spark
day01_SparkBase
今日内容:
-
1-spark的基本介绍(了解)
-
1.1: spark的基本概念
-
1.2: spark的发展历程
-
1.3: spark的特点
-
-
2- spark的环境搭建 (参考安装文档搭建成功)
-
2.1: local本地模式安装操作
-
2.2: pySpark环境安装操作
-
2.3: standalone集群模式搭建操作
-
2.4: standalone HA 高可用集群模式搭建操作
-
-
3- 如何使用Python语句 完成 spark的入门案例 (作业)
1. spark的基本介绍
1.1 spark的基本介绍
-
MapReduce 分布式的计算框架:
适用于处理批量化的数据操作, 优势在于可以处理海量的数据, 同时对内存消耗是比较低, 弊端: MR运行的效率是非常低
思考: 为什么 MR运行的效率非常低呢?
MR是一个IO密集型框架, 数据在整个MR中需要不断的从磁盘到内存, 从内存到磁盘 .... 从而导致执行效率是比较低, 更加将整个计算操作, 放置在磁盘上进行运行的
第二个弊端: MR在进行迭代计算的时候, 需要构建多个MR 进行串联处理, 导致迭代计算的不方便
比如执行HIVE SQL:
select * from score where sid = (select sid from stu where name = '张三');
思考: 如果运行在HIVE上, HIVE需要翻译为几个MR来运行呢? 2个MR
第一个MR先执行 (select sid from stu where name = '张三') 将张三的 sid获取出来
第二个MR: 在执行外部的SQL, 根据第一个MR的结果进行过滤相关的数据
这种需要多个MR进行配合计算处理的操作, 称为迭代计算操作
迭代计算: 将第一个执行结果交给第二个, 第二个执行完之后, 交给第三个, 直到将最终结果计算完成
正因为有了之前MR的问题存在, 整个市场迫切的需要一款新的计算框架, 能够更加高效的执行计算任务, 而这就是spark的来源...
spark就是一款大规模数据的统一分析引擎, 基于内存计算, 整个spark核心数据结构: RDD(弹性分布式数据集)
spark在早期是由加州大学伯克莱分校的一些博士的发布一篇论文诞生的, 后期将其贡献给apache , 目前已经是apache的顶级项目
spark框架中各个节点的通信采用模块为: netty框架
spark是使用scala语言编写的
spark核心: 弹性分布式数据集(RDD), 借鉴了MR的分布式并行计算的思想, 但是解决了MR存在的一些问题, 会将中间的结果存储在内存中(如果存储不下, 也可以存储在磁盘中), 从而提升运行的效率, 同时spark对数据集提供了丰富的处理API(算子)
为什么说spark的运行效率比MR快呢?
1) 数据结构不同: 对于spark 核心数据结构RDD(基于内存的弹性的数据集)
理论为一个大的数据容器, 容器中数据是可以都存储在内存中, 直接对容器中数据执行相关API, 完成对数据在内存中处理统计操作, 这样一种基于内存的计算 要比MR这种基于磁盘的计算效率高的多(官方: 快100倍)
2) 运行方式:
spark基于多线程的运行方案. 一个进程中运行多个线程的, 由每一个线程完成具体的操作
MR基于进程的运行方案, 一个计算程序, 会启动多个Task进程来计算的
说明: 进程启动效率要远远低于在一个进程中启动线程的效率
1.2 spark的发展史
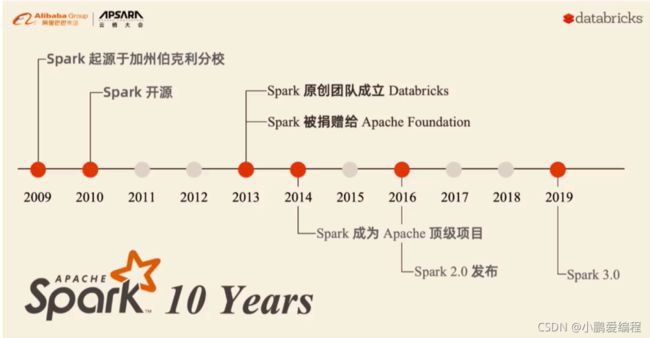
spark的发展是非常不错的, 包括在后续生产环境中, 大部分的时候都是基于spark干活
当使用spark进行操作的时候, 采用的语言主要是两种: scala(母语) 和 Python
目前使用python操作spark的人群是越来越多的, Python提供一个操作spark的库: pyspark
1.3 spark的特点
四大特点:
-
1- 运行速度快
原因一: 中间结果是可以保存在内存中, 采用DAG(有向无环图)方式运行, 官方宣称 在内存中运行要比MR快100倍, 如果基于磁盘运行, 比MR快10倍
原因二: spark是基于线程运行, 而MR是基于进程的运行, 线程启动和销毁要比进程更快
-
2- 易用性好
原因一: spark支持多种操作语言进行处理: 包括 Python sql scala java go ....
原因二: spark提供了更加高阶的API, 并且 这些API都是见名之意, 不同语言的API都是类型的
比如: reduceByKey, groupBykey ...
-
3- 通用型强
spark组成部分由很多:
spark core : spark核心库 (次重要)
包含RDD的API, 任务调度, 内存的管理API等等...
spark SQL : 用于操作结构化数据的工具库 , 可以使用SQL的方式操作数据集 (最常用)
spark streaming: spark用于流式处理(实时处理)一个库
目前使用率在不断的下降, 新的项目都是采用flink进行流式 实时统计计算
spark MLlib: 支持机器学习库 (特定人群) , 包括: 分类 回归, 聚类....
spark graphX: 支持图计算(特定人群), 比如 路程规划计算
-
4-随处运行
原因一: spark程序可以运行在更多的资源调度平台 (spark集群, yarn, 云上调度环境)
原因二: spark可以和其他的软件进行集成, 降低程序员代码难度, 比如可以和hive集成
2. spark环境安装
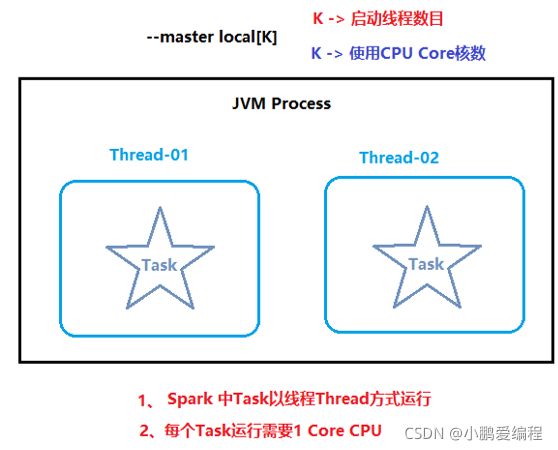
2.1 local模式搭建
本质: 启动一个java的进程(JVM进程), 在进程中启动多个线程进行运行执行
好处: 方便测试, 校验代码是否OK, 用于测试环境
弊端: 单个节点, 无法处理大规模数据
类似于 pandas, 因为pandas就是单机运行
采用提供三个虚拟机:
ip地址:
node1: 192.168.88.161
node2: 192.168.88.162
node3: 192.168.88.162
网关地址:
192.168.88.2
子网掩码:
255.255.255.0
当获取到三个虚拟机后, 首先将其解压到一个没有中文, 没有空格目录下 (磁盘空间充足 >100GB)
-
第一步: 将虚拟机挂载到VMware上
-
第二步: 修改网络编辑器(如果新零售的环境就是88网段, 那么这里只是校验, 应该都是都是一致的)
-
第三步: 启
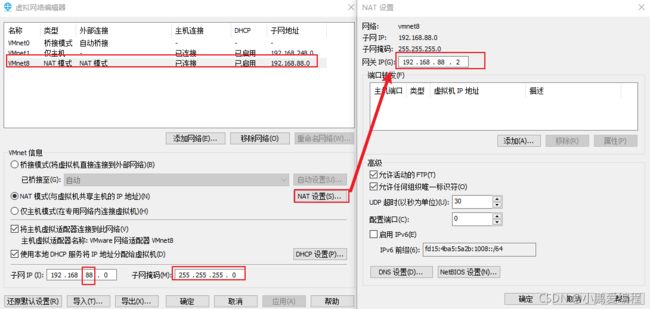 动虚拟机: 选择我已移动此虚拟机
动虚拟机: 选择我已移动此虚拟机 -
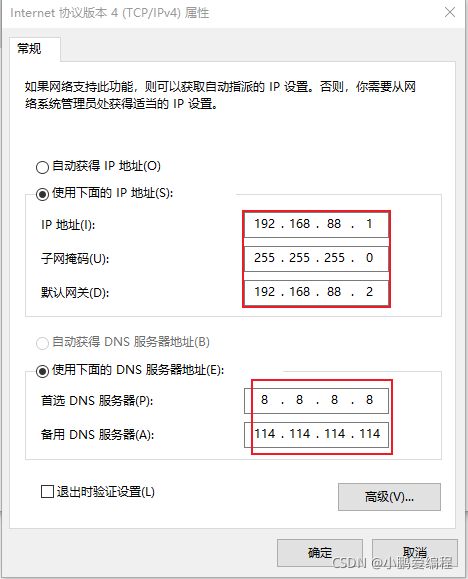 第四步: 配置windows的hosts文件: (需要将之前的有冲突的名字的删除)
第四步: 配置windows的hosts文件: (需要将之前的有冲突的名字的删除)
192.168.88.161 node1 node1.itcast.cn 192.168.88.162 node2 node2.itcast.cn 192.168.88.163 node3 node3.itcast.cn
-
第五步: 就可以使用CRT 连接虚拟机 正常使用了
注意事项: 提供虚拟机, 所有的环境都是配置好的, 大家可以直接将虚拟机恢复到对应快照下即可使用对应环境了, 如果想自己安装, 可以恢复到对应快照的上一个快照 即可自己尝试安装了 快照的恢复一定是三个节点一起恢复到同一个快照
2.1.1 local搭建
-
步骤一: 上传spark的安装包到node1的 /export/software
-
步骤二: 对包进行解压到/export/server下, 并构建软连接
-
步骤三: 启动spark客户端即可
./spark-shell [ --master local[N] ] 说明: 默认不加 --master 表示local[*] 当前节点有几个核, 启动几个线程 N: 启动线程的数量 默认为 *
说明: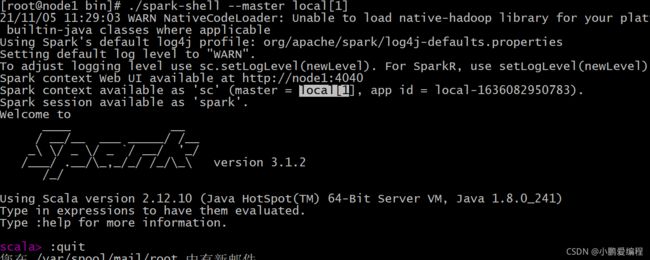
1) 客户端一旦启动后, spark提供一个客户端的任务监控界面: node1:4040 2) 启动spark客户端后, 提供 两个spark核心对象: spark context对象: spark的上下文对象(核心对象) (别名: sc) 此对象主要在spark core中使用 spark session对象: spark的会话对象 (别名: spark) 此对象主要是在spark SQL中使用 3) 启动后, 可以在窗口中通过编写scala代码 构建spark的程序了....
目前 并没有学习过scala的语言, 此界面也是无法使用的, 后续更多通过使用Python操作spark, 那么这个时候就需要构建pySpark的环境了
2.2 PySpark环境搭建
说明:
需要在虚拟机中安装pySpark的包, 但是呢发现在虚拟机中提供的Python环境是 2.7.5 环境 ,而使用Python环境为3.8环境, 导致无法使用此环境 需要先安装Python环境, 然后才能安装pySpark
首先, 安装anaconda的环境:
参考部署文档将其安装完成 注意: 安装完成后, 自动进入anaconda的base环境中, 当然也可以设置自动离开此环境 安装完成后, 需要设置一下国内的镜像, 保证后续在安装各种Python库的效率更高
接着, 安装pySpark的库:
-
方式一: 本地环境直接安装操作 (测试,或者全局环境都是统一的)
-
方式二: 构建一个虚拟环境(沙箱环境), 然后安装pySpark库 (一般是生产环境中)
为什么在生产环境中使用沙箱环境? 原因: 1) 在公司中, 一般各个项目采用Python的版本可能略有不同, 由于python各个版本之间存在不兼容情况, 公司为了解决这种问题, 一般可以通过构建沙箱环境, 独立出不同的python环境 2) 在进行独立测试的时候, 需要使用沙箱环境来测试, 避免影响本地环境配置内容
最后: 通过pySpark访问spark本地模式
cd /export/server/spark/bin ./pyspark [--master local[N]] 进入后, 其实就可以编写python代码了
注意事项:
不管在沙箱环境中操作spark, 还是在本地环境中操作spark 都是可以的,但是发现在两个环境中对应python版本是不一样的 主要原因: 在构建虚拟环境的时候, 设置python版本的时候, 没有指定小版本, 导致anaconda自动选择了新的python版本来使用
扩展说明: anaconda操作
如何创建虚拟环境: 格式 : conda create -n 虚拟环境名字 python=版本信息 例如: conda create -n pyspark_env python=3.8 如何进入指定的虚拟环境: conda activate 虚拟环境名字 或者 source activate 虚拟环境名字 如何退出当前的虚拟环境: conda deactivate [虚拟环境名字]
向spark提供一个sparkpython程序, 计算圆周率:
cd /export/server/spark/bin ./spark-submit \ --master local[*] \ /export/server/spark/examples/src/main/python/pi.py \ 10 属性说明: ./spark-submit: 此脚本用于提交spark任务使用 类似于 yarn jar 操作 --master : 将程序提交到那个位置(可选: local(默认) , spark://xxx (提交spark集群) , yarn
2.3 spark集群模式搭建_Standalone
2.3.1: spark集群架构
主节点作用: 1) 管理众多的从节点 2) 管理整个集群的资源 3) 负责接收任务 4) 负责资源和任务的分配 从节点作用: 1) 从节点负责和主节点进行通信, 报告自己资源情况 2) 管理自己的资源信息 3) 负责接收主节点分配的任务, 进行任务的具体执行
2.3.2 spark集群构建(非高可用)
意味着, 主节点只需要一台即可 + 多个 从节点 + 可选的历史任务服务节点
整个安装操作, 大家可以参考部署文档即可
如何启动spark集群:
1) 必须先启动hadoop集群: 在node1的任何位置下, 执行start-all.sh 2) 启动spark的集群: node1 统一启动: 主节点和从节点 cd /export/server/spark/sbin ./start-all.sh 统一关闭: ./stop-all.sh 单独启动主节点: cd /export/server/spark/sbin ./start-master.sh 单独停止主节点: cd /export/server/spark/sbin ./stop-master.sh 单独启动从节点: 一次性启动所有的从节点: node1执行可以将三个从节点都启动 ./start-slaves.sh 一次性关闭所有的从节点: ./stop-slaves.sh 单独启动某一个从节点: 需要启动哪一个, 就到对应节点下启动即可 ./start-slave.sh 单独停止某一个从节点: ./stop-slave.sh 如何访问: node1:8080 访问spark集群
如何进入spark集群的客户端呢?
-
spark-shell操作
cd /export/server/spark/bin/ ./spark-shell --master spark://node1:7077
-
pyspark客户端:
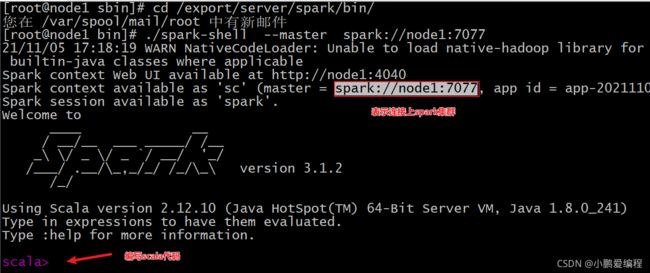
cd /export/server/spark/bin/ ./pyspark --master spark://node1:7077
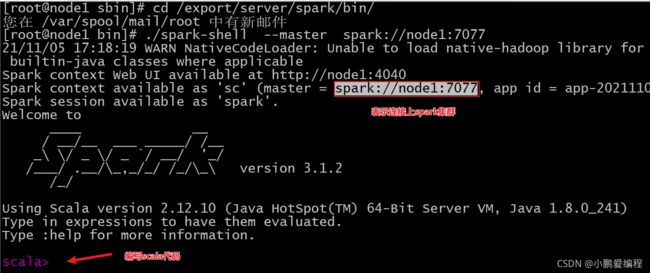
-
如何向集群提交spark任务:
cd /export/server/spark/bin ./spark-submit \ --master spark://node1:7077 \ /export/server/spark/examples/src/main/python/pi.py \ 10

测试案例: 通过 pyspark完成 WordCount入门案例
需求:
第一步: 先在node1的 /root目录下创建words.txt文件 内容如下: hello hadoop hive hadoop hello hive hadoop world hive hive hive hadoop sqoop sqoop 第二步: 将 words.txt上传到 hdfs的目录中: hdfs dfs -put words.txt / 需求 : 统计在这个words.txt文件中, 各个单词出现了多少次?
编写代码: 初体验
第一步: 读取HDFS上文件数据:
res1 = sc.textFile("hdfs://node1:8020/words.txt")
第二步: 对数据执行切割操作: 形成一个列表, 列表中每一个元素就是一个个单词
res2 = res1.flatMap(lambda line : line.split(" "))
第三步: 对每一个单词进行转换为: (单词,1)
res3 = res2.map(lambda word : (word,1))
第四步: 对单词进行分组操作, 将相同的单词放置在同一个组内, 进行统计操作
res4 = res3.reduceByKey(lambda agg,curr : agg + curr )
第五步: 查看统计的结果
res4.collect()
得到结果内容:
[('hadoop', 4), ('hive', 5), ('world', 1), ('sqoop', 2), ('hello', 2)]
注意:
整个操作, 大家可以分步骤通过 collect收集数据, 看到每一步的执行结果
升级一下: 将上述代码写成一行: 链式编程
sc.textFile("hdfs://node1:8020/words.txt").flatMap(lambda line : line.split(" ")).map(lambda word : (word,1)).reduceByKey(lambda agg,curr : agg + curr ).collect()
2.4 spark的Standalone HA搭建
spark集群的高可用
所谓的高可用, 指的就是让spark集群中 主节点高可用 ,目前spark的standalone模式下, 主节点只有一台, 存在单点故障的问题 解决方案: 当主节点变成多台, 其中一台为active(激活)节点, 另外主节点为standby状态(备份节点) 一般来说: 备份方案 一主一备 或者 一主两备
思考: 当有了多个主节点后, 到底有谁来担任激活的master节点呢?
1) 当Master启动后, 建立与zookeeper的会话连接, 在zookeeper上创建一个 /master的临时节点, 那个节点将这个临时节点创建成功了, 谁就是active的master了
2) 其他的Master发现已经有节点创建了 /master的临时节点 , 其他节点就为standby节点即可, 同时这些节点对 /master的临时节点进行监听
3) 一旦 发现 /master的临时节点 被删除了, 说明Master已经宕机了, 其他备份节点立即去抢着创建这个 master临时节点, 谁抢上 谁就是active节点了
注意:
除了通过监听来检测后, 也可以使用定时检测这个Master节点是否存在, 当然这种定时检测的时效性比较差, 会存在延迟
如何配置高可用的模式呢? 参考部署文档即可
连接说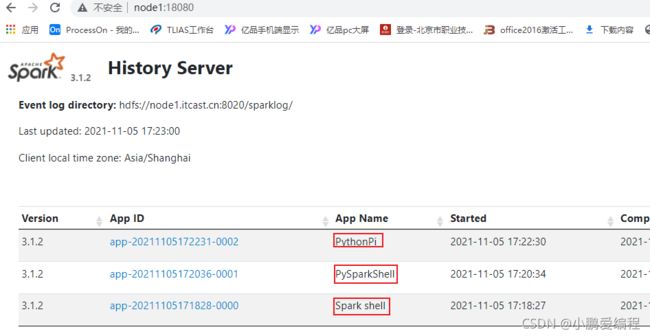 明:
明: