Linux超能力BPF技术介绍及学习分享
转自:https://www.sohu.com/a/418582768_198222
近两年BPF技术跃然成为了一项热门技术,在刚刚结束的KubeCon 2020 Europe会议上有7个关于BPF的技术分享, 而在KubeCon 2020 China会议上也已有了3个关于BPF技术的中文分享,分别来自腾讯和PingCAP,涉足网络优化和系统追踪等领域。在中文社区里,包括阿里巴巴、网易、字节跳动等国内第一梯队IT公司也越来越关注BPF这项新技术。本文主要介绍BPF技术发展和应用,以及我是如何学习BPF技术的。
BPF是什么?
需要回答BPF是什么?就得先回答为什么需要BPF?
多年前很多程序,例如网络监控器,都是作为用户级进程运行的。为了分析只在内核空间运行的数据,它们必须将这些数据从内核空间复制到用户空间的内存中去,并进行上下文切换。
这与直接在内核空间分析这些数据相比,导致了巨大的性能开销。
而随着近年来网络速度和流量井喷式增长,一些应用程序必须处理大量的数据(如音频、视频流媒体数据)。要在用户空间监控分析那么多的流量数据已经不可行了,因而BPF应运而生——一种在内核空间执行高效安全的程序的机制。
BPF全称是「Berkeley Packet Filter」,翻译过来是「伯克利包过滤器」,顾名思义,它是在伯克利大学诞生的,1992年Steven McCanne和Van Jacobson写了一篇论文:《The BSD Packet Filter: A New Architecture for User-level Packet Capture》,第一次提出了BPF技术,在文中,作者描述了他们如何在Unix内核实现网络数据包过滤,这种新的技术比当时最先进的数据包过滤技术快20倍。
下图为BPF概览,来自上面的论文:

BPF 在数据包过滤上引入了两大革新:
- 一个新的虚拟机(VM)设计,可以有效地工作在基于寄存器结构的CPU之上;
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息,最大程度地减少BPF 处理的数据,提高处理效率。
我们熟悉的tcpdump就是基于BPF技术,成为了站在神器肩膀上的神器。
发展到现在名称升级为eBPF:extended Berkeley Packet Filter。演进成一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者。其使用场景不再仅仅是网络分析,可以基于eBPF开发性能分析、系统追踪、网络优化等多种类型的工具和平台。
eBPF由执行字节码指令、存储对象和帮助函数组成,字节码指令在内核执行前必须通过BPF验证器的验证,同时在启用BPF JIT模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行,具有很高的执行效率。
下图是eBPF工作原理演示:

原来的BPF就被称为cBPF(classic BPF),目前已基本废弃。当前Linux 内核只运行eBPF,内核会将cBPF透明转换成eBPF再执行。下文提到的BPF字样没有特别说明的话,是泛指cBPF和eBPF。
BPF技术发展史
从1992年发布以来,BPF技术快速发展,除了技术本身得到了升级,基于它的工具和平台也如雨后春笋一般层出不穷,下面是我整理的BPF技术发展史,里面罗列几个重要的eBPF发展里程碑和基于eBPF技术的工具和平台的诞生事件,其中包括BCC、Cilium、Falco、bpftrace、kubectl-trace,还有最近非常热门的腾讯云独创的IPVS-BPF模式。

关注公众号『 分布式实验』,回复关键词: BPF,获取高清图片下载链接。
那么对于Linux内核开发来说,BPF究竟有哪些超能力,吸引了这么多的开发者纷纷「入局」?
在了解BPF的超能之前,我们先来看下当前Linux内核有哪些困难?
传统的Linux内核开发需要实现以下3个目标:
- 强安全,即不能允许不可信的代码运行在内核中,这是头等重要的事情
- 高性能,作为承载千百万服务的操作系统内核,如果没有高性能的保障,互联网蓬勃发展将收到严重影响
- 持续交付,在越来越多应用进入到云原生时代的今天,持续交付这个命题,一点都不陌生,而在内核开发领域,这点也至关重要,每次功能的升级,都需要你重新安装新的系统,大多数人都不会买账。我们希望做到跟Chrome浏览器升级一样,用户都不会注意到升级完成了(除非有一些视觉上的变化),实现真正的无缝升级。
想要实现上面的目标,没有想象中那么简单。
我们来看进行Linux内核开发的一般解决方案以及它们的缺陷。
- 直接修改内核代码进行开发,通过API暴露能力,可能要等上n年用户才能更新到这个版本来使用,而且每次的功能更新都可能需要重新编译打包内核代码。
- 开发新的可即时加载的内核模块,用户可以在运行时加载到Linux内核中,从而实现扩展内核功能的目的。然而每次内核版本的官方更新,可能会引起内核API的变化,因此你编写的内核模块可能会随着每一个内核版本的发布而不可用,这样就必须得为每次的内核版本更新调整你的模块代码,你得非常小心,不然就会让内核直接崩溃。
来看BPF带来的解决方案,它是如何实现上面3个目标的:
- 强安全:BPF验证器(verifier)会保证每个程序能够安全运行,它会去检查将要运行到内核空间的程序的每一行是否安全可靠,如果检查不通过,它将拒绝这个程序被加载到内核中去,从而保证内核本身不会崩溃,这是不同于开发内核模块的。比如以下几种情况是无法通过的BPF验证器的:
- BPF验证机制很像Chrome浏览器对于Java脚本的沙盒机制。
- 没有实际加载BPF程序所需的权限
- 访问任意内核空间的内存数据 将任意内核空间的内存数据暴露给用户空间
- 高性能: 一旦通过了BPF验证器,那么它就会进入JIT编译阶段,利用Just-In-Time编译器,编译生成的是通用的字节码,它是完全可移植的,可以在x86和ARM等任意球CPU架构上加载这个字节码,这样我们能获得本地编译后的程序运行速度,而且是安全可靠的。
- 持续交付:通过JIT编译后,就会把编译后的程序附加到内核中各种系统调用的钩子(hook)上,而且可以在不影响系统运行的情况下,实时在线地替换这些运行在Linux内核中的BPF程序。举个例子,拿一个处理网络数据包的应用程序来说,在每秒都要处理几十万个数据包的情况下,在一个数据包和下一个数据包之间,加载到网络系统调用hook上的BPF程序是可以自动替换的,可以预见到的结果是,上一个数据包是旧版本的程序在处理,而下一个数据包就会看到新版本的程序了,没有任何的中断。这就是无缝升级,从而实现持续交付的能力。
因此,大名鼎鼎的系统性能优化专家Brendan Gregg对于BPF的到来,就给出了以下的名言:
“Super powers have finally come to Linux” — Brendan Gregg
BPF的超能力
第一个,BPF Hooks,即BPF钩子,也就是在内核中,哪些地方可以加载BPF程序,在目前的Linux内核中已经有了近10种的钩子,如下所示:
- kernel functions(kprobes)
- userspace functions(uprobes)
- system calls
- fentry/fexit
- Tracepoints
- network devices(tc/xdp)
- network routes
- TCP congestion algorithms
- sockets(data level)
从文件打开、创建TCP链接、Socket链接到发送系统消息等几乎所有的系统调用,加上用户空间的各种动态信息,都能加载BPF程序,可以说是无所不能。它们在内核中形成不同的BPF程序类型,在加载时会有类型判断。
下图的内核代码片段是用来判断BPF程序类型:

第二个核心技能点——BPF Map。
一个程序通常复杂的逻辑都有一个必不可少的部分,那就是记录数据的状态。对于BPF程序来说,可以在哪里存储数据状态、统计信息和指标信息呢?这就是BPF Map的作用,BPF程序本身只有指令,不会包含实际数据及其状态。我们可以在BPF程序创建BPF Map,这个Map像其他编程语言具有的Map数据结构类似,也有很多类型,常用的就是Hash和Array类型,如下所示:
- Hash tables,Arrays
- LRU(Least Recently Used)
- Ring Buffer
- Stack Trace
- LPM(Longest Prefix match)
下图所示是一个典型的BPF Map创建代码:

值得一提的是:
- BPF Map是可以被用户空间访问并操作的
- BPF Map是可以与BPF程序分离的,即当创建一个BPF Map的BPF程序运行结束后,该BPF Map还能存在,而不是随着程序一起消亡
基于上面两个特点,意味着我们可以利用BPF Map持久化数据,在不丢失重要数据的同时,更新BPF程序逻辑,实现在不同程序之间共享信息,在收集统计信息或指标等场景下,尤其有用。
第三个核心技能点——BPF Helper Function,即BPF辅助函数。

它们是面向开发者的,提供操作BPF程序和BPF Map的工具类函数。由于内核本身会有不定期更新迭代,如果直接调用内核模块,那天可能就不能用了,因此通过定义和维护BPF辅助函数,由BPF辅助函数来去面对后端的内核函数的变化,对开发者透明,形成稳定API接口。
例如,BPF程序不知道如何生成一个随机数,有一个BPF辅助函数会可以帮你检索并询问内核,完成“给我一个随机数”的任务,或者“从BPF Map中读取某个值”等等。任何一种与操作系统内核的交互都是通过BPF辅助函数来完成的,由于这些都是稳定的API,所以BPF程序可以跨内核版本进行移植。
下图是部分BPF辅助函数的列表:

介绍完这些BPF超能力的技能点,接下来要讲讲超能力也有限制的地方。
BPF技术虽然强大,但是为了保证内核的处理安全和及时响应,内核对于BPF 技术也给予了诸多限制,如下是几个重点限制:
- eBPF程序不能调用任意的内核参数,只限于内核模块中列出的BPF Helper函数,函数支持列表也随着内核的演进在不断增加
- eBPF程序不允许包含无法到达的指令,防止加载无效代码,延迟程序的终止
- eBPF程序中循环次数限制且必须在有限时间内结束
- eBPF堆栈大小被限制在MAX_BPF_STACK,截止到内核Linux 5.8版本,被设置为512。 目前没有计划增加这个限制,解决方法是改用BPF Map,它的大小是无限的。
- eBPF字节码大小最初被限制为4096条指令,截止到内核Linux 5.8版本, 当前已将放宽至100万指令(BPF_COMPLEXITY_LIMIT_INSNS),对于无权限的BPF程序,仍然保留4096条限制(BPF_MAXINSNS)
更多相关信息可以查看这里:https://github.com/DavadDi/bpf_study#23-ebpf-的限制
随着技术的发展和演进,限制也在逐步放宽或者提供了对应的解决方案。
BPF应用场景
接下来我们通过3个案例分析,来看下具有强大超能力的BPF在实际环境中的应用场景:
1、Cilium,是首款完全基于eBPF程序实现了kube-proxy的所有功能的Kubernetes CNI网络插件,无需依赖iptables和IPVS。
我们知道kube-proxy基于iptables的服务负载均衡功能在大规模容器场景下具有严重的性能瓶颈,同时由于容器的创建和销毁非常频繁,基于IP做身份关联的故障排除和安全审计等也很难实现。
Cilium作为一款Kubernetes CNI插件,从一开始就是为大规模和高度动态的容器环境而设计,并且带来了API级别感知的网络安全管理功能,通过使用基于Linux内核特性的新技术——BPF,提供了基于Service/Pod/Container作为标识,而非传统的IP地址,来定义和加强容器和Pod之间网络层、应用层的安全策略。因此,Cilium不仅将安全控制与寻址解耦来简化在高度动态环境中应用安全性策略,而且提供传统网络第3层、4层隔离功能,以及基于http层上隔离控制,来提供更强的安全性隔离。
另外,由于BPF可以动态地插入控制Linux系统的程序,实现了强大的安全可视化功能,而且这些变化是不需要更新应用代码或重启应用服务本身就可以生效,因为BPF是运行在系统内核中的。
以上这些特性,使Cilium能够在大规模容器环境中也具有高度可伸缩性、可视化以及安全性。
如何通过eBPF程序实现请求转发的原理分析:
Cilium通过将eBPF程序加载到内核的几个网络Hook上,包括TC,XDP,实现了原来Kube-Proxy请求转发的能力。在内核网络栈中,这两个网络hook都要比kube-proxy所依赖的iptables处于更早的网络前端,还没有生成完全的网络报文的上下文(包含更复杂的元数据结构),因此具有更高的网络数据处理效率,如下图所示:

配合eBPF Map存储后端Pod地址和端口,实现高效查询和更新。

更多Cilium部署使用内容可以看我的这篇博文:《 最Cool Kubernetes网络方案Cilium入门教程 》
2、Falco,来自老牌安全厂商Sysdig开源的关注云原生运行时安全的项目。
当前问题:目前云原生时代Kubernetes技术解决了基础架构平台Day 1 Operation问题,而Day 2 Operation包含了monitor,maintain,和 troubleshoot等一系列运行时工作,其中「云原生安全问题」已经引起越来越多的注意。
Falco解决方案:Falco是第一个加入CNCF的关注云原生运行时安全的开源项目,目前是威胁Kubernetes平台监测引擎的事实标准,还可以监测意外的应用行为和运行时发出的威胁警告。
如何使用eBPF程序实现实时应用监控:
Falco主要使用了raw_tracepoint的系统调用hook,检测应用进程的启动和退出,然后通过Perf类型的BPF Map将检测到的数据发送回用户空间,实现监控的pipeline。官方Falco已自带了很多默认监控规则,具体可以查看Falco pod中的/etc/falco/falco_rules.yaml文件。
下面几个样例:


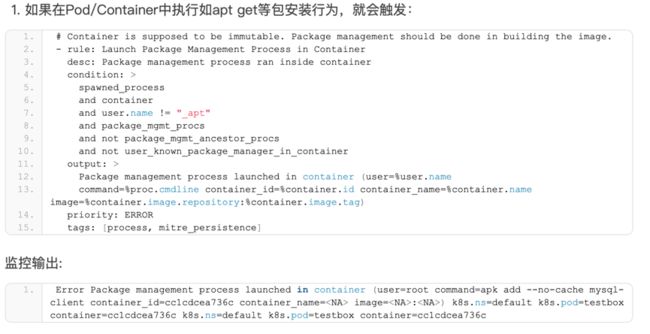
最近两年KubeCon大会上都有Falco的精彩talk,都是来自Sysdig的 大神,介绍了Falco的运作原理和使用场景,是了解掌握Falco非常好的材料,其中Kris Nova是个非常cool的技术女神,她的PPT也非常有个性,是基于命令行的。
更多Falco部署使用内容可以看我的这篇博文:https://davidlovezoe.club/wordpress/archives/831
3、Kubectl-trace,一款基于bpftrace的kubectl插件,帮助用户追踪排查Kubernetes应用的运行情况。
首先介绍下bpftrace,它是一种高阶的描述系统追踪的语言,其优势在于可以通过一行脚本(One-Liner)实现多种应用追踪能力,如下图所示:

通过和BCC集成,能实现更强追踪能力。如果你想要的脚本比较复杂,可以放在一个扩展名为bt的文件里,如下图所示的bashreadline.bt:

回到我们的kubectl-trace,它的能力就是可以把定义好的bpftrace脚本attach到指定的节点、Pod上,来追踪脚本里定义的目标。具体来说,kubectl-trace插件在Kubernetes集群内是通过名为trace-runner的job形式指定执行一个bpftrace程序,如下图所示:

而在这个trace-runner job的Pod中,它的工作原理就是一个原生BPF程序原生的工作流程了,通过加载BPF程序(即bpftrace生成的)到kprobes,uprobes,tracepoints等系统调用hook上,并把程序的输出重定向到磁盘上,以便进行事后查询,整体工作流程如下图所示:

蓬勃发展的BPF社区和生态
各种社区网站,是学习BPF的好去处:
- https://ebpf.io,最全BPF学习资源网站,主要由Cilium团队维护,上面会及时更新BPF技术的文档和视频。
- https://lwn.net/Kernel/Index/#Berkeley_Packet_Filter,LWN是学习Linux内核技术的最好的网站,这个BPF分类文章集合,记录了很多BPF里程碑事件的前前后后,既学会了知识,又明白了背景。
- https://cilium.readthedocs.io/en/stable/bpf/,Cilium提供的BPF文档,是我看到过的最具实战价值的BPF手册,值得好好阅读。
- https://www.kernel.org/doc/html/latest/bpf/bpf_devel_QA.html,开发BPF必读Q&A,里面是维护BPF内核代码的大佬给出的代码开发建议,读了能明白社区是如何运作BPF的。
学习技术还是得从源代码开始:
- https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf.git/,这个repo是Linux社区官方维护的独立BPF代码仓库,一旦发布新版本后,代码就不会大改,只接受bug fix,相当于master repo,最终会merge到Linux内核代码主干中。
- https://git.kernel.org/pub/scm/linux/kernel/git/bpf/bpf-next.git/,这个repo也是Linux社区官方维护的BPF代码仓库,更新频繁,用于引入新功能或现有功能优化,稳定后merge到上面的master repo,相当于feature repo。
看到最近的commits里,不乏有国人的贡献,感兴趣的话,来参与吧~
学习技术也需要沟通交流:
- https://cilium.slack.com/archives/C4XCTGYEM,为Cilium提供的关于eBPF的thread,有什么疑问都可以去问
- https://github.com/DavadDi/bpf_study,狄卫华老师的收集的BPF文章和教程,有问题可以去提issue
- https://github.com/nevermosby/linux-bpf-learning,本人编写的BPF教程,欢迎来提issue和PR
BPF大神们:
- Brendan Gregg,来自Netflix最强BPF布道师,他的博客都是关于Linux系统优化的,观点独到,每一篇都值得一读;
- Alexei Starovoitov,eBPF创造者,目前在Facebook就职,经常能在内核代码commit中看到他的踪迹;
- Daniel Borkmann,eBPF kernel co-maintainer,目前在Cilium所在的公司Isovalent就职,是给eBPF增加feature的能力者;
- Thomas Graf,Cilium之父,Isovalent的CTO,他也是eBPF和Cilium的强力布道师,能说会道,各种大会上都有他的风采;
- Quentin Monnet,BPFTool co-maintainer,Quentin是在stackoverflow上bpf问题的killer,Twitter有关于eBPF的系列实战短文,值得细品。
BPF书籍:
- 《Linux Observability with BPF》,作者David Calavera和Lorenzo Fontana, 这本书篇幅不长,是来自sysdig的两位大佬写的BPF手册书,推荐入门阅读
- 《Linux内核观测技术BPF》,是最近刚出版的第一本BPF中文书籍,为上面英文书的翻译版本,由范彬和狄卫华两位翻译
- 《BPF Performance Tools》,这是Brendan Gregg大神对于BPF技术如何做系统性能优化的一本集大成者的秘籍,BPF学习者必备。
- 《Systems Performance: Enterprise and the Cloud, 2nd Edition》,这是Brendan Gregg大神系统优化书籍的第二版,篇幅较长,但是值得一啃。
另外建议大家可以跟踪各种大会上的eBPF技术分享。
最开始提到的最近两年的KubeCon上的eBPF相关Session。
下面是最新的几个session详细链接:
- 绕过conntrack,使用eBPF增强 IPVS优化k8s网络性能:https://v.qq.com/x/page/s3137ehoq8i.html
- 深入了解服务网格数据平面性能和调优:https://v.qq.com/x/page/v3137ax6zss.html
- Kubernetes中用于混沌与跟踪的BPF:https://v.qq.com/x/page/f3130lpe0iv.html
- https://kccnceu20.sched.com/event/ZejN/tutorial-using-bpf-in-cloud-native-environments-alban-crequy-marga-manterola-kinvolk
- https://kccnceu20.sched.com/event/Zeoz/hubble-ebpf-based-observability-for-kubernetes-sebastian-wicki-isovalent
- https://kccnceu20.sched.com/event/Zexb/designing-a-grpc-interface-for-kernel-tracing-with-ebpf-leonardo-di-donato-sysdig
- https://kccnceu20.sched.com/event/ZemQ/ebpf-and-kubernetes-little-helper-minions-for-scaling-microservices-daniel-borkmann-cilium
- https://kccnceu20.sched.com/event/Zewd/intro-to-falco-intrusion-detection-for-containers-shane-lawrence-shopify
- https://kccnceu20.sched.com/event/ZetL/seccomp-security-profiles-and-you-a-practical-guide-duffie-cooley-vmware
- https://kccnceu20.sched.com/event/ZeqL/k8s-in-the-datacenter-integrating-with-preexisting-bare-metal-environments-max-stritzinger-bloomberg
LPC 2020 Networking and BPF Summit,这个会一周前刚结束,可以说是BPF技术的专题会,上面有非常多的eBPF实践案例以及未来可能增加的功能列表,比如BPF Map是否能resize,而不是一上来就定义好大小。
罗列下使用BPF技术的项目:
- Tcpdump
- BCC,BPFTrace,kubectl-trace from IOVisor
- Cilium from Isovalent
- Falco from Sysdig
- Katran from Facebook
- Bottlerocket from Amazon
中文社区有:
- 腾讯云IPVS-BPF K8S网络优化方案
- Kernel Chaos With BPF by PingCAP
- 网易轻舟做系统检测和网络优化
- 字节跳动做高性能网络ACL管理
更多IT公司都在尝试使用BPF技术到各个领域中。
我是如何学习BPF技术的
先来说说我和BPF的缘起。我第一次接触BPF技术是在今年年初,看到了介绍Cilium这款Kubernetes网络插件的视频,它能通过BPF程序实现了所有Kube-proxy功能,而且把请求转发效率提升了近50%,觉得非常不可思议,然后就决定深入了解下BPF这项超能力技术。
整个学习过程,总的来说我是先看了很多英文文章,因为当时中文社区关于BPF技术的文章非常少,然后设计编写自己的BPF程序,希望把它跑起来并获得预期的结果,期间会有很多问题发生,就会不停地去调试代码,最终通过写博客,把每次有目的的学习过程和成果,记录总结并分享出来。
其中要给大家重点说的就是学习之初要做计划。
做计划对大多数人来说,是获得成功结果的必要条件,而做计划的过程是我认为就是全盘思考的过程。当然计划不是一成不变的,以你自己的学习节奏和输出效率,可以在过程中按需进行适当调整。
下图是我刚开始制定的BPF学习计划:

第一阶段主要是学习和翻译经典英文材料,跟“多读书,读好书”道理一样,翻译材料也是这样,首选要去优秀的社区,然后去选优质的材料,通过逐句逐句地翻译,就能理解这项技术的方方面面。这个过程有点像读文档翻译文档,但是比看文档有趣多了,因为这种优质的材料里一般都会有精彩的故事,让你知道技术的诞生和发展其背后真正的驱动力。
BPF的优秀社区是哪家?我选择了上面提到的LWN.net社区,最早全称为Linux Weekly News。现在内容已经不单单是Linux了,涉足广泛。很多资深IT圈人士都会给LWN供稿,内容详实有深度,值得反复阅读。
而在选取材料时,由于不同阶段的阅读目标不同,初级阶段建议选择没有太多技术细节的,能讲明白BPF技术是什么?解决什么问题?以及发展历程,就可以作为候选。
完成了第一阶段,就会对这项技术的背景和术语有了初步的认识,接下来就是选取一个兴趣点作为切入口,深入了解这项技术的使用场景和工作原理,也就是第二阶段——动手实践。
我自己对使用BPF进行网络优化这个领域很感兴趣,因此它变成了我动手学习的切入口。下面是我的第一个网络层面的XDP BPF程序:

目的非常简单,就是所有经过XDP钩子的网络数据包,全部drop掉,也就是形成了“丢包”的结果,这就是业界最出名的一个XDP BPF应用场景的雏形——Facebook基于XDP实现高效的防DDoS攻击,其本质上就是实现尽可能早地实现「丢包」,而不去消耗系统资源创建完整的网络栈链路,即「early drop」。
像上面这样,通过准备动手实验环境,写代码,调试代码,这一步步的过程中一定会出现预料之外的问题,不用怕,要有耐心去啃,虽然耗时会可能会非常长,但要有不达目的不罢休的毅力。
我的自己的一个经历,就是在调试TC BPF程序时,发现结果总是不符合预期,然后就不停地调试代码,同时也对用来调试的BPF辅助函数bpf_trace_printk进行了深入地研究(链接是我当初整理的关于这个函数的思维导图:https://github.com/nevermosby/linux-bpf-learning/blob/master/bpf/bpf_trace_printk_definition.pdf),从而了解到了BPF底层实现,包括它是由11个64位寄存器、1个计数器和1个512字节BPF stack组成。寄存器命名规则是r0-r10,每个寄存器都有专属的作用:
- r0保存了调用一次辅助函数后的返回值
- r1 – r5 保存了从BPF程序到辅助函数的参数列表
- r6 – r9 是用来保存中间值的寄存器,它可以被多个辅助函数调用
- r10 是唯一的只读寄存器,包含访问BPF stack的指针
上面这些都是你不罢休的成果,要相信由付出必有回报。
第三阶段,就是我现在正在做的事情,总结和分享。成功的实践一定会让你有输出的欲望,我选择博客作为我的输出渠道,当然大家也可以去选择其他的渠道。对我而言,通过文字和图片把一件事情娓娓道道是个很舒服的方式。而把这些内容再分享出去,让更多的人了解这项技术并获得收获,会令你自己感到快乐,这就是分享的意义。
再分享一点关于如何阅读理解代码的TIPS:
- 在线阅读Linux内核代码的好去处:https://elixir.bootlin.com/linux/v5.8.7/source
- 快速定位函数的定义和引用
- 下载Linux内核代码,编译运行BPF示例程序
- 参见博文: https://davidlovezoe.club/compile-bpf-examples
- 根据示例程序,写自己的BPF程序,并跑起来
学习BPF给我带来的收获
- 能够静下心来看Linux内核代码,这件事听起来简单,做起来不易,因为有了学习兴趣有学习目标,我开始习惯于阅读那些看起来冗长晦涩的代码
- 理解Linux系统调用、文件系统等功能模块的工作原理,正式由于能静下心来读代码,所以那些原本认为这辈子都看不懂的东西,竟然慢慢变得清晰起来
- 写文章可以锻炼很多其他软技能,比如画图,录视频,做视频等等,写技术博客就是这么一件痛并快乐着的事情
如果对BPF技术感兴趣想深入了解的,可以关注我博客的BPF系列文章:https://davidlovezoe.club/wordpress/archives/tag/bpf以及GitHub上配套的BPF源码repo:https://github.com/nevermosby/linux-bpf-learning/。
Q&A
Q:真正使用BPF,或者想了解透彻,是否一定要看源码?
A :我的建议是要看源代码,不一定要每句都理解,但是要知道其基本工作原理。是精读还是泛读,可以根据你的使用需求来。
Q:部署Cilium后,能否回退回Calico或者其他插件?
A:当然可以,通过kubectl delete -f [你用来部署cilium的yaml],是可以删除所有的Cilium相关资源的,不会影响其他CNI插件的部署。
Q:Cilium距离应用生产环境还存在什么问题?
A:个人觉得还是内核版本的要求比较高,Cilium官方推荐是使用内核5.XX以上的系统来部署,但是绝大多数企业可能都停留在3.XX或4.XX。
Q:看不懂代码,只是需要排查定位故障,有什么资料学习分享?
A :https://cilium.readthedocs.io/en/stable/bpf/,Cilium提供的BPF文档,是我看到过的最具实战价值的BPF手册,有基本原理的介绍和命令行BPFTool工具的使用方法。
Q:eBPF现在是alpha版本吗,以后内核升级的话,eBPF的API会有大的变动吗?另外是从那个内核版本引进的eBPF呢?BPF是不是比eBPF缺少很多接口?
A:eBPF是2014年诞生的,Linux内核是在3.15之后引入eBPF的,目前已经非常成熟,很多国外IT企业都是生产使用的,包括Facebook、Netflix、Google。Google最近把的GKE平台升级成默认使用eBPF模式的Cilium网络方案了。内核升级不会影响eBPF的API,本质上说eBPF没有所谓的对外API接口,它对外暴露的是各种钩子hook,用来插入用C语言或其他语言写的eBPF程序编译后的字节码文件。现在老的BPF(也就是cBPF)已经基本废弃了,开发者面向的都是具有eBPF的Linux环境。
Q:是否改变预设BPF Map的大小讨论的意义是什么,是基于不同操作系统的应用以及场景的问题吗?
A :当前情况是声明创建一个BPF Map是固定大小的,往里面存数据是动态的。有些应用场景的需求,希望可以动态地扩容BPF Map大小,这样比再声明一个更大的BPF Map更高效。
Q:文中提到BPF map在BPF程序运行完毕后还可以独立存在,那比如我卸掉Cilium之后这个map要如何回收?
A:BPF map持久化是通过挂载到磁盘上,Cilium官方的做法是mount bpffs/sys/fs/bpf -t bpf,就像删除文件一样,删除这个目录下的文件即可。
Q:请问下,kubectl-trace对OS系统版本(内核版本),Kubenetes的版本之类有要求吗?
A :有的,因为它会运行eBPF程序到你的目标节点上,所以节点OS内核版本肯定是要支持eBPF的,推荐是5.XX以上。需要的Kubenetes版本官方倒是没有提及,我这边v1.16和v.17试过都可以。