色。请编写一个程序,当用户输入小猫的名字时,就显示该猫的名字,
// 年龄,颜色。如果用户输入的小猫名错误,则显示 张老太没有这只猫猫。
// 使用struct来完成案例
// 创建一个Cat的变量
var cat1 Cat // var a int
fmt.Printf("cat1的地址=%p\n", &cat1)
cat1.Name = "小白"
cat1.Age = 3
cat1.Color = "白色"
cat1.Hobby = "吃<・)))><<"
fmt.Println("cat1=", cat1)
fmt.Println("猫猫的信息如下:")
fmt.Println("name=", cat1.Name)
fmt.Println("Age=", cat1.Age)
fmt.Println("color=", cat1.Color)
fmt.Println("hobby=", cat1.Hobby)
}
通过上面的案例和讲解我们可以看出:
1 ) 结构体是自定义的数据类型,代表一类事物.
2 ) 结构体变量(实例)是具体的,实际的,代表一个具体变量
10.2 结构体在内存里的布局
- 基本语法
type 结构体名称 struct {
field 1 type
field 2 type
}
- 举例:
type Student struct{
Namestring//字段
Ageint//字段
Scorefloat 32
}
不同结构体变量的字段是独立,互不影响,一个结构体变量字段的更改,不影响另外一个, 结构体是值类型。
package main
import (
"fmt"
)
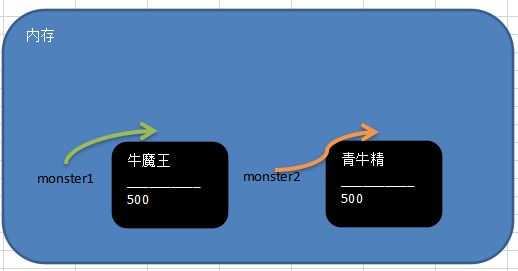
type Monster struct{
Name string
Age int
}
func main() {
//不同结构体变量的字段是独立,互不影响,一个结构体变量字段的更改,
//不影响另外一个, 结构体是值类型
var monster1 Monster
monster1.Name = "牛魔王"
monster1.Age = 500
monster2 := monster1 //结构体是值类型,默认为值拷贝
monster2.Name = "青牛精"
fmt.Println("monster1=", monster1) //monster1= {牛魔王 500}
fmt.Println("monster2=", monster2) //monster2= {青牛精 500}
}
画出上面代码的内存示意图:
10.3 创建结构体变量和访问字段
-
方式 1 - 直接声明
案例演示:var person Person
前面我们已经说了。
-
方式 2 - {}
案例演示: var person Person = Person{}
package main
import (
"fmt"
)
type Person struct{
Name string
Age int
}
func main() {
//方式2
p2 := Person{"mary", 20}
// p2.Name = "tom"
// p2.Age = 18
fmt.Println(p2)
}
- 方式 3 - &
package main
import (
"fmt"
)
type Person struct{
Name string
Age int
}
func main() {
//方式3-&
//案例: var person *Person = new (Person)
var p3 *Person= new(Person)
//因为p3是一个指针,因此标准的给字段赋值方式
//(*p3).Name = "smith" 也可以这样写 p3.Name = "smith"
//原因: go的设计者 为了程序员使用方便,底层会对 p3.Name = "smith" 进行处理
//会给 p3 加上 取值运算 (*p3).Name = "smith"
(*p3).Name = "smith"
p3.Name = "john" //
(*p3).Age = 30
p3.Age = 100
fmt.Println(*p3)
}
- 方式 4 - {}
package main
import (
"fmt"
)
type Person struct{
Name string
Age int
}
func main() {
//方式4-{}
//案例: var person *Person = &Person{}
//下面的语句,也可以直接给字符赋值
//var person *Person = &Person{"mary", 60}
var person *Person = &Person{}
//因为person 是一个指针,因此标准的访问字段的方法
// (*person).Name = "scott"
// go的设计者为了程序员使用方便,也可以 person.Name = "scott"
// 原因和上面一样,底层会对 person.Name = "scott" 进行处理, 会加上 (*person)
(*person).Name = "scott"
person.Name = "scott~~"
(*person).Age = 88
person.Age = 10
fmt.Println(*person)
}
- 说明:
1 ) 第 3 种和第 4 种方式返回的是 结构体指针。
2 ) 结构体指针访问字段的标准方式应该是:(* 结构体指针 ) . 字段名 ,比如
(*person).Name="tom"
3 ) 但go做了一个简化,也支持 结构体指针. 字段名, 比如 person.Name=“tom”。更加符合程序员使用的习惯, go 编译器底层 对 person.Name 做了转化 (*person).Name
注意

10.3 结构体细节
1 ) 结构体的所有字段在内存中是连续的
package main
import "fmt"
//结构体
type Point struct {
x int
y int
}
//结构体
type Rect struct {
leftUp, rightDown Point
}
//结构体
type Rect2 struct {
leftUp, rightDown *Point
}
func main() {
r1 := Rect{Point{1,2}, Point{3,4}}
//r1有四个int, 在内存中是连续分布
//打印地址
fmt.Printf("r1.leftUp.x 地址=%p r1.leftUp.y 地址=%p r1.rightDown.x 地址=%p r1.rightDown.y 地址=%p \n",
&r1.leftUp.x, &r1.leftUp.y, &r1.rightDown.x, &r1.rightDown.y)
//r2有两个 *Point类型,这个两个*Point类型的本身地址也是连续的,
//但是他们指向的地址不一定是连续
r2 := Rect2{&Point{10,20}, &Point{30,40}}
//打印地址
fmt.Printf("r2.leftUp 本身地址=%p r2.rightDown 本身地址=%p \n",
&r2.leftUp, &r2.rightDown)
//他们指向的地址不一定是连续..., 这个要看系统在运行时是如何分配
fmt.Printf("r2.leftUp 指向地址=%p r2.rightDown 指向地址=%p \n",
r2.leftUp, r2.rightDown)
}
对应的分析图:

2 ) 结构体是用户单独定义的类型,和其它类型进行转换时需要有完全相同的字段(名字、个数和类型)
package main
import "fmt"
import "encoding/json"
type A struct {
Num int
}
type B struct {
Num int
}
func main() {
var a A
var b B
a = A(b) // ? 可以转换,但是有要求,就是结构体的的字段要完全一样(包括:名字、个数和类型!)
fmt.Println(a, b)
}
3 ) 结构体进行type重新定义(相当于取别名),Golang认为是新的数据类型,但是相互间可以强转

4 ) struct的每个字段上,可以写上一个 tag , 该tag可以通过反射机制获取,常见的使用场景就是序列化和反序列化。
- 序列化的使用场景:

- 举例:
package main
import "fmt"
import "encoding/json"
type Monster struct{
Name string `json:"name"` // `json:"name"` 就是 struct tag
Age int `json:"age"`
Skill string `json:"skill"`
}
func main() {
//1. 创建一个Monster变量
monster := Monster{"牛魔王", 500, "芭蕉扇~"}
//2. 将monster变量序列化为 json格式字串
// json.Marshal 函数中使用反射,这个讲解反射时,我会详细介绍
jsonStr, err := json.Marshal(monster)
if err != nil {
fmt.Println("json 处理错误 ", err)
}
fmt.Println("jsonStr", string(jsonStr))
}
10.4 方法
在某些情况下,我们要需要声明(定义)方法。比如Person结构体:除了有一些字段外( 年龄,姓名…),Person结构体还有一些行为比如:可以说话、跑步…,通过学习,还可以做算术题。这时就要用方法才能完成。
Golang中的方法是作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是 struct
10.4.1 方法的声明与调用
func(recevier type)methodName(参数列表) (返回值列表){
方法体
return 返回值
}
1 ) 参数列表:表示方法输入
2 ) receviertype: 表示这个方法和type这个类型进行绑定,或者说该方法作用于type类型
3 ) receivertype:type可以是结构体,也可以其它的自定义类型
4 ) receiver: 就是type类型的一个变量(实例),比如 :Person结构体 的一个变量(实例)
5 ) 返回值列表:表示返回的值,可以多个
6 ) 方法主体:表示为了实现某一功能代码块
7 ) return 语句不是必须的。
type A struct{
Numint
}
func(a A)test(){
fmt.Println(a.Num)
}
- 对上面的语法的说明
1 ) func( a A )test() {} 表示 A结构体有一方法,方法名为 test
2 ) (a A) 体现 test方法是和A类型绑定的
package main
import (
"fmt"
)
type Person struct{
Name string
}
//给Person类型绑定一方法
func (p Person) test() {
fmt.Println("test() name=",p.Name)
func main() {
var p Person
p.Name = "tom"
p.test() //调用方法
}
1 ) test方法和Person类型绑定
2 ) test方法只能通过 Person类型的变量来调用,而不能直接调用,也不能使用其它类型变量来调用
3 ) func(p Person)test(){}…p 表示哪个Person变量调用,这个p就是它的副本, 这点和函数传参非常相似。
4 ) p 这个名字,有程序员指定,不是固定, 比如修改成person也是可以
10.4.2 方法的调用与传参机制原理*
方法的调用和传参机制和函数基本一样,不一样的地方是方法调用时,会将调用方法的变量,当做实参也传递给方法。下面我们举例说明。
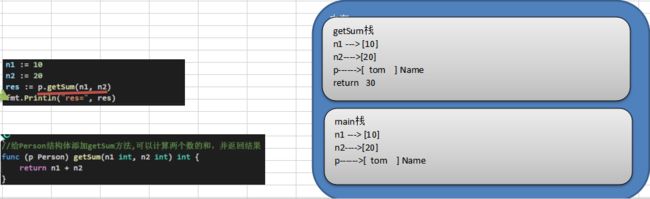
1 ) 在通过一个结构体实例变量去调用方法时,其调用机制和函数一样
2 ) 不一样的地方时,变量调用方法时,该结构体实例变量变量本身也会作为一个参数传递到方法(如果变量是值类型,则进行值拷贝,如果变量是引用类型,则进行地址拷贝)
10.4.3 方法使用细节
1 ) 结构体类型是值类型,在方法调用中,遵守值类型的传递机制,是值拷贝传递方式
2 ) 如程序员希望在方法中,修改结构体变量的值,可以通过结构体指针的方式来处理
package main
import (
"fmt"
)
type Circle struct {
radius float64
}
//为了提高效率,通常我们方法和结构体的指针类型绑定
func (c *Circle) area2() float64 {
//因为 c是指针,因此我们标准的访问其字段的方式是 (*c).radius
//return 3.14 * (*c).radius * (*c).radius
// (*c).radius 等价 c.radius
fmt.Printf("c 是 *Circle 指向的地址=%p", c)
c.radius = 10
return 3.14 * c.radius * c.radius
}
func main() {
//创建一个Circle 变量
var c Circle
fmt.Printf("main c 结构体变量地址 =%p\n", &c)
c.radius = 7.0
//res2 := (&c).area2()
//编译器底层做了优化 (&c).area2() 等价 c.area()
//因为编译器会自动的给加上 &c
res2 := c.area2()
fmt.Println("面积=", res2)
fmt.Println("c.radius = ", c.radius) //10
}
3 ) Golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,都可以有方法,而不仅仅是struct, 比如int,float 32 等都可以有方法
package main
import (
"fmt"
)
/*
Golang中的方法作用在指定的数据类型上的(即:和指定的数据类型绑定),因此自定义类型,
都可以有方法,而不仅仅是struct, 比如int , float32等都可以有方法
*/
type integer int
func (i integer) print() {
fmt.Println("i=", i)
}
//编写一个方法,可以改变i的值
func (i *integer) change() {
*i = *i + 1
}
func main() {
var i integer = 10
i.print()
i.change()
fmt.Println("i=", i)
}
4 ) 方法的访问范围控制的规则,和函数一样。方法名首字母小写,只能在本包访问,方法首字母大写,可以在本包和其它包访问。[讲解]
5 ) 如果一个类型实现了String()这个方法,那么fmt.Println默认会调用这个变量String()进行输出
package main
import (
"fmt"
)
type Student struct {
Name string
Age int
}
//给*Student实现方法String()
func (stu *Student) String() string {
str := fmt.Sprintf("Name=[%v] Age=[%v]", stu.Name, stu.Age)
return str
}
func main() {
//定义一个Student变量
stu := Student{
Name : "tom",
Age : 20,
}
//如果你实现了 *Student 类型的 String方法,就会自动调用
fmt.Println(&stu)
}
10.4.4 方法与函数的区别
1 ) 调用方式不一样
- 函数的调用方式: 函数名(实参列表)
- 方法的调用方式: 变量.方法名(实参列表)
2 ) 对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
package main
import (
"fmt"
)
type Person struct {
Name string
}
//函数
//对于普通函数,接收者为值类型时,不能将指针类型的数据直接传递,反之亦然
func test01(p Person) {
fmt.Println(p.Name)
}
func test02(p *Person) {
fmt.Println(p.Name)
}
func main() {
p := Person{"tom"}
test01(p)
test02(&p)
}
3 ) 对于方法(如struct的方法),接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
package main
import (
"fmt"
)
type Person struct {
Name string
}
//对于方法(如struct的方法),
//接收者为值类型时,可以直接用指针类型的变量调用方法,反过来同样也可以
func (p Person) test03() {
p.Name = "jack"
fmt.Println("test03() =", p.Name) // jack
}
func (p *Person) test04() {
p.Name = "mary"
fmt.Println("test03() =", p.Name) // mary
}
func main() {
p := Person{"tom"}
p.test03()
fmt.Println("main() p.name=", p.Name) // tom
(&p).test03() // 从形式上是传入地址,但是本质仍然是值拷贝
fmt.Println("main() p.name=", p.Name) // tom
(&p).test04()
fmt.Println("main() p.name=", p.Name) // mary
p.test04() // 等价 (&p).test04 , 从形式上是传入值类型,但是本质仍然是地址拷贝
}
1 ) 不管调用形式如何,真正决定是值拷贝还是地址拷贝,看这个方法是和哪个类型绑定.
2 ) 如果是和值类型,比如 ( pPerson ), 则是值拷贝, 如果和指针类型,比如是 ( p*Person ) 则是地址拷贝。
10.5 工厂模式
Golang的结构体没有构造函数,通常可以使用工厂模式来解决这个问题。
使用工厂模式实现跨包创建结构体实例(变量)的案例:
如果model 包的 结构体变量首字母大写,引入后,直接使用 , 没有问题

如果model 包的 结构体变量首字母小写,引入后,不能直接使用, 可以工厂模式解决(公共构造方法)
student.go
package model
//定义一个结构体
type student struct{
Name string
Score float64
}
//因为student结构体首字母是小写,因此是只能在model使用
//我们通过工厂模式来解决
func NewStudent(n string, s float64) *student { // 编写一个函数可以返回构造的结构体
return &student{ // 因为函数首字母是大写,公开函数所以可以在其他包里用本程序的私有类
Name : n, // 前提是私有类里变量首字母都大写
Score : s,
}
}
main.go
package main
import (
"fmt"
"go_code/chapter10/factory/model"
)
func main() {
//定student结构体是首字母小写,我们可以通过工厂模式来解决
var stu = model.NewStudent("tom~", 98.8)
fmt.Println(*stu) //&{....}
fmt.Println("name=", stu.Name, " score=", stu.Score)
}
如果model包的student 的结构体的字段 Score改成 score,我们还能正常访问吗?又应该如何解决这个问题呢?[老师给出思路,学员自己完成]
解决方法如下:
package model
//定义一个结构体
type student struct{
Name string
score float64
}
//因为student结构体首字母是小写,因此是只能在model使用
//我们通过工厂模式来解决
func NewStudent(n string, s float64) *student {
return &student{
Name : n,
score : s,
}
}
//如果score字段首字母小写,则,在其它包不可以直接方法,我们可以提供一个方法
func (s *student) GetScore() float64{
return s.score //ok
}
如果model包的student 的结构体的字段 Score改成 score,即使创建了类也访问不了score
解决方法如下:
package model
//定义一个结构体
type student struct{
Name string
score float64
}
//因为student结构体首字母是小写,因此是只能在model使用
//我们通过工厂模式来解决
func NewStudent(n string, s float64) *student {
return &student{
Name : n,
score : s,
}
}
//如果score字段首字母小写,则,在其它包不可以直接方法,我们可以提供一个方法
func (s *student) GetScore() float64{
return s.score //ok
}
10.6 面向对象编程特性一封装
封装(encapsulation)就是把抽象出的字段和对字段的操作封装在一起,数据被保护在内部,程序的其它包只有通过被授权的操作(方法),才能对字段进行操作
-
封装的好处
- 隐藏实现细节
- 提可以对数据进行验证,保证安全合理(Age)
-
封装的步骤(工厂说了)
-
将结构体、字段(属性)的首字母小写(不能导出了,其它包不能使用,类似private)
-
给结构体所在包提供一个工厂模式的函数,首字母大写。类似一个构造函数
-
提供一个首字母大写的Set方法(类似其它语言的public),用于对属性判断并赋值
func(var 结构体类型名)SetXxx(参数列表)(返回值列表){ //加入数据验证的业务逻辑 var.字段 =参数 } -
提供一个首字母大写的Get方法(类似其它语言的public),用于获取属性的值
func(var 结构体类型名)GetXxx(){ returnvar.age; }
特别说明:在Golang开发中并没有特别强调封装,这点并不像Java. 所以提醒学过java 的朋友,不用总是用java的语法特性来看待Golang,Golang本身对面向对象的特性做了简化的.
-
10.6 面向对象编程特性二继承
package main
import(
"fmt"
)
//编写一个学生考试系统
//小学生
type Pupilstruct{
Namestring
Ageint
Scoreint
}
//显示他的成绩
func(p *Pupil)ShowInfo(){
fmt.Printf("学生名=%v 年龄=%v 成绩=%v\n",p.Name,p.Age,p.Score)
}
func(p *Pupil)SetScore(scoreint){
//业务判断
p.Score=score
}
func(p*Pupil)testing(){
fmt.Println("小学生正在考试中.....")
}
//大学生, 研究生。。
//大学生
type Graduatestruct{
Namestring
Ageint
Scoreint
}
//显示他的成绩
func(p *Graduate)ShowInfo(){
fmt.Printf("学生名=%v 年龄=%v 成绩=%v\n",p.Name,p.Age,p.Score)
}
func(p *Graduate)SetScore(scoreint){
//业务判断
p.Score=score
}
func(p *Graduate)testing(){
fmt.Println("大学生正在考试中.....")
}
//代码冗余.. 高中生....
func main(){
//测试
varpupil=&Pupil{
Name:"tom",
Age: 10 ,
}
pupil.testing()
pupil.SetScore( 90 )
pupil.ShowInfo()
//测试
vargraduate=&Graduate{
Name:"mary",
Age: 20 ,
}
graduate.testing()
graduate.SetScore( 90 )
graduate.ShowInfo()
}
- Pupil 和 Graduate 两个结构体的字段和方法几乎,但是我们却写了相同的代码,代码复用性不强
- 出现代码冗余,而且代码不利于维护,同时也不利于功能的扩展。
- 解决方法-通过继承方式来解决
-
继承介绍
当多个结构体存在相同的属性(字段)和方法时,可以从这些结构体中抽象出结构体(比如刚才的Student),在该结构体中定义这些相同的属性和方法。
其它的结构体不需要重新定义这些属性(字段)和方法,只需嵌套一个Student匿名结构体即可。
在Golang中,如果一个struct嵌套了另一个匿名结构体,那么这个结构体可以直接访问匿名结构体的字段和方法,从而实现了继承特性。
type Goods struct{
Namestring
Priceint
}
type Bookstruct{
Goods //这里就是嵌套匿名结构体Goods
Writerstring
}
-
深入讨论
1 ) 结构体可以使用嵌套匿名结构体所有的字段和方法,即:首字母大写或者小写的字段、方法,都可以使用
2 ) 匿名结构体字段访问可以简化
package main
import (
"fmt"
)
type A struct {
Name string
age int
}
func (a *A) SayOk() {
fmt.Println("A SayOk", a.Name)
}
func (a *A) hello() {
fmt.Println("A hello", a.Name)
}
type B struct {
A
Name string
}
func (b *B) SayOk() {
fmt.Println("B SayOk", b.Name)
}
func main() {
b.Name = "smith"
b.age = 20
b.SayOk()
b.hello()
}
对上面的代码小结
- 当我们直接通过 b 访问字段或方法时,其执行流程如下比如 b.Name
- 编译器会先看b对应的类型有没有Name, 如果有,则直接调用B类型的Name字段
- 如果没有就去看B中嵌入的匿名结构体A有没有声明Name字段,如果有就调用,如果没有继续查找…如果都找不到就报错.
- 当结构体和匿名结构体有相同的字段或者方法时,编译器采用就近访问原则访问,如希望访问匿名结构体的字段和方法,可以通过匿名结构体名来区分
func main() {
var b B
b.Name = "jack" // ok
b.A.Name = "scott"
b.age = 100 //ok
b.SayOk() // B SayOk jack
b.A.SayOk() // A SayOk scott
b.hello() // A hello ? "jack" 还是 "scott"
}
- 结构体嵌入两个(或多个)匿名结构体,如两个匿名结构体有相同的字段和方法(同时结构体本身没有同名的字段和方法),在访问时,就必须明确指定匿名结构体名字,否则编译报错。
5 ) 如果一个struct嵌套了一个有名结构体,这种模式就是组合,如果是组合关系,那么在访问组合的结构体的字段或方法时,必须带上结构体的名字
6 ) 如果一个结构体有int类型的匿名字段,就不能第二个。
7 ) 如果需要有多个int的字段,则必须给int字段指定名字
10.7 多重继承
- 多重继承说明
如一个 struct 嵌套了多个匿名结构体,那么该结构体可以直接访问嵌套的匿名结构体的字段和方法,从而实现了多重继承。
- 案例演示 通过一个案例来说明多重继承使用
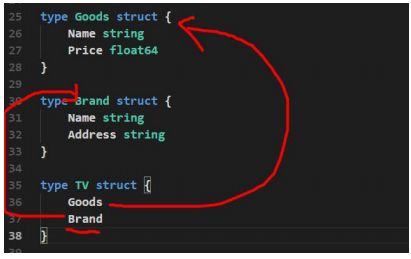
- 多重继承细节说明
1 ) 如嵌入的匿名结构体有相同的字段名或者方法名,则在访问时,需要通过匿名结构体类型名来区分。【案例演示】

2 ) 为了保证代码的简洁性,建议大家尽量不使用多重继承
10.8 接口
讲解多态前,我们需要讲解接口(interface),因为在Golang中 多态 特性主要是通过接口来体现的。
package main
import (
"fmt"
)
//声明/定义一个接口
type Usb interface {
//声明了两个没有实现的方法
Start()
Stop()
}
//声明/定义一个接口
type Usb2 interface {
//声明了两个没有实现的方法
Start()
Stop()
Test()
}
type Phone struct {
}
//让Phone 实现 Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
type Camera struct {
}
//让Camera 实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作~~~。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
//计算机
type Computer struct {
}
//编写一个方法Working 方法,接收一个Usb接口类型变量
//只要是实现了 Usb接口 (所谓实现Usb接口,就是指实现了 Usb接口声明所有方法)
func (c Computer) Working(usb Usb) {
//通过usb接口变量来调用Start和Stop方法
usb.Start()
usb.Stop()
}
func main() {
//测试
//先创建结构体变量
computer := Computer{}
phone := Phone{}
camera := Camera{}
//关键点
computer.Working(phone)
computer.Working(camera) //
}
-
接口概念
interface类型可以定义一组方法,但是这些不需要实现。并且interface不能包含任何变量。到某个 自定义类型(比如结构体Phone)要使用的时候,在根据具体情况把这些方法写出来(实现)。
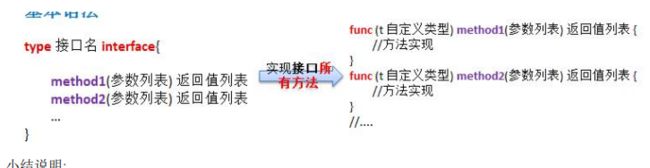
1 ) 接口里的所有方法都没有方法体,即接口的方法都是没有实现的方法。接口体现了程序设计的多态和高内聚低偶合的思想。
2 ) Golang中的接口,不需要显式的实现。只要一个变量,含有接口类型中的所有方法,那么这个变量就实现这个接口。因此,Golang中没有 implement这样的关键字
10.8.1注意事项与细节
1 ) 接口本身不能创建实例,但是可以指向一个实现了该接口的自定义类型的变量(实例)
2 ) 接口中所有的方法都没有方法体,即都是没有实现的方法。
3 ) 在Golang中,一个自定义类型需要将某个接口的所有方法都实现,我们说这个自定义类型实现 了该接口。
4 ) 一个自定义类型只有实现了某个接口,才能将该自定义类型的实例(变量)赋给接口类型
5 ) 只要是自定义数据类型,就可以实现接口,不仅仅是结构体类型。
6 ) 一个自定义类型可以实现多个接口
package main
import (
"fmt"
)
type AInterface interface {
Say()
}
type BInterface interface {
Hello()
}
type Monster struct {
}
func (m Monster) Hello() {
fmt.Println("Monster Hello()~~")
}
func (m Monster) Say() {
fmt.Println("Monster Say()~~")
}
func main() {
//Monster实现了AInterface 和 BInterface
var monster Monster
var a2 AInterface = monster
var b2 BInterface = monster
a2.Say()
b2.Hello()
}
7 ) Golang接口中不能有任何变量
type AInterface interface {
Name string //错误
Say()
}
8 ) 一个接口(比如A接口)可以继承多个别的接口(比如B,C接口),这时如果要实现A接口,也必须将B,C接口的方法也全部实现。
package main
import (
"fmt"
)
type BInterface interface {
test01()
}
type CInterface interface {
test02()
}
type AInterface interface {
BInterface
CInterface
test03()
}
//如果需要实现AInterface,就需要将BInterface CInterface的方法都实现
type Stu struct {
}
func (stu Stu) test01() {
}
func (stu Stu) test02() {
}
func (stu Stu) test03() {
}
type T interface{
}
func main() {
var stu Stu
var a AInterface = stu
a.test01()
}
10 ) 空接口interface{}没有任何方法,所以所有类型都实现了空接口, 即我们可以把任何一个变量 赋给空接口。
package main
import (
"fmt"
)
type BInterface interface {
test01()
}
type CInterface interface {
test02()
}
type AInterface interface {
BInterface
CInterface
test03()
}
//如果需要实现AInterface,就需要将BInterface CInterface的方法都实现
type Stu struct {
}
func (stu Stu) test01() {
}
func (stu Stu) test02() {
}
func (stu Stu) test03() {
}
type T interface{
}
func main() {
var stu Stu
var a AInterface = stu
a.test01()
var t T = stu //ok
fmt.Println(t)
var t2 interface{} = stu
var num1 float64 = 8.8
t2 = num1
t = num1
fmt.Println(t2, t)
}
10.9 接口与继承的区别
10 ) 空接口interface{}没有任何方法,所以所有类型都实现了空接口, 即我们可以把任何一个变量 赋给空接口。
package main
import (
"fmt"
)
type BInterface interface {
test01()
}
type CInterface interface {
test02()
}
type AInterface interface {
BInterface
CInterface
test03()
}
//如果需要实现AInterface,就需要将BInterface CInterface的方法都实现
type Stu struct {
}
func (stu Stu) test01() {
}
func (stu Stu) test02() {
}
func (stu Stu) test03() {
}
type T interface{
}
func main() {
var stu Stu
var a AInterface = stu
a.test01()
var t T = stu //ok
fmt.Println(t)
var t2 interface{} = stu
var num1 float64 = 8.8
t2 = num1
t = num1
fmt.Println(t2, t)
}
1 ) 当A结构体继承了B结构体,那么A结构就自动的继承了B结构体的字段和方法,并且可以直接使用
2 ) 当A结构体需要扩展功能,同时不希望去破坏继承关系,则可以去实现某个接口即可,因此我们可以认为:实现接口是对继承机制的补充.
- 实现接口可以看作是对 继承的一种补充

-
接口和继承解决的解决的问题不同
继承的价值主要在于:解决代码的复用性和可维护性。
接口的价值主要在于:设计,设计好各种规范(方法),让其它自定义类型去实现这些方法。
-
接口比继承更加灵活 Person Student BirdAbleLittleMonkey
接口比继承更加灵活,继承是满足 is-a的关系,而接口只需满足 like-a的关系。
-
接口在一定程度上实现代码解耦
10.10 面向对象编程特性三多态
变量(实例)具有多种形态。面向对象的第三大特征,在Go语言,多态特征是通过接口实现的。可 以按照统一的接口来调用不同的实现。这时接口变量就呈现不同的形态。
在前面的Usb接口案例,Usbusb ,既可以接收手机变量,又可以接收相机变量,就体现了Usb 接 口 多态特性。[点明]

接口体现多态的两种形式
-
多态参数
在前面的Usb接口案例,Usbusb ,即可以接收手机变量,又可以接收相机变量,就体现了Usb 接口多态。
-
多态数组
演示一个案例:给Usb数组中,存放 Phone 结构体 和 Camera结构体变量
案例说明:
package main
import (
"fmt"
)
//声明/定义一个接口
type Usb interface {
//声明了两个没有实现的方法
Start()
Stop()
}
type Phone struct {
name string
}
//让Phone 实现 Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
func (p Phone) Call() {
fmt.Println("手机 在打电话..")
}
type Camera struct {
name string
}
//让Camera 实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
func main() {
//定义一个Usb接口数组,可以存放Phone和Camera的结构体变量
//这里就体现出多态数组
var usbArr [3]Usb
usbArr[0] = Phone{"vivo"}
usbArr[1] = Phone{"小米"}
usbArr[2] = Camera{"尼康"}
fmt.Println(usbArr)
}
10.11 类型断言
package main
import (
"fmt"
)
type Point struct {
x int
y int
}
func main() {
var a interface{}
var point Point = Point{1, 2}
a = point //oK
// 如何将 a 赋给一个Point变量?
var b Point
// b = a 不可以
// b = a.(Point) // 可以
b = a.(Point)
fmt.Println(b) //
}

- 断言介绍
类型断言,由于接口是一般类型,不知道具体类型,如果要转成具体类型,就需要使用类型断言,
在进行类型断言时,如果类型不匹配,就会报 panic, 因此进行类型断言时,要确保原来的空接口指向的就是断言的类型.
- 如何在进行断言时,带上检测机制,如果成功就ok,否则也不要报panic
package main
import (
"fmt"
)
type Point struct {
x int
y int
}
func main() {
//类型断言(带检测的)
var x interface{}
var b2 float32 = 2.1
x = b2 //空接口,可以接收任意类型
// x=>float32 [使用类型断言]
//类型断言(带检测的)
if y, ok := x.(float32); ok {
fmt.Println("convert success")
fmt.Printf("y 的类型是 %T 值是=%v", y, y)
} else {
fmt.Println("convert fail")
}
fmt.Println("继续执行...")
}
- 给Phone结构体增加一个特有的方法call(), 当Usb 接口接收的是Phone 变量时,还需要调用call方法, 走代码:
package main
import (
"fmt"
)
//声明/定义一个接口
type Usb interface {
//声明了两个没有实现的方法
Start()
Stop()
}
type Phone struct {
name string
}
//让Phone 实现 Usb接口的方法
func (p Phone) Start() {
fmt.Println("手机开始工作。。。")
}
func (p Phone) Stop() {
fmt.Println("手机停止工作。。。")
}
func (p Phone) Call() {
fmt.Println("手机 在打电话..")
}
type Camera struct {
name string
}
//让Camera 实现 Usb接口的方法
func (c Camera) Start() {
fmt.Println("相机开始工作。。。")
}
func (c Camera) Stop() {
fmt.Println("相机停止工作。。。")
}
type Computer struct {
}
func (computer Computer) Working(usb Usb) {
usb.Start()
//如果usb是指向Phone结构体变量,则还需要调用Call方法
//类型断言..[注意体会!!!]
if phone, ok := usb.(Phone); ok {
phone.Call()
}
usb.Stop()
}
func main() {
//定义一个Usb接口数组,可以存放Phone和Camera的结构体变量
//这里就体现出多态数组
var usbArr [3]Usb
usbArr[0] = Phone{"vivo"}
usbArr[1] = Phone{"小米"}
usbArr[2] = Camera{"尼康"}
//遍历usbArr
//Phone还有一个特有的方法call(),请遍历Usb数组,如果是Phone变量,
//除了调用Usb 接口声明的方法外,还需要调用Phone 特有方法 call. =》类型断言
var computer Computer
for _, v := range usbArr{
computer.Working(v)
fmt.Println()
}
//fmt.Println(usbArr)
}
十一、文件操作
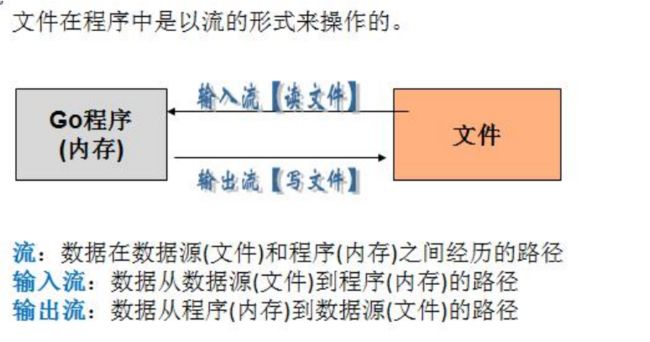
- os .File封装所有文件相关操作,File是一个结构体
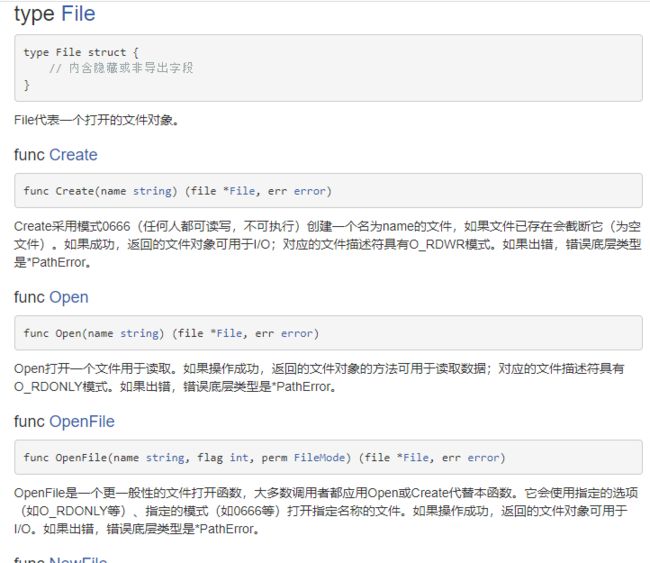
11.1 文件打开与关闭
-
使用的函数和方法
func Open
func Open(name string) (file *File, err error)Open打开一个文件用于读取。如果操作成功,返回的文件对象的方法可用于读取数据;对应的文件描述符具有O_RDONLY模式。如果出错,错误底层类型是*PathError。
func (*File) Close
func (f *File) Close() errorClose关闭文件f,使文件不能用于读写。它返回可能出现的错误。
-
案例演示
package main
import (
"fmt"
"os"
)
func main() {
//打开文件
//概念说明: file 的叫法
//1. file 叫 file对象
//2. file 叫 file指针
//3. file 叫 file 文件句柄
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//输出下文件,看看文件是什么, 看出file 就是一个指针 *File
fmt.Printf("file=%v", file)
//关闭文件
err = file.Close()
if err != nil {
fmt.Println("close file err=", err)
}
}
11.2 读文件操作
1 ) 读取文件的内容并显示在终端(带缓冲区的方式),使用os.Open,file.Close,bufio.NewReader(), reader.ReadString 函数和方法.
package main
import (
"fmt"
"os"
"bufio"
"io"
)
func main() {
//打开文件
//概念说明: file 的叫法
//1. file 叫 file对象
//2. file 叫 file指针
//3. file 叫 file 文件句柄
file , err := os.Open("d:/test.txt")
if err != nil {
fmt.Println("open file err=", err)
}
//当函数退出时,要及时的关闭file
defer file.Close() //要及时关闭file句柄,否则会有内存泄漏.
// 创建一个 *Reader ,是带缓冲的
/*
const (
defaultBufSize = 4096 //默认的缓冲区为4096
)
*/
reader := bufio.NewReader(file)
//循环的读取文件的内容
for {
str, err := reader.ReadString('\n') // 读到一个换行就结束
if err == io.EOF { // io.EOF表示文件的末尾
break
}
//输出内容
fmt.Printf(str)
}
fmt.Println("文件读取结束...")
}
2 ) 一次性读取文件的内容并显示在终端(使用ioutil一次将整个文件读入到内存中),这种方式适用于文件 不大的情况。相关方法和函数(ioutil.ReadFile)
package main
import (
"fmt"
"io/ioutil"
)
func main() {
//使用ioutil.ReadFile一次性将文件读取到位
file := "d:/test.txt"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Printf("read file err=%v", err)
}
//把读取到的内容显示到终端
//fmt.Printf("%v", content) // []byte
fmt.Printf("%v", string(content)) // []byte
//我们没有显式的Open文件,因此也不需要显式的Close文件
//因为,文件的Open和Close被封装到 ReadFile 函数内部
}
11.3 写文件操作
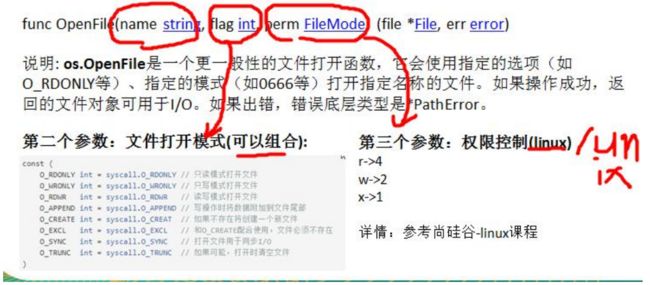
1 ) 创建一个新文件,写入内容 5 句 “hello,Gardon”
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
//创建一个新文件,写入内容 5句 "hello, Gardon"
//1 .打开文件 d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句 "hello, Gardon"
str := "hello,Gardon\r\n" // \r\n 表示换行
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实
//内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据
//真正写入到文件中, 否则文件中会没有数据!!!
writer.Flush()
}
2 ) 打开一个存在的文件中,将原来的内容覆盖成新的内容 10 句 “你好,Golang Roadmap!”
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
//打开一个存在的文件中,将原来的内容覆盖成新的内容10句 "你好,Golang Roadmap!"
//创建一个新文件,写入内容 5句 "hello, Gardon"
//1 .打开文件已经存在文件, d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_TRUNC, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句 "你好,Golang Roadmap!"
str := "你好,Golang Roadmap!\r\n" // \r\n 表示换行
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实
//内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据
//真正写入到文件中, 否则文件中会没有数据!!!
writer.Flush()
}
3 ) 打开一个存在的文件,在原来的内容追加内容 ‘ABC!ENGLISH!’
package main
import (
"fmt"
"bufio"
"os"
)
func main() {
//打开一个存在的文件,在原来的内容追加内容 'ABC! ENGLISH!'
//1 .打开文件已经存在文件, d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//准备写入5句 "你好,Golang Roadmap!"
str := "ABC,ENGLISH!\r\n" // \r\n 表示换行
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实
//内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据
//真正写入到文件中, 否则文件中会没有数据!!!
writer.Flush()
}
4 ) 打开一个存在的文件,将原来的内容读出显示在终端,并且追加 5 句"hello,北京!" 代码实现:
package main
import (
"fmt"
"bufio"
"os"
"io"
)
func main() {
//打开一个存在的文件,将原来的内容读出显示在终端,并且追加5句"hello,北京!"
//1 .打开文件已经存在文件, d:/abc.txt
filePath := "d:/abc.txt"
file, err := os.OpenFile(filePath, os.O_RDWR | os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//及时关闭file句柄
defer file.Close()
//先读取原来文件的内容,并显示在终端.
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF { //如果读取到文件的末尾
break
}
//显示到终端
fmt.Print(str)
}
//准备写入5句 "你好,Golang Roadmap!"
str := "hello,北京!\r\n" // \r\n 表示换行
//写入时,使用带缓存的 *Writer
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
//因为writer是带缓存,因此在调用WriterString方法时,其实
//内容是先写入到缓存的,所以需要调用Flush方法,将缓冲的数据
//真正写入到文件中, 否则文件中会没有数据!!!
writer.Flush()
}
5)编程一个程序,将一个文件的内容,写入到另外一个文件。注:这两个文件已经存在了
说明:使用ioutil.ReadFile/ioutil.WriteFile 完成写文件的任务
package main
import (
"fmt"
"io/ioutil"
)
func main() {
//将d:/abc.txt 文件内容导入到 e:/kkk.txt
//1. 首先将 d:/abc.txt 内容读取到内存
//2. 将读取到的内容写入 e:/kkk.txt
file1Path := "d:/abc.txt"
file2Path := "e:/kkk.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil {
//说明读取文件有错误
fmt.Printf("read file err=%v\n", err)
return
}
err = ioutil.WriteFile(file2Path, data, 0666)
if err != nil {
fmt.Printf("write file error=%v\n", err)
}
}
11.4 判断文件是否存在
golang判断文件或文件夹是否存在的方法为使用os.Stat()函数返回的错误值进行判断:
- 如果返回的错误为nil,说明文件或文件夹存在
- 如果返回的错误类型使用os.IsNotExist()判断为true,说明文件或文件夹不存在
- 如果返回的错误为其他类型,则不确定是否存在
func PathExists(path string)(bool,error){
_, err := os.Stat(path)
if err == nil{//文件或目录存在
return true,nil
}
if os.IsNotExit(err){
return false,nil
}
return false,err
}
11.5 文件复制
将一张图片/电影/mp 3 拷贝到另外一个文件 e:/abc.jpg io包
funcCopy(dstWriter,srcReader)(writtenint 64 ,errerror)
注意;Copy 函数是 io包提供的.
package main
import (
"fmt"
"os"
"io"
"bufio"
)
//自己编写一个函数,接收两个文件路径 srcFileName dstFileName
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
defer srcFile.Close()
//通过srcfile ,获取到 Reader
reader := bufio.NewReader(srcFile)
//打开dstFileName
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY | os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
//通过dstFile, 获取到 Writer
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
return io.Copy(writer, reader)
}
func main() {
//将d:/flower.jpg 文件拷贝到 e:/abc.jpg
//调用CopyFile 完成文件拷贝
srcFile := "d:/flower.jpg"
dstFile := "e:/abc.jpg"
_, err := CopyFile(dstFile, srcFile)
if err == nil {
fmt.Printf("拷贝完成\n")
} else {
fmt.Printf("拷贝错误 err=%v\n", err)
}
}
11.6 命令行参数
我们希望能够获取到命令行输入的各种参数
-
os.Args 是一个string的切片,用来存储所有的命令行参数
package main import ( "fmt" "os" ) func main() { fmt.Println("命令行的参数有", len(os.Args)) //遍历os.Args切片,就可以得到所有的命令行输入参数值 for i, v := range os.Args { fmt.Printf("args[%v]=%v\n", i, v) } }
执行结果
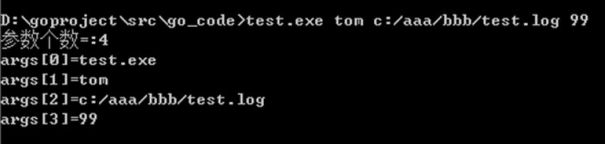
- flag包用来解析命令行参数
前面的方式是比较原生的方式,对解析参数不是特别的方便,特别是带有指定参数形式的命
令行。比如:cmd>main.exe -f c:/aaa.txt -p 200 - u root
这样的形式命令行,go设计者给我们提供了 flag包,可以方便的解析命令行参数,而且参数顺序可以随意
package main
import (
"fmt"
"flag"
)
func main() {
//定义几个变量,用于接收命令行的参数值
var user string
var pwd string
var host string
var port int
//&user 就是接收用户命令行中输入的 -u 后面的参数值
//"u" ,就是 -u 指定参数
//"" , 默认值
//"用户名,默认为空" 说明
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为localhost")
flag.IntVar(&port, "port", 3306, "端口号,默认为3306")
//这里有一个非常重要的操作,转换, 必须调用该方法
flag.Parse()
//输出结果
fmt.Printf("user=%v pwd=%v host=%v port=%v",
user, pwd, host, port)
}
执行结果

11.7 JSON序列化
-
介绍
json序列化是指,将有 key-valu e结构的数据类型(比如结构体、 map 、切片)序列化成json字符串的操作。
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string `json:"monster_name"` //反射机制
Age int `json:"monster_age"`
Birthday string //....
Sal float64
Skill string
}
func testStruct() {
//演示
monster := Monster{
Name :"牛魔王",
Age : 500 ,
Birthday : "2011-11-11",
Sal : 8000.0,
Skill : "牛魔拳",
}
//将monster 序列化
data, err := json.Marshal(&monster) //..
if err != nil {
fmt.Printf("序列号错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("monster序列化后=%v\n", string(data))
}
//将map进行序列化
func testMap() {
//定义一个map
var a map[string]interface{}
//使用map,需要make
a = make(map[string]interface{})
a["name"] = "红孩儿"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
//将monster 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("a map 序列化后=%v\n", string(data))
}
//演示对切片进行序列化, 我们这个切片 []map[string]interface{}
func testSlice() {
var slice []map[string]interface{}
var m1 map[string]interface{}
//使用map前,需要先make
m1 = make(map[string]interface{})
m1["name"] = "jack"
m1["age"] = "7"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
//使用map前,需要先make
m2 = make(map[string]interface{})
m2["name"] = "tom"
m2["age"] = "20"
m2["address"] = [2]string{"墨西哥","夏威夷"}
slice = append(slice, m2)
//将切片进行序列化操作
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("slice 序列化后=%v\n", string(data))
}
//对基本数据类型序列化,对基本数据类型进行序列化意义不大
func testFloat64() {
var num1 float64 = 2345.67
//对num1进行序列化
data, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
fmt.Printf("num1 序列化后=%v\n", string(data))
}
func main() {
//演示将结构体, map , 切片进行序列号
testStruct()
testMap()
testSlice()//演示对切片的序列化
testFloat64()//演示对基本数据类型的序列化
}
-
注意事项
package main import ( "fmt" "encoding/json" ) //定义一个结构体 type Monster struct { Name string `json:"monster_name"` //反射机制 Age int `json:"monster_age"` Birthday string //.... Sal float64 Skill string } func testStruct() { //演示 monster := Monster{ Name :"牛魔王", Age : 500 , Birthday : "2011-11-11", Sal : 8000.0, Skill : "牛魔拳", } //将monster 序列化 data, err := json.Marshal(&monster) //.. if err != nil { fmt.Printf("序列号错误 err=%v\n", err) } //输出序列化后的结果 fmt.Printf("monster序列化后=%v\n", string(data)) } //将map进行序列化 func testMap() { //定义一个map var a map[string]interface{} //使用map,需要make a = make(map[string]interface{}) a["name"] = "红孩儿" a["age"] = 30 a["address"] = "洪崖洞" //将a这个map进行序列化 //将monster 序列化 data, err := json.Marshal(a) if err != nil { fmt.Printf("序列化错误 err=%v\n", err) } //输出序列化后的结果 fmt.Printf("a map 序列化后=%v\n", string(data)) } //演示对切片进行序列化, 我们这个切片 []map[string]interface{} func testSlice() { var slice []map[string]interface{} var m1 map[string]interface{} //使用map前,需要先make m1 = make(map[string]interface{}) m1["name"] = "jack" m1["age"] = "7" m1["address"] = "北京" slice = append(slice, m1) var m2 map[string]interface{} //使用map前,需要先make m2 = make(map[string]interface{}) m2["name"] = "tom" m2["age"] = "20" m2["address"] = [2]string{"墨西哥","夏威夷"} slice = append(slice, m2) //将切片进行序列化操作 data, err := json.Marshal(slice) if err != nil { fmt.Printf("序列化错误 err=%v\n", err) } //输出序列化后的结果 fmt.Printf("slice 序列化后=%v\n", string(data)) } //对基本数据类型序列化,对基本数据类型进行序列化意义不大 func testFloat64() { var num1 float64 = 2345.67 //对num1进行序列化 data, err := json.Marshal(num1) if err != nil { fmt.Printf("序列化错误 err=%v\n", err) } //输出序列化后的结果 fmt.Printf("num1 序列化后=%v\n", string(data)) } func main() { //演示将结构体, map , 切片进行序列号 testStruct() testMap() testSlice()//演示对切片的序列化 testFloat64()//演示对基本数据类型的序列化 }
11.8 JSON反序列化
json反序列化是指,将json字符串反序列化成对应的数据类型(比如结构体、map、切片)的操作
- 这里我们介绍一下将json字符串反序列化成结构体、map和切片
- 反序列化,不需要make,因为make操作被封装到 Unmarshal函数
package main
import (
"fmt"
"encoding/json"
)
//定义一个结构体
type Monster struct {
Name string
Age int
Birthday string //....
Sal float64
Skill string
}
//演示将json字符串,反序列化成struct
func unmarshalStruct() {
//说明str 在项目开发中,是通过网络传输获取到.. 或者是读取文件获取到
str := "{\"Name\":\"牛魔王~~~\",\"Age\":500,\"Birthday\":\"2011-11-11\",\"Sal\":8000,\"Skill\":\"牛魔拳\"}"
//定义一个Monster实例
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 monster=%v monster.Name=%v \n", monster, monster.Name)
}
//将map进行序列化
func testMap() string {
//定义一个map
var a map[string]interface{}
//使用map,需要make
a = make(map[string]interface{})
a["name"] = "红孩儿~~~~~~"
a["age"] = 30
a["address"] = "洪崖洞"
//将a这个map进行序列化
//将monster 序列化
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误 err=%v\n", err)
}
//输出序列化后的结果
//fmt.Printf("a map 序列化后=%v\n", string(data))
return string(data)
}
//演示将json字符串,反序列化成map
func unmarshalMap() {
//str := "{\"address\":\"洪崖洞\",\"age\":30,\"name\":\"红孩儿\"}"
str := testMap()
//定义一个map
var a map[string]interface{}
//反序列化
//注意:反序列化map,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 a=%v\n", a)
}
//演示将json字符串,反序列化成切片
func unmarshalSlice() {
str := "[{\"address\":\"北京\",\"age\":\"7\",\"name\":\"jack\"}," +
"{\"address\":[\"墨西哥\",\"夏威夷\"],\"age\":\"20\",\"name\":\"tom\"}]"
//定义一个slice
var slice []map[string]interface{}
//反序列化,不需要make,因为make操作被封装到 Unmarshal函数
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Printf("unmarshal err=%v\n", err)
}
fmt.Printf("反序列化后 slice=%v\n", slice)
}
func main() {
unmarshalStruct()
unmarshalMap()
unmarshalSlice()
}
-
1 ) 在反序列化一个json字符串时,要确保反序列化后的数据类型和原来序列化前的数据类型一致。
2 ) 如果json字符串是通过程序获取到的,则不需要再对 “ 转义处理。
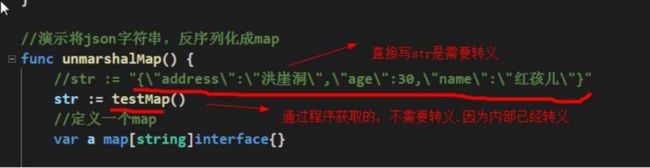
十二、单元测试
- 传统方法的缺点分析
1 ) 不方便, 我们需要在main函数中去调用,这样就需要去修改main函数,如果现在项目正在运行,就可能去停止项目。
2 ) 不利于管理,因为当我们测试多个函数或者多个模块时,都需要写在main函数,不利于我们管理和清晰我们思路
3 ) 引出单元测试。->testing 测试框架 可以很好解决问题。
12.1 单元测试基本介绍
1 ) 确保每个函数是可运行,并且运行结果是正确的
2 ) 确保写出来的代码性能是好的,
3 ) 单元测试能及时的发现程序设计或实现的逻辑错误,使问题及早暴露,便于问题的定位解决,而性能测试的重点在于发现程序设计上的一些问题,让程序能够在高并发的情况下还能保持稳定
cal.go
package cal
//一个被测试函数
func addUpper(n int) int {
res := 0
for i := 1; i <= n - 1; i++ {
res += i
}
return res
}
//求两个数的查
func getSub(n1 int, n2 int) int {
return n1 - n2
}
cal_test.go
package cal
import (
"fmt"
"testing" //引入go 的testing框架包
)
//编写要给测试用例,去测试addUpper是否正确
func TestAddUpper(t *testing.T) {
//调用
res := addUpper(10)
if res != 55 {
//fmt.Printf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
t.Fatalf("AddUpper(10) 执行错误,期望值=%v 实际值=%v\n", 55, res)
}
//如果正确,输出日志
t.Logf("AddUpper(10) 执行正确...")
}
func TestHello(t *testing.T) {
fmt.Println("TestHello被调用..")
}
特别说明 : 测试时,可能需要暂时退出 360 。(因为 360 可能会认为生成的测试用例程序是木马)
演示如何进行单元测试:
单元测试的运行原理示意图:

12.2 单元测试总结
1 ) 测试用例文件名必须以 _test.go 结尾。 比如 cal_test.go,cal 不是固定的。
2 ) 测试用例函数必须以Test开头,一般来说就是Test+被测试的函数名,比如TestAddUpper
3 ) TestAddUpper(t*tesingT) 的形参类型必须是 *testingT 【看一下手册】
4 ) 一个测试用例文件中,可以有多个测试用例函数,比如 TestAddUpper、TestSub
5 ) 运行测试用例指令
- ( 1 )cmd>gotest [如果运行正确,无日志,错误时,会输出日志]
- ( 2 )cmd>gotest-v [运行正确或是错误,都输出日志]
6 ) 当出现错误时,可以使用tFatalf 来格式化输出错误信息,并退出程序
7 ) tLogf 方法可以输出相应的日志
8 ) 测试用例函数,并没有放在main函数中,也执行了,这就是测试用例的方便之处[原理图]
9 ) PASS表示测试用例运行成功,FAIL 表示测试用例运行失败
10 ) 测试单个文件,一定要带上被测试的原文件 gotest-v cal_testgocalgo
11 )测试单个方法 gotest-v-testrun TestAddUpper
十六、goroutine和channel
16.1 goroutine线程-基本介绍
- 进程就是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位
- 线程是进程的一个执行实例,是程序执行的最小单元,它是比进程更小的能独立运行的基本单位
- 一个进程可以创建销毁多个线程,同一个进程中的多个线程可以并发执行
- 一个程序至少一个进程,一个进程至少一个线程
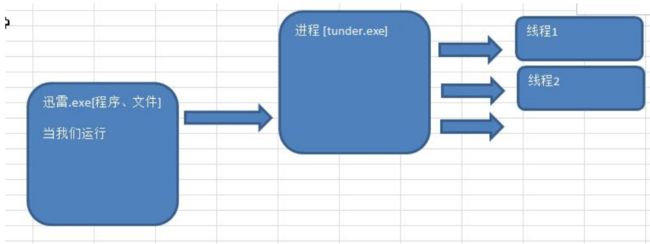
- 并发和并行
1 ) 多线程程序在单核上运行,就是并发
2 ) 多线程程序在多核上运行,就是并行
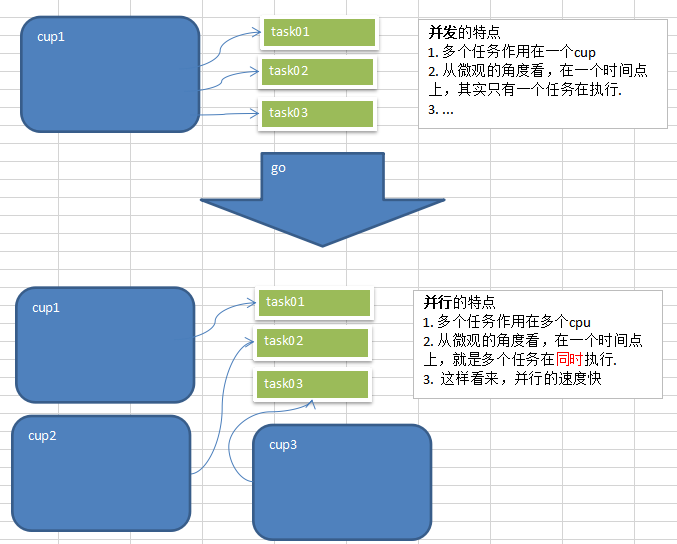
并发:因为是在一个cpu上,比如有10个线程,每个线程执行10毫秒(进行轮询操作),从人的角度看,好像这10个线程都在运行,但是从微观上看,在某一个时间点看,其实只有一个线程在执行,这就是并发。
并行:因为是在多个cpu上(比如有10个cpu),比如有10个线程,每个线程执行10毫秒(各自在不同cpu上执行),从人的角度看,这10个线程都在运行,但是从微观上看,在某一个时间点看,也同时有10个线程在执行,这就是并行。
16.2 Go协程和Go主线程
-
Go主线程(有程序员直接称为线程/也可以理解成进程): 一个Go线程上,可以起多个协程,你可以 这样理解,协程是轻量级的线程[编译器做优化]。
-
Go协程的特点
1 ) 有独立的栈空间
2 ) 共享程序堆空间
3 ) 调度由用户控制
4 ) 协程是轻量级的线程
-
一个示意图

- 请编写一个程序,完成如下功能:
1 ) 在主线程(可以理解成进程)中,开启一个goroutine, 该协程每隔 1 秒输出 “hello,world”
2 ) 在主线程中也每隔一秒输出"hello,golang", 输出 10 次后,退出程序
3 ) 要求主线程和goroutine同时执行
4 ) 画出主线程和协程执行流程图
package main
import (
"fmt"
"strconv"
"time"
)
// 在主线程(可以理解成进程)中,开启一个goroutine, 该协程每隔1秒输出 "hello,world"
// 在主线程中也每隔一秒输出"hello,golang", 输出10次后,退出程序
// 要求主线程和goroutine同时执行
//编写一个函数,每隔1秒输出 "hello,world"
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("tesst () hello,world " + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
func main() {
go test() // 开启了一个协程
for i := 1; i <= 10; i++ {
fmt.Println(" main() hello,golang" + strconv.Itoa(i))
time.Sleep(time.Second)
}
}
输出的效果说明,main这个主线程和 test 协程同时执行
main() hello,golang1
tesst () hello,world 1
main() hello,golang2
tesst () hello,world 2
main() hello,golang3
tesst () hello,world 3
main() hello,golang4
tesst () hello,world 4
main() hello,golang5
tesst () hello,world 5
main() hello,golang6
tesst () hello,world 6
main() hello,golang7
tesst () hello,world 7
main() hello,golang8
tesst () hello,world 8
main() hello,golang9
tesst () hello,world 9
main() hello,golang10
tesst () hello,world 10
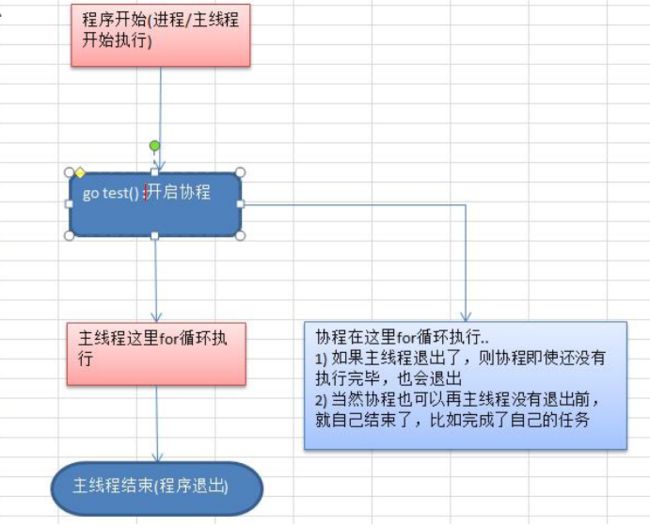
- 协程特点
1 ) 主线程是一个物理线程,直接作用在cpu上的。是重量级的,非常耗费cpu资源。
2 ) 协程从主线程开启的,是轻量级的线程,是逻辑态。对资源消耗相对小。
3 ) Golang的协程机制是重要的特点,可以轻松的开启上万个协程。其它编程语言的并发机制是一般基于线程的,开启过多的线程,资源耗费大,这里就突显Golang在并发上的优势了
16.3 MPG模式基本介绍

- M:操作系统的主线程(是物理线程)
- P:协程执行需要的上下文
- G:协程
16.3.1 MPG模式运行的状态 1

- 当前程序有三个M,如果三个M都在一个cpu运行,就是并发,如果在不同的cpu运行就是并行
- M1,M2,M3正在执行一个G,M1的协程队列有三个,M2的协程队列有3个,M3协程队列有2个
- 从上图可以看到:Go的协程是轻量级的线程,是逻辑态的,Go可以容易的起上万个协程。
- 其他程序c/java的多线程,往往是内核态的,比较重量级,几千个线程可能耗光cpu
16.3.2 MPG模式运行的状态 2

-
设置GOLANG运行的CPU数
-
为了充分了利用多cpu的优势,在Golang程序中,设置运行的cpu数目
package main
import (
"runtime"
"fmt"
)
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
//可以自己设置使用多个cpu
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("ok")
}
- go1.8后,默认让程序运行在多个核上,可以不用设置了
- go1.8前,还是要设置以下,可以更高效的利用cpu
16.4 channel管道介绍
-
使用goroutine 来完成,效率高,但是会出现并发/并行安全问题
package main import ( "fmt" "time" ) // 需求:现在要计算 1-200 的各个数的阶乘,并且把各个数的阶乘放入到map中。 // 最后显示出来。要求使用goroutine完成 // 思路 // 1. 编写一个函数,来计算各个数的阶乘,并放入到 map中. // 2. 我们启动的协程多个,统计的将结果放入到 map中 // 3. map 应该做出一个全局的. var ( myMap = make(map[int]int, 10) ) // test 函数就是计算 n!, 让将这个结果放入到 myMap func test(n int) { res := 1 for i := 1; i <= n; i++ { res *= i } //这里我们将 res 放入到myMap myMap[n] = res //concurrent map writes? } func main() { // 我们这里开启多个协程完成这个任务[200个] for i := 1; i <= 200; i++ { go test(i) } //休眠10秒钟【第二个问题 】 time.Sleep(time.Second * 10) //这里我们输出结果,变量这个结果 for i, v := range myMap { fmt.Printf("map[%d]=%d\n", i, v) } }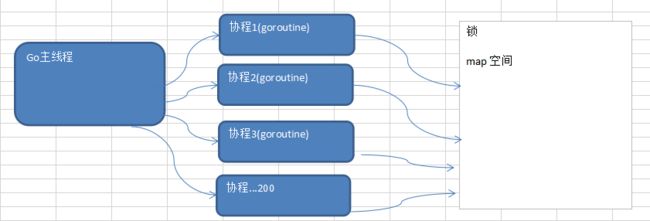
-
这里就提出了不同goroutine如何通信的问题
- 1 ) 全局变量的互斥锁
- 2 ) 使用管道channel来解决
16.4.1 全局变量加锁同步改进程序
- 因为没有对全局变量 m 加锁,因此会出现资源争夺问题,代码会出现错误,提示concurrent map writes
- 解决方案:加入互斥锁
- 我们的数的阶乘很大,结果会越界,可以将求阶乘改成 sum+=uint 64 (i)
package main
import (
"fmt"
_ "time"
"sync"
)
// 需求:现在要计算 1-200 的各个数的阶乘,并且把各个数的阶乘放入到map中。
// 最后显示出来。要求使用goroutine完成
// 思路
// 1. 编写一个函数,来计算各个数的阶乘,并放入到 map中.
// 2. 我们启动的协程多个,统计的将结果放入到 map中
// 3. map 应该做出一个全局的.
var (
myMap = make(map[int]int, 10)
//声明一个全局的互斥锁
//lock 是一个全局的互斥锁,
//sync 是包: synchornized 同步
//Mutex : 是互斥
lock sync.Mutex
)
// test 函数就是计算 n!, 让将这个结果放入到 myMap
func test(n int) {
res := 1
for i := 1; i <= n; i++ {
res *= i
}
//这里我们将 res 放入到myMap
//加锁
lock.Lock()
myMap[n] = res //concurrent map writes?
//解锁
lock.Unlock()
}
func main() {
// 我们这里开启多个协程完成这个任务[200个]
for i := 1; i <= 20; i++ {
go test(i)
}
//休眠10秒钟【第二个问题 】
//time.Sleep(time.Second * 5)
//这里我们输出结果,变量这个结果
lock.Lock()
for i, v := range myMap {
fmt.Printf("map[%d]=%d\n", i, v)
}
lock.Unlock()
}
16.4.2 为什么需要channel
- 前面使用全局变量加锁同步来解决goroutine的通讯,但不完美
- 主线程在等待所有goroutine全部完成的时间很难确定,我们这里设置 10 秒,仅仅是估算。
- 如果主线程休眠时间长了,会加长等待时间,如果等待时间短了,可能还有goroutine处于工作状态,这时也会随主线程的退出而销毁
- 通过全局变量加锁同步来实现通讯,也并不利用多个协程对全局变量的读写操作。
- 上面种种分析都在呼唤一个新的通讯机制-channel
16.4.3 channel介绍
- channle本质就是一个数据结构-队列【示意图】
- 数据是先进先出【FIFO:firstinfirstout】
- 线程安全,多goroutine访问时,不需要加锁,就是说channel本身就是线程安全的
- channel有类型的,一个string的channel只能存放string类型数据。
- 示意图:
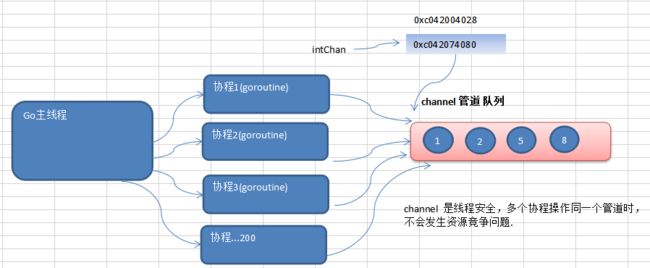
-
定义声明channel
var 变量名 chan 数据类型- 举例:
var intChan chan int(intChan用于存放int数据) var mapChan chan map[int]string(mapChan用于存放map[int]string类型) var perChan chan Person var perChan2 chan *Person
说明
- channel是引用类型
- channel必须初始化才能写入数据, 即make后才能使用
- 管道是有类型的,intChan 只能写入 整数 int
16.5 管道初始化写入数据读出数据
package main
import (
"fmt"
)
func main() {
//演示一下管道的使用
//1. 创建一个可以存放3个int类型的管道
var intChan chan int
intChan = make(chan int, 3)
//2. 看看intChan是什么
fmt.Printf("intChan 的值=%v intChan本身的地址=%p\n", intChan, &intChan)
//3. 向管道写入数据
intChan<- 10
num := 211
intChan<- num
intChan<- 50
// //如果从channel取出数据后,可以继续放入
<-intChan
intChan<- 98//注意点, 当我们给管写入数据时,不能超过其容量
//4. 看看管道的长度和cap(容量)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 3, 3
//5. 从管道中读取数据
var num2 int
num2 = <-intChan
fmt.Println("num2=", num2)
fmt.Printf("channel len= %v cap=%v \n", len(intChan), cap(intChan)) // 2, 3
//6. 在没有使用协程的情况下,如果我们的管道数据已经全部取出,再取就会报告 deadlock
num3 := <-intChan
num4 := <-intChan
//num5 := <-intChan
fmt.Println("num3=", num3, "num4=", num4/*, "num5=", num5*/)
}
16.6 注意事项
- channel中只能存放指定的数据类型
- channle的数据放满后,就不能再放入了
- 如果从channel取出数据后,可以继续放入
- 在没有使用协程的情况下,如果channel数据取完了,再取,就会报deadlock
- 使用例子
1)创建一个intChan,最多可以存放3个int,演示存3数据到intChan,然后再取出这三个int
package main
import (
"fmt"
)
func main() {
var intChan chan int
intChan = make(chan int, 3)
intChan <- 10
intChan <- 20
intChan <- 10
//因为intChan 的容量为3,再存放会报deadlock
//intChan <- 50
num1 := <-intChan
num2 := <-intChan
num3 := <-intChan
//因为intChan 这时已经没有数据了,再取就会报deadlock
//num3 := <- intChan
fmt.Printf("num1=%v num2=%v num3=%v", num1, num2, num3)
}
2)创建一个mapChan,最多可以存放10个map[string]string的key-val,演示写入和读取
package main
import (
"fmt"
)
func main() {
var mapChan chan map[string]string
mapChan = make(chan map[string]string, 10)
m1 := make(map[string]string, 20)
m1["city1"] = "北京"
m1["city2"] = "天津"
m2 := make(map[string]string, 20)
m2["hero1"] = "宋江"
m2["hero2"] = "武松"
mapChan <- m1
mapChan <- m2
m11 := <-mapChan
m22 := <-mapChan
fmt.Println(m11, m22)
}
3)创建一个catChan,最多可以存放10个Cat结构体变量
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var catChan chan Cat
catChan = make(chan Cat, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
catChan <- cat1
catChan <- cat2
//取出
cat11 := <-catChan
cat22 := <-catChan
fmt.Println(cat11, cat22)
}
4)创建一个catChan2,最多可以存放10个*Cat变量,演示写入和读取的方法
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var catChan chan *Cat
catChan = make(chan *Cat, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
catChan <- &cat1
catChan <- &cat2
//取出
cat11 := <-catChan
cat22 := <-catChan
fmt.Println(cat11, cat22)
}
5)创建一个allChan,最多可以存放10个任意数据类型变量,演示写入和读取的用法
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var allChan chan interface{}
allChan = make(chan interface{}, 10)
cat1 := Cat{Name: "tom", Age: 18}
cat2 := Cat{Name: "tom~", Age: 180}
allChan <- cat1
allChan <- cat2
allChan <- 10
allChan <- "jack"
//取出
cat11 := <-allChan
cat22 := <-allChan
v1 := <-allChan
v2 := <-allChan
fmt.Println(cat11, cat22, v1, v2)
}
6)看下面代码,会输出什么?
package main
import (
"fmt"
)
type Cat struct {
Name string
Age byte
}
func main() {
var allChan chan interface{}
allChan = make(chan interface{}, 10)
cat1 := Cat{Name: "tom", Age: 18}
allChan <- cat1
//取出
newCat := <-allChan //从管道中取出的cat是什么?
fmt.Printf("newCat=%T,newCat=%v\n", newCat, newCat)
//下面的写法是错误的!编译不通过
//fmt.Printf("newCat.Name=%v",newCat.Name)
//使用类型断言
a := newCat.(Cat)
fmt.Printf("newCat.Name=%v", a.Name)
}
-
channel可以声明为只读,或者只写性质
package main import ( "fmt" ) func main() { //管道可以声明为只读或者只写 //1. 在默认情况下下,管道是双向 //var chan1 chan int //可读可写 //2 声明为只写 var chan2 chan<- int chan2 = make(chan int, 3) chan2<- 20 //num := <-chan2 //error fmt.Println("chan2=", chan2) //3. 声明为只读 var chan3 <-chan int num2 := <-chan3 //chan3<- 30 //err fmt.Println("num2", num2) }channel只读和只写的最佳实践案例
package main import ( "fmt" ) // ch chan<- int,这样ch就只能写操作 func send(ch chan<- int, exitChan chan struct{}) { for i := 0; i < 10; i++ { ch <- i } close(ch) var a struct{} exitChan <- a } // ch <-chan int,这样ch就只能读操作 func recv(ch <-chan int, exitChan chan struct{}) { for { v, ok := <-ch if !ok { break } fmt.Println(v) } var a struct{} exitChan <- a } func main() { var ch chan int ch = make(chan int, 10) exitChan := make(chan struct{}, 2) go send(ch, exitChan) go recv(ch, exitChan) var total = 0 for _ = range exitChan { total++ if total == 2 { break } } fmt.Println("结束。。。") }
8)使用select可以解决从管道取数据的阻塞问题
package main
import (
"fmt"
"time"
)
func main() {
//使用select可以解决从管道取数据的阻塞问题
//1.定义一个管道 10个数据int
intChan := make(chan int, 10)
for i := 0; i < 10; i++ {
intChan<- i
}
//2.定义一个管道 5个数据string
stringChan := make(chan string, 5)
for i := 0; i < 5; i++ {
stringChan <- "hello" + fmt.Sprintf("%d", i)
}
//传统的方法在遍历管道时,如果不关闭会阻塞而导致 deadlock
//问题,在实际开发中,可能我们不好确定什么关闭该管道.
//可以使用select 方式可以解决
//label:
for {
select {
//注意: 这里,如果intChan一直没有关闭,不会一直阻塞而deadlock
//,会自动到下一个case匹配
case v := <-intChan :
fmt.Printf("从intChan读取的数据%d\n", v)
time.Sleep(time.Second)
case v := <-stringChan :
fmt.Printf("从stringChan读取的数据%s\n", v)
time.Sleep(time.Second)
default :
fmt.Printf("都取不到了,不玩了, 程序员可以加入逻辑\n")
time.Sleep(time.Second)
return
//break label
}
}
}
9 ) goroutine中使用recover,解决协程中出现panic,导致程序崩溃问题

package main
import (
"fmt"
"time"
)
//函数
func sayHello() {
for i := 0; i < 10; i++ {
time.Sleep(time.Second)
fmt.Println("hello,world")
}
}
//函数
func test() {
//这里我们可以使用defer + recover
defer func() {
//捕获test抛出的panic
if err := recover(); err != nil {
fmt.Println("test() 发生错误", err)
}
}()
//定义了一个map
var myMap map[int]string
myMap[0] = "golang" //error
}
func main() {
go sayHello()
go test()
for i := 0; i < 10; i++ {
fmt.Println("main() ok=", i)
time.Sleep(time.Second)
}
}
16.7 channel关闭与遍历
使用内置函数close可以关闭channel, 当channel关闭后,就不能再向channel写数据了,但是仍然 可以从该channel读取数据
案例演示:
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel
//intChan<- 300
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
}
channel支持for–range的方式进行遍历,请注意两个细节
1 ) 在遍历时,如果channel没有关闭,则回出现deadlock的错误
2 ) 在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
package main
import (
"fmt"
)
func main() {
intChan := make(chan int, 3)
intChan<- 100
intChan<- 200
close(intChan) // close
//这是不能够再写入数到channel
//intChan<- 300
fmt.Println("okook~")
//当管道关闭后,读取数据是可以的
n1 := <-intChan
fmt.Println("n1=", n1)
//遍历管道
intChan2 := make(chan int, 100)
for i := 0; i < 100; i++ {
intChan2<- i * 2 //放入100个数据到管道
}
//遍历管道不能使用普通的 for 循环
// for i := 0; i < len(intChan2); i++ {
// }
//在遍历时,如果channel没有关闭,则会出现deadlock的错误
//在遍历时,如果channel已经关闭,则会正常遍历数据,遍历完后,就会退出遍历
close(intChan2)
for v := range intChan2 {
fmt.Println("v=", v)
}
}
16.8 管道阻塞
- 开启一个writeData协程,向管道intChan中写入50个整数
- 开启一个readData协程,从管道intChan中读取writeData写入的数据
- 注意:writeData和readData操作的是同一个管道
- 主线程需要等待writeData和readData协程都完成工作才能退出管道
- 思路分析:
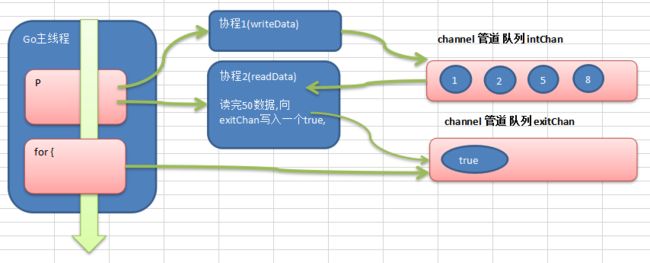
- 代码的实现:
package main
import (
"fmt"
"time"
)
//write Data
func writeData(intChan chan int) {
for i := 1; i <= 50; i++ {
//放入数据
intChan<- i //
fmt.Println("writeData ", i)
//time.Sleep(time.Second)
}
close(intChan) //关闭
}
//read data
func readData(intChan chan int, exitChan chan bool) {
for {
v, ok := <-intChan
if !ok {
break
}
time.Sleep(time.Second)
fmt.Printf("readData 读到数据=%v\n", v)
}
//readData 读取完数据后,即任务完成
exitChan<- true
close(exitChan)
}
func main() {
//创建两个管道
intChan := make(chan int, 10)
exitChan := make(chan bool, 1)
go writeData(intChan)
go readData(intChan, exitChan)
//time.Sleep(time.Second * 10)
for {
_, ok := <-exitChan
if !ok {
break
}
}
}

十七、反射
17.1 基本介绍
1 ) 反射可以在运行时动态获取变量的各种信息, 比如变量的类型(type),类别(kind)
2 ) 如果是结构体变量,还可以获取到结构体本身的信息(包括结构体的字段、方法)
3 ) 通过反射,可以修改变量的值,可以调用关联的方法。
4 ) 使用反射,需要 import(“ reflect ”)
5 ) 示意图

17.2 反射应用场景
- 不知道接口调用哪个函数,根据传入参数在运行时确定调用的具体接口,这种需要对函数或方法反射。例如以下这种桥接模式。
func bridge(funcPtr interface{},args ...interface{})
第一个参数funcPtr以接口的形式传入函数指针,函数参数args以可变参数的形式传入,bridge函数中可以用反射来动态执行funcPtr函数
- 对结构体序列化时,如果结构体有指定Tag,也会使用到反射生成对应的字符串。
17.3 反射重要的函数和概念
- reflect.TypeOf(变量名),获取变量的类型,返回reflext.Type类型
2)reflect.ValueOf(变量名),获取变量的值,返回reflect.Value类型reflect.Value是一个结构体类型。通过reflect.Value,可以获取到该变量的很多信息。
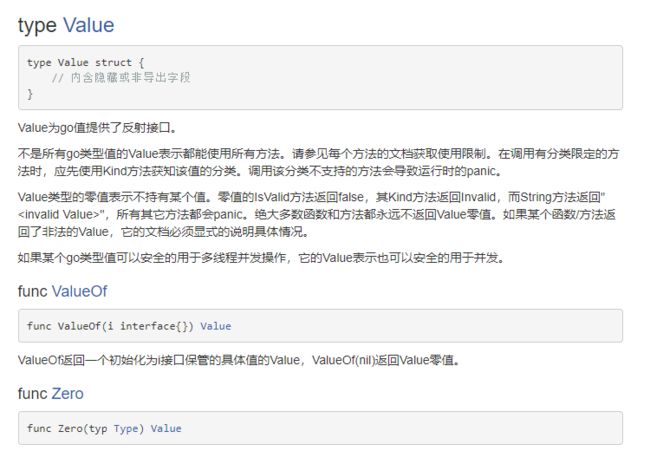
3 ) 变量、interface{} 和 reflect.Value是可以相互转换的,这点在实际开发中,会经常使用到。画 出示意图

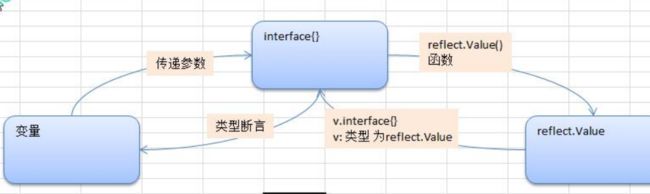
案例
package main
import (
"reflect"
"fmt"
)
//专门演示反射
func reflectTest01(b interface{}) {
//通过反射获取的传入的变量的 type , kind, 值
//1. 先获取到 reflect.Type
rTyp := reflect.TypeOf(b)
fmt.Println("rType=", rTyp)
//2. 获取到 reflect.Value
rVal := reflect.ValueOf(b)
n2 := 2 + rVal.Int()
//n3 := rVal.Float()
fmt.Println("n2=", n2)
//fmt.Println("n3=", n3)
fmt.Printf("rVal=%v rVal type=%T\n", rVal, rVal)
//下面我们将 rVal 转成 interface{}
iV := rVal.Interface()
//将 interface{} 通过断言转成需要的类型
num2 := iV.(int)
fmt.Println("num2=", num2)
}
//专门演示反射[对结构体的反射]
func reflectTest02(b interface{}) {
//通过反射获取的传入的变量的 type , kind, 值
//1. 先获取到 reflect.Type
rTyp := reflect.TypeOf(b)
fmt.Println("rType=", rTyp)
//2. 获取到 reflect.Value
rVal := reflect.ValueOf(b)
//3. 获取 变量对应的Kind
//(1) rVal.Kind() ==>
kind1 := rVal.Kind()
//(2) rTyp.Kind() ==>
kind2 := rTyp.Kind()
fmt.Printf("kind =%v kind=%v\n", kind1, kind2)
//下面我们将 rVal 转成 interface{}
iV := rVal.Interface()
fmt.Printf("iv=%v iv type=%T \n", iV, iV)
//将 interface{} 通过断言转成需要的类型
//这里,我们就简单使用了一带检测的类型断言.
//同学们可以使用 swtich 的断言形式来做的更加的灵活
stu, ok := iV.(Student)
if ok {
fmt.Printf("stu.Name=%v\n", stu.Name)
}
}
type Student struct {
Name string
Age int
}
type Monster struct {
Name string
Age int
}
func main() {
//请编写一个案例,
//演示对(基本数据类型、interface{}、reflect.Value)进行反射的基本操作
//1. 先定义一个int
var num int = 100
reflectTest01(num)
//2. 定义一个Student的实例
stu := Student{
Name : "tom",
Age : 20,
}
reflectTest02(stu)
}
17.4 反射注意事项
1 ) reflect.Value.Kind,获取变量的类别,返回的是一个常量
2 ) Type 和 Kind 的区别
-
Type是类型,Kind是类别,Type 和 Kind 可能是相同的,也可能是不同的
比如: varnumint= 10 num的Type是int,Kind也是int
比如: varstuStudent stu的Type是 pkg 1 .Student,Kind是struct
3)通过反射可以在让变量在interface{}和Reflect.Value之间相互转换,这点在前面画过示意图并在快速入门案例中讲解过,这里我们看下是如何在代码中体现的。

5 ) 通过反射的来修改变量, 注意当使用SetXxx方法来设置需要通过对应的指针类型来完成, 这样才能改变传入的变量的值, 同时需要使用到reflect.Value.Elem()方法
package main
import (
"reflect"
"fmt"
)
//通过反射,修改,
// num int 的值
// 修改 student的值
func reflect01(b interface{}) {
//2. 获取到 reflect.Value
rVal := reflect.ValueOf(b)
// 看看 rVal的Kind是
fmt.Printf("rVal kind=%v\n", rVal.Kind())
//3. rVal
//Elem返回v持有的接口保管的值的Value封装,或者v持有的指针指向的值的Value封装
rVal.Elem().SetInt(20)
}
func main() {
var num int = 10
reflect01(&num)
fmt.Println("num=", num) // 20
//你可以这样理解rVal.Elem()
// num := 9
// ptr *int = &num
// num2 := *ptr //=== 类似 rVal.Elem()
}
6 ) reflect.Value.Elem() 应该如何理解?

17.4 反射实践
1 ) 使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体标签的值
package main
import (
"fmt"
"reflect"
)
//定义了一个Monster结构体
type Monster struct {
Name string `json:"name"`
Age int `json:"monster_age"`
Score float32 `json:"成绩"`
Sex string
}
//方法,返回两个数的和
func (s Monster) GetSum(n1, n2 int) int {
return n1 + n2
}
//方法, 接收四个值,给s赋值
func (s Monster) Set(name string, age int, score float32, sex string) {
s.Name = name
s.Age = age
s.Score = score
s.Sex = sex
}
//方法,显示s的值
func (s Monster) Print() {
fmt.Println("---start~----")
fmt.Println(s)
fmt.Println("---end~----")
}
func TestStruct(a interface{}) {
//获取reflect.Type 类型
typ := reflect.TypeOf(a)
//获取reflect.Value 类型
val := reflect.ValueOf(a)
//获取到a对应的类别
kd := val.Kind()
//如果传入的不是struct,就退出
if kd != reflect.Struct {
fmt.Println("expect struct")
return
}
//获取到该结构体有几个字段
num := val.NumField()
fmt.Printf("struct has %d fields\n", num) //4
//变量结构体的所有字段
for i := 0; i < num; i++ {
fmt.Printf("Field %d: 值为=%v\n", i, val.Field(i))
//获取到struct标签, 注意需要通过reflect.Type来获取tag标签的值
tagVal := typ.Field(i).Tag.Get("json")
//如果该字段于tag标签就显示,否则就不显示
if tagVal != "" {
fmt.Printf("Field %d: tag为=%v\n", i, tagVal)
}
}
//获取到该结构体有多少个方法
numOfMethod := val.NumMethod()
fmt.Printf("struct has %d methods\n", numOfMethod)
//var params []reflect.Value
//方法的排序默认是按照 函数名的排序(ASCII码)
val.Method(1).Call(nil) //获取到第二个方法。调用它
//调用结构体的第1个方法Method(0)
var params []reflect.Value //声明了 []reflect.Value
params = append(params, reflect.ValueOf(10))
params = append(params, reflect.ValueOf(40))
res := val.Method(0).Call(params) //传入的参数是 []reflect.Value, 返回[]reflect.Value
fmt.Println("res=", res[0].Int()) //返回结果, 返回的结果是 []reflect.Value*/
}
func main() {
//创建了一个Monster实例
var a Monster = Monster{
Name: "黄鼠狼精",
Age: 400,
Score: 30.8,
}
//将Monster实例传递给TestStruct函数
TestStruct(a)
}
) 使用反射的方式来获取结构体的tag标签, 遍历字段的值,修改字段值,调用结构体方法(要求: 通过传递地址的方式完成, 在前面案例上修改即可)
3 ) 定义了两个函数test 1 和test 2 ,定义一个适配器函数用作统一处理接口【了解】
4 ) 使用反射操作任意结构体类型:【了解】
5 ) 使用反射创建并操作结构体
十八、TCP编程
Golang的主要设计目标之一就是面向大规模后端服务程序,网络通信这块是服务端 程序必不可少 也是至关重要的一部分。
网络编程有两种:
1 ) TCPsocket编程,是网络编程的主流。之所以叫Tcpsocket编程,是因为底层是基于Tcp/ip协 议的. 比如:QQ聊天 [示意图]
2 ) b/s结构的http编程,我们使用浏览器去访问服务器时,使用的就是http协议,而http底层依 旧是用tcpsocket实现的。[示意图] 比如: 京东商城 【这属于goweb 开发范畴 】
18.1 TCP/IP协议
TCP/IP(TransmissionControlProtocol/InternetProtocol)的简写,中文译名为传输控制协议/因特网互联协议,又叫网络通讯协议,这个协议是Internet最基本的协议、Internet国际互联网络的基础,简单地说,就是由网络层的IP协议和传输层的TCP协议组成的。
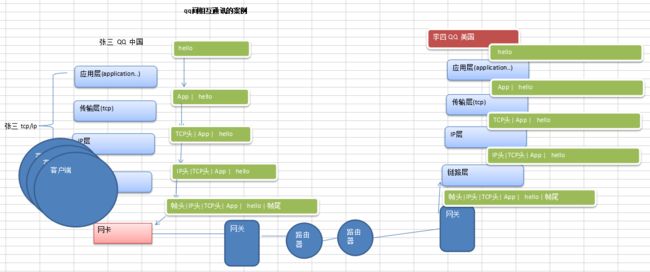
18.2 端口
这里所指的端口不是指物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口。
如果把IP地址比作一间房子,端口就是出入这间房子的门。真正的房子只有几个门,但是一个IP地址的端口 可以有 65536 (即: 256 × 256 )个之多!端口是通过端口号来标记的,端口号只有整数,范围是从 0 到 65535 ( 256 × 256 - 1 )
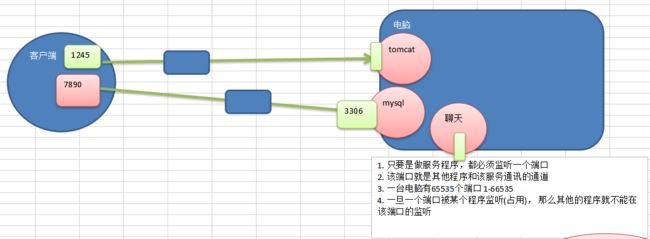
端口分类
-
0 号是保留端口.
-
1 - 1024 是固定端口(程序员不要使用)
又叫有名端口,即被某些程序固定使用,一般程序员不使用.
22 :SSH远程登录协议 23 :telnet使用 21 :ftp使用 25 :smtp服务使用 80 :iis使用 7 :echo服务
-
1025 - 65535 是动态端口,这些端口,程序员可以使用.
端口注意事项
1 ) 在计算机(尤其是做服务器)要尽可能的少开端口
2 ) 一个端口只能被一个程序监听
3 ) 如果使用 netstat –an 可以查看本机有哪些端口在监听
4 ) 可以使用 netstat –anb 来查看监听端口的pid,在结合任务管理器关闭不安全的端口
18.3 socket编程
18.3.1 服务端的处理流程
1 ) 监听端口 8888
2 ) 接收客户端的tcp链接,建立客户端和服务器端的链接
3 ) 创建 goroutine ,处理该链接的请求(通常客户端会通过链接发送请求包)
18.3.2 客户端的处理流程
1 ) 建立与服务端的链接
2 ) 发送请求数据[终端],接收服务器端返回的结果数据
3 ) 关闭链接

18.3.3 代码实现
- 程序框架图示意图
服务器端功能:
- 编写一个服务器端程序,在 8888 端口监听
- 可以和多个客户端创建链接
- 链接成功后,客户端可以发送数据,服务器端接受数据,并显示在终端上
- 先使用telnet 来测试,然后编写客户端程序来测试
- 服务端的代码:
package main
import (
"fmt"
"net" //做网络socket开发时,net包含有我们需要所有的方法和函数
_"io"
)
func process(conn net.Conn) {
//这里我们循环的接收客户端发送的数据
defer conn.Close() //关闭conn
for {
//创建一个新的切片
buf := make([]byte, 1024)
//conn.Read(buf)
//1. 等待客户端通过conn发送信息
//2. 如果客户端没有wrtie[发送],那么协程就阻塞在这里
//fmt.Printf("服务器在等待客户端%s 发送信息\n", conn.RemoteAddr().String())
n , err := conn.Read(buf) //从conn读取
if err != nil {
fmt.Printf("客户端退出 err=%v", err)
return //!!!
}
//3. 显示客户端发送的内容到服务器的终端
fmt.Print(string(buf[:n]))
}
}
func main() {
fmt.Println("服务器开始监听....")
//net.Listen("tcp", "0.0.0.0:8888")
//1. tcp 表示使用网络协议是tcp
//2. 0.0.0.0:8888 表示在本地监听 8888端口
listen, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println("listen err=", err)
return
}
defer listen.Close() //延时关闭listen
//循环等待客户端来链接我
for {
//等待客户端链接
fmt.Println("等待客户端来链接....")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() err=", err)
} else {
fmt.Printf("Accept() suc con=%v 客户端ip=%v\n", conn, conn.RemoteAddr().String())
}
//这里准备其一个协程,为客户端服务
go process(conn)
}
//fmt.Printf("listen suc=%v\n", listen)
}
客户端功能:
- 编写一个客户端端程序,能链接到 服务器端的 8888 端口
- 客户端可以发送单行数据,然后就退出
- 能通过终端输入数据(输入一行发送一行), 并发送给服务器端 []
- 在终端输入exit,表示退出程序.
package main
import (
"fmt"
"net"
"bufio"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "192.168.20.253:8888")
if err != nil {
fmt.Println("client dial err=", err)
return
}
//功能一:客户端可以发送单行数据,然后就退出
reader := bufio.NewReader(os.Stdin) //os.Stdin 代表标准输入[终端]
for {
//从终端读取一行用户输入,并准备发送给服务器
line, err := reader.ReadString('\n')
if err != nil {
fmt.Println("readString err=", err)
}
//如果用户输入的是 exit就退出
line = strings.Trim(line, " \r\n")
if line == "exit" {
fmt.Println("客户端退出..")
break
}
//再将line 发送给 服务器
_, err = conn.Write([]byte(line + "\n"))
if err != nil {
fmt.Println("conn.Write err=", err)
}
}
}
stu, ok := iV.(Student)
if ok {
fmt.Printf("stu.Name=%v\n", stu.Name)
}
}
type Student struct {
Name string
Age int
}
type Monster struct {
Name string
Age int
}
func main() {
//请编写一个案例,
//演示对(基本数据类型、interface{}、reflect.Value)进行反射的基本操作
//1. 先定义一个int
var num int = 100
reflectTest01(num)
//2. 定义一个Student的实例
stu := Student{
Name : "tom",
Age : 20,
}
reflectTest02(stu)
}
17.4 反射注意事项
1 ) reflect.Value.Kind,获取变量的类别,返回的是一个常量
2 ) Type 和 Kind 的区别
- Type是类型,Kind是类别,Type 和 Kind 可能是相同的,也可能是不同的
比如: varnumint= 10 num的Type是int,Kind也是int
比如: varstuStudent stu的Type是 pkg 1 .Student,Kind是struct
3)通过反射可以在让变量在interface{}和Reflect.Value之间相互转换,这点在前面画过示意图并在快速入门案例中讲解过,这里我们看下是如何在代码中体现的。
[外链图片转存中...(img-5wgq244j-1669084586608)]
5 ) 通过反射的来修改变量, 注意当使用SetXxx方法来设置需要通过对应的指针类型来完成, 这样才能改变传入的变量的值, 同时需要使用到reflect.Value.Elem()方法
```go
package main
import (
"reflect"
"fmt"
)
//通过反射,修改,
// num int 的值
// 修改 student的值
func reflect01(b interface{}) {
//2. 获取到 reflect.Value
rVal := reflect.ValueOf(b)
// 看看 rVal的Kind是
fmt.Printf("rVal kind=%v\n", rVal.Kind())
//3. rVal
//Elem返回v持有的接口保管的值的Value封装,或者v持有的指针指向的值的Value封装
rVal.Elem().SetInt(20)
}
func main() {
var num int = 10
reflect01(&num)
fmt.Println("num=", num) // 20
//你可以这样理解rVal.Elem()
// num := 9
// ptr *int = &num
// num2 := *ptr //=== 类似 rVal.Elem()
}
6 ) reflect.Value.Elem() 应该如何理解?
[外链图片转存中…(img-F6Rtj9Bt-1669084586609)]
17.4 反射实践
1 ) 使用反射来遍历结构体的字段,调用结构体的方法,并获取结构体标签的值
package main
import (
"fmt"
"reflect"
)
//定义了一个Monster结构体
type Monster struct {
Name string `json:"name"`
Age int `json:"monster_age"`
Score float32 `json:"成绩"`
Sex string
}
//方法,返回两个数的和
func (s Monster) GetSum(n1, n2 int) int {
return n1 + n2
}
//方法, 接收四个值,给s赋值
func (s Monster) Set(name string, age int, score float32, sex string) {
s.Name = name
s.Age = age
s.Score = score
s.Sex = sex
}
//方法,显示s的值
func (s Monster) Print() {
fmt.Println("---start~----")
fmt.Println(s)
fmt.Println("---end~----")
}
func TestStruct(a interface{}) {
//获取reflect.Type 类型
typ := reflect.TypeOf(a)
//获取reflect.Value 类型
val := reflect.ValueOf(a)
//获取到a对应的类别
kd := val.Kind()
//如果传入的不是struct,就退出
if kd != reflect.Struct {
fmt.Println("expect struct")
return
}
//获取到该结构体有几个字段
num := val.NumField()
fmt.Printf("struct has %d fields\n", num) //4
//变量结构体的所有字段
for i := 0; i < num; i++ {
fmt.Printf("Field %d: 值为=%v\n", i, val.Field(i))
//获取到struct标签, 注意需要通过reflect.Type来获取tag标签的值
tagVal := typ.Field(i).Tag.Get("json")
//如果该字段于tag标签就显示,否则就不显示
if tagVal != "" {
fmt.Printf("Field %d: tag为=%v\n", i, tagVal)
}
}
//获取到该结构体有多少个方法
numOfMethod := val.NumMethod()
fmt.Printf("struct has %d methods\n", numOfMethod)
//var params []reflect.Value
//方法的排序默认是按照 函数名的排序(ASCII码)
val.Method(1).Call(nil) //获取到第二个方法。调用它
//调用结构体的第1个方法Method(0)
var params []reflect.Value //声明了 []reflect.Value
params = append(params, reflect.ValueOf(10))
params = append(params, reflect.ValueOf(40))
res := val.Method(0).Call(params) //传入的参数是 []reflect.Value, 返回[]reflect.Value
fmt.Println("res=", res[0].Int()) //返回结果, 返回的结果是 []reflect.Value*/
}
func main() {
//创建了一个Monster实例
var a Monster = Monster{
Name: "黄鼠狼精",
Age: 400,
Score: 30.8,
}
//将Monster实例传递给TestStruct函数
TestStruct(a)
}
) 使用反射的方式来获取结构体的tag标签, 遍历字段的值,修改字段值,调用结构体方法(要求: 通过传递地址的方式完成, 在前面案例上修改即可)
3 ) 定义了两个函数test 1 和test 2 ,定义一个适配器函数用作统一处理接口【了解】
4 ) 使用反射操作任意结构体类型:【了解】
5 ) 使用反射创建并操作结构体
十八、TCP编程
Golang的主要设计目标之一就是面向大规模后端服务程序,网络通信这块是服务端 程序必不可少 也是至关重要的一部分。
网络编程有两种:
1 ) TCPsocket编程,是网络编程的主流。之所以叫Tcpsocket编程,是因为底层是基于Tcp/ip协 议的. 比如:QQ聊天 [示意图]
2 ) b/s结构的http编程,我们使用浏览器去访问服务器时,使用的就是http协议,而http底层依 旧是用tcpsocket实现的。[示意图] 比如: 京东商城 【这属于goweb 开发范畴 】
18.1 TCP/IP协议
TCP/IP(TransmissionControlProtocol/InternetProtocol)的简写,中文译名为传输控制协议/因特网互联协议,又叫网络通讯协议,这个协议是Internet最基本的协议、Internet国际互联网络的基础,简单地说,就是由网络层的IP协议和传输层的TCP协议组成的。
[外链图片转存中…(img-bHhpGz78-1669084586609)]
[外链图片转存中…(img-p65fyna9-1669084586610)]
18.2 端口
这里所指的端口不是指物理意义上的端口,而是特指TCP/IP协议中的端口,是逻辑意义上的端口。
如果把IP地址比作一间房子,端口就是出入这间房子的门。真正的房子只有几个门,但是一个IP地址的端口 可以有 65536 (即: 256 × 256 )个之多!端口是通过端口号来标记的,端口号只有整数,范围是从 0 到 65535 ( 256 × 256 - 1 )
[外链图片转存中…(img-pWpbL0Xx-1669084586610)]
端口分类
-
0 号是保留端口.
-
1 - 1024 是固定端口(程序员不要使用)
又叫有名端口,即被某些程序固定使用,一般程序员不使用.
22 :SSH远程登录协议 23 :telnet使用 21 :ftp使用 25 :smtp服务使用 80 :iis使用 7 :echo服务
-
1025 - 65535 是动态端口,这些端口,程序员可以使用.
端口注意事项
1 ) 在计算机(尤其是做服务器)要尽可能的少开端口
2 ) 一个端口只能被一个程序监听
3 ) 如果使用 netstat –an 可以查看本机有哪些端口在监听
4 ) 可以使用 netstat –anb 来查看监听端口的pid,在结合任务管理器关闭不安全的端口
18.3 socket编程
18.3.1 服务端的处理流程
1 ) 监听端口 8888
2 ) 接收客户端的tcp链接,建立客户端和服务器端的链接
3 ) 创建 goroutine ,处理该链接的请求(通常客户端会通过链接发送请求包)
18.3.2 客户端的处理流程
1 ) 建立与服务端的链接
2 ) 发送请求数据[终端],接收服务器端返回的结果数据
3 ) 关闭链接
[外链图片转存中…(img-8FZ7dSpE-1669084586611)]
18.3.3 代码实现
- 程序框架图示意图
服务器端功能:
- 编写一个服务器端程序,在 8888 端口监听
- 可以和多个客户端创建链接
- 链接成功后,客户端可以发送数据,服务器端接受数据,并显示在终端上
- 先使用telnet 来测试,然后编写客户端程序来测试
- 服务端的代码:
package main
import (
"fmt"
"net" //做网络socket开发时,net包含有我们需要所有的方法和函数
_"io"
)
func process(conn net.Conn) {
//这里我们循环的接收客户端发送的数据
defer conn.Close() //关闭conn
for {
//创建一个新的切片
buf := make([]byte, 1024)
//conn.Read(buf)
//1. 等待客户端通过conn发送信息
//2. 如果客户端没有wrtie[发送],那么协程就阻塞在这里
//fmt.Printf("服务器在等待客户端%s 发送信息\n", conn.RemoteAddr().String())
n , err := conn.Read(buf) //从conn读取
if err != nil {
fmt.Printf("客户端退出 err=%v", err)
return //!!!
}
//3. 显示客户端发送的内容到服务器的终端
fmt.Print(string(buf[:n]))
}
}
func main() {
fmt.Println("服务器开始监听....")
//net.Listen("tcp", "0.0.0.0:8888")
//1. tcp 表示使用网络协议是tcp
//2. 0.0.0.0:8888 表示在本地监听 8888端口
listen, err := net.Listen("tcp", "0.0.0.0:8888")
if err != nil {
fmt.Println("listen err=", err)
return
}
defer listen.Close() //延时关闭listen
//循环等待客户端来链接我
for {
//等待客户端链接
fmt.Println("等待客户端来链接....")
conn, err := listen.Accept()
if err != nil {
fmt.Println("Accept() err=", err)
} else {
fmt.Printf("Accept() suc con=%v 客户端ip=%v\n", conn, conn.RemoteAddr().String())
}
//这里准备其一个协程,为客户端服务
go process(conn)
}
//fmt.Printf("listen suc=%v\n", listen)
}
客户端功能:
- 编写一个客户端端程序,能链接到 服务器端的 8888 端口
- 客户端可以发送单行数据,然后就退出
- 能通过终端输入数据(输入一行发送一行), 并发送给服务器端 []
- 在终端输入exit,表示退出程序.
package main
import (
"fmt"
"net"
"bufio"
"os"
"strings"
)
func main() {
conn, err := net.Dial("tcp", "192.168.20.253:8888")
if err != nil {
fmt.Println("client dial err=", err)
return
}
//功能一:客户端可以发送单行数据,然后就退出
reader := bufio.NewReader(os.Stdin) //os.Stdin 代表标准输入[终端]
for {
//从终端读取一行用户输入,并准备发送给服务器
line, err := reader.ReadString('\n')
if err != nil {
fmt.Println("readString err=", err)
}
//如果用户输入的是 exit就退出
line = strings.Trim(line, " \r\n")
if line == "exit" {
fmt.Println("客户端退出..")
break
}
//再将line 发送给 服务器
_, err = conn.Write([]byte(line + "\n"))
if err != nil {
fmt.Println("conn.Write err=", err)
}
}
}