Spark计算框架
Spark计算框架
- 一、Spark概述
- 二、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
-
- 1、Spark的安装模式
-
- 1.1、Spark(单节点)本地安装
- 1.2 Spark的Standalone部署模式的伪分布式安装
- 1.3Spark的YARN部署模式
- 1.4Spark的Standalone部署模式的完全分布式安装
- 1.5Spark的HA配置
- 2、Spark运行程序的历史日志服务器
- 3、Spark安装部署涉及到的端口
- 三、Spark运行中集群角色
- 四、Spark程序的部署运行的方式 —— Spark执行jar包
- 五、Spark的编程方式
- 六、Spark的核心基础Spark Core
-
- 1、Spark Core中最核心的有两个概念
- 2、RDD的属性(RDD具备的一些特征)
- 3、RDD的弹性的体现
- 4、RDD的特点
- 5、RDD的分类
- 6、RDD的编程
-
- 6.1、RDD的创建操作
- 6.2、RDD的转换操作(转换算子)
- 6.3、RDD的行动算子
- 6.4、RDD的一些比较特殊的行动算子(只针对整数类型的RDD有效)
- 7、RDD的持久化(缓存)
- 8、RDD的检查点机制
- 9、RDD算子的依赖关系
- 10、RDD的两个特殊的使用
- 11、RDD的分区机制
- 七、【补充】Scala的比较器问题
一、Spark概述
Spark的诞生背景
- Spark 2009年诞生的一个技术,诞生的主要原因是因为Hadoop大数据解决方案存在一些弊端
- MR程序是基于磁盘进行运算,因此导致MR程序计算效率底下。
- MR程序无法计算复杂的任务,如果想要实现复杂的计算逻辑,可能编写多个MR Job,其中后续的Job依赖于前一个Job的输出,但是多个Job无法知道前一个job,需要通过任务调度框架自己指定多job的依赖关系。
Spark概念
-
Spark是一个计算框架,内部包含了很多的子组件,子组件解决了各种各样的大数据计算问题,子组件都是计算框架。Spark本身也是一个分布式计算程序,代码的运行也得需要分布式资源调度。
-
Spark主要解决了Hadoop的MR存在的问题,Spark是基于内存运算的一种迭代式计算框架。
-
Spark相当于是Hadoop的升级版本的解决方案,基于内存进行运算,并且Spark内部实现迭代式计算思想,可以在一个应用程序编写复杂的计算逻辑。
-
Spark之所以可以实现基于内存的迭代式计算,主要也是因为Spark Core中的一个核心数据抽象RDD。
-
Spark有一个思想(one stack to rule them all) - 一栈式解决方案,一个技术实现大数据中各种计算场景的应用问题。Spark中包含很多的计算子组件。
- Spark Core:Spark的核心基础,Spark的任务调度规则,Spark的基础语法,数据抽象RDD。
- Spark SQL(结构化数据查询):借助SQL或者Hive版本的HQL进行结构化数据的处理。
- Spark Streaming(准实时计算):内部采用了微批次处理思想,实现数据的实时计算。
数据处理和开发
-
Spark MLlib(算法)
-
Spark GraphX(图计算)
-
Spark R
数据科学或者算法计算
-
官网地址

Spark的特点
- 计算快速:Spark相当于Hadoop的升级版的大数据计算解决方案
- 易用性:Spark提供了多种语法的编程风格
- 兼容性:Spark计算框架和大数据中很多技术无缝衔接,比如Spark支持直接从HDFS、Kafka、HBase、Hive、MySQL…等等地方直接读取数据处理
- 通用性:Spark一个技术栈可以解决大数据中遇到的大部分计算场景问题,而且Spark各个子组件都是基于Spark Core的,因此Spark的各个子组件可以无缝的衔接转换
二、Spark的安装部署(安装部署Spark的Cluster Manager-资源调度管理器的)
【注意】Spark的安装部署,Spark本身就是一个分布式计算框架,如果使用Spark,我们需要使用对应的编程语言编写Spark代码,编写Spark程序不需要部署Spark程序,因此Spark的安装部署主要指的是编写好的Spark程序在什么环境下运行(编写好的Spark程序使用哪种资源调度器进行资源的申请和调度)。
Spark的安装部署就是安装部署Spark运行的资源调度器的。
- Spark的资源调度器常用的有三个:Spark自带的standalone独立调度器、Hadoop的YARN、Apache的Mesos。
1、Spark的安装模式
Spark的安装部署就是安装Spark的不同的资源调度器。
前提:服务器上先安装部署JDK
**本地安装模式(不使用任何的资源调度器,只在本地运行Spark程序):**解压配置环境,Spark程序的运行只能由本地的CPU进行资源调度,这种部署模式只能做测试学习使用。
**Standalone独立调度器部署模式:**使用Spark自带的独立资源调度器进行资源调度。部署Master和Worker节点(主从架构):这种部署模式既可以测试学习、也可以做项目开发部署。
- 伪分布式:将Standalone的master、worker安装到一台节点上,同时worker只有一个
- 完全分布式
- HA高可用模式
四个核心配置文件:
spark-env.sh
spark-default.conf
workers
sbin/spark-config.sh
两个脚本文件的名字
**Hadoop的YARN部署模式:**使用YARN当作Spark程序的资源调度器,部署Spark程序在YARN上运行,这种模式一般项目生产环境用的比较多。
**Apache的Mesos部署模式Mesos部署模式:**使用Mesos当作Spark程序的资源调度器,部署Spark程序在Mesos上运行,这种模式一般项目生产环境用的比较多。
K8S部署模式
1.1、Spark(单节点)本地安装
Step1:从官网下载压缩包,Download --> 往下滑找到Archived releases中的release archives --> 我下载的是3.1.1版本的。

Step2:下载好安装包后,将其上传到虚拟机上面,并进行解压。

Step3:软件重命名

Step4:重命名启动脚本,避免与Hadoop启动脚本起冲突。

Step5:配置环境变量


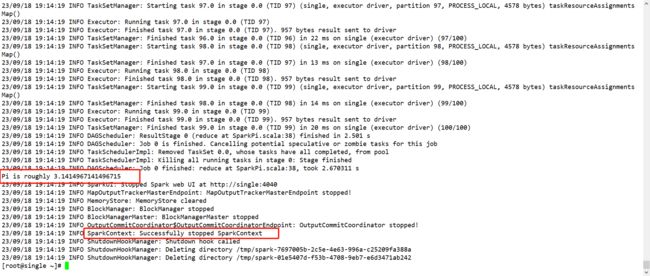
Step6:测试本地模式是否可以使用,显示如图即为安装成功。
spark-submit --class org.apache.spark.examples.SparkPi --master local /opt/app/spark-3.1.1/examples/jars/spark-examples_2.12-3.1.1.jar 100
1.2 Spark的Standalone部署模式的伪分布式安装
Step1:重命名配置文件

Step2:配置workers

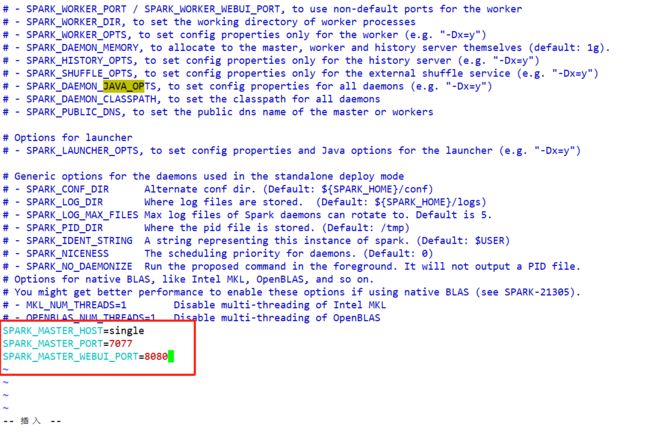
Step3:修改spark-env.sh文件添加如下配置
SPARK_MASTER_HOST=single
SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
Step4:启动Spark程序start-spark-all.sh

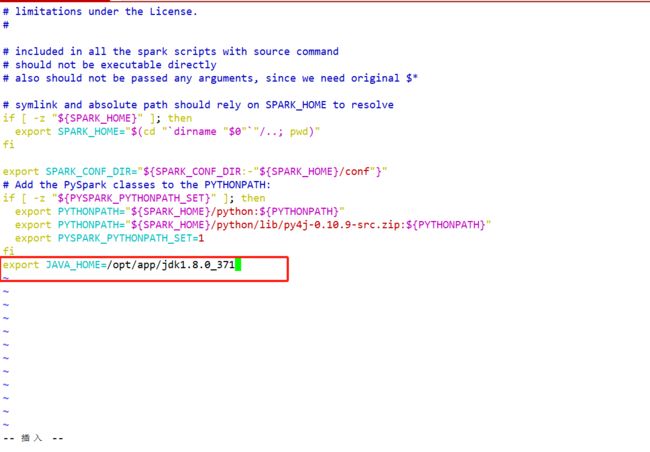
【注意】如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置:
export JAVA_HOME=XXXX
再次启动Spark,即可启动成功!


执行spark-submit --class org.apache.spark.examples.SparkPi --master spark://single:7077 /opt/app/spark-3.1.1/examples/jars/spark-examples_2.12-3.1.1.jar 100



1.3Spark的YARN部署模式
Step1:修改Hadoop配置下的yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabledname>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.vmem-check-enabledname>
<value>falsevalue>
property>

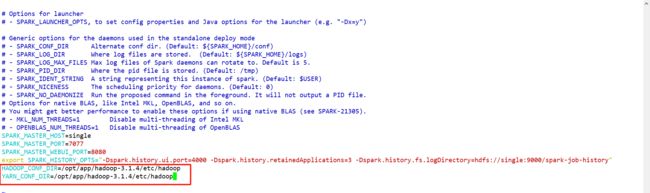
Step2:修改spark-env.sh添加
HADOOP_CONF_DIR=/opt/app/hadoop-3.1.4/etc/hadoop
YARN_CONF_DIR=/opt/app/hadoop-3.1.4/etc/hadoop
Step3:启动yarn

Step4:运行Spark程序spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client /opt/app/spark-3.1.1/examples/jars/spark-examples_2.12-3.1.1.jar 100
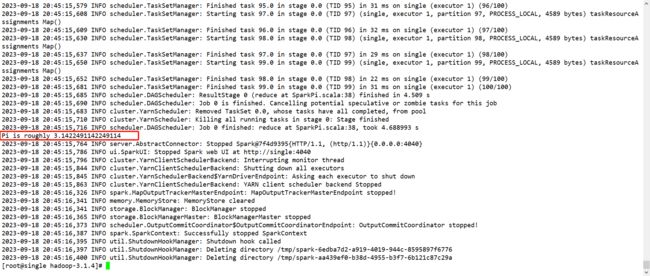


1.4Spark的Standalone部署模式的完全分布式安装
Step1:上传解压修改配置文件名字(/conf路径)和之前步骤一样
Step2:vim workers

Step3:vim spark-env.sh

Step4:vim spark-defaults.conf
Step5:vim spark-config.sh (/sbin目录)

Step6:分发文件
scp -r /opt/app/spark-3.1.1/ root@node2:/opt/app/
scp -r /opt/app/spark-3.1.1/ root@node3:/opt/app/
Step7:统一配置环境变量
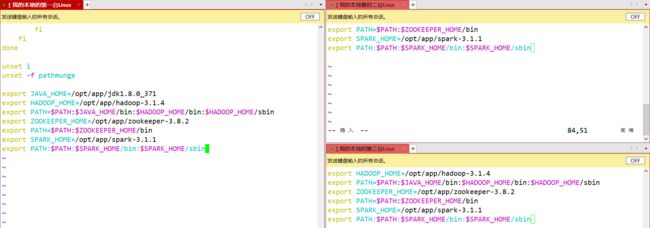
Step8:创建日志文件夹hdfs dfs -mkdir /spark-job-history于node1节点上
Step9:启动历史日志服务器start-history-server.sh

Step10:修改脚本文件的名字

Step11:启动Sparkstart-spark-all.sh

Step12:将spark-env.sh的端口号进行修改(伪分布式环境下不需要修改,完全分布式环境下需要修改)
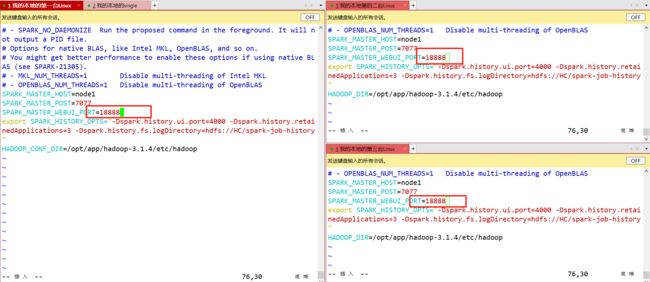
Step13:
Step14:执行测试Spark运行程序spark-submit --class org.apache.spark.examples.SparkPi --master spark://node1:7077 /opt/app/spark-3.1.1/examples/jars/spark-examples_2.12-3.1.1.jar 100



1.5Spark的HA配置
Step1:修改修改配置文件spark-env.shexport SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"
Step2:发送文件给另外两台节点

Step3:启动Sparkstart-spark-all.sh,然后在第二台节点上单独启动master
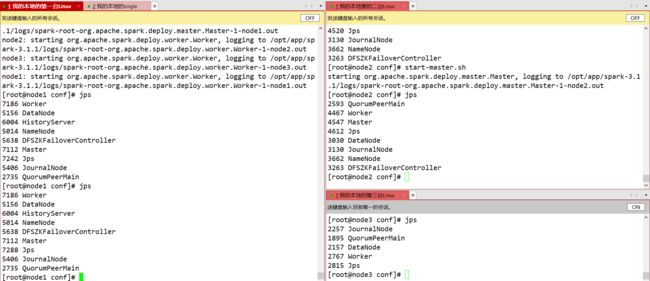


Step4:stop-master.sh(node1)

即配置成功!
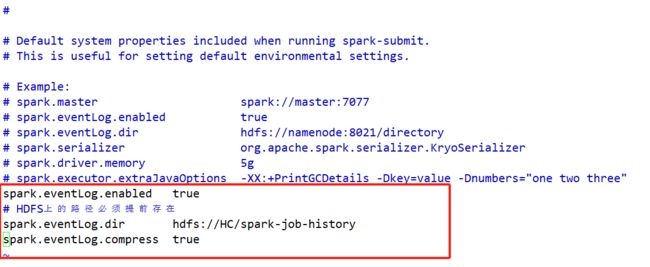
2、Spark运行程序的历史日志服务器
【注意】Spark的历史日志服务器:汇聚Spark的应用程序的计算日志,借助于HDFS完成操作
spark-default.conf
spark.eventLog.enabled true
# HDFS上的路径必须提前存在
spark.eventLog.dir hdfs://single:9000/spark-job-history
spark.eventLog.compress true
--------------------------------------------
spark-env.sh
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://single:9000/spark-job-history"


先开启hdfs,并在hdfs上创建spark-job-history的目录
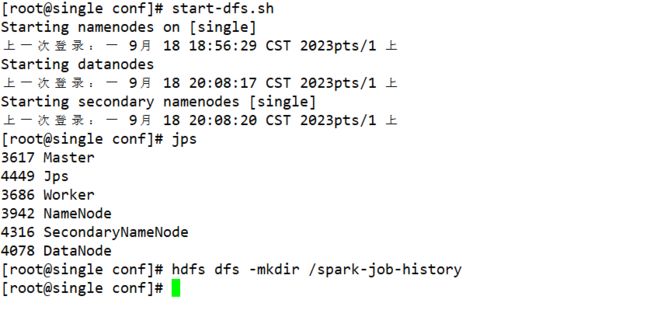
启动历史服务器start-history-server.sh

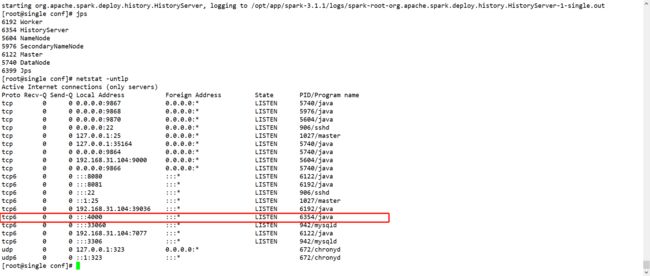
然后运行Spark程序,就可以在历史日志服务器看到运行历史

Spark的历史服务器可以汇总不同运行模式下的spark程序,不仅仅只是在standalone模式下的spark程序。
3、Spark安装部署涉及到的端口
- 7077 spark的standalone模式下的master节点的通信端口
- 4000 Spark的历史日志服务器的默认端口
- 8080/自定义端口 Spark的standalone模式下Master节点的webui端口
- 8088:YARN的web访问端口
三、Spark运行中集群角色
-
Driver驱动程序:就是我们自己编写的代码程序,代码程序包含着程序运行的DAG有向无环图。驱动程序启动之后,会给我们提供一个web界面,用来展示当前Spark程序的运行日志,web界面当Driver运行完成,自动销毁。
-
Cluster Manager:资源管理器
-
Executor:执行器
-
从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点,Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。Worker节点负责具体的业务运行。
从Spark程序运行的层面来看,Spark主要分为驱动器节点和执行器节点。

Spark集群角色
-
Driver驱动程序
-
Driver是一个JVM Process 进程,编写的Spark应用程序就运行在Driver上,由Driver进程执行。
-
Driver首先会向集群管理者(standalone、yarn,mesos)申请spark应用所需的资源,也就是executor,然后集群管理者会根据spark应用所设置的参数在各个worker上分配一定数量的executor,每个executor都占用一定数量的cpu和memory。在申请到应用所需的资源以后,driver就开始调度和执行我们编写的应用代码了。
-
Driver进程会将我们编写的spark应用代码拆分成多个stage,每个stage执行一部分代码片段,并为每个stage创建一批tasks,然后将这些tasks分配到各个executor中执行。
-
-
集群管理器Cluster Manager
-
Spark的集群管理器主要包括Spark Standalone、Yarn、Mesos。
-
Master(ResourceManager):是一个JVM Process 进程,主要负责资源的调度和分配,并进行集群的监控等职责。
-
Worker(NodeManager):是一个JVM Process 进程,一个Worker运行在集群中的一台服务器上,主要负责两个职责,一个是用自己的内存存储RDD的某个或某些partition;另一个是启动其他进程和线程(Executor),对RDD上的partition进行并行的处理和计算。
-
-
执行器Executor
-
是一个JVM Process 进程,一个Worker(NodeManager)上可以运行多个Executor,Executor通过启动多个线程(task)来执行对RDD的partition进行并行计算,也就是执行我们对RDD定义的例如map、flatMap、reduce等算子操作。
-
executor进程宿主在worker节点上,一个worker可以有多个executor。每个executor持有一个线程池,每个线程可以执行一个task,executor执行完task以后将结果返回给driver,
-
每个executor执行的task都属于同一个应用。此外executor还有一个功能就是为应用程序中要求缓存的RDD提供内存式存储,RDD是直接缓存在executor进程内
--num-executors 配置Executor的数量 --driver-memory 配置Driver内存(影响不大) --executor-memory 配置每个Executor的内存大小 --executor-cores 配置每个Executor的CPU core数量 -
Spark中的其他核心概念
- Application:指的是用户编写的Spark应用程序,包含了含有一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码。一个Spark程序可以包含多个job。
- Driver:运行Application的main函数并创建SparkContext,SparkContext的目的是为了准备Spark应用程序的运行环境。SparkContext负责资源的申请、任务分配和监控等。当Executor运行结束后,Driver负责关闭SparkContext。
- Job:一个Application可以产生多个Job,其中Job由Spark Action触发产生。每个Job包含多个Task组成的并行计算。
- Stage:每个Job会拆分为多个Task,作为一个TaskSet,称为Stage;Stage的划分和调度是由DAGScheduler负责的。Stage分为Result Stage和Shuffle Map Stage。核心就是用来划分shuffle阶段的,一个stage阶段可能包含多个RDD的计算的,因此一个stage中包含多个Task的。
- Task:Application的运行基本单位,Executor上的工作单元。其调度和管理由TaskScheduler负责。每一个executor内部可以同时启动多个任务,Task就是Spark程序运行的最小单位,一个executor可以运行多少个task取决于cpu core。假如Spark程序总共有100个任务,一般分配30个左右task。
- RDD:Spark基本计算单元,是Spark最核心的东西。表示已被分区、被序列化、不可变的、有容错机制的、能被并行操作的数据集合。在Spark程序中,无外乎就三种操作:创建RDD、转化RDD、从RDD中获取结果/将结果输出保存。
- DAGScheduler:记录RDD之间的依赖关系的,也是用来划分stage阶段的。
- TaskScheduler:任务调度器,Driver驱动程序分配任务给task运行的。将TaskSet提交给Worker运行,每个Worker运行了什么Task于此处分配。同时还负责监控、汇报任务运行情况等。
-
四、Spark程序的部署运行的方式 —— Spark执行jar包
Spark部署运行和MR程序的部署运行方式一致的,需要将我们编写的Spark程序打包成为一个jar包,放到我们的Spark集群中,然后通过Spark相关命令启动运行Spark程序即可
spark-submit [options] <app jar | python file | R file> [app arguments]
spark-submit --class 全限定类名 --master local|local[*]|local[n]|mesos|yarn|spark://ip:port --deploy-mode client|cluster jar包的路径 参数
spark-submit
--class 全限定类名
--master 运行的资源管理器
--deploy-mode 部署运行的模式
--num-executors 只在yarn模式下使用 指定executor的数量
--executor-cores 指定每一个executor具备多少个CPU内核,一个内核可以运行一个TASK
--executor-memory 每一个executor占用的内存
jar包路径
main函数的args参数列表
options的常用选型以及含义:
- –master masterurl 将Spark程序部署到哪个资源管理器运行
spark://host:port, mesos://host:port, yarn,k8s://https://host:port, or local (Default: local[*]). - –deploy-mode mode Spark应用程序的部署模式(YARN场景下)
取值 client cluster - –class class_name jar包中Driver驱动程序的全限定类名
- –name name spark应用程序的别名
- –driver-memory 1024M driver驱动程序
- –executor-memory 1G 等同于YARN中容器,一个容器有多少内存
- –executor-cores num 每一个executor中有多少个内核
五、Spark的编程方式
1、REPL交互式命令行窗口代码编程:Spark提供了一个REPL工具:spark-shell
spark-shell --master local[*]


2、Java/Scala/Python等等代码进行编程
本地运行spark编写的单词计数程序
- 引入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.kanggroupId>
<artifactId>spark-studyartifactId>
<version>1.0version>
<packaging>jarpackaging>
<name>spark-studyname>
<url>http://maven.apache.orgurl>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
properties>
<dependencies>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.12artifactId>
<version>3.1.1version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.6.1version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.4version>
dependency>
dependencies>
<build>
<finalName>spark-studyfinalName>
build>
project>
- 编写scala代码
package com.kang
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark的单词计数案例的实现
*/
object WordCount {
def main(args: Array[String]): Unit = {
//1、创建一个Spark程序执行入口 SparkContext(Scala中) JavaSparkContext(Java中) 首先需要一个Spark的配置文件对象SparkConf
val sparkConf:SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc:SparkContext = new SparkContext(sparkConf)
//2、编写spark的运行代码 调用spark的算子完成计算逻辑
sc.textFile("hdfs://single:9000/wc.txt").
flatMap(_.split(" ")).map((_,1)).reduceByKey((_+_)).collect().foreach(println)
//3、关闭sparkContext对象
sc.stop()
}
}


部署到服务器上运行
- 删除scala代码中的master

- 用maven打jar包 Lifecycle --> package,然后上传到服务器上
- 运行jar包,
spark-submit --class com.kang.WordCount --master yarn --deploy-mode client spark-study.jar
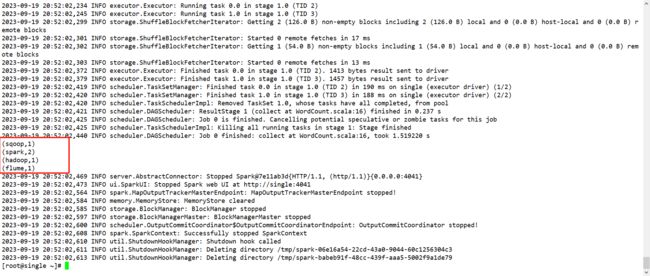

在yarn的web端界面上也有显示,如果没有显示出来,请检查yarn的相关配置是否成功或者检查打包后jar包中的代码是否是修改之后的代码,jar包中的class文件使用jd-gui来查看。
六、Spark的核心基础Spark Core
-
Spark Core是Spark计算框架的核心基础,Spark中子组件都是基于Spark Core封装而来的。
-
Spark Core中包含了Spark的运行调度机制、Spark的迭代式计算、基于内存的运算机制。
1、Spark Core中最核心的有两个概念
- SparkContext:Spark的上下文对象,Spark程序的提交运行,任务分配等等都是由SparkContext来完成的。
- RDD(Resilient Distributed Dataset):叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。也是Spark最核心最重要的概念,也是Spark中最基础的数据抽象(spark处理的所有数据都会封装成为RDD然后进行处理)。
2、RDD的属性(RDD具备的一些特征)
- 一组分区(一组切片):RDD可分区的数据集,RDD内部的数据是以分区的形式存在,每一个分区的数据可以存储在不同的节点上。
- 一个计算每一个分区(切片)数据的compute函数:RDD计算的时候每一个分区的数据是并行计算的,通过一个函数将计算逻辑封装在分区数据上运行计算。
- 一个用来记录RDD依赖关系的列表:记录RDD的依赖关系,容错机制。
- 一个分区机制(RDD必须得是键值对类型的RDD):分区器只对键值对类型的RDD生效。
- 一个用来记录分区位置的列表:如果计算程序和数据不在同一个节点上,会把数据移动到计算节点。
3、RDD的弹性的体现
- 存储的弹性:rdd数据可以在内存和磁盘之间自由切换。
- 计算的弹性:rdd在计算的时候,stage、task都有可能计算失败,如果失败了stage和task都会进行特定次数的重试,默认重试4次。
- 容错的弹性:rdd计算中如果数据丢失,可以根据依赖链重新计算。
- 分片的弹性:rdd计算中,我们可以根据实际情况,在代码中动态的调整分片。
4、RDD的特点
- 1、可分区
- 2、只读:RDD是只读的,不可变的,RDD一旦创建,内部不能改变了,只能根据RDD计算返回一个新的RDD,而原有的RDD不受任务的干扰。
- 3、依赖
- 宽依赖:父RDD的一个分区数据被子RDD的多个分区同时使用,一般在shuffle算子中才会出现。
- 窄依赖:父RDD的分区数据只能给子RDD的一个分区。
- 依赖是Spark程序划分stage的核心依据,stage划分规则是从上一个宽依赖算子到下一个宽依赖算子之前的操作都属于同一个stage。
- 4、可缓存
- 5、可设置检查点
5、RDD的分类
- RDD数据集,内部可以存放各种各样的数据类型,根据存储的数据类型不同,将RDD分为两类:数值类型的RDD(RDD)、键值对类型的RDD(PairRDD)。
- 数值类型的RDD存放的数据类型可以是任何类型,包括键值对类型
RDD[String]、RDD[People] - 键值对类型的RDD指的是数据集中存放的数据类型是一个二元组,是一种比较特殊的数值类型的RDD
RDD[(String,Int)]、RDD[(Int,(String,Int))] - 键值对类型的RDD有它自己独特的一些算子操作,同时键值对类型的RDD可以使用数值类型RDD的所有操作。
6、RDD的编程
-
在Spark中,对数据操作其实就是对RDD的操作,对RDD的操作无外乎三种:
- 1、创建RDD
- 2、转换操作(Transformation):从一个RDD中得到另外一个RDD的算子。
- 3、行动操作(Action):从RDD得到一个Scala集合、Scala标量、将RDD数据保存到外部存储中。
RDD计算操作是惰性计算的,遇到转换算子不会计算,只会先记录RDD的依赖关系,只有当遇到行动算子,才会根据记录的依赖链依次计算。
-
RDD的编程方式主要分为两种:命令行编程方式(spark-shell – 数据科学、算法研究)、API编程方法(数据处理 java scala python R)
6.1、RDD的创建操作
-
将数据源的数据转换成为Spark中的RDD,RDD的创建主要分为三种:1、从外部存储设备创建RDD(HDFS、Hive、HBase、Kafka、本地文件系统…)2、Scala|Java集合中创建RDD 3、从已有的RDD转换成为一个新的RDD(RDD的转换算子)
-
1、从集合中创建RDD
- parallelize(Seq[T],num)
- makeRDD(Seq[T],num) 底层就是parallelize函数的实现了
都可以传递一个第二个参数,第二个参数代表的是RDD的并行度(RDD的分区数),默认分区数就是master中设置的cpu核数。
-
makeRDD(Seq[(T, Seq[String])]) 这种方式创建的RDD是带有分区编号的 ,集合创建的RDD的分区数就是指定的分区数。
-
代码示例
package com.kang.create import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 1、创建RDD * 【注意】如果我们想要编写Spark程序,我们必须先创建一个SparkContext,因为Spark程序的提交运行、RDD的创建操作都是由SparkContext完成的。 */ object ScalaDemo01 { def main(args: Array[String]): Unit = { //1、创建SparkContext val sparkConf:SparkConf = new SparkConf().setAppName("create-rdd").setMaster("local[*]") val sc:SparkContext = new SparkContext(sparkConf) //2、集合中创建RDD // val rdd:RDD[Int] = sc.parallelize(1 until 100) // val rdd[Int] = sc.makeRDD(1 to 100) val rdd:RDD[List[Int]] = sc.makeRDD(Array((List(1,2,3),List("node1","node2")),(List(4,5,6),List("node2","node3")))) rdd.collect().foreach(println) sc.stop() } } -
2、从外部存储创建RDD
-
textFile()
-
wholeTextFile()
-
sc.sequenceFiile(path,classof[Key],classof[V]):RDD[(Key,V)](sequenceFile文件夹的目录) 读取sequenceFile文件成为键值对类型的RDD
【注意】需要传入key和value的Class类型,是hadoop序列化之前的类型 -
objectFile(path)读取ObjectFile文件成为RDD,RDD的类型取决于写出的Object文件的类型
-
package com.kang.create import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo02 { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("create-rdd").setMaster("local[5]") val sc: SparkContext = new SparkContext(sparkConf) val rdd = sc.sequenceFile("file:///D://Desktop/a.sequence",classOf[String],classOf[Int]) rdd.foreach(println) val rdd1:RDD[Int] = sc.objectFile("file:///D://Desktop/a.obj") rdd1.foreach(println) rdd.cache() rdd.persist() sc.stop() } } -
-

-
-
根据JDBC创建RDD
-
package com.kang.create import org.apache.spark.rdd.{JdbcRDD, RDD} import org.apache.spark.{SparkConf, SparkContext} import java.sql.{DriverManager, ResultSet} case class Student(id:Int,name:String,age:Int,sex:String) object Demo03 { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("create-rdd-jdbc").setMaster("local[5]") val sc: SparkContext = new SparkContext(sparkConf) val rdd:RDD[Student] = new JdbcRDD[Student](sc, () => { DriverManager.getConnection("jdbc:mysql://localhost:3306/spark?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8","root","root") }, "select * from student where id>=? and id <=?", 1, 3, 2, (rs: ResultSet) => { val id = rs.getInt("id") val name = rs.getString("name") val age = rs.getInt("age") val sex = rs.getString("sex") Student(id, name, age, sex) }) rdd.foreach(println) sc.stop() } } -
-
-
代码示例
package com.kang.create import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 1、创建RDD * 【注意】如果我们想要编写Spark程序,我们必须先创建一个SparkContext,因为Spark程序的提交运行、RDD的创建操作都是由SparkContext完成的。 */ object ScalaDemo01 { def main(args: Array[String]): Unit = { //1、创建SparkContext val sparkConf:SparkConf = new SparkConf().setAppName("create-rdd").setMaster("local[5]") val sc:SparkContext = new SparkContext(sparkConf) //3、从外部存储创建RDD 外部文件必须得是text file 只能读取一个文件 // val rdd1:RDD[String] = sc.textFile("hdfs://single:9000/wc.txt") // println(rdd1.getNumPartitions) // rdd1.collect().foreach(println) val rdd2:RDD[(String,String)] = sc.wholeTextFiles("hdfs://single:9000/dataCollect/2023-07-15") rdd2.collect().foreach(println) //4、关闭SparkContext sc.stop() } }package com.kang.create; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import java.util.Arrays; import java.util.List; public class JavaDemo01 { public static void main(String[] args) { SparkConf sparkConf = new SparkConf().setAppName("java-rdd").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); JavaRDD<Integer> javaRDD = jsc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6)); List<Integer> collect = javaRDD.collect(); for (Integer integer : collect) { System.out.println(integer); } jsc.stop(); } } -
6.2、RDD的转换操作(转换算子)
-
RDD之所以可以实现迭代式操作,就是因为RDD中提供了很多算子,算子之间进行操作时,会记录算子之间的依赖关系。
-
RDD中具备一个转换操作的算子,转换算子是用来从一个已有的RDD经过某种操作得到一个新的RDD的,转换算子是惰性计算规则,只有当RDD遇到行动算子,转换算子才会去执行。
-
算子:就是Spark已经给我们封装好的一些计算规则,只不过这些计算规则内部还需要传入计算逻辑,代码层面上,算子就是需要传入函数的函数。Spark提供了80+个算子。
-
数值型RDD的转换算子(通用算子)
- map(f:T=>U)算子–一对一算子
- mapPartitions(f:Iterator[T]=>Iterator[U])算子—一对一算子,一个分区的数据统一执行一次map操作
- mapPartitionsWithIndex(f:(Index,Iterator[T])=>Iterator[U])----一对一算子,和mapPartitions算子的逻辑一模一样的,只不过就是多了一个分区编号。
- 以上三种适用场景:将RDD的数据类型转换为另外一种数据类型。
- filter(f:T=>Boolean) 算子—过滤算子,对原有RDD的每一个算子应用一个f函数,如果函数返回true,那么数据保留,如果返回false,那么数据舍弃。适用场景:清洗数据,RDD的数据类型不会发生任何的更改。
- 代码示例:
package com.kang.transformation import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 数值型的RDD转换算子 * */ object ScalaDemo02 { def main(args: Array[String]): Unit = { val sparkConf:SparkConf = new SparkConf().setAppName("transformation").setMaster("local[*]") val sc:SparkContext = new SparkContext(sparkConf) //创建RDD // val rdd:RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 7, 8)) val rdd:RDD[String] = sc.makeRDD(List("spark","scala","spark","hadoop")) /** * 1、map算子,一对一算子 * 对原有RDD的每一个数据应用一个函数,经过函数计算得到一个新的返回值,新的返回值组成一个新的RDD * 原有的RDD一个数据通过这个算子返回一个数据 */ // val rdd1:RDD[Int] = rdd.map((a: Int) => {a * 3}) // val rdd1:RDD[Int] = rdd.map((_*3))//简化版本 // val rdd1:RDD[(String,Int)] = rdd.map((a:String)=>{(a,1)}) // val rdd1:RDD[(String,Int)] = rdd.map((_,1))//简化版本 // val rdd1:RDD[(String,Int)] = rdd.mapPartitions((list:Iterator[String])=>{ // import scala.collection.mutable.ArrayBuffer // var ab:ArrayBuffer[(String,Int)] = ArrayBuffer() // for (elem <- list) { // ab.+=((elem,1)) // } // ab.iterator // }) // val rdd1:RDD[(String,Int)] = rdd.mapPartitionsWithIndex((index:Int,list:Iterator[String])=>{ // println(s"现在是第$index 分区的数据,分区数据为${list.mkString(",")}") // import scala.collection.mutable.ArrayBuffer // var ab:ArrayBuffer[(String,Int)] = ArrayBuffer() // for (elem <- list) { // ab.+=((elem,1)) // } // ab.iterator // }) /** * 2、filter过滤算子 */ val rdd1:RDD[String] = rdd.filter((word:String)=>{word.startsWith("h")}) rdd1.collect().foreach(println) sc.stop() } }- flatmap(f: T => TraversableOnce[U]):RDD[U]:压扁算子,一对多的算子,一条输入数据可以被映射成为0个或多个数据,最后函数的返回值必须是一个集合类型,最后得到的RDD的类型就是集合元素的类型。
/** * flatmap算子 */ val rdd1:RDD[String] = rdd.flatMap((line:String)=>{ val array:Array[String] = line.split(" ") array }) //val rdd1: RDD[String] = rdd.flatMap( _.split(" "))简化版本- sample(boolean是否为有放回的抽样,抽取比例,种子 - 底层抽样算法使用默认值):抽样算子,数据量越大,抽取的数据越精准,数据量越小,抽取的数据偏差越大。适用场景:随机抽取原始RDD的部分数据,RDD的数据类型不会发生任何的更改,一般使用在源RDD的数据量过多。
/** * 从flatmap算子计算结果中,抽取50%的数据 */ val rdd2:RDD[String] = rdd1.sample(false,0.5)- union(RDD[T]):RDD[T] 并集算子,将两个RDD中所有数据组合成为一个新的RDD然后返回。
/** * union算子 */ val rdd3:RDD[String] = sc.makeRDD(Array("hadoop","spark","storm")) val rdd4:RDD[String] = rdd1.union(rdd3) rdd4.collect().foreach(println)- intersection(RDD[T]):RDD[T]:交集算子,将两个RDD取交集返回。—— 通过equals方法判断重复
/** * intersection */ val rdd5:RDD[String] = rdd1.intersection(rdd3)- subtract差集算子 —— 通过equals方法判断重复
/** * 创建两个RDD subtract差集算子 */ val rdd1:RDD[Int] = sc.parallelize(Array(1,2,3,4)) val rdd2:RDD[Int] = sc.makeRDD(Array(3,4,5,6)) val rdd3:RDD[Int] = rdd1.subtract(rdd2) ---------------------------------------------------------------------------------------------- case class Animal(name: String, age: Int) val rdd: RDD[Animal] = sc.parallelize(Array(Animal("zs", 30), Animal("ls", 20))) val rdd1: RDD[Animal] = sc.makeRDD(Array(Animal("zs", 30), Animal("ww", 20))) val rdd2: RDD[Animal] = rdd.subtract(rdd1)- distinct([numPartitions]))(implicat ordering = null):去重算子,对RDD元素去重,借助元素的equals方法去重的,第二个隐式参数的目的是为了去重之后对数据分区进行排序,如果没有排序规则,不排序了。 —— 通过equals方法判断重复
/** * distinct([numPartitions])) */ val rdd6:RDD[String] = rdd3.distinct() //scalaBean的去重 case class People(name:String,age:Int) val rdd7:RDD[People] = sc.makeRDD(Array(People("zs",20),People("ls",30),People("zs",20))) val rdd8:RDD[People] = rdd7.distinct()- cartesian(RDD[U]):生成笛卡尔乘积,在T和U类型的RDD上,列出T和U的所有组合情况,返回一个新的RDD[(T,U)]。
/** * 笛卡尔乘积 */ val rdd11:RDD[((String,Int),(String,Int))] = rdd5.cartesian(rdd6) rdd11.collect().foreach(println) sc.stop()- sortBy(T=>U,asc:Boolean=true)(implicit ordering[U]):排序算子, 将RDD中T类型转换成为U类型然后对RDD进行排序,返回的还是RDD[T]
【注意】U必须能排序的,两种方式:实现Ordered接口,定义一个隐式类是Ordering[U]的子类
当然我们也可以手动在sortBy函数的第二个括号中传递一个Ordering的匿名内部类
/** * sortBy */ case class Teacher(name:String,age:Int) val rddC:RDD[(Int,Teacher)] = sc.makeRDD(Array((1,Teacher("zs", 20)), (2,Teacher("ls", 25)))) implicit val teacherOrdering: Ordering[Teacher] = new Ordering[Teacher] { override def compare(x: Teacher, y: Teacher): Int = { if (x.age > y.age) { 1 } else { -1 } } } val rdd10: RDD[(Int, Teacher)] = rddC.sortBy(data => data._2)- zip拉链算子 两个RDD的元素个数必须相同
/** * zip拉链算子 */ val rdd3:RDD[(Animal,Animal)] = rdd.zip(rdd1)- repartition(num) 分区算子,将RDD数据重新分区之后得到一个新的RDD
val rdd:RDD[Int] = sc.makeRDD(Array(1,2,3,4,5,6,7,8,9,10,11,12)) val rdd1: RDD[Int] = rdd.repartition(3) val rdd2: RDD[Int] = rdd1.mapPartitionsWithIndex((a: Int, b: Iterator[Int]) => { println(s"第${a}个分区,数据为${b.mkString(",")}") b }) println(rdd2.getNumPartitions) println(rdd2.partitioner) rdd2.collect() sc.stop()
-
键值对类型RDD的转换算子
- groupByKey([numPartitions]):分组算子,根据RDD的键值对数据的key值把Value数据聚合到一起,然后返回一个新的RDD,新的RDD也是kv类型,v变成集合类型。
//创建一个kv键值对rdd val rdd:RDD[(String,Int)] = sc.makeRDD((Array(("spark",1),("flink",1),("spark",1)))) val rdd1:RDD[(String,Iterable[Int])] = rdd.groupByKey()-
join(RDD[(K,W)]):内连接算子,和另外一个键值对RDD做inner join操作,返回RDD[(K,(V,W))]
/** * join操作 等同于SQL中join操作 内连接 */ //学生的数学成绩 val rdd5:RDD[(String,Int)] = sc.makeRDD(Array(("zs",80),("ls",72),("ww",92),("ww",85))) //学生的语文成绩 val rdd6:RDD[(String,Int)] = sc.makeRDD(Array(("zs",90),("ls",82),("ww",70),("zsf",75))) val rdd7:RDD[(String,(Int,Int))] = rdd5.join(rdd6) rdd7.collect().foreach((data:(String,(Int,Int)))=>{ println(s"学生姓名为${data._1},数学成绩为${data._2._1},语文成绩为${data._2._2}") }) -
leftOutJoin|rightOutJoin|fullOutJoin(RDD(K,W))和另外一个RDD做外连接操作,外连接算子
左连接:返回RDD[(K,(V,Option[W]))] —— 保留调用者信息
右连接:返回RDD[(K,(Option[V],W))] —— 保留参数信息
全外连接:返回RDD[(K,(Option[V],Option[W]))] —— 保留全部信息
Option是为了防止空指针异常的,Option的取值有两种:None、Some,如果Option包含的数据不为Null,那么使用Some将数据封装,然后我们可以使用get方法获取里面的值,如果数据为Null,那么使用None将数据封装,不能使用get获取数据。/** * 左外连接 */ val rdd8: RDD[(String, (Int, Option[Int]))] = rdd5.leftOuterJoin(rdd6) rdd8.collect().foreach((data: (String, (Int, Option[Int]))) => { println(s"学生姓名为${data._1},数学成绩为${data._2._1},语文成绩为${data._2._2}") }) /** * 右外连接 */ val rdd9: RDD[(String,(Option[Int],Int))] = rdd5.rightOuterJoin(rdd6) rdd9.collect().foreach((data: (String, (Option[Int],Int))) => { println(s"学生姓名为${data._1},数学成绩为${data._2._1},语文成绩为${data._2._2}") }) /** * 全外连接 */ val rdd10: RDD[(String, (Option[Int], Option[Int]))] = rdd5.fullOuterJoin(rdd6) rdd10.collect().foreach((data: (String, (Option[Int], Option[Int]))) => { println(s"学生姓名为${data._1},数学成绩为${data._2._1},语文成绩为${data._2._2}") }) -
cogroup(RDD[(K,W)]):连接算子plus版本,返回一个 RDD[(K, (Iterable, Iterable)) ] 将两个RDD中所有key值相同的数据全部聚合到一块,RDD1中相同的Value组成Iterable[V] RDD2中相同的value组成Iterable[W]
/** * cogroup算子 */ //学生的数学成绩 val rdd12: RDD[(String, Int)] = sc.makeRDD(Array(("zs", 80), ("ls", 72), ("ww", 92), ("zs", 90))) //学生的语文成绩 val rdd13: RDD[(String, Int)] = sc.makeRDD(Array(("zs", 90), ("ls", 82), ("ww", 70), ("zs", 80))) val rdd14:RDD[(String,(Iterable[Int],Iterable[Int]))] = rdd12.cogroup(rdd13) rdd14.collect().foreach(date => { println(s"学生为${date._1},数学成绩为${date._2._1.mkString(" ")},语文成绩为${date._2._2.mkString(" ")}") }) -
mapValues(f: V => U) :RDD[(K,U)] 操作键值对的value数据算子,一对一,针对KV类型的RDD只对v操作返回一个新的类型,由新的类型和原有的key组成一个新的RDD
/** * mapValues * 可以使用map算子替代,但是map算子替代比较复杂 */ val rdd15:RDD[(String,Int)] = rdd12.mapValues((value:Int) => {value+5}) rdd15.collect().foreach(println) -
flatMapValues 操作键值对的value数据算子 一对多
/** * flatMapValues算子 */ val rdd4: RDD[(String, String)] = sc.makeRDD(Array(("zs", "80-90-85"), ("ls", "70-75-90"))) val rdd5: RDD[(String, String)] = rdd4.flatMapValues((value: String) => { value.split("-") })

-
reduceByKey(func: (V, V) => V) :分组聚合算子,reduceByKey=groupBykey+reduce操作,函数输入数据有两个,输出有一个,输出类型和输出类型是同一个类型。根据key值,把value聚合到一起,并且对value求出一个聚合结果,RDD的类型不会发生变化。
输入的两个v:第一个v是上一次聚合的结果 第二v是本次要聚合的value
输出的v就是本次聚合的结果/** * reduceBykey */ val rdd2:RDD[(String,Int)] = rdd.reduceByKey((a:Int,b:Int)=>{a+b}) val rdd3:RDD[(String,Int)] = sc.makeRDD(Array(("zs",80),("zs",90),("ls",70),("ls",85))) val rdd4:RDD[(String,Int)] = rdd3.reduceByKey((a:Int,b:Int) =>{ if(a>b) { a }else{ b } }) -
combineByKey( createCombiner: V => C,mergeValue: (C, V) => C,mergeCombiners: (C, C) => C) 分组聚合Plus算子,combiner也是根据key值聚合value,只不过value如何聚合,是什么样的聚合逻辑,我们要通过三个函数说明(比reduceByKey的功能要强大):
- createCombiner:V=>C 将key值对应得value数据先进行初始化操作,返回一个新的类型。
- mergeValue:(C,V)=>C 每一个分区都会单独执行一个mergeValue函数,通过mergeValue函数将当前分区的key的value值和刚刚创建的初始值做计算 得到当前分区下的唯一的计算结果,结算结果的类型必须和初始化之后的类型保持一致。
- mergeCombiners:(C,C)=>C 将所有分区当前key值计算出来的结果C 再进行一次全局的聚合,得到唯一的结果,结果就是我们这个combineByKey的计算结果。
- 返回RDD[(K,C)]
/** * combineByKey实现类似于ReduceByKey的效果 */ val rdd1:RDD[(String,Int)] = rdd.combineByKey((a:Int)=>a,(a:Int,b:Int)=>{ if (a>b) { a }else{ b } },(a:Int,b:Int)=>{ if(a>b){ a }else{ b } }) /** * combineByKey计算科目总成绩以及科目的数量 */ val rdd2:RDD[(String,(Int,Int))] = rdd.combineByKey((a:Int)=>(a:Int,1),(a:(Int,Int),b:Int)=>{ ((a._1+b),(a._2+1)) },((a:(Int,Int),b:(Int,Int))=>{ ((a._1+b._1),(a._2+b._2)) })) val rdd3:RDD[(String,Double)] = rdd2.mapValues((a:(Int,Int))=>{a._1.toDouble /a._2.toDouble}) -
aggregateByKey(zeroValue:U)(mergerValue:(U,V)=>U,mergerCombiner:(U,U)=>U)分组聚合plus算子
aggreGateByKey算子和CombineByKey算子实现的效果是一样的,区别在于初始值不一样的,combineBykey的初始值是根据函数计算来的,是根据每一个分区的一个真实的value数据计算得来的,而aggregateByKey的初始值是我们随意给的。/** * aggregateByKey算子计算科目总成绩以及科目的数量 */ val rdd4:RDD[(String,(Int,Int))] = rdd.aggregateByKey((0,0))((a:(Int,Int),b:Int)=>{(a._1+b,a._2+1)},(a:(Int,Int),b:(Int,Int))=>{((a._1+b._1),(a._2+b._2))}) val rdd5:RDD[(String,Double)] = rdd4.mapValues((a:(Int,Int))=>{a._1.toDouble/a._2.toDouble}) val rdd6:RDD[(String,Int)] = rdd.aggregateByKey(Int.MaxValue)((a:Int,b:Int)=>{a.min(b)},((a:Int,b:Int)=>{a.min(b)})) -
foldByKey(zeroValue:V)(f:(V,V)=>V)):aggregateByKey算子的简化版,相当于是aggregateByKey的简化版,当aggregateByKey的mergeValue和mergeCombiner函数的计算逻辑一致,并且zerovalue初始化类型的值和原先RDD的value的类型一致的时候,就可以使用foldByKey简化。
/** * foldByKey */ val rdd7:RDD[(String,Int)] = rdd.foldByKey(Int.MaxValue)((a:Int,b:Int)=>{a.min(b)}) val rdd7:RDD[(String,Int)] = rdd.foldByKey(Int.MaxValue)(_ min _)//简化版本 -
sortByKey(asc:Boolean=true):根据键值对kv的key进行排序,默认升序排序,RDD的类型不会改变。
【注意】key值必须实现了Ordered比较器接口,如果想让排序规则准确,那么你的Ordered接口中排序逻辑必须得是升序(前者大于后者,返回正数)逻辑。/** * sortByKey */ val rddA:RDD[(String,Int)] = sc.makeRDD(Array(("zs",80),("ls",80),("ww",92),("ml",90),("qsf",75),("bwj",72)),2) val rdd8:RDD[(String,Int)] = rddA.sortByKey(false) case class Student(name:String,age:Int) extends Ordered[Student] { override def compare(that: Student): Int = { if(age>that.age){ 1 }else{ -1 } } } val rddB:RDD[(Student,Int)] = sc.makeRDD(Array((Student("zs", 20), 1), (Student("ls", 25), 2))) val rdd9:RDD[(Student,Int)] = rddB.sortByKey(false) -
partitionBy(分区器):只有再涉及到shuffle算子的时候才会出现分区器的概念
HashPartitioner 默认的分区器,可能会出现数据倾斜问题
RangePartitioner 范围分区器–尽可能保证每个分区的数据一致,抽样算法
自定义分区器package com.kang.transformation import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} object ScalDemo07 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("kv-transformation").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) val rdd: RDD[(String, Int)] = sc.makeRDD(Array(("zs", 20), ("zs", 30), ("zs", 50), ("zs", 40), ("ls", 30), ("ww", 20), ("ml", 20), ("zsf", 30))); rdd.mapPartitionsWithIndex((a, b) => { println(s"第${a}个分区,数据为${b.mkString(",")}") b }).collect() // val rdd1:RDD[(String,Int)] = rdd.partitionBy(new HashPartitioner(2)) // val rdd1:RDD[(String,Int)] = rdd.partitionBy(new RangePartitioner(2,rdd)) val rdd1:RDD[(String,Int)] = rdd.partitionBy(new MyPartitioner()) rdd1.mapPartitionsWithIndex((a, b) => { println(s"第${a}个分区,数据为${b.mkString(",")}") b }).collect() println(rdd1.partitioner) println(rdd1.getNumPartitions) sc.stop() } } class MyPartitioner extends Partitioner{ override def numPartitions: Int = 2 override def getPartition(key: Any): Int = { val str: String = key.toString if(str.startsWith("z")){ 0 }else{ 1 } } }
-
查看一个RDD的分区数和分区器:rdd中存在两个内容:partitioner 属性、getNumPartitions 函数。
6.3、RDD的行动算子
-
行动算子是用来触发依赖链的执行的,在Spark程序中,一个行动算子触发的一个依赖链会单独成为Spark中job运行。
-
数值型RDD的行动算子(通用算子)
- reduce((T,T)=>T):T 聚合算子,从RDD中把所有的数据聚合得到一个结果,结果的类型必须和RDD中数据类型保持一致。

- aggregate(zerovalue:U)(mergeValue,combineValue) :U:聚合算子的plus版本。

package com.kang.action import org.apache.spark.{SparkConf, SparkContext} object Demo01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("transformation").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val rdd = sc.makeRDD(Array(1,2,3,4,5,6,7,8,9)) /** * reduce行动算子 */ val max:Int = rdd.reduce((a,b)=>{if(a>b) a else b}) println(max) /** * aggregate算子 */ val result:(Int,Int) = rdd.aggregate((0,0))((a:(Int,Int),b:Int)=>{(a._1+b,a._2+1)},(a:(Int,Int),b:(Int,Int))=>{(a._1+b._1,a._2+b._2)}) println(result._1/result._2) sc.stop() } }- fold(zerovalue:T)(f:(T,T)=>T):T aggregate的简化版本。
- collect() :Array[T] 算子慎用,很可能造成OOM异常,将RDD所有分区的数据拉取到Driver驱动程序端以数组的形式在内存中保存RDD中的所有数据。
- foreach(T=>Unit)|foreachPartition(Iterator[T] => Unit)对RDD中的数据进行一个函数操作,函数无返回值,这个函数中我们既可以输出数据(不用担心OOM问题),同时也可以在函数内部编写保存数据代码,保存到外部存储中。
使用foreach替换collect去检查数据。
package com.kang.action import com.mysql.cj.jdbc.Driver import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import java.sql.DriverManager object Demo02 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("transformation").setMaster("local[1]") val sc: SparkContext = new SparkContext(conf) case class Student(id:Int,name:String,age:Int,sex:String) val rdd:RDD[Student] = sc.parallelize(Array(Student(1,"zs",20,"man"),Student(2,"ls",30,"woman"))) rdd.foreach((a:Student)=>{ var conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/spark?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8","root","root") var sql = "insert into student values(?,?,?,?)" val statement = conn.prepareStatement(sql) statement.setInt(1,a.id) statement.setString(2,a.name) statement.setInt(3,a.age) statement.setString(4,a.sex) val i = statement.executeUpdate() statement.close() conn.close() }) sc.stop() } }
-
count():Long 返回RDD中数据量
-
获取RDD中的部分数据的算子
- first():T 获取RDD中第一个元素,底层实现就是take(1)
- take(n): Array[T] 获取RDD中的前n个元素
- takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] 获取RDD排好序之后的前N个元素,
【注意】RDD中的T类型必须可以比较大小,Scala中所有数值型的数据类型都不需要传递 - takeSample(withReplacement, num, [seed]):Array[T] 随机抽取RDD中的num条数据 返回一个array数组。
package com.kang.action import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo03 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("transformation").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) val rdd:RDD[Int] = sc.makeRDD(Array(50,34,56,78,23,15,19)) val first:Int = rdd.first() val array:Array[Int] = rdd.take(3) val array1:Array[Int] = rdd.takeOrdered(3) val array2:Array[Int] = rdd.takeSample(true, 5) println(s"rdd的第一条数据为$first") println(s"rdd的未排序之前的前三条数据为${array.mkString(",")}") println(s"rdd的排序之后的前三条数据为${array1.mkString(",")}") println(s"rdd的随机抽取五条为${array2.mkString(",")}") Thread.sleep(1000000000) sc.stop() } }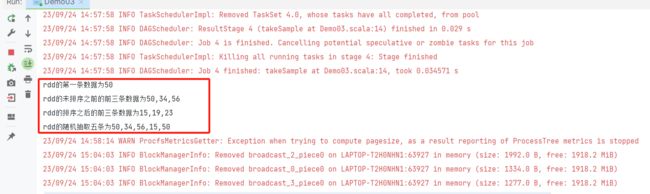
-
用来保存数据到文件中算子
- saveAsTextFile(path)
- saveAsObjectFile(path)
package com.kang.action import org.apache.hadoop.io.compress.GzipCodec import org.apache.spark.io.CompressionCodec import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo04 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("transformation").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) val rdd:RDD[Int] = sc.makeRDD(Array(50,34,56,78,23,15,19)) rdd.saveAsTextFile("file:///D://Desktop/a.txt") rdd.saveAsObjectFile("file:///D://Desktop/a.obj") val rdd1:RDD[(String,Int)] = sc.makeRDD(Array(("zs",20),("ls",20))) rdd1.saveAsSequenceFile("file:///D://Desktop/a.sequence",Option(classOf[GzipCodec])) Thread.sleep(1000000000) sc.stop() } }
-
键值对类型RDD的行动算子
- saveAsSequenceFile(path)
- countByKey(): Map[K,Long] 将键值对RDD中key值出现的次数以map集合的形式给我们返回。
package com.kang.action import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo05 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("action").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) val rdd:RDD[String] = sc.makeRDD(Array("hadoop", "spark", "flink", "hadoop")) val rdd1:RDD[(String,Int)] = rdd.map((_,1)) val map:scala.collection.Map[String,Long] = rdd1.countByKey() map.foreach(println) sc.stop() } }
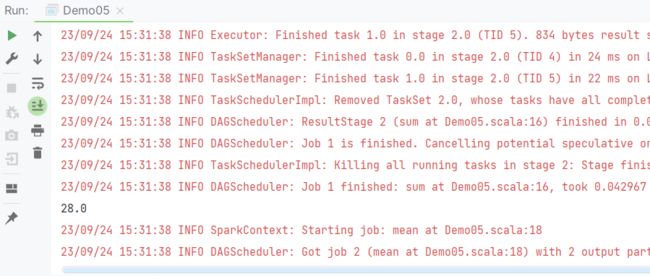
6.4、RDD的一些比较特殊的行动算子(只针对整数类型的RDD有效)
val rdd2:RDD[Int] = sc.makeRDD(Array(1,2,3,4,5,6,7))
val sum:Double = rdd2.sum()
println(sum)
val d = rdd2.mean()
println(d)

【补充】在Scala中,每一个RDD都是RDD类型的,可调用的方法按道理来说只能是RDD内部定义的方法,但是有些特殊的RDD(键值对RDD、整数类型的RDD)可以调用非RDD内部声明的函数,底层采用了Scala的隐式转换机制扩充了特殊RDD类型的功能。
package com.kang.RDD的底层隐式转换的模拟
class RDDModel[T] {
def test():Unit={
}
}
class DoubleRDDModel[T]{
def test01(): Unit = {
}
}
object Demo01{
def main(args: Array[String]): Unit = {
implicit def a(r:RDDModel[Double]):DoubleRDDModel[Double]={
new DoubleRDDModel[Double]();
}
implicit def b(r:RDDModel[Int]):DoubleRDDModel[Double]={
new DoubleRDDModel[Double]();
}
var rdd:RDDModel[Int] = new RDDModel[Int]()
rdd.test01()
}
}
7、RDD的持久化(缓存)
-
在一个Spark的Application中,可能一个RDD被多个Job,或者被同一Job多次使用,但是RDD每次计算完成之后,下次如果还需要使用,需要根据依赖链从头开始计算RDD,这样的话,效率太低,根据依赖链计算确实挺安全,但是也特别浪费时间。如果我们想让计算快速完成,Spark提供了一种机制,缓存机制,可以实现将重复性使用的RDD缓存起来(内存、磁盘、内存+磁盘),RDD缓存只有当触发了第一个行动算子之后才会进行缓存操作。这样的话第二个job和后续的job再使用RDD直接从缓存获取,就不需要重新计算了。而且如果缓存的数据丢失,可以根据依赖链重新计算。
-
缓存涉及到两个算子:cache() persist() persist(StorageLevel)。
- cache底层实现是persist(),persist底层实现persist(StorageLevel.MEMORY_ONLY)
- StorageLevel有很多种缓存级别
package com.kang.cache import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo01 { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("create-rdd").setMaster("local[5]") val sc: SparkContext = new SparkContext(sparkConf) val rdd:RDD[Int] = sc.makeRDD(1 to 10) val rdd1:RDD[Int] = rdd.map(a=>{ print("map算子执行了") a }) rdd1.cache() rdd1.collect().foreach(print) rdd1.foreach(print) rdd1.take(5).foreach(print) sc.stop() } }
8、RDD的检查点机制
- 检查点也是一种另类的RDD缓存方式,只不过和RDD持久化的区别在于,检查点会把依赖链断掉,同时检查点的数据保存到HDFS分布式文件系统中,这样依靠HDFS的副本机制保证缓存的高可靠性。RDD检查点一旦设置成功,依赖链断了,下一次如果我们再重新运行Spark程序,会从检查点获取数据往后运行,RDD之前的依赖计算全部不用执行了。
- 如果设置缓存点,那么设置之前,必须先使用SparkContext设置检查点目录,sc.setCheckPointDir(hdfspath),然后需要进行设置检查点的RDD,使用rdd.checkpoint()。
- 检查点也是第一次触发行动算子之后才会进行操作的。
package com.kang.checkpoint
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo01 {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("create-rdd").setMaster("local[5]")
val sc: SparkContext = new SparkContext(sparkConf)
sc.setCheckpointDir("hdfs://single:9000/checkpoint")
val rdd:RDD[Int] = sc.makeRDD(1 to 10)
val rdd1:RDD[Int] = rdd.map(a=>{
print("map算子执行了")
a
})
rdd1.checkpoint()
rdd1.collect().foreach(print)
Thread.sleep(120000)
rdd1.foreach(print)
rdd1.take(5).foreach(print)
sc.stop()
}
}
9、RDD算子的依赖关系
- RDD算子的依赖分为两种
- 宽依赖:shuffle类型的算子,父RDD的一个分区的数据被子RDD的多个分区使用,同时子RDD的一个分区数据也可能来自于多个父RDD的分区。
- 窄依赖:父RDD的一个分区数据只能被子RDD的一个分区使用,但是子RDD的分区可以来自多个父RDD。
- 如何查看一个算子的前一个依赖是宽依赖还是窄依赖:rdd.dependencies 函数。
- stage划分依据 —— 一个stage指的是从一个shuffle算子开始到另一个shuffle算子之前的操作都归属于同一个stage。
- DAG生成 —— 基于依赖链和stage生成的。
package com.kang.depend
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WC {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[5]")
val sc: SparkContext = new SparkContext(sparkConf)
val rdd:RDD[String] = sc.textFile("hdfs://single:9000/wc.txt")
println(s"rdd的依赖为${rdd.dependencies}")
val rdd1:RDD[String] = rdd.flatMap((line:String)=>{line.split(" ")})
println(s"rdd1的依赖为${rdd1.dependencies}")
val rdd2:RDD[(String,Long)] = rdd1.map((word:String)=>{(word,1L)})
println(s"rdd2的依赖为${rdd2.dependencies}")
val rdd3:RDD[(String,Long)] =rdd2.reduceByKey((a:Long,b:Long)=>{a+b})
println(s"rdd3的依赖为${rdd3.dependencies}")
val rdd4:RDD[(String,Long)] = rdd3.mapValues((v:Long)=>{v+5})
println(s"rdd4的依赖为${rdd4.dependencies}")
rdd4.foreach(println)
Thread.sleep(10000000)
sc.stop()
}
}
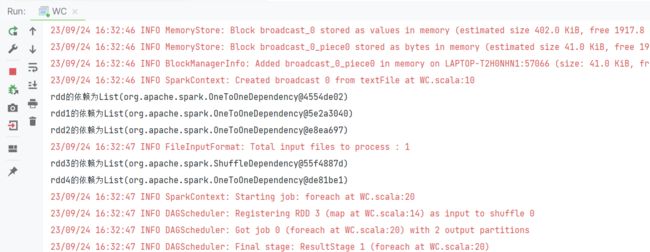
- 依赖关系是我们划分stage阶段的关键,stage划分的依据就是根据宽依赖划分。
10、RDD的两个特殊的使用
-
RDD的累加器
-
累加器就是在程序运行中获取一些感兴趣的数据的量,Spark中累加器功能比较强大的,除了获取感兴趣的数据量,还可以自定义累加器的类型,获取一些其他的数据。
-
累加器的使用有一个注意点:累加器一般是在Driver端定义,然后在RDD分区中修改累加器的数值,然后在Driver端获取累加器的结果。
-
用法
- 1、需要在Driver中创建一个累加器 — Spark自带的,累加整数类型的值
val accu = sc.xxxxaccumulator(累加器的名字) - 2、在RDD的算子计算中对累加器进行赋值操作
accu.add(1) - 3、在Driver端获取累加器的结果
accu.value
package com.kang.accu import org.apache.spark.rdd.RDD import org.apache.spark.util.LongAccumulator import org.apache.spark.{SparkConf, SparkContext} object Demo01 { def main(args: Array[String]): Unit = { val sparkConf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[5]") val sc: SparkContext = new SparkContext(sparkConf) val accumulator:LongAccumulator = sc.longAccumulator("wordcount") val rdd: RDD[String] = sc.makeRDD(Array("spark flink sqoop","hive hadoop spark","hadoop spark")) val rdd1: RDD[String] = rdd.flatMap((line: String) => { line.split(" ") }) val rdd2: RDD[(String, Long)] = rdd1.map((word: String) => { accumulator.add(1L) (word, 1L) }) val rdd3: RDD[(String, Long)] = rdd2.reduceByKey((a: Long, b: Long) => { a + b }) val rdd4: RDD[(String, Long)] = rdd3.mapValues((v: Long) => { v + 5 }) rdd4.foreach(println) println(s"总共有${accumulator.value}个单词") } }
- 1、需要在Driver中创建一个累加器 — Spark自带的,累加整数类型的值
-
-
RDD的广播变量
-
广播变量和累加器还挺像的,广播变量是只能让RDD的分区获取值,而不能修改值,广播变量是只读的。
-
在Driver端声明一个广播变量以后,这样的话可以在任何一个RDD的任何一个分区中获取广播变量的值计算。而且广播变量的数据类型可以自定义
-
用法
- 1、Driver端设置广播变量
val factorBC:Broadcast[T] = sc.broadcast(变量名) - 2、RDD分区中使用广播变量
factorBC.value
package com.kang.broad import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object Demo01 { def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName("transformation").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) val rdd:RDD[Int] = sc.makeRDD(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 2) var num = 5 val broad:Broadcast[Int] = sc.broadcast(num) rdd.map(a=>{ a*broad.value }).foreach(println) sc.stop() } }
- 1、Driver端设置广播变量
-
11、RDD的分区机制
- 只有键值对类型的RDD才有分区器,分区器在执行shuffle算子的时候才会生效。
- HashPartitioner(默认)、RangePartitioner、自定义分区器
七、【补充】Scala的比较器问题
在编程语言中,数据类型基本上都是比较大小的,数值类型的数据类型可以使用大于小于比较运算符直接比较大小,面向对象中引用数据类型也是一种数据类型(自定义类型),因此我们就得需要通过一个比较器来告诉编译器我们自定义的类型如何去比较大小。
Java中存在两个比较器用于比较Java类的大小关系,Java的比较器有两个Comparable,Comparator,区别在于Comparable是让Java类必须实现的,Comparator是在使用比较器的时候使用匿名内部类的形式传递比较规则的。
Scala也是面向对象的,Scala中也存在类的概念,类在有些情况下也是必须能比较大小的。Scala也给我们提供了两个比较器,两个比较器是Java两个比较器的子接口。
Ordered 是Comparable的子接口
Ordering 是Comparator的子接口