中国智能产业高峰论坛:文档大模型与文档图像智能理解的进展和思考
-
- ✓ 写在前面
- ✓ 文档大模型的思考与探索
- ✓ 文档图像大模型的进展
- ✓ 多模态大模型与文档图像智能理解
-
-
- 多模态大模型的应用和发展
- 文档图像智能理解的技术和挑战
- 产业应用和前景展望
-
✓ 写在前面
2023 年第十二届中国智能产业高峰论坛(CIIS 2023)于 9 月 17-18 日在江西南昌举行。该论坛聚焦于大模型、生成式AI、无界智能等方向,近 200 名政府领导、专家学者参会,共同探讨如何推动智能产业发展。
在今年的论坛中,与会专家学者和企业代表就 AI 大模型、生成式AI、无人系统、智能制造、数字安全等领域的前沿技术和产业应用进行了深入探讨。同时,来自多个学术机构的院士和专家学者还进行了主题报告演讲和专题论坛研讨,分享了各自的研究成果和实践经验,探讨了智能科技领域的未来发展趋势和创新应用。
作为一名对前沿科技深感兴趣的技术博主,很遗憾我没能有机会去现场学习各位专家老师的演讲,但我全程参与了 CIIS 的线上直播。尤其关注了中国智能产业高峰论坛中的多模态大模型与文档图像智能理解专题论坛。其中合合信息的丁凯博士演讲介绍的《文档图像预训练模型的探索与思考》感受颇多,作为行业领先的人工智能及大数据科技企业,合合信息致力于通过智能文字识别及商业大数据领域的核心技术、C 端和 B 端产品以及行业解决方案为全球企业和个人用户提供创新的数字化、智能化服务。是聚焦于文档图像领域的一家企业,像“名片全能王”、“扫描全能王”这些著名 APP 都是合合信息的产品,全球累计用户下载已超 23 亿。

✓ 文档大模型的思考与探索
文档图像领域发展其实已经有将近一百年的历史,时间虽长但仍有大量的问题亟待解决。最明显就是的文档或者图像在被扫描后出现的质量退化问题,通常情况下一个清晰的文档或者图像在使用手机等设备扫描后,就会难免的出现看不清、模糊等问题。此外当文档上的文字排版复杂或者字迹潦草时,我们的图像扫描技术还能否完美的复现文档?这是图像处理技术一个极大挑战。

针对以上这些难题,合合信息分别从几个主题进行了智能文档处理的研究。
首先是 文档图像分析与预处理,它主要解决的是文档质量的问题,通过切边增强、去摩尔纹、弯曲矫正、图片压缩、PS 检测等技术来处理扫描得到的图像,增强图像整体质量,使得用户体验更佳。其次是 文档解析与识别,通过文字识别、表格识别、电子档解析等获取到图片当中的信息。此外还有 版面分析与还原、文档信息抽取与理解、AI 安全、知识化&存储检索和管理 这一整套逻辑实现文档的智能化处理。
看到这里可能有人会问:说了这么多都在讲文档图像处理,这跟大模型有什么关系呢?这两者表面上看貌似真的没有什么关系。但是文档图像处理技术是在处理文字、大模型其实也是在处理文字,从这个层面来看这两者又好像算是“同宗一脉”。众所周知,语言大模型是需要基于大量的语言数据进行预训练的,据一些机构预测,到 2026 年可以供大模型训练的语料数据将会被耗尽。可以说当前我们在网上使用的语料数据基本上被大模型挖掘的差不多了。
基于这样的状况,很多大模型厂商开始致力于寻找新的未被大模型挖掘的“语料数据基地”。于是电子文档(电子书)成为了一个理想的语料数据宝藏。电子书中的绝大部分内容又都是来源于文档扫描所生成。这也就造就了大模型领域与图形图像领域的一层联系:为了更加充分的训练大模型,将会有大量的文档和图像待扫描后录入成为电子文档。此外大模型的语言理解能力、学习能力、推理能力等对于图形图像处理的研究也是至关重要的,一方面二者可以深度融合,另一方面大模型也会为图形图像领域带来更多的研究课题。
文档图像也会是 ChatGpt 特别关注的一个点。我们看下面这个案例:这是使用 GPT-4 做题的一个过程。给它一张图像,里面有文字、公式、图表,GPT 不仅需要先认识文档中的文字内容,更需要去理解。

而这个认识的过程又是基于图像扫描的。不仅是 ChatGPT,国内的文心一言等语言模型也已经支持的图像的识别。
✓ 文档图像大模型的进展
在文档图像专有大模型这一块,具有代表意义的就是微软(Microsoft)的 LayoutLM 系列,它是一个多模态预训练模型,包括 LayoutLM、LayoutLMv2 和 LayoutLMv3,基于多模态 Transformer Encoder 的预训练和下游任务微调,能够实现布局信息与文本信息的联合学习,用于表单类数据预训练,可提高相关类型数据识别的准确率。
合合信息与华南理工大学正在研究视觉模型与大语言模型解耦联合建模的多模态信息抽取新框架,它的核心特征是在多语言的小样本和零样本上性能是非常好的,这也是文档图像专有大模型领域的代表作。
在今年(2023)微软又推出了新的文档处理大一统模型 UDOP,与以往的预训练模型相比,UDOP 的不同之处在于它是一个端到端模型。将文档输入以后,模型会将文字、版面与图像信息进行统一的编码,然后进行分离解码。该模型采用了统一的 Vision-Text-Layout 编码器、分离的 Text-Layouot 和 Vision 解码器。
以上这些模型都是需要依赖于 OCR 引擎的,这样的模式有一个明显的缺陷就是容易积累误差。
OCR(Optical Character Recognition,光学字符识别)是一种将印刷或手写文本转换为计算机可编辑和存储格式的技术,通过利用图像处理和模式识别算法,将图像中的文本字符提取出来,并将其转换为计算机可识别的数字形式。
所以无需 OCR 的用于文档理解的 Transformer 模型 Donut 应运而生,它只需要将文字和图像输入到模型中,然后描述我们需要它做的事情,最后基于编码器解码器输出我们想要的内容。
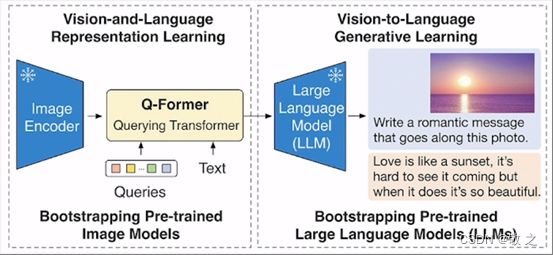
还有多模态大模型 BLIP2,使用 Q-Former 连接预训练的图像编码器 (ViT) 和 LLM 解码器(OPT,FlanT5等),通过 Image Encoder 将图像进行编码,然后使用 Q-Former 将图像模态和融合模态进行对齐,最后再对接一个大模型。这样的工作机制不仅能很好的进行图像识别,还可以很好的利用大语言模型的理解能力。
此外还有谷歌的 Flamingo,在 LLM 中增加 Gated Attention 层引入视觉信息;微软的 LLaVA,将 CLIP ViT-L 和 LLaMA 采用全连接层连接,使用 GPT-4 和 Self-Instructl2 生成高质量的 158kinstruction following 数据;还有 MiniGPT-4,视觉部分采用 ViT+Q-Former,语言模型部分采用 Vicuna,视觉和语言模块间采用全连接层衔接。
这些模型一方面很好的利用了视觉信息,另一方面也充分的利用了大语言模型本身的特性。这样的技术研究,无论对于图像图像领域还是大语言模型领域都是意义重大的。
✓ 多模态大模型与文档图像智能理解
在多模态大模型与文档图像智能理解论坛中,各位专家都也都提出了自己的见解:
多模态大模型的应用和发展
多模态大模型是指结合了多种数据模态(如文本、图像、音频等)的大型深度学习模型。与传统的单模态模型相比,多模态大模型具有更强的表征能力和泛化性能,能够更好地理解和处理复杂的多模态数据。
与会专家认为,多模态大模型的应用前景广泛,可以应用于智能客服、智能问答、智能推荐等多个领域。同时,多模态大模型的训练和推理也需要更高的计算资源和算法优化技术,需要进一步加强研究和探索。
文档图像智能理解的技术和挑战
文档图像智能理解是指利用计算机视觉和深度学习等技术,对文档图像进行自动化阅读、理解和分析的过程。随着应用场景的不断扩大,文档图像智能理解技术也面临着更多的挑战和难点。
与会专家探讨了文档图像智能理解的最新技术和应用,包括文档图像分类、文字识别、表格识别、版面分析等多个方面。同时,专家也指出了文档图像智能理解面临的挑战和难点,如文字识别精度、版面分析的稳定性、以及如何处理复杂文档格式等问题。
产业应用和前景展望
与会企业代表分享了多模态大模型和文档图像智能理解在产业中的应用案例和实践经验。其中,涉及到智能客服、智能推荐、智能风控等多个领域的应用案例。同时,与会专家和企业代表也探讨了未来的技术发展趋势和产业前景,认为多模态大模型和文档图像智能理解将会成为未来智能化发展的重要方向。