什么是索引覆盖?什么是索引下推?
索引覆盖
在执行某个查询语句时,在一颗索引数上就能够获取sql所需要的所有列的数据,无需回表。
这就是索引覆盖
当发起一个索引覆盖的查询时,在explain的extra列会显示Using index
如何实现索引覆盖呢?
常见方法:将被查询的字段建立到联合索引里去。
举个例子
先建立一张表,表结构如下
create table user(
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;然后执行sql语句:
select id, name, sex from user where name='zhangsan'显而易见,这个sql是可以命中name索引的,但是这个sql 不符合索引覆盖,
原因就是name索引的叶子节点只存储了id和name字段,没有存储sex,sex字段必须回表查询才能获取到,需要拿到id值到主键索引获取sex字段
这时如果把(name)单列索引换成联合索引(name, sex),
那就不同了,索引的叶子节点存储了主键id、name、sex
那么上面的sql 语句就可以命中索引覆盖无需回表,查询效率更高。
索引下推
索引条件下推 也被称为 索引下推(Index Condition Pushdown)ICP
MySQL5.6新添加的特性,用于优化数据查询的。
5.6之前通过非主键索引查询时,存储引擎通过索引查询数据,然后将结果返回给MySQL server层,在server层判断是否符合条件,在以后的版本可以使用索引下推,当存在索引列作为判断条件时,Mysql server 将这一部分判断条件传递给存储引擎,然后存储引擎会筛选出符合传递传递条件的索引项,即在存储引擎层根据索引条件过滤掉不符合条件的索引项,然后回表查询得到结果,将结果再返回给Mysql server,有了索引下推的优化,在满足一定条件下,存储 引擎层会在回表查询之前对数据进行过滤,可以减少存储引擎回表查询的次数。
假如有一张表user
表有四个字段 id,name,level,tool
| id | name | level | tool |
| 1 | 大王 | 1 | 电话 |
| 2 | 小王 | 2 | 手机 |
| 3 | 小李 | 3 | BB机 |
| 4 | 大李 | 4 | 马儿 |
建立联合索引(name,level)
匹配姓名第一个字为“大”,并且level为1的用户,sql语句为
select * from user where name like "大%" and level = 1;在5.6之前,执行流程是如下图
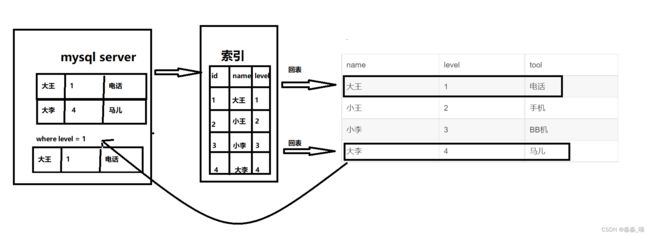
5.6及之后,执行流程图如下
 使用索引下推后由两次回表变为一次,提高了查询效率。
使用索引下推后由两次回表变为一次,提高了查询效率。