Flink的window(窗口)
Flink的window(窗口)
1.Flink窗口的概念
窗口(window)就是将无限流切割为有限流的一种方式,它会将流数据分发到有限大小的桶(bucket)中进行分析

2.Flink的窗口分类
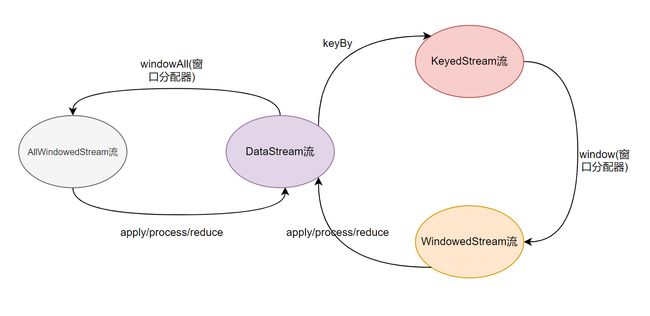
其实, 在用window前首先需要确认应该是在keyBy后的流上用, 还是在没有keyBy的流上使用.
2.1Non-Keyed Windows
在non-keyed stream上使用窗口,只能调用windowAll()方法,返回AllWindowedStream流.Flink会把所有数据放到同一个窗口中.导致只有一个并行度.官方不建议使用.
在non-keyed stream上使用窗口,无论并行度设置的是几.窗口的并行度都是1, 所有的窗口逻辑只能在一个单独的task上执行
public class WindowAll {
public static void main(String[] args) throws Exception {
//1.获取流的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.从端口获取数据
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
//3.将数据转为Tuple
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDStream = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String s : split) {
out.collect(Tuple2.of(s, 1));
}
}
});
//TODO windowAll
AllWindowedStream<Tuple2<String, Integer>, TimeWindow> windowAll = wordToOneDStream.windowAll(new TumblingAlignedProcessingTimeWindows(5));
env.execute();
}
}
2.2Keyed Windows
必须keyBy之后才可以调用窗口方法.
一个完整的Keyed Windows操作,必须包含三步:
1.keyBy
2.window(窗口分配器)
3.窗口函数即聚合操作(增量聚合/全量聚合)
Keyed Windows分类
基于时间的窗口
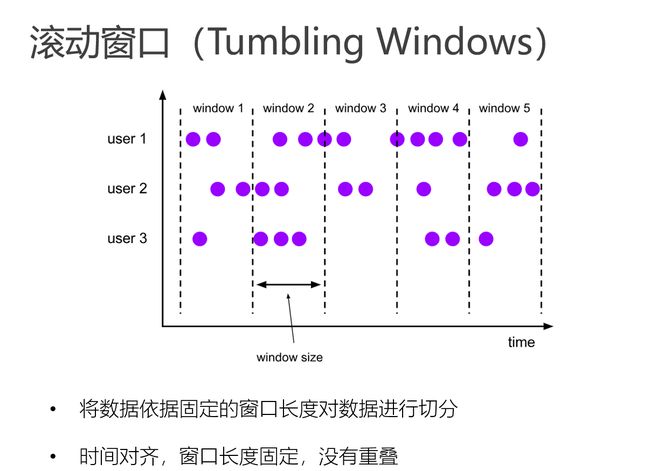
滚动窗口(Tumbling Windows)
滚动窗口能将数据流切分成不重叠的窗口,每一个事件只能属于一个窗口。
Tumbling Windows首先是Keyed Windows,那么KeyBy之后每个分组怎么维护窗口呢?
属于同一个时间的,所有分组的数据都在同一个窗口里边.-->换句话说也就是窗口关闭时,所有分组的窗口都关闭
//TODO keyBy 要想调用window方法必须keyBy
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDStream.keyBy(r -> r.f0);
//TODO 调用window()方法 开启一个基于处理时间的5s滚动窗口
//window()方法中,传入窗口分配器 得到WindowedStream
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
//TODO 窗口函数(增量/全量聚合)
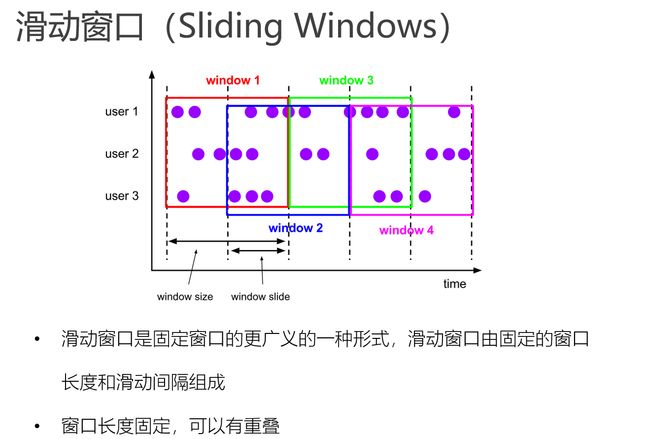
滑动窗口(Sliding Windows)
Sliding Windows首先是Keyed Windows,那么KeyBy之后每个分组怎么维护窗口呢?
属于同一个时间的,所有分组的数据都在相同窗口里边.-->换句话说也就是窗口关闭时,所有分组的窗口都关闭
//TODO keyBy 要想调用window方法必须keyBy
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDStream.keyBy(r -> r.f0);
//TODO 调用window()方法 开启一个基于处理时间的 窗口长度为6s,滑动步长为3s的滑动窗口
//window()方法中,传入窗口分配器 得到WindowedStream
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(SlidingProcessingTimeWindows.of(Time.seconds(6), Time.seconds(3)));
//TODO 窗口函数(增量/全量聚合)
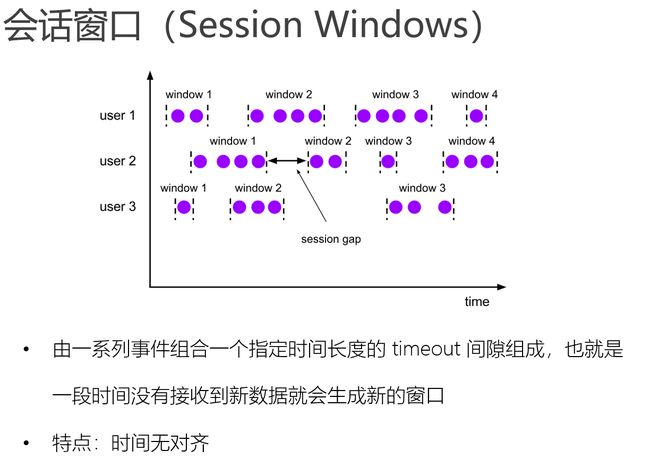
会话窗口(Session Windows)
会话窗口分配器会根据活动的元素进行分组. 会话窗口不会有重叠, 与滚动窗口和滑动窗口相比, 会话窗口也没有固定的开启和关闭时间.
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的时间就是会话窗口的gap(间隔)
我们可以配置静态的gap, 也可以通过一个gap extractor 函数来定义gap的长度. 当时间超过了这个gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话窗口
Session Windows首先是Keyed Windows,那么KeyBy之后每个分组怎么维护窗口呢?
从图中可以看出,每个key(分组)维护了自己的窗口.-->换句话说Session Windows窗口的关闭只是这个分组Session Windows的关闭.
创建原理:
因为会话窗口没有固定的开启和关闭时间, 所以会话窗口的创建和关闭与滚动, 滑动窗口不同. 在Flink内部, 每到达一个新的元素都会创建一个新的会话窗口, 如果这些窗口彼此相距比较定义的gap小, 则会对他们进行合并. 为了能够合并, 会话窗口算子需要合并触发器和合并窗口函数: ReduceFunction, AggregateFunction, or ProcessWindowFunction
- 静态gap
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
- 动态gap
.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) { // 返回 gap值, 单位毫秒
return element.f0.length() * 1000;
}
}))
全局窗口(Global Windows)
全局窗口分配器会分配相同key的所有元素进入同一个 Global window. 这种窗口机制只有指定自定义的触发器时才有用. 否则, 不会做任务计算, 因为这种窗口没有能够处理聚集在一起元素的结束点.
很少用,没研究

示例代码:
.window(GlobalWindows.create());
基于元素个数的窗口
按照指定的数据条数生成一个Window,与时间无关
滚动窗口
默认的CountWindow是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
实例代码
.countWindow(3)
说明:那个窗口先达到3个元素, 哪个窗口就关闭. 不影响其他的窗口.
滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是window_size,一个是sliding_size。下面代码中的sliding_size设置为了2,也就是说,每收到两个相同key的数据就计算一次,每一次计算的window范围最多是3个元素。
实例代码
.countWindow(3, 2)
3.Keyed Windows使用
必须keyBy之后才可以调用Keyed Windows窗口方法.
一个完整的Keyed Windows操作,必须包含三步:
1.keyBy
2.window(窗口分配器)
3.窗口函数即聚合操作(增量聚合/全量聚合)
Window Function
window function 定义了要对窗口中收集的数据做的计算操作
可以分为两类
1.增量聚合函数(incremental aggregation functions)
每条数据到来就进行计算,保持一个简单的状态.直到触发状态输出才会输出状态
ReduceFunction, AggregateFunction,滚动聚合函数(max,sum,min,maxBy等)
2.全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
ProcessWindowFunction,WindowFunction
增量聚合函数是来一条计算一条,而全窗口函数则是等到数据都到了再做计算做一次计算。
3.1增量聚合函数
增量聚合函数是来一条计算一条,并把计算结果写入状态.直到触发状态输出才会输出状态
ReduceFunction(不会改变数据的类型)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
System.out.println(value1 + " ----- " + value2);
// value1是上次聚合的结果. 所以遇到每个窗口的第一个元素时, 这个函数不会进来
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
})
AggregateFunction(可以改变数据的类型)
public class Tumbling {
public static void main(String[] args) throws Exception {
//1.获取流的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.从端口获取数据
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
//3.将数据转为Tuple
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDStream = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String s : split) {
out.collect(Tuple2.of(s, 1));
}
}
});
//TODO keyBy 要想调用window方法必须keyBy
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDStream.keyBy(r -> r.f0);
//TODO 调用window()方法 开启一个基于处理时间的5s滚动窗口
//window()方法中,传入窗口分配器 得到WindowedStream
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
//TODO 窗口函数(增量/全量聚合)
//增量聚合
//AggregateFunction:IN->输入数据类型 ACC->accumulator累积器即中间聚合状态 OUT->输出数据类型
//输入数据类型是Tuple2 输出是Integer --->改变了输入/出数据类型
SingleOutputStreamOperator<Integer> resultDStream = windowedStream.aggregate(new AggregateFunction<Tuple2<String, Integer>, Integer, Integer>() {
//创建中间状态初始值
@Override
public Integer createAccumulator() {
return 0;
}
//累加的逻辑
@Override
public Integer add(Tuple2<String, Integer> value, Integer accumulator) {
return accumulator + value.f1;
}
//返回最后输出结果
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
//一般时间窗口装用不上,主要用在SessionWindow中
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
});
resultDStream.print();
env.execute();
}
}
3.2全窗口函数
ProcessWindowFunction (全窗口函数)可以得到一个包含这个窗口中所有元素的迭代器, 以及这些元素所属窗口的一些元数据信息.
等到触发计算才会触发计算
全窗口函数应用场景:可以求百分之多少的数据或者求平均数这种需要把全部数据拿到之后再求的场景。
ProcessWindowFunction(全窗口函数)
.process(new ProcessWindowFunction<Tuple2<String, Long>, Tuple2<String, Long>, String, TimeWindow>() {
// 参数1: key 参数2: 上下文对象 参数3: 这个窗口内所有的元素 参数4: 收集器, 用于向下游传递数据
@Override
public void process(String key,
Context context,
Iterable<Tuple2<String, Long>> elements,
Collector<Tuple2<String, Long>> out) throws Exception {
System.out.println(context.window().getStart());
long sum = 0L;
for (Tuple2<String, Long> t : elements) {
sum += t.f1;
}
out.collect(Tuple2.of(key, sum));
}
})
WindowFunction (全窗口函数)
public static void main(String[] args) throws Exception {
//1.获取流的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.从端口获取数据
DataStreamSource<String> streamSource = env.socketTextStream("hadoop102", 9999);
//3.将数据转为Tuple
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDStream = streamSource.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] split = value.split(" ");
for (String s : split) {
out.collect(Tuple2.of(s, 1));
}
}
});
//TODO keyBy 要想调用window方法必须keyBy
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDStream.keyBy(r -> r.f0);
//TODO 调用window()方法 开启一个基于处理时间的5s滚动窗口
//window()方法中,传入窗口分配器 得到WindowedStream
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
//TODO 窗口函数(全量聚合)
//WindowFunction, Integer, String, TimeWindow>
//Tuple2:输入 Integer:输出 String: key
windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Tuple3<Long,Long,Integer>, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple3<Long,Long,Integer>> out) throws Exception {
Iterator<Tuple2<String, Integer>> iterator = input.iterator();
List list = IteratorUtils.toList(iterator);
long windowEnd = window.getEnd();
long windowStart = window.getStart();
out.collect(new Tuple3<Long, Long, Integer>(windowStart,windowEnd,list.size()));
}
}).print();
env.execute();
}
4.其他API
.trigger() —— 触发器:定义 window 什么时候关闭,触发计算并输出结果
.evictor() —— 移除器:定义移除某些数据的逻辑
.allowedLateness() —— 允许处理迟到的数据.到了窗口关闭时间,只触发计算并输出,而且之后来一条计算一次并输出,不会关闭窗口.等迟到时间到了,触发窗口关闭.
.sideOutputLateData() —— 将迟到的数据放入侧输出流(SingleOutputStreamOperator的API,只针对EventTime windows才有意义)
.getSideOutput() —— 获取侧输出流(SingleOutputStreamOperator的API)
5.window API 总览

6.Flink流的转换