快速使用Spring Cache
哈喽~大家好,这篇我们来看看快速使用Spring Cache。
个人主页:个人主页
系列专栏:【日常学习上的分享】
与这篇相关的文章:
Redis快速入门及在Java中使用Redis Redis快速入门及在Java中使用Redis_程序猿追的博客-CSDN博客 为什么不推荐使用Lombok?@Data不香吗? 为什么不推荐使用Lombok?@Data不香吗?-CSDN博客 Mybatis报错: Parameter ‘XXX‘ not found. Available parameters are [arg1, arg0, param1, param2]解决方案及问题原因 Mybatis报错: Parameter ‘XXX‘ not found. Available parameters are [arg1, arg0, param1, param2]解决方案及问题原因-CSDN博客
一、前言
在前一篇提到了Redis快速入门并且在Java中使用Redis,但是呢代码感觉还是有点长,先是redisTemplate.opsForValue().set("K","V");然后redisTemplate.opsForValue().get("K"); 这样太麻烦了,而且显得太繁琐了,有没有一种方法可以快速设置缓存数据?
二、Spring Cache
缓存数据使用了一个新的框架——Spring Cache,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,例如:EHCache、Caffeine、Redis(常用)。
1、起步依赖
在pom文件导入下面依赖
org.springframework.boot
spring-boot-starter-cache
2.7.3
2、常见注解
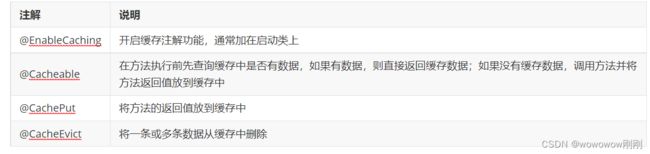
在spring boot项目中,使用缓存技术只需在项目中导入相关缓存技术的依赖包,并在启动类上使用@EnableCaching开启缓存支持即可。
例如,使用Redis作为缓存技术,只需要导入Spring data Redis的maven坐标即可。
3、入门案例
首先,使用Spring Cache要在引导类上加@EnableCaching。
@Slf4j
@SpringBootApplication
@EnableCaching
@EnableTransactionManagement //开启注解方式的事务管理
public class CacheDemoApplication {
public static void main(String[] args) {
SpringApplication.run(CacheDemoApplication.class,args);
log.info("项目启动成功...");
}
}
3.1、@CachePut注解
@CachePut 说明:
作用: 将方法返回值,放入缓存
value: 缓存的名称, 每个缓存名称下面可以有很多key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
在save方法上加注解@CachePut
当前UserController的save方法是用来保存用户信息的,我们希望在该用户信息保存到数据库的同时,也往缓存中缓存一份数据,我们可以在save方法上加上注解 @CachePut,用法如下:
/**
* CachePut:将方法返回值放入缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@PostMapping
@CachePut(value = "userCache", key = "#user.id")//key的生成:userCache::1
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}说明:#user.id这是spel表达式,如果使用spring cache 缓存数据,key的生成:userCache::key的值。
key的写法有很多,如下
#user.id : #user指的是方法形参的名称, id指的是user的id属性 , 也就是使用user的id属性作为key ;
#result.id : #result代表方法返回值,该表达式 代表以返回对象的id属性作为key ;
#p0.id:#p0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
#a0.id:#a0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
#root.args[0].id:#root.args[0]指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key ;
不过常用的还是#user.id,具体更多的用法可以见源码。
3.2、@Cacheable注解
作用: 在方法执行前,spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
value: 缓存的名称,每个缓存名称下面可以有多个key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法。
在getById上加注解@Cacheable
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据, *调用方法并将方法返回值放到缓存中
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@GetMapping
@Cacheable(cacheNames = "userCache",key="#id")
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}3.3、@CacheEvict注解
@CacheEvict 说明:
作用: 清理指定缓存
value: 缓存的名称,每个缓存名称下面可以有多个key
key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
@DeleteMapping
@CacheEvict(cacheNames = "userCache",key = "#id")//删除某个key对应的缓存数据
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache",allEntries = true)//删除userCache下所有的缓存数据
public void deleteAll(){
userMapper.deleteAll();
}更多效果可以见原项目源代码。
三、图书推荐
1、内容简介
本书从分布式系统的基础概念讲起,逐步深入分布式系统中间件Spring Cloud Alibaba进阶实战,重点介绍了使用Spring Cloud Alibaba框架整合各种分布式组件的完整过程,让读者不但可以系统地学习分布式中间件的相关知识, 而且还能对业务逻辑的分析思路、实际应用开发有更为深入的理解。
全书共分5大章节,第1章开篇部分,讲解分布式系统的演进过程和Spring Cloud Alibaba概述及版本的选择,以及单体架构/微服务架构的优缺点;第2章讲解如何使用Spring Cloud Alibaba实现RPC通讯;第3章在介绍主流Nacos组件时,介绍了三元的概念以及使用Nacos实现注册中心和配置中心,包含环境的动态切换、配置的动态刷新、通用型配置、版本回滚等核心技术,为微服务环境提供基础的架构;第4章介绍了负责限流和熔断降级的Sentinel组件,包含收集系统运行状态、流量控制、熔断降级、热点、授权、系统规则、流控的异常处理、熔断的异常处理、规则持久化等;第4章介绍了网关常用案例,以及在软件项目中常用的高频使用技术点,力求为开发微服务项目的程序员提供一个快速学习的书籍。

购买链接