hive详解
什么是 Hive
1) hive 简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并
提供类 SQL 查询功能
2) Hive 本质:将 HQL 转化成 MapReduce 程序

(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
1.2Hive 的优缺点
1.2.1 优点
(1)操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
(2)避免了去写 MapReduce,减少开发人员的学习成本。
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
1.Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却 无法实现。
1.3 Hive 架构原理

2)元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、 表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
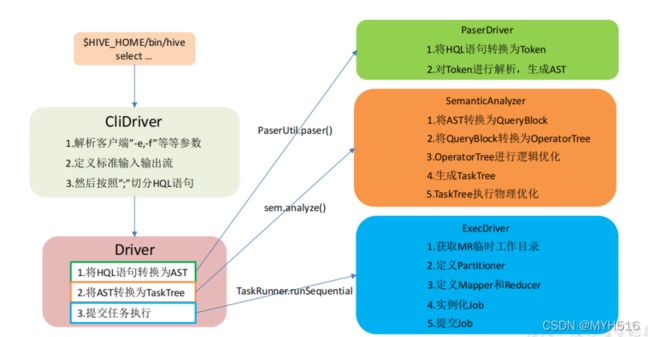
4)驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第 三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来 说,就是 MR/Spark。

Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver, 结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将 执行返回的结果输出到用户交互接口。
内部表和外部表
元数据、原始数据
1删除数据时: 内部表:元数据、原始数据,全删除
外部表:元数据 只删除
2生产环境下,什么时候创建内部表,什么时候创建外部表?
绝大多数场景都是外部表。 自己使用的临时表,才会创建内部表
内部表
与数据库中的table在概念上是类似的
每一个table在hive中都有一个对应的目录存储数据
所有的table数据(不包括 external table ) 都保存在这个目录中
删除表时 元数据和数据都会被删除
外部表
指向已经在HDFS中存在的数据 可以创建 Partition
它和内部表在元数据的组织上相同的 而实际数据的存储有较大差异
外部表只有一个过程 加载数据和创建表同时完成 并不会移动到数据库目录中
只有与外部数据建立一个连接 当删除一个外部表时 仅删除一个连接和元数据
4 个 By 区别
1)Order By:全局排序,只有一个 Reducer;
hive中的order by跟传统的sql语言中的order by 作用是一样的,会对查询结果做一次全局排序
所以说 只有hive的sql中制定了对order所有数据都会到同一个reducer进行处理
(不管有多少map 也不管文件有多少的block 只会启动一reducer) 但是对于大量数据这将会消耗
很长时间执行 这里跟传统的sql有一点区别 :如果指定了hive.mapred.mode=strict (默认是nonstrict) 这时就必须指定limit 来限制输出条数 原因是所有的数据 都会在同一个reducer端进行 数据量大的情况下 可能不能出结果, 那么在这样的严格模式下 必须输出指定的条数
2)Sort By:分区内有序;
hive中指定了sort by 那么在每个reducer端都会做排序 也就是说保证了局部有序 (每个reducer 出来的数据都是有序的 但是不能保证所有的数据都是有序的 除非只有一个reducer) 好处是:执行了局部排序之后可以为接下去的全局排序提高不少效率(其实就是做一次归并排序就可以做到全局排序了)
3)Distrbute By:类似 MR 中 Partition,进行分区,结合 sort by 使用。
Distribute by和sort by 一起用,distribute by 是控制map的输出在reducer 是如何划分的 举个例子 我们有张表 mid指这个store所属的商户,money是这个商户的盈利,name 是这个 store的名字 执行hive语句,select mid ,money,name from store distribute by mid sort by mid asc,money asc. 我们所有的mid相同的数据会被传送到同一个reducer去处理,这就是因为指定了distribute by mid 这样的话就可以统计出每个商户中各个商店的盈利的排序(这个肯定是全局有序的,因为相同的商户会放到同一个reducer去处理),这里需要注意的是distribute by 必须要写在sort by 之前
4)Cluster By:当 Distribute by 和 Sorts by 字段相同时,可以使用 Cluster by 方式。Cluster by 除了具有 Distribute by 的功能外还兼具 Sort by 的功能。
Cluster by 的功能是 dirtribute by和sort by相结合,如下两个语句是等价的 select mid,money,name from store cluster by mid
Select mid,money,name from store distribute by mid sort by mid
但是cluster by 指定的列只能是降序的 不能指定ASC,DESC
在生产环境中 Order By 用的比较少,容易导致 OOM。
在生产环境中 Sort By+ Distrbute By 用的多。
企业级调优
1执行计划 explain
2fetch抓取
hive-default.xml.tmplate文件中hive.fetch.task.conversion默认more 老版本默认minimal
改成more
全局查找,字段查找,limit 查找不走mr
3本地模式
不走yarn调度 数量少 跟运行环境有关 提交给本地 or yarn
4表优化
大小表 join mapjoin
小表缓存到内存 慢慢加载大表数据 在map里面找小表对应的数据 小表放左 大表放右 内部已经做了优化.
开启 MapJoin 参数设置
set hive.auto.convert.join = true; 默认为 true

大表 Join 大表


相对均衡 (数据倾斜情况下 真实生产环境很有可能导致出不来结果! 倾斜的那个)