Spring Bean的循环依赖问题
目录
初步介绍&情况分析
再分析
三级缓存
为什么要第三级缓存
"半成品"对象
为什么只支持单例
为什么不支持构造函数注入
为什么一级、二级缓存是ConcurrentHashMap而三级缓存都是HashMap
-
初步介绍&情况分析
- 循环依赖其实就是循环引用,也就是两个或者两个以上的bean互相持有对方,最终形成闭环
- 比如A依赖于B,B依赖于C,C又依赖于A
- 如下图:
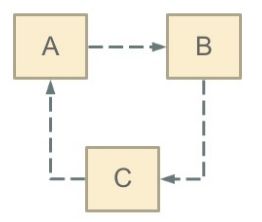
- 注意,这里不是函数的循环调用,是对象的相互依赖关系
- 循环调用其实就是一个死循环,除非有终结条件
- Spring中循环依赖场景有:
- (1)构造器的循环依赖
- (2)field属性的循环依赖
- 第一种:构造器参数循环依赖
- Spring容器会将每一个正在创建的 Bean 标识符放在一个“当前创建Bean池”中,Bean标识符在创建过程中将一直保持在这个池中,因此如果在创建Bean过程中发现自己已经在“当前创建Bean池”里时将抛出BeanCurrentlyInCreationException异常表示循环依赖
- 而对于创建完毕的Bean将从“当前创建Bean池”中清除掉


- 如果大家理解开头那句话的话,这个报错应该不惊讶
- Spring容器先创建单例StudentA,StudentA依赖StudentB,然后将A放在“当前创建Bean池”中,此时创建StudentB,StudentB依赖StudentC,然后将B放在“当前创建Bean池”中,此时创建StudentC,StudentC又依赖StudentA,但是,此时StudentA已经在池中,所以会报错,因为在池中的Bean都是未初始化完的,所以会依赖错误(初始化完的Bean会从池中移除)
- 第二种:setter方式单例,默认方式(三级缓存可以解决)
- 当然,Spring对于循环依赖的解决不是无条件的,首先前提条件是针对scope单例并且没有显式指明不需要解决循环依赖的对象
- 而且要求该对象没有被代理过
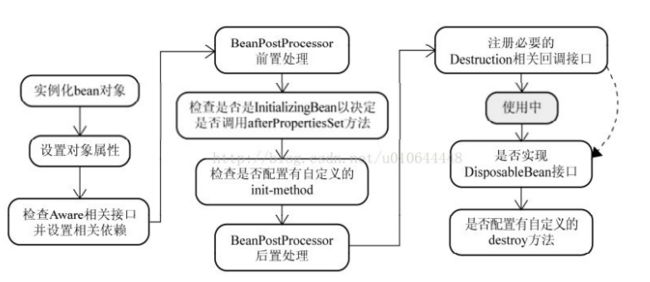
- 如图中前两步骤得知:Spring是先将Bean对象实例化之后再设置对象属性的
- 为什么用set方式就不报错了呢
- “三级缓存”主要是指

- 让我们来分析一下“A的某个field或者setter依赖了B的实例对象,同时B的某个field或者setter依赖了A的实例对象”这种循环依赖的情况
- A首先完成了初始化的第一步,并且将自己提前曝光到singletonFactories(三级缓存)中
- 此时进行初始化的第二步,发现自己依赖对象B,此时就尝试去get(B),发现B还没有被create,所以走create流程,B在初始化第一步的时候发现自己依赖了对象A,于是尝试get(A),尝试一级缓存singletonObjects(肯定没有,因为A还没初始化完全),尝试二级缓存earlySingletonObjects(也没有),尝试三级缓存singletonFactories,由于A通过ObjectFactory将自己提前曝光了,所以B能够通过ObjectFactory.getObject拿到A对象(虽然A还没有初始化完全,但是总比没有好呀)
- B拿到A对象后顺利完成了初始化阶段1、2、3,完全初始化之后将自己放入到一级缓存singletonObjects中
- 此时返回A中,A此时能拿到B的对象顺利完成自己的初始化阶段2、3,最终A也完成了初始化,长大成人,进去了一级缓存singletonObjects中,而且更加幸运的是,由于B拿到了A的对象引用,所以B现在hold住的A对象也蜕变完美了!一切都是这么神奇
- Spring通过三级缓存加上“提前曝光”机制,配合Java的对象引用原理,比较完美地解决了某些情况下的循环依赖问题
- 第三种:setter方式原型,prototype
- 为什么原型模式就报错了呢?
- 对于“prototype”作用域Bean,Spring容器无法完成依赖注入,因为“prototype”作用域的Bean,Spring容器不进行缓存,因此无法提前暴露一个创建中的Bean
-
再分析
- 在Spring框架中,循环依赖是指两个或多个bean之间相互依赖,形成了一个循环引用的情况
- 如果不加以处理,这种情况会导致应用程序启动失败

- 如以上情况,两个Bean就发生了互相依赖
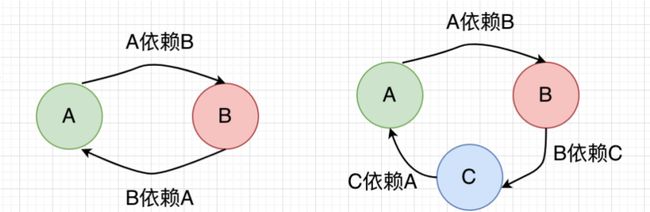
- 在Spring中,解决循环依赖的方式就是引入了三级缓存
- 三级缓存分别是存储完整对象的singletonObjects,存储半成品对象的earlySingletonObjects,存储对象的创建工厂的singletonFactories
- 在第一次创建 Bean 的时候,Spring 会把创建的 Bean 放到 singletonObjects 的缓存中
- 在创建 Bean 的过程中,如果出现了循环依赖,则创建半成品对象,即早期暴露的 Bean 引用,放到 earlySingletonObjects 缓存中
- 如果 Bean 还未完全创建完成,且早期暴露的 Bean 引用已经存在,Spring 会将 ObjectFactory 放到 singletonFactories 缓存中,以便在需要的时候调用
- 当出现循环依赖时,Spring 会从 singletonObjects 和 earlySingletonObjects 缓存中获取已经创建的对象,如果都没获取到,会调用 singletonFactories 中的 ObjectFactory 来创建半成品对象
- 在半成品对象创建完成之后,将其注入到之前创建的 Bean 中,完成循环依赖的解决
- 但是,Spring解决循环依赖是有一定限制的,首先就是要求互相依赖的Bean必须要是单例的Bean,另外就是依赖注入的方式不能都是构造函数注入的方式
-
三级缓存
- 在Spring的BeanFactory体系中,BeanFactory是Spring IoC容器的基础接口
- 其中DefaultSingletonBeanRegistry类实现了BeanFactory接口,并且维护了三级缓存:

- singletonObjects是一级缓存,存储的是完整创建好的单例bean对象
- 在创建一个单例bean时,会先从singletonObjects中尝试获取该bean的实例,如果能够获取到,则直接返回该实例,否则继续创建该bean
- earlySingletonObjects是二级缓存,存储的是尚未完全创建好的单例bean对象
- 在创建单例bean时,如果发现该bean存在循环依赖,则会先创建该bean的"半成品"对象,并将"半成品"对象存储到earlySingletonObjects中
- 当循环依赖的bean创建完成后,Spring会将完整的bean实例对象存储到singletonObjects中,并将earlySingletonObjects中存储的代理对象替换为完整的bean实例对象
- 这样可以保证单例bean的创建过程不会出现循环依赖问题
- singletonFactories是三级缓存,存储的是单例bean的创建工厂
- 当一个单例bean被创建时,Spring会先将该bean的创建工厂存储到singletonFactories中,然后再执行创建工厂的getObject()方法,生成该bean的实例对象
- 在该bean被其他bean引用时,Spring会从singletonFactories中获取该bean的创建工厂,创建出该bean的实例对象,并将该bean的实例对象存储到singletonObjects中
- 以下是DefaultSingletonBeanRegistry#getSingleton方法,该方法是获取bean的单例实例对象的核心方法:

- 以上代码包括一级缓存、二级缓存、三级缓存的处理逻辑
- 如果bean的单例实例对象在一级缓存中不存在,则需要从二级缓存和三级缓存中获取
- 同时,在允许提前引用的情况下,如果二级缓存中不存在bean实例对象,还需要加锁,以确保线程安全
- 在获取bean实例对象之后,还需要将其存储到一级缓存或者二级缓存中,以便后续的获取操作可以快速返回
-
为什么要第三级缓存
- singletonFactories是三级缓存,它里面存储的是单例Bean的创建工厂ObjectFactory,那么为什么需要存储这个对象工厂呢?为了解决什么问题呢?
- ObjectFactory是一个接口,它定义了一个获取对象的工厂,也就是获取Bean实例对象的工厂
- 具体来说,ObjectFactory接口只有一个方法:
- T getObject() throws BeansException;
- 该方法用于获取一个指定类型的对象
- Spring容器中的Bean实例对象,其实就是由ObjectFactory来创建的
- 在Spring容器初始化时,会将每个Bean定义都封装为一个BeanDefinition对象,其中包含了Bean实例化的相关信息,比如类名、构造器参数、属性值等等
- 当我们需要使用一个Bean实例时,Spring容器会根据BeanDefinition中的信息,调用相应的ObjectFactory来创建Bean实例对象
- 想要搞清楚他是干嘛的,就要看看他是在什么地方保存进去的,以下是DefaultSingletonBeanRegistry中singletonFactories被put的地方,在DefaultSingletonBeanRegistry及其子类中,只有这一个地方是put的,所以很容易找到

- 上面的方法addSingletonFactory又是在什么地方被调用的呢?
- 通过查看代码,我们也能定位到其实是在AbstractAutowireCapableBeanFactory#doCreateBean方法中,部分代码如下:
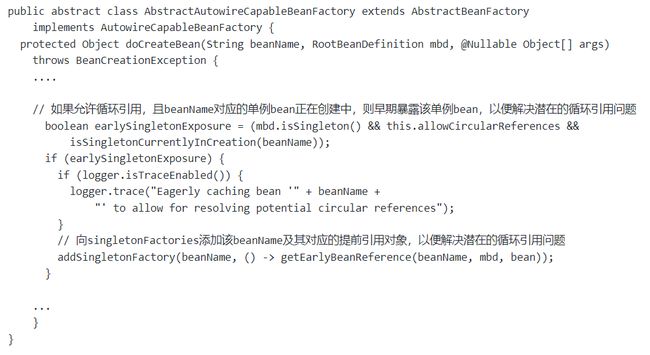
- 也就是说,在创建Bean的过程中,如果Spring发现,如果允许循环引用,且beanName对应的单例bean正在创建中,则会调用addSingletonFactory方法,会向singletonFactories添加该beanName及其对应的"提前引用对象"
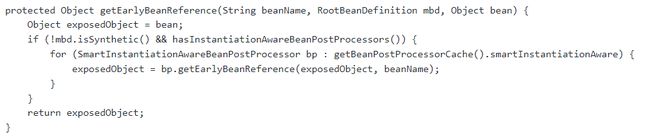
- 这个提前引用对象,是通过getEarlyBeanReference方法实现的,他的具体逻辑如下:
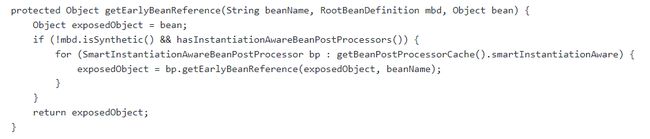
- 遍历所有的 SmartInstantiationAwareBeanPostProcessor,调用它们的 getEarlyBeanReference() 方法,将半成品对象传入
- 最终返回的 exposedObject 就是 Bean 的半成品对象
- 所以,我们现在基本可以确定,singletonFactories中缓存的是某个Bean的对象工厂,而这个对象工厂就是用来创建半成品对象的
- 而这个半成品对象会在创建出来之后被放到二级缓存中:

- 所以,如果没有singletonFactories这个第三级缓存的话,Spring就无法实现循环依赖的解决,因为循环依赖问题的解决需要借助第三级缓存中的对象工厂来创建bean的代理对象(半成品对象)
- 如果没有该缓存,当两个bean之间存在循环依赖时,就会进入死循环,因为每个bean都在等待对方创建完成,导致程序无法继续执行
- 那么,如果Spring中取消第三级缓存,而是在需要半成品对象的时候再去创建不就行了吗?
- 为啥还需要提前缓存ObjectFactory?
- 如果取消第三级缓存,那么,每次获取单例对象时都需要重新创建对象,这样会导致性能问题,特别是在需要解决大量循环依赖的情况下
- 因此,为了避免这种性能问题,Spring引入了三级缓存并提前缓存ObjectFactory,使得在需要创建半成品对象的时候,可以直接从缓存中获取ObjectFactory来创建半成品对象,避免了每次都要重新创建的性能问题
- 还有就是,SmartInstantiationAwareBeanPostProcessor还有一个实现类是AbstractAutoProxyCreator,这个类是和代理有关
- AbstractAutoProxyCreator 是 Spring 框架中用于自动代理创建的一个抽象类,它实现了getEarlyBeanReference() 方法
- 通过实现该方法,AbstractAutoProxyCreator 能够在 Bean 对象创建的过程中,及时地获取到目标对象的代理处理器,并进行代理处理
- Spring AOP的实现依赖于动态代理技术,当Bean需要被AOP代理时,Spring会为该Bean创建一个代理对象,并将该代理对象交给ApplicationContext管理,同时还需要保证代理对象也能够正常地解决循环依赖问题
- 在这个过程中,singletonFactories发挥了重要的作用
- 当需要解决循环依赖问题时,如果某个 Bean 依赖于另一个需要代理的 Bean,则需要将需要代理的 Bean 先返回一个半成品对象,等到代理对象生成后再将其注入到 Bean 中,以避免代理对象在生成时依赖于另一个还未初始化的 Bean,从而产生死循环
- 这时候,Spring会从singletonFactories缓存中获取代理工厂对象,通过调用代理工厂对象的getEarlyBeanReference方法获取代理对象,并将代理对象存储到singletonObjects缓存中
- 由于代理对象的创建需要使用其他Bean,所以代理对象的创建会放到最后完成
- 所以,第三缓存的引入,可以将创建半成品对象的对象工厂进行缓存,方便在需要的时候可以快速的使用它创建半成品对象,并且因为有了这个缓存,能够避免在多次需要同一个半成品对象的时候重复创建
- 另外,有了第三级缓存,在解决代理Bean的时候,也能把代理对象的对象工厂缓存下来,可以在需要的时候调用这个工厂来创建一个代理对象
-
"半成品"对象
- 前面提到了为了解决循环依赖,需要创建一个半成品对象,那么这个半成品对象是怎么创建出来的呢?
- SmartInstantiationAwareBeanPostProcessor 接口是 InstantiationAwareBeanPostProcessor 接口的子接口,它增加了一个方法 determineCandidateConstructors,用于在实例化 bean 前确定最佳构造函数
- 在确定构造函数之后,InstantiationStrategy 的 instantiate() 方法会使用这个构造函数来创建一个半成品对象,这个半成品对象只是 bean 对象的一个空壳子,还没有进行属性注入和初始化
- 当半成品对象创建完毕后,Spring 就可以解决循环依赖的问题了
- 在半成品对象创建完毕后,Spring 会调用 populateBean() 方法来进行属性注入和初始化,最终生成一个完整的 bean 对象并将其放入到 singletonObjects 缓存中
- 也就是说,SmartInstantiationAwareBeanPostProcessor 通过拦截 BeanFactory 的 bean 实例化过程,在实例化之前确定最适合的构造函数,创建一个半成品对象
-
为什么只支持单例
- Spring循环依赖的解决方案主要是通过对象的提前暴露来实现的
- 当一个对象在创建过程中需要引用到另一个正在创建的对象时,Spring会先提前暴露一个尚未完全初始化的对象实例,以解决循环依赖的问题
- 这个尚未完全初始化的对象实例就是半成品对象
- 在 Spring 容器中,单例对象的创建和初始化只会发生一次,并且在容器启动时就完成了
- 这意味着,在容器运行期间,单例对象的依赖关系不会发生变化
- 因此,可以通过提前暴露半成品对象的方式来解决循环依赖的问题
- 相比之下,原型对象的创建和初始化可以发生多次,并且可能在容器运行期间动态地发生变化
- 因此,对于原型对象,提前暴露半成品对象并不能解决循环依赖的问题,因为在后续的创建过程中,可能会涉及到不同的原型对象实例,无法像单例对象那样缓存并复用半成品对象
- 因此,Spring只支持通过单例对象的提前暴露来解决循环依赖问题
-
为什么不支持构造函数注入
- Spring无法解决构造函数的循环依赖,是因为在对象实例化过程中,构造函数是最先被调用的,而此时对象还未完成实例化,无法注入一个尚未完全创建的对象,因此Spring容器无法在构造函数注入中实现循环依赖的解决
- 在属性注入中,Spring容器可以通过先创建一个空对象或者提前暴露一个半成品对象来解决循环依赖的问题
- 但在构造函数注入中,对象的实例化是在构造函数中完成的,这样就无法使用类似的方式解决循环依赖问题了
-
为什么一级、二级缓存是ConcurrentHashMap而三级缓存都是HashMap
- 这几个map都可能被多线程访问,但是一级、二级缓存是相对频繁的,所以使用ConcurrentHashMap可以实现在多线程环境下高效地读取和写入singletonObjects
- 而三级缓存,只有在Bean初始化过程中才会被访问,并且并没有一级缓存那么频繁,所以加在需要保证线程安全的地方加个synchronized全局锁就行了