【数据结构】插入排序:直接插入排序、折半插入排序、希尔排序的学习知识总结
目录
1、排序的基本概念
2、直接插入排序
2.1 算法思想
2.2 代码实现
3、折半插入排序
3.1 算法思想
3.2 代码实现
4、希尔排序
4.1 算法思想
4..2 代码实现
1、排序的基本概念
排序是将一组数据按照预定的顺序排列的过程,排序的基本概念包括以下内容:
-
关键字:排序时按照哪个字段进行排序,该字段称为关键字。
-
排序规则:排序时按照升序或降序的方式排列。升序表示从小到大排列,降序表示从大到小排列。
-
稳定性:排序算法如果经过排序后,具有相同关键字的元素,排序前后的相对顺序是否保持不变。如果保持不变,该排序算法就是稳定的。
-
时间复杂度:排序算法进行排序所需要的时间复杂度。
-
空间复杂度:排序算法进行排序所需要的额外空间复杂度,即算法需要占用的额外内存大小。
2、直接插入排序
2.1 算法思想
直接插入排序算法的思想是将待排序的元素插入到已经排好序的元素序列中,从而得到一个新的、更大的有序序列。
具体来说,算法从第二个元素开始遍历待排序序列,将当前元素插入到已经排好的元素序列中的正确位置上,使得插入后仍然保持有序。因为初始时已经有一个元素的有序序列,所以排序过程中每次插入的元素都将比已经排好序的元素序列中的元素小,因此不会影响已经排好序的元素序列的有序性。当遍历完整个序列,待排序序列就被完全插入到已经排好序的元素序列中,排序完成。
直接插入排序的时间复杂度为O(n^2),空间复杂度为O(1)。虽然时间复杂度较高,但是对于小规模数据的排序效率较高,并且具有稳定性。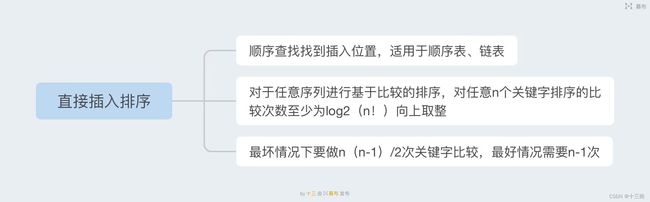
2.2 代码实现
以下是C语言编写的直接插入排序并计数比较次数的程序:
#include
#define MAXSIZE 100
void InsertionSort(int A[], int n, int *cnt) {
int i, j, temp;
for(i = 1; i < n; i++) {
temp = A[i];
for(j = i - 1; j >= 0; j--) {
(*cnt)++;
if(A[j] > temp)
A[j + 1] = A[j];
else
break;
}
A[j + 1] = temp;
}
}
int main() {
int A[MAXSIZE];
int n, cnt = 0;
printf("请输入待排序数列元素个数(不超过%d):", MAXSIZE);
scanf("%d", &n);
printf("请输入待排序数列:");
for(int i = 0; i < n; i++)
scanf("%d", &A[i]);
InsertionSort(A, n, &cnt);
printf("排序后结果:");
for(int i = 0; i < n; i++)
printf("%d ", A[i]);
printf("\n比较次数:%d\n", cnt);
return 0;
}
程序中的 InsertionSort 函数实现了直接插入排序,并使用指针形参 cnt 对比较次数进行计数。主函数中首先输入待排序数列元素个数和数列元素,然后调用 InsertionSort 函数进行排序,并输出排序后的结果和比较次数。
下面是C语言在链式存储结构上设计直接插入排序算法的示例代码:
typedef struct Node {
int data;
struct Node *next;
}Node;
void insertSort(Node **head) {
if (*head == NULL || (*head)->next == NULL) {
return;
}
Node *p = (*head)->next;
(*head)->next = NULL; // 设置新的有序链表头节点
while (p != NULL) {
Node *q = p->next;
Node *prev = NULL;
Node *cur = *head;
while (cur != NULL && cur->data < p->data) {
prev = cur;
cur = cur->next;
}
if (prev == NULL) { // 插入到头节点之前
p->next = *head;
*head = p;
} else { // 插入到prev和cur之间
prev->next = p;
p->next = cur;
}
p = q;
}
}
此代码首先对链表的头节点进行判断,若链表为空或只有一个节点则不需要排序。然后指针p指向头节点的后继节点,将头节点的后继节点设为空,新的有序链表头节点为原链表的头节点。接下来,对p的每个节点进行插入排序操作,找到p应该插入的位置并插入。最后返回排好序的链表头节点。
3、折半插入排序
3.1 算法思想
折半插入排序算法是插入排序算法的一种变种。它的基本思想是将待排序的序列分成两部分,前半部分为已排序好的部分,后半部分为未排序的部分。排序过程中,每次从未排序的部分中选出一个元素,通过折半查找的方式,找到它应该插入到已排序的部分中的哪个位置,然后再将的元素插入到已排序的部分中。
具体实现步骤如下:
1. 将待排序序列的第一个元素作为已排序的部分,剩下的元素作为未排序的部分。
2. 从未排序的部分中选出一个元素,通过二分查找找到它应该插入到已排序的部分中的位置。
3. 将该元素插入到已排序的部分中,同时将已排序的部分的长度增加1,未排序的部分的长度减少1。
4. 重复步骤2和步骤3,直到未排序的部分为空。
折半插入排序算法相比于普通的插入排序算法,虽然查找的时间复杂度由O(n)降低为O(log n),但是这并不影响算法的总体时间复杂度,依然是O(n^2)。不过,在某些特定的场景下,折半插入排序算法的效率可能会比普通的插入排序算法更高。
3.2 代码实现
折半插入排序是插入排序的一种优化算法,它利用二分查找的思想来确定插入位置,从而减少比较和移动的次数,提高排序效率。
下面是C语言实现折半插入排序的示例代码:
void binary_insertion_sort(int arr[], int len) {
int i, j, left, right, mid, tmp;
for (i = 1; i < len; i++) {
tmp = arr[i];
left = 0;
right = i - 1;
// 找到插入位置
while (left <= right) {
mid = (left + right) / 2;
if (tmp < arr[mid]) {
right = mid - 1;
} else {
left = mid + 1;
}
}
// 移动元素
for (j = i - 1; j >= left; j--) {
arr[j + 1] = arr[j];
}
// 插入元素
arr[left] = tmp;
}
}
该算法的时间复杂度为O(nlogn),空间复杂度为O(1)。
4、希尔排序
4.1 算法思想
希尔排序算法是插入排序的一种改进算法,也称为缩小增量排序。希尔排序的基本思想是将待排序序列分割成若干个子序列,对每个子序列进行插入排序,然后不断减小步长,直到步长为1,完成排序。
具体实现时,先确定一个增量,在每个增量下将序列分成若干个小组,对每个小组进行插入排序。然后逐渐减小增量,重复上述操作,直到增量减小为1,再进行一次插入排序。不同的增量序列会影响希尔排序的效率,一般采用Hibbard增量序列或Sedgewick增量序列来提高排序效率。
希尔排序算法时间复杂度为O(nlogn)到O(n^2)之间,取决于增量序列的选择。在一般情况下,希尔排序具有较好的排序效率和稳定性,特别适用于数据量较大、无序性较强的序列。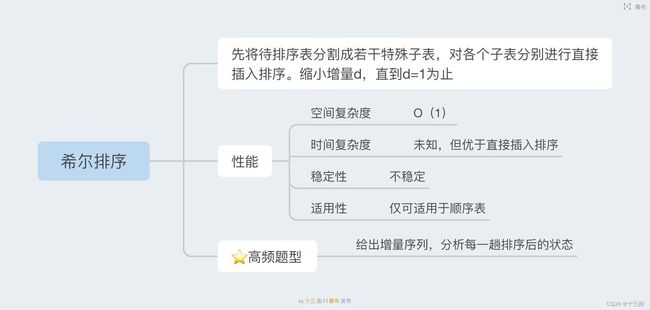
4..2 代码实现
下面是C语言实现希尔排序的代码:
void shell_sort(int arr[], int len)
{
int gap, i, j, temp;
for (gap = len / 2; gap > 0; gap /= 2) { // gap为步长,每次减半直到为1
for (i = gap; i < len; i++) {
temp = arr[i];
for (j = i - gap; j >= 0 && arr[j] > temp; j -= gap) {
arr[j + gap] = arr[j]; // 向后移动gap位
}
arr[j + gap] = temp; // 插入到正确位置
}
}
}
该代码首先将整个待排序序列分成若干个子序列,按照步长进行插入排序。然后逐渐缩小步长,直至为1,最后进行一次普通的插入排序,完成整个排序过程。