FPGA实现 TCP/IP 协议栈 纯VHDL代码编写 提供数据回环工程源码和技术支持
目录
- 1、前言
-
- 版本更新说明
- 免责声明
- 2、我这里已有的以太网方案
- 3、该TCP/IP协议栈性能
-
- 常规性能
- 支持多节点
- FPGA资源占用少
- 数据吞吐率高
- 低延时性能
- 4、TCP/IP 协议栈代码详解
-
- 代码架构
- 用户接口
- 代码模块级细讲
-
- 顶层模块
- PACKET_PARSING模块
- ARP模块
- IGMP_REPORT和IGMP_QUERY模块
- PING和WHOIS2模块
- ARP_CACHE2模块
- UDP_TX模块
- UDP_RX模块
- TCP_SERVER模块
- TCP_TX模块
- TCP_TXBUF模块
- TCP_RXBUFNDEMUX模块
- IP、MAC地址定义修改
- 5、详细设计方案
-
- PHY
- Tri Mode Ethernet MAC
- TCP数据回环
- 6、vivado工程1-->B50610 工程
- 7、vivado工程2-->RTL8211 工程
- 8、vivado工程3-->88E1518 工程
- 9、工程移植说明
-
- vivado版本不一致处理
- FPGA型号不一致处理
- 其他注意事项
- 10、上板调试验证并演示
-
- 准备工作
- ping测试
- TCP数据回环测试
- 传输速率测试
- 11、福利:工程代码的获取
1、前言
目前网上fpga实现udp协议的源码满天飞,我这里也有不少,但用FPGA纯源码实现TCP的项目却很少,能上板调试跑通的项目更是少之又少,甚至可以说是凤毛菱角,但很不巧,本人这儿就有一个;
本设采用纯VHDL实现了TCP/IP协议栈,该协议栈为TCP服务器,没有用到任何一个IP核,为了适应大批量数据传输和匹配不同型号FPGA的源语,RGMII转GMII部分调用了Xilinx的Tri Mode Ethernet MAC三速网IP,TCP/IP协议栈的MAC接口与Tri Mode Ethernet MAC实现了MAC层数据交互,TCP/IP协议栈用户接口分为UDP和TCP接口,这里只需要用到TCP接口,感兴趣的朋友可以试试UDP玩儿,将TCP的收发端口直接用assign语句连接起来形成数据回环,外部指定FPGA开发板的IP地址、MAC地址、端口号、目的IP地址、目的端口号等信息,即可完成TCP协议栈数据回环的工程搭建;
TCP/IP协议栈目前速率固定位千兆,MAC层数据接口为GMII,所以与phy对接的数据接口为RGMII,鉴于不同phy的时序略有不同,所以我在RTL8211、B50610、88E1518三款phy上做了测试,对应的也建了3套vivado工程,在电脑端使用网络调试助手进行TCP收发验证;
本设计可以配置为TCP的服务器,本设计经过反复大量测试稳定可靠,可在项目中直接移植使用,工程代码可综合编译上板调试,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于医疗、军工等行业的数字通信领域;
提供完整的、跑通的工程源码和技术支持;
工程源码和技术支持的获取方式放在了文章末尾,请耐心看到最后;
版本更新说明
此版本为第2版,根据读者的建议,对第1版工程做了如下改进和更新:
1:增加了工程移植的简单说明;
2:增加了Tri Mode Ethernet MAC IP核的使用、更新、修改等说明,以单独文档形式放在了资料包中;
3:增加了RTL8211、B50610、88E1518三款phy的原理图,已放在资料包中,如下:

免责声明
本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。。。
2、我这里已有的以太网方案
目前我这里有大量UDP协议的工程源码,包括UDP数据回环,视频传输,AD采集传输等,也有TCP协议的工程,对网络通信有需求的兄弟可以去看看:直接点击前往
3、该TCP/IP协议栈性能
常规性能
1:纯VHDL实现,没有用到任何一个IP核;
2:移植性天花板,该协议栈可在Xilinx、Altera、Lattice、国产FPGA等各大FPGA型号之间任意移植,因为是没有任何IP和源语的纯VHDL代码实现;但例如Tri Mode Ethernet MAC这样的PHY侧IP核目前用的Xilinx的;
3:功能齐全,包含了服务器和客户端,分为2套vivado工程源码;TCP/IP协议栈本身包含了动态ARP、NDP、PING、IGMP (for multicast UDP)、DHCP serve、DHCP client等功能模块;
4:代码符合标准的IEEE 802.3协议,支持IPv4和IPv6;
5:对外接PHY的数据格式要求:RGMII;
6:时序收敛很到位,考虑到TCP协议的复杂性和时序的高要求,所以没有采用时序收敛不强的verilog,而是VHDL,虽然阅读性可能会低一些,但用户只需要知道用户接口即可,并不需要去看内部的复杂代码;
7:动态ARP功能;
8:带ping功能;
9:支持多播;
支持多节点
支持节点数是TCP里面最重要的性能指标之一,这里需要重点讲述:
TCP节点数最大支持255个,通过parameter TCP_NUM参数设置,但前提是你的FPGA资源能满足;TCP_NUM参数可以在代码中自由修改,含义和用法,在代码里有详细的注释,为了防止不同编译器下中文注释出现乱码,注释均由英文书写,英语较差的兄弟可以直接某度翻译,位置如下:


本例程只用到了1个节点;
FPGA资源占用少
FPGA资源消耗是TCP里面最重要的性能指标之一,这里需要重点讲述:
FPGA资源消耗很低;以下举例:
以Xilinx旗下资源很小的Spartan-6平台为例,下只运行UDP时的资源消耗如下:
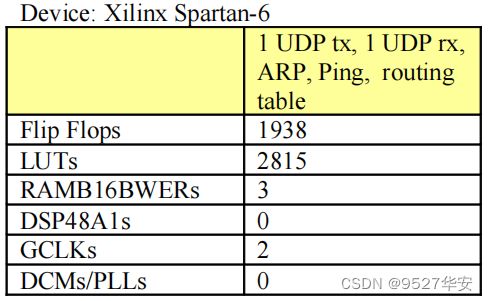
只运行1个TCP服务器时的资源消耗如下:

运行2个TCP服务器时的资源消耗如下:

数据吞吐率高
数据吞吐率是TCP里面最重要的性能指标之一,这里需要重点讲述:
下面给出4项测试结果,你可以自己对比评估以下:
测试1:
通过千兆以太网在TCP服务器和TCP客户端之间双向连接,FPGA参考时钟120 MHz条件下,测量的持续吞吐率为双向并发452 Mbits/s;
测试2:
Xilinx Spartan-6 -2速度等级,FPGA参考时钟120 MHz,512字节的UDP数据包通过局域网点对点发送下测得:
0丢包,吞吐率为878.5 Mbits/s;当用户时钟为125 MHz或以上时,UDP最大帧吞吐率为915 Mbits/s;
测试3:
TCP服务器传输吞吐量在1百兆局域网下PC端测量平均吞吐量为93 Mbps,如下;

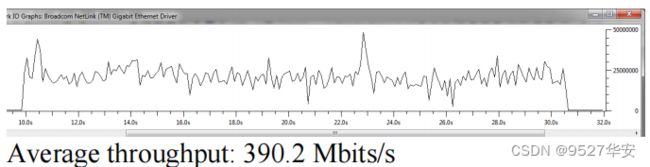
测试4:
TCP服务器将8Gbits发送到TCP Java客户端,同时Wireshark收集速度信息。从基于FPGA的TCP服务器到PC的点对点LAN连接平均吞吐率为390.2 Mbits/s;如下:
低延时性能
延时性能是TCP里面最重要的性能指标之一,这里需要重点讲述:
延时与TCP数据包长直接相关,如果你对延时性能性能要求很高,则可以减少包长来有效降低延时,假设你的载包为X bytes,那么你的收发延时关系如下:
发送延时=0.5 + 2X÷125 µs;
接收延时=0.5 + X÷125 µs;
最大帧长度为1460字节,FPGA 时钟125 MHz下的测试结果如下:
发送延时=23.9µs;
接收延时=12.2µs;
4、TCP/IP 协议栈代码详解
代码架构
TCP/IP 协议栈代码架构如下:

所有模块均由vhdl源码实现,没有使用任何IP,可以移植到任何平台的FPGA上;模块的具体细节在后续章节讲述;用户接口顶层代码如下:
纯VHDL实现,没有用到任何一个IP核,用户只需要知道用户接口即可,并不需要去看内部的复杂代码;用户接口及其注释如下:
module network_top #(
parameter TCP_NUM = 1
)(
input sys_rst ,
input clk_125 ,
input clk_200 ,
output phy_rst_n ,
output gtx_resetn ,
output [3: 0] rgmii_txd , // RGMII Interface
output rgmii_tx_ctl , // RGMII Interface
output rgmii_txc , // RGMII Interface
input [3: 0] rgmii_rxd , // RGMII Interface
input rgmii_rx_ctl , // RGMII Interface
input rgmii_rxc , // RGMII Interface
output [7: 0] UDP_RX_DATA , // UDP 接收数据输出
output UDP_RX_DATA_VALID , // UDP 接收数据输出有效信号 高有效
output UDP_RX_SOF , // UDP 接收数据包的第一个数据标志
output UDP_RX_EOF , // UDP 接收数据包的最后一个数据标志
input [15:0] UDP_RX_DEST_PORT_NO_IN , // UDP 接收目的端口号
input CHECK_UDP_RX_DEST_PORT_NO, // 置 1 使能 UDP 接收目的端口号输入比对
output [15:0] UDP_RX_DEST_PORT_NO_OUT , // CHECK_UDP_RX_DEST_PORT_NO=1-->UDP_RX_DEST_PORT_NO_OUT=UDP_RX_DEST_PORT_NO_IN
input [7:0] UDP_TX_DATA , // UDP 发送数据输出
input UDP_TX_DATA_VALID , // UDP 发送数据输出有效信号 高有效
input UDP_TX_SOF , // UDP 发送数据包的第一个数据标志
input UDP_TX_EOF , // UDP 发送数据包的最后一个数据标志
output UDP_TX_CTS , // UDP 数据此时可以发送标志
output UDP_TX_ACK , // UDP 数据包发送完成应答
output UDP_TX_NAK , // UDP 数据包发送未完成应答
input [31:0] UDP_TX_DEST_IP_ADDR , // UDP 发送目的 IP 地址
input [15:0] UDP_TX_DEST_PORT_NO , // UDP 发送目的端口号
input [15:0] UDP_TX_SOURCE_PORT_NO , // UDP 发送源端口号
output [8*TCP_NUM-1:0] TCP_RX_DATA , // TCP 接收数据输出
output [TCP_NUM-1: 0] TCP_RX_DATA_VALID , // TCP 接收数据输出有效信号 高有效
output [TCP_NUM-1: 0] TCP_RX_RTS , // 通知用户准备接收 TCP 数据
input [TCP_NUM-1: 0] TCP_RX_CTS , // 清除接收的 TCP 数据
input [8*TCP_NUM-1:0] TCP_TX_DATA , // TCP 发送数据输入
input [TCP_NUM-1: 0] TCP_TX_DATA_VALID , // TCP 发送数据输入有效信号 高有效
output [TCP_NUM-1: 0] TCP_TX_CTS , // TCP 数据此时可以发送标志
input [47: 0] MAC_ADDR , // 本地 MAC 地址
input [31: 0] IPv4_ADDR , // IPv4 地址
input [127: 0] IPv6_ADDR , // IPv6 地址
input [31: 0] GATEWAY_IP_ADDR , // 本地网关地址
input [31: 0] SUBNET_MASK , // 本地子网掩码
input [31: 0] MULTICAST_IP_ADDR , // 多播 IP 地址
input [16*TCP_NUM-1:0] TCP_LOCAL_PORTS , // 本地 TCP 端口号
input [TCP_NUM-1: 0] CONNECTION_RESET // TCP 模块高电平复位
);
详细代码请看源代码;
用户接口
用户接口分为配置接口和用户接口,用户接口又分为跟应用程序对接的接口和跟MAC对接的用户接口;框图如下:

配置接口主要完成一些开关功能,例如使能UDP、IPv6、IGMP、本地MAC地址、IP地址等等,下面举1个例子:
使能UDP接收的配置在代码中的位置如下:

与MAC对接的用户接口不需要讲述,直接与MAC对接即可;
UDP协议的用户接口个人感觉不太重要,因为这里有价值的是TCP协议,所以直接介绍TCP协议的用户接口,TCP协议的用户接口分为接收和发送,都是可与AXI4-Stream对接的类AXI4-Stream接口,代码中有用法,你一看就懂,很简单;
代码的端口中,有一些缩写可能不好理解,下面给出解释:

代码模块级细讲
顶层模块
顶层模块将各个分模块例化在一起,没什么可讲的,在代码中的位置如下:

PACKET_PARSING模块
PACKET_PARSING模块功能是解析从MAC接收到的数据包,并有效地提取与多个协议相关的关键信息。解析是动态进行的,而不存储数据;在代码中的位置如下:

ARP模块
ARP模块的作用是检测ARP请求,并组包一个ARP响应以太网数据包传输到MAC;在代码中的位置如下:
IGMP_REPORT和IGMP_QUERY模块
IGMP_REPORT模块的作用是以广播形式发送GMP成员身份报告,IGMP_QUERY.vhd模块响应成员资格查询。在代码中的位置如下:
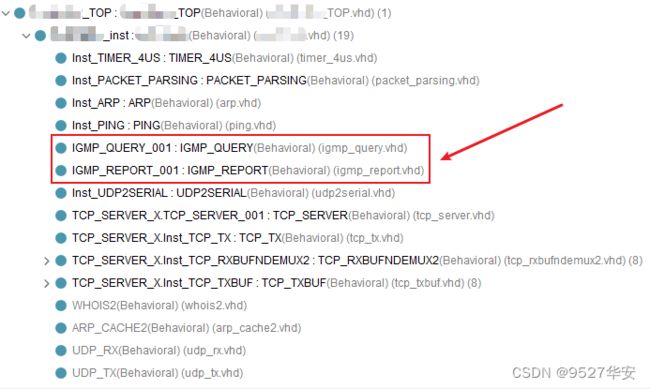
PING和WHOIS2模块
PING模块的作用是检测ICMP回波(ping)请求,并组装一个ping回波以太网数据包,以传输到MAC,Ping同时适用于IPv4和IPv6。
WHOIS2模块的作用是生成一个ARP请求广播包(IPv4)或一个请求消息(IPv6),请求由其IP地址标识的目标用其MAC地址响应。
两个模块共同构成了我们经常用到的ping功能;
在代码中的位置如下:

ARP_CACHE2模块
ARP_CACHE2模块是一个共享的路由表,它存储最多128个IP地址及其关联的48位MAC地址和一个“实时的”时间戳。此模块将确定目标IP地址是否为本地地址。在后一种情况下,将返回网关的MAC地址,只存储有关本地地址的记录(例如,不是WAN地址,因为这些地址通常指向路由器MAC地址);仲裁电路用于仲裁来自多个传输实例的路由请求。在代码中的位置如下:

UDP_TX模块
UDP_TX模块的作用是将一个数据包封装到一个UDP帧中,即从任何端口到任何端口/IP目标的地址。同时支持IPv4和IPv6。通常例化一次,而不管源或目标UDP端口的数量如何,在代码中的位置如下:

UDP_RX模块
UDP_RX模块的作用是验证接收到的UDP帧,并提取其中的数据包。由于验证是在接收到的数据通过时动态执行的(没有存储),因此在数据包结束时提供了有效性确认信号。在代码中的位置如下:

TCP_SERVER模块
TCP_SERVER模块是TCP协议的核心。它可参数化配置,以支持ntcp流并发TCP连接。它本质上是处理TCP服务器的TCP状态机:首先监听来自远程TCP客户端的连接请求,建立和删除连接,并在建立连接时管理流控制和字节排序。由于这是一个服务器,它事先不预先知道协议是IPv4还是IPv6(它依赖于客户端),所以每个服务器有两个IP地址,每个IP版本一个。此模块在TCP服务器的vivado工程中才有,在代码中的位置如下:
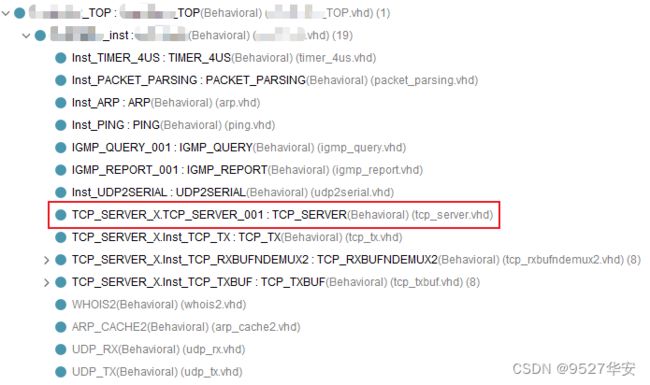
TCP_TX模块
TCP_TX模块的作用是格式化TCP tx帧,包括所有层:TCP,IP,MAC/以太网。它对所有并发流都是通用的,因此只实例化一次。在代码中的位置如下:

TCP_TXBUF模块
TCP_TXBUF模块的作用是将TCP tx有效负载数据存储在单独的弹性缓冲区中,每个传输流对应一个。缓冲区大小是在合成之前通过ADDR_WIDTH通用参数配置的。在代码中的位置如下:

TCP_RXBUFNDEMUX模块
TCP_RXBUFNDEMUX模块解复用了几个TCP rx流。该模块有两个目标: (1)暂时保持一个接收到的TCP帧,直到在帧结束时确认其有效性。如果无效则丢弃,如果无效则丢弃进一步处理。(2)基于目标端口号来分解多个TCP流。在代码中的位置如下:

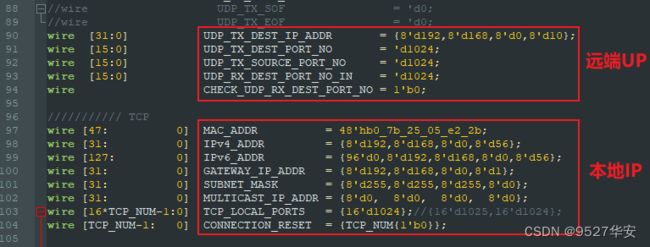
IP、MAC地址定义修改
工程代码中需要定义开发板的MAC、IP地址以及端口号等信息,包括服务器和客户端的;
服务器和客户端的定义修改在代码中的位置一样的,如下:
开发板本地 IP、MAC地址定义修改位置如下:
top.v
5、详细设计方案
详细设计方案如下:

PHY
本例程提供3套vivado工程源码,分别对应RTL8211、B50610、88E1518三款不同的PHY,为了方便大家设计,我直接给出了三款PHY的原理图,已放在资料包中,如下:
Tri Mode Ethernet MAC
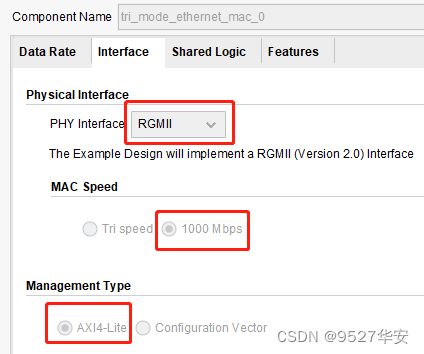
由于TCP协议栈前面已经详细讲过了,这里重点讲讲Tri Mode Ethernet MAC这个IP,IP调用如下:适应大批量数据传输和匹配不同型号FPGA的源语,RGMII转GMII部分调用了Xilinx的Tri Mode Ethernet MAC三速网IP,TCP/IP协议栈的MAC接口与Tri Mode Ethernet MAC实现了MAC层数据交互,MAC数据在Tri Mode Ethernet MAC和TCP/IP 协议栈之间用两个AXI-FIFO实现数据缓冲和提高数据带宽;Tri Mode Ethernet MAC固定速率为1000兆,IP配置如下:

Tri Mode Ethernet MAC在本设计中处于被锁定状态,这是我们故意为之,目的是根据不同的PHY延时参数而修改其内部代码和内部时序约束代码,这里重点介绍使Tri Mode Ethernet MAC时的修改和移植事项,当你需要工程移植,或者你的vivado版本与我的不一致时,Tri Mode Ethernet MAC都需要在vivado中进行升级,但由于该IP已被我们人为锁定,所以升级和修改需要一些高端操作,关于操作方法,我专门写了一篇文档,已附在资料包里,如下:

TCP数据回环
将TCP的收发端口直接用assign语句连接起来形成数据回环,外部指定FPGA开发板的IP地址、MAC地址、端口号、目的IP地址、目的端口号等信息,即可完成TCP协议栈数据回环的工程搭建;代码部分如下:

6、vivado工程1–>B50610 工程
开发板:Xilinx–>xc7k325tffg676-2;
开发环境:Vivado2020.2;
网络PHY:B50610 延时模式;
输入\输出:TCP 网络通信;
测试项:数据收发、连续ping;
工程代码架构如下:

FPGA资源消耗和功耗预估;

7、vivado工程2–>RTL8211 工程
开发板:Xilinx–>xc7a35tfgg484-2;
开发环境:Vivado2020.2;
网络PHY:RTL8211;
输入\输出:TCP 网络通信;
测试项:数据收发、连续ping;
工程代码架构如下:

FPGA资源消耗和功耗预估;

8、vivado工程3–>88E1518 工程
开发板:Xilinx–>xc7k325tffg676-2;
开发环境:Vivado2020.2;
网络PHY:88E1518;
输入\输出:TCP 网络通信;
测试项:数据收发、连续ping;
工程代码架构如下:

FPGA资源消耗和功耗预估;

9、工程移植说明
vivado版本不一致处理
1:如果你的vivado版本与本工程vivado版本一致,则直接打开工程;
2:如果你的vivado版本低于本工程vivado版本,则需要打开工程后,点击文件–>另存为;但此方法并不保险,最保险的方法是将你的vivado版本升级到本工程vivado的版本或者更高版本;
3:如果你的vivado版本高于本工程vivado版本,解决如下:

打开工程后会发现IP都被锁住了,如下:

此时需要升级IP,操作如下:


FPGA型号不一致处理
如果你的FPGA型号与我的不一致,则需要更改FPGA型号,操作如下:



更改FPGA型号后还需要升级IP,升级IP的方法前面已经讲述了;
其他注意事项
1:由于每个板子的DDR不一定完全一样,所以MIG IP需要根据你自己的原理图进行配置,甚至可以直接删掉我这里原工程的MIG并重新添加IP,重新配置;
2:根据你自己的原理图修改引脚约束,在xdc文件中修改即可;
3:纯FPGA移植到Zynq需要在工程中添加zynq软核;
10、上板调试验证并演示
准备工作
以vivado工程1–>B50610 工程为例进行上板调试;
连接如下:

首先设置电脑端IP如下:

下载bit,如下:

ping测试
打开cdm,输入 ping 192.168.0.56,如下:

TCP数据回环测试
打开网络调试助手并配置,如下:

单次发送数据测试结果如下:

循环发送数据测试结果如下,1秒时间间隔循环:

传输速率测试
去除合理线损后的PC段测得991M速率,如下:

11、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:私,或者文章末尾的V名片。
网盘资料如下:

TCP源码路径如下:
