SpringBoot整合RabbitMQ——RabbitMQ进阶
rabbitMQ如何保证如果消息发送失败,保证其消息不丢失、怎么设置消息过期时间以及死信队列是如何在消息消费失败时保证消息不丢失的、如何使用过期时间来实现延迟队列以及rabbitMQ的持久化、消息确认的机制是怎样的?本博文将具体介绍上述内容
本博文中的代码实现实在SpringBoot整合RabbitMQ——消息的发送和接收的基础上实现了,完整的代码可以查看Gitee上的项目rabbitmq
rabbitMQ如何保证消息的不丢失
消息的丢失有以下四种情况:
- 消息发送到RabbitMQ服务器,交换机根据自身的类型和路由键无法匹配到队列,导致消息丢失
- 消息设置了过期时间,消息过期了导致消息丢失
- 消息不能被正确的消费,导致消息的丢失
- 因为服务器的崩溃导致消息的丢失
针对以上的情况,rabbitMQ提供了不同的解决方案
消息设置mandatory参数和使用备份交换机
mandatory参数
在上篇博文中我们其实已经在配置文件中配置了mandatory的参数,并且在connectionFactory中设置了其中的参数
spring:
rabbitmq:
template:
mandatory: true
publisher-confirms: true
publisher-returns: true
然后再发送消息的时候设置回调函数
/**
* 确认后回调方法
*
* @param correlationData
* @param ack
* @param cause
*/
@Override
public final void confirm(CorrelationData correlationData, boolean ack, String cause) {
this.logger.info("confirm-----correlationData:" + correlationData.toString() + "---ack:" + ack + "----cause:" + cause);
// TODO 记录日志(数据库或者es)
this.handleConfirmCallback(correlationData.getId(), ack, cause);
}
/**
* 失败后回调方法
*
* @param message
* @param replyCode
* @param replyText
* @param exchange
* @param routingKey
*/
@Override
public final void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
this.logger.info("return-----message:" + message.toString() + "---replyCode:" + replyCode + "----replyText:" + replyText + "----exchange:" + exchange + "----routingKey:" + routingKey);
// TODO 记录日志(数据库或者es)
this.handleReturnCallback(message, replyCode, replyText, routingKey);
}
用户可以在这里对消息进行本地持久化,其实上面的也叫消息确认模式,发送端将消息发送给RabbitMQ,rabbitMQ会异步回调Confirm方法,告诉发送方,RabbitMQ服务端有没有收到消息,如果没有收到消息的话,原因是什么。同时会异步回调设置的returnedMessage将发送的消息返回
备份交换机
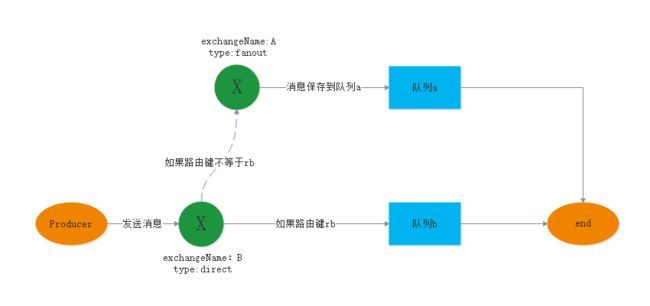
除了上面的消息确认模式,还有一种备份交换机的方案也是可以解决消息的丢失问题,具体的逻辑如下:
- 声明一个交换机A,其类型为fanout类型
- 声明一个交换机B,设置其
alternate-exchange属性为交换机A - 声明一个队列a,并且与交换机A绑定
- 声明一个队列b,并且与交换机B绑定,路由键为rb
这样我们就实现了备份交换机功能,其业务实现逻辑如下:
我们发送一个消息到交换机B上,当路由键等于rb时,消息会正确发送到队列b上,当路由键不等于rb时,即消息不能正确的发送到队列b上,此时就会发送给交换机A,由于交换机A是fanout类型的,所以消息会被进一步发送到队列a上。这样我们就实现了发送方消息的不丢失。
代码实现这里给出alternaate-exchange的实现
Map<String,Object> map = new HashMap<String,Object>();
map.put("alternate-exchange","A");
MqExchange exchange = new MqExchange().arguments(map).name("B").type(ExchangeTypeEnum.DIRECT.getCode());
amExchangeDeclare.declareExchange(exchange);
过期时间和死信队列
过期时间
我们常见的购物车订单,一般有这样的需求,在规定的时间内没有付款的话,该订单就会失效,这里常见就是使用消息的过期时间来控制的,在rabbitMQ中实现过期时间有两种方式
- 设置队列的过期时间,则该队列中所有的消息的过期时间都是一样的
// 设置队列的过期时间
Map<String,Object> map = new HashMap<String,Object>();
map.put("x-message-ttl",6000);
MqQueue queue = new MqQueue().name(queueName).arguments(map);
amQueueDeclare.declareQueue(queue);
如果不设置ttl(Time To Live),则这个消息不会过期,如果将TTL设置为0,则表示除非此时可以直接将消息投递到消费者,否则消息会立即丢弃
- 设置消息的过期时间,只有这个消息存在过期时间,设置消息的过期时间如下:
// 设置消息的过期时间
MessagePostProcessor messagePostProcessor = new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setExpiration(6000);
return message;
}
};
sendService.send(exchangeName,routingKey,data, messagePostProcessor, messageId);
注意:使用第一种方式来设置过期时间,一旦消息过期,就会从队列中消除,而采用第二种方式,即使消息过期,也不会马上从队列中消除,因为每条消息是否过期是在即将投递到消费者之期间进行判断的
队列也是有过期时间的,通过x-expires属性来设置的
Map<String,Object> map = new HashMap<String,Object>();
map.put("x-expires",6000);
MqQueue queue = new MqQueue().name(queueName).arguments(map);
amQueueDeclare.declareQueue(queue);
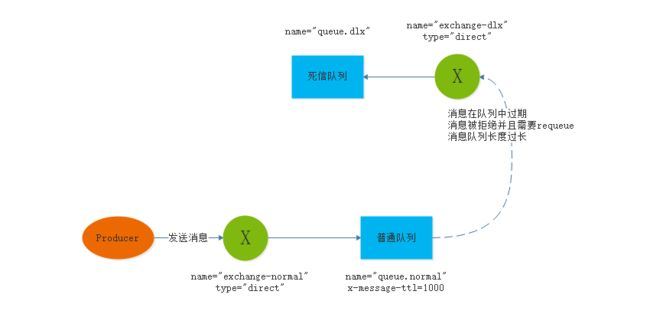
死信队列
DLX:Dead-Letter-Exchange:当一个消息在一个队列中变成死信之后,他能被重新发送到另一个交换机中,这个交换机就是DLX。
那么消息满足什么条件就会成为死信呢?
- 消息被拒绝,并且设置requeue参数为false
- 消息过期
- 队列达到最大长度
那么如何使用死信队列?
死信队列一般都是作为其他队列的一个属性来用的,当这个队列中存在死信时,RabbitMQ就会自动将这个消息重新发布到设置的DLX上,进而被路由到另一个队列中
// 定义一个交换机
MqExchange dlxExchange = new MqExchange().name("B").type(ExchangeTypeEnum.DIRECT.getCode());
amExchangeDeclare.declareExchange(exchange);
// 声明一个队列时,设置他的属性 x-dead-letter-exchange 为上面定义的交换机
Map<String,Object> map = new HashMap<String,Object>();
map.put("x-dead-letter-exchange ","dlxExchange");
// 也可以为DLX指定路由键 这个不是必须的,如果没有设置路由键,则使用原队列的路由键
map.put("x-dead-letter-routing-key","dlx-routing-key");
MqQueue queue = new MqQueue().name(queueName).arguments(map);
amQueueDeclare.declareQueue(queue);
这样就初步完成了死信队列的声明。其业务流程图如下:
延时队列(定时队列)
上述的购物车订单的示例,其实最优的方案设计是使用TTL+DLX来实现,如果用户没有在规定的时间来支付,则这个订单就进行一场处理。
延时队列的具体使用方法如下:
方案一:
- 声明一个设置死信队列的队列,该队列没有消费者
- 给每一个发送该队列的消息设置过期时间
- 消息一旦过期就会被死信队列消费,这样就能实现延时队列的效果
方案二:
- 声明多个设置死信队列、不同过期时间的队列,该队列没有消费者
- 然后通过不同的的routingKey来将消息发送到不同的队列上
- 等队列过期时间一到,消息就会匹配到死信队列上,这样也能实现延时队列的效果
方案一和方案二的实现原理基本相同,不同的是一个是消息的过期时间,一个是队列的过期时间,方案二声明多个不同过期时间的队列,而方案一只声明一个队列,这样的话有优点也有缺点,优点是减少了RabbitMQ的队列数量,缺点是降低了RabbitMQ队列消息消费的速度,而使用哪种方案可以根据业务和流量来衡量使用
具体的业务流程图如下:
[外链图片转存失败(img-vHyfJ7TP-1562419542229)(https://s2.ax1x.com/2019/07/04/ZUaCqI.png)]
消息持久化
RabbitMQ中交换机、队列和消息都可以持久化,其中交换机和队列的持久化只需要在声明时,其属性durable为true即可,而消息的持久化是建立在队列持久化的基础上,因为在RabbitMQ中,消息时存储在队列上的,队列都没有了,消息肯定也是存储不了的。
消息的持久化在上面的内容已经介绍过了,不同版本的SpringBoot的RabbitMQ集成,实现的方式可能 不一样,但是本质都是一样的,最终操作的都是RabbitMQ服务器
消息和队列的持久化都是比较简单的,但是我们这里要清楚的知道,如果我们将所有的消息都设置了持久化了,会严重影响RabbitMQ的性能,毕竟消息写入到磁盘的速度比写入内存的数据慢的不是一点点的。
这个就要求我们在设计时需要注意,对于可靠性不是那么高的消息,可以不采用持久化处理来提高吞吐量。在选择是否将消息持久化时,需要在可靠性和吞吐量之间做一个权衡
消息消费处理
参数isAck
这里需要注意一点,在我们上一篇博文SpringBoot整合RabbitMQ——消息的发送和接收中,我们有介绍在为队列设置监听时,有个参数isAck,这里如果设置成true,则队列在接收到消息后,不管业务方有没有完全消费消息,都会给RabbitMQ返回个消息已经消费成功的结果,RabbitMQ在判断消息已经成功消费了则会删除队列中的消息,但是业务方其实没有真正完成消息的消费,这样就会导致数据的丢失。
那我们怎么来处理这个问题呢?
其实很简单,我们只需要将isAck字段的参数设置成false即可,这样的话就需要业务方手动去操作该消息有没有被成功消费。如果没有消费的话就拒绝这个消息,是的拒绝这个消息,还记得我们之前介绍过的死信队列,队列设置了死信队列,消息一旦被拒绝的话,消息就会进入死信交换机,进而匹配到响应的队列中,可以在队列中将消息持久化到本地,这是一种解决方法。
具体的流程图可以参考死信队列的流程图:
消息分发
在实际的生产过程中,可能一个队列存在多个消费者,那么队列此时收到的消息就会以轮询的方式发送给消费者。
一般情况下,rabbitMQ会将第m条消息发送给第m%n个消费者。这里其实有个隐患,在消费者任务非常繁重的情况下,来不及消费那么多的消息,而其他的消费者,由于某些原因,很快的处理完消息,这种情况就很容易出现某个消费者承受的压力就比较大,造成整体应用的吞吐量下降。
为了解决这个问题, 我们其实可以设置Channel信道上的最大处理消息的个数,代码设置如下:
// 在系统初始化启动时,加载Connection,创建Channel,然后设置BasicQos的个数
Channel channel = cachingConnectionFactory.createConnection().createChannel();
channel.basicQos(1000);
basicQos具体的作用是设置允许限制Channel上所有消费者所能保持的最大未确认的消息的数量
注意如果这里设置了最大的未确认的消息的数量,那么所有的消费者都会生效