PySpark(Spark3.0)
PySpark(Spark3.0)
PySpark简单来说就是Spark提供的Python编程API,包括交互式的PySpark shell和非交互式的Python程序。
1.环境
- Spark3.0
- Hadooop3.2
- Centos7
- Python3.6.8
- Pycharm
- Windos10
其中值得注意的是Python的版本必须是3.6+,以下是Spark官网的说明

前提
Spark3.0的集群已经搭建完毕,本文使用的是Standalone模式的集群
Hadoop3.2分布式集群搭建完毕
2.PySpark shell
2.1安装python3
yum install -y python3
PS:集群中的所有节点都要安装
# 验证
python3 -V

2.1配置环境变量
PySparkShell的启动需要配置SPARK_HOME和PYSPARK_PYTHON这两个环境变量,如果不配置就会使用系统自带的Python2.7.5,由于Python2和Python3的语法是不兼容的,这样就会出现问题,导致PySPark无法使用。
vi /etc/profile
export SPARK_HOME=/opt/spark-3.0.2
export PATH=$PATH:$SPARK_HOME/bin
export PYSPARK_PYTHON=python3
# 刷新环境变量
source /etc/profile

注意:根据自己时间的路径配置
2.2使用PySpark Shell
# 启动Spark
/opt/spark-3.0.2/sbin/start-all.sh
# 在Spark的bin目录中有pySpark的脚本 直接全路径执行
/opt/spark-3.0.2/bin/pyspark
# 使用如下命令退出PySpark Shell
exit()

如果Python的版本不是3.6+ 那就需要检查环境变量配置是否正确以及环境变量是否生效
使用source /etc/profile 使环境变量的配置生效
注意:这样启动只是一个Local模式的PySpark Shell
2.3PySpark的WordCount
WordCount单词次数计算 是一个比较经典的分布式计算样例,相当于Hello World了
启动HDFS并将提前准备好单词文件上传到HDFS
单词数据如下
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
python java scala
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
spark flink mapreduce
hello world
hello world
hello world
hello world
hello world
# 使用vi创建一个文件并将单词数据复制到文件中
vi 1.txt
# 启动hdfs
start-dfs.sh
# 创建存放数据的文件
hdfs dfs -mkdir -p /wc/in
# 上传文件
hdfs dfs -put 1.txt /wc/in/1.txt
hdfs dfs -put 1.txt /wc/in/2.txt
hdfs dfs -put 1.txt /wc/in/3.txt
# 启动PySpark 指定Master 编写WordCount
/opt/spark-3.0.2/bin/pyspark --master spark://master:7077
# PySpark中提供了两个变量sc 和 spark
# 其中sc 是 SparkContext对象
# spark 是 SparkSession对象
# 读取hdfs中的文件生成RDD Python是弱类型的语言 变量的定义比较随意
lines = sc.textFile("hdfs://master:9000/wc/in")
# 将每一行单词使用split 切分 分隔符为" "并压平
# 这里会得到由一个个单独单词组成的RDD
words = lines.flatMap(lambda x: x.split(" "))
# 将单词和1组合在一起 (word,1)
wordAndOne = words.map(lambda x: (x,1))
# 对单词进行分组聚合
reduced = wordAndOne.reduceByKey(lambda x,y: x + y)
# 对聚合后的结果进行排序 默认为升序 False用于指定降序
res = reduced.sortBy(lambda x: x[1],False)
# 将结果收集到Drive 也就是shell
res.collect()
# 将结果保存到HDFS
# 注意这里指定的HDFS不能存在 程序会自动生成
res.saveAsTextFile("hdfs://master:9000/wc/res1")
# 退出PySpark Shell
quit()
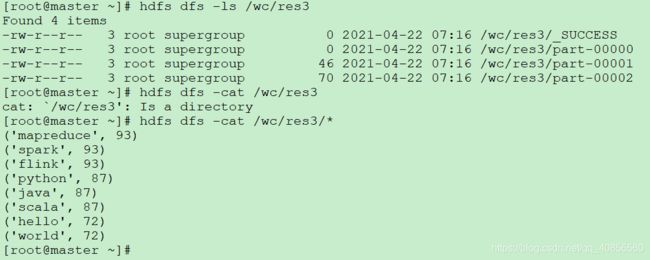
2.4在HDFS中查看结果
hdfs dfs -cat /wc/res1/*
hdfs dfs -ls /wc/res1/

结果分散在多个结果文件中,是全局有序的
3.Pycharm中编写PySpark程序
提前:Windows上安装好了Python3.6+
1.解压Spark
PySpark程序编写是在Windows10上的,首先将Spark3.0的安装包解压,解压到D:\app目录下,解压Spark安装包的原因是因为,安装包中提供了PySpark的依赖。
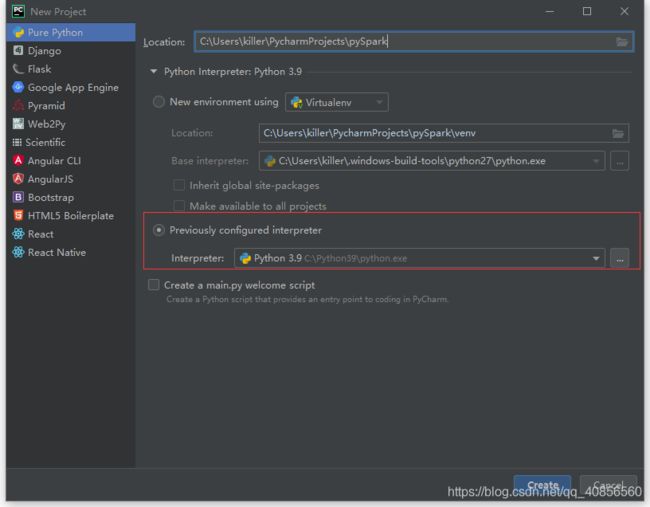
2.创建项目
在创建项目时指定Python解释器的版本
配置项目依赖
File --> Settings --> Project Structure
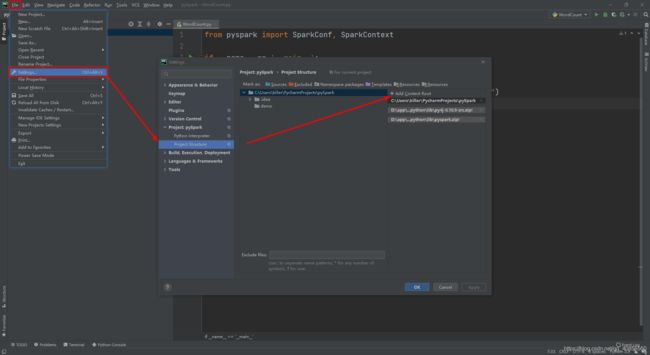
选择Add Content Root,在弹出的文件选择框中,选择Spark安装目录中的python文件夹下的lib目录中的py4j和pyspark的依赖文件,点击OK,将这两个依赖加入到当前项目的依赖库中。
py4j 将Python代码转换为Java代码的库
pyspark Python的Spark编程依赖库

3.编写WordCount程序
新建一个demo文件夹,然后新建一个WordCount.py文件
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# 创建SparkConf对象 配置程序名为 WordCount 运行模式为local[*]
# * 代表当前机器有几个逻辑核就启动几个线程
conf = SparkConf().setMaster("wordCount").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 读取hdfs中的文件生成RDD Python是弱类型的语言 变量的定义比较随意
lines = sc.textFile("hdfs://master:9000/wc/in")
# 将每一行单词使用split 切分 分隔符为" "并压平
# 这里会得到由一个个单独单词组成的RDD
words = lines.flatMap(lambda x: x.split(" "))
# 将单词和1组合在一起 (word,1)
wordAndOne = words.map(lambda x: (x, 1))
# 对单词进行分组聚合
reduced = wordAndOne.reduceByKey(lambda x, y: x + y)
# 对聚合后的结果进行排序 默认为升序 False用于指定降序
res = reduced.sortBy(lambda x: x[1], False)
# 将结果收集到Drive 也就是本地
print(res.collect())
# 将结果保存到HDFS
res.saveAsTextFile("hdfs://master:9000/wc/res3")
# 关闭SparkContext
sc.stop()
程序报错,Could not find valid SPARK_HOME while searching…,主要是因为没有配置SPARK_HOME以及PYSPARK_PYTHON这两环境变量
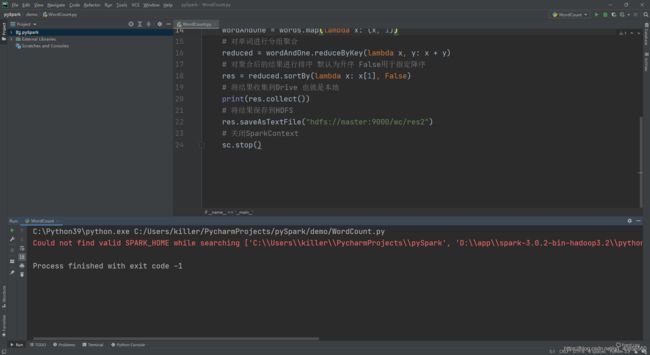
点击右上角的程序配置,配置环境变量,添加SPARK_HOME值为SPARK安装包的解压路径,PYSAPRK_PYTHON指定PySpark的Python命令,注意python版本为3.6+。
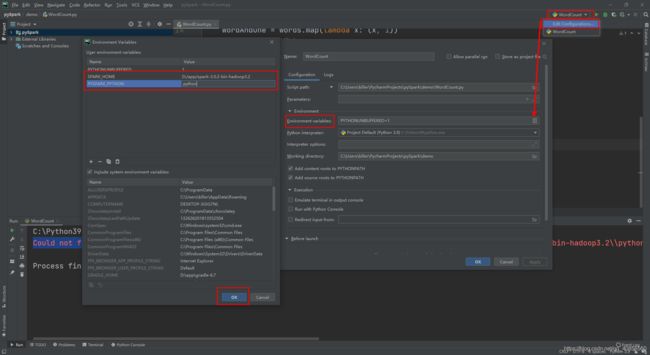
继续运行程序,报错:Permission denied: user=killer

这里主要是由于HDFS的权限问题,需要将当前程序伪装成ROOT用户,按照上面的方法配置环境变量HADOOP_USER_NAME为root
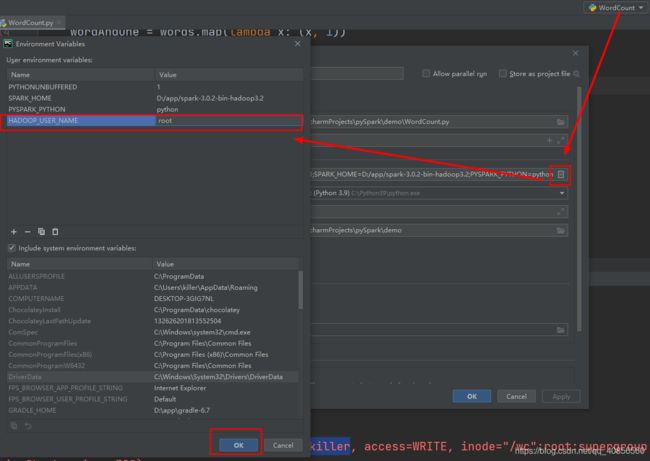
然后运行成功

可以看到打印的单词出现次数,然后在HDFS中查看结果