Elasticsearch互联网主流分布式全文检索框架实战-ElasticStack(上)v7.14.0
Elasticsearch概述
**本人博客网站 **IT小神 www.itxiaoshen.com
Elasticsearch官网地址 https://www.elastic.co/cn/elasticsearch/
Elasticsearch简称为ES,是一个基于Lecene开源的分布式高度可扩展的搜索和数据分析引擎,使用Java语言开发,带有RESTful 风格的API,是目前最流行的企业级搜索引擎;能够快速、接近实时地存储、搜索和分析大量数据;通常被用作底层引擎/技术,为具有复杂搜索特性和需求的应用程序提供支持。目前最新Release版本为7.14 ,7.15版本虽然已出现在官方但暂时还没有提供基于docker的镜像
Elasticsearch参考文档官网 https://www.elastic.co/guide/en/elasticsearch/reference/index.html
Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您使用的是结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch都能以一种支持快速搜索的方式有效地存储和索引它们。您可以远远超出简单的数据检索和聚合信息来发现数据中的趋势和模式。随着数据和查询量的增长,Elasticsearch的分布式特性使您的部署能够与之无缝地增长。
Elasticsearch使用场景
- 维基百科,类似百度百科、谷歌和百度这类基于搜索核心,使用到全文检索、高亮、搜索推荐,
- GitHub,托管开源项目源码,全文搜索千亿行级的源代码
- 电商网站,比如京东、淘宝之类,检索商品
- Stack Overflow ,国外程序员讨论论坛,输入报错日志搜索问题和答案
- 日志数据分析,ELK,Logstash和Beats收集日志,Elasticsearch复杂分析,Kibana做可视化
- 常见新闻网站用户行为分析,比如将用户的点击、浏览、收藏、评论进行数据分析
- 其他行业的站内搜索
- 总之ES常用全文检索、结构化搜索、数据分析及相互混用的场景
Elasticsearch和Solr
Solr简介
Solr官网 https://solr.apache.org
Solr是一个基于 Apache Lucene 之上的搜索服务器,开源的、基于 Java 的信息检索库。它的主要功能包括强大的全文搜索、高亮显示、分面搜索、动态集群、数据库集成、丰富的文档处理和地理空间搜索;Solr具有高度的可扩展性,提供容错的分布式搜索和索引,并支持许多世界上最大的互联网站点的搜索和导航功能。具有类似rest的API,可以通过JSON、XML、CSV或HTTP上的二进制文件将文档放入其中(称为“索引”),通过HTTP GET查询它,并接收JSON、XML、CSV或二进制结果。目前最新版本为8.9.0
Lucene
概述
Lucene官网 https://lucene.apache.org/
Apache Lucene™是一个开源的、高性能、全功能的文本搜索引擎库,完全用Java编写。它适用于几乎所有需要全文搜索的应用程序,特别是跨平台的应用程序。Lucene Core是一个Java库,提供强大的索引和搜索功能,以及拼写检查、点击高亮和高级分析/标记功能。
Apache Lucene为搜索和索引性能设置了标准,是Apache Solr和Elasticsearch的搜索核心,目前最新版本为8.9.0
缺点
- Lucene只能在Java项目中使用,以jar引用
- 使用比较复杂,包括创建和搜索索引代码较为复杂,需要先了解检索的相关知识来理解它是如何工作的
- 不支持集群环境,索引不能同步,不支持大规模数据的应用
什么是全文检索
- 简单的将就是通过扫描文本的每一个单词,针对单词建立索引,并保存该单词在文本中的位置以及出现的频次
- 用户需要查询时,通过之前建立好的索引来查询,将索引中单词对应的位置、单词频次信息返回给用户,因为有了文本位置信息编号就可以通过正排索引将内容获取出来
倒排索引
索引就类似于目录,平时我们使用的都是索引,都是通过主键定位到某条数据,那么倒排索引,刚好相反,数据对应到主键.这里以一个博客文章的内容为例:
- 索引
| 文章ID | 文章标题 | 文章内容 |
|---|---|---|
| 1 | 浅析JAVA设计模式 | JAVA设计模式是每一个JAVA程序员都应该掌握的进阶知识 |
| 2 | JAVA多线程设计模式 | JAVA多线程与设计模式结合 |
- 倒排索引
假如,我们有一个站内搜索的功能,通过某个关键词来搜索相关的文章,那么这个关键词可能出现在标题中,也可能出现在文章内容中,那我们将会在创建或修改文章的时候,建立一个关键词与文章的对应关系表,这种,我们可以称之为倒排索引,因此倒排索引,也可称之为反向索引.如:
| 关键词 | 文章ID |
|---|---|
| JAVA | 1 |
| 设计模式 | 1,2 |
| 多线程 | 2 |
倒排索引一般由单词词典(Term Distionary)和倒排列表(PostingList)组成
单词词典
- 是倒排索引的重要组成部分,记录所有单词及其与倒排列表的关联关系,单词词典一般用B+Tree来实现,存储在内存中
倒排列表一般存储在磁盘中,包含一下信息
- 文档ID
- 单词词频 (Term Frequency)
- 位置 (position)
- 偏移 (offset)
动态索引更新策略
动态索引通过在内存中维护临时索引,实现对动态文档和实时搜索的支持。对于服务器的内存总是有限的,随着加入的文档数据越来越多,临时索引消耗的内存也会不断增加。当最初分配的内存被使用完时就需要考虑使用什么策略来将临时索引的部分内容更新到磁盘索引中,以释放内存空间来存储新的数据。
常用的索引更新策略主要有四种:完全重建策略、再合并策略、原地更新策略及混合策略。
- 完全重建策略:属于一种很直接的方法,当新增文档达到一定数量,将新增文档和原先的老文档进行合并,然后利用建立静态索引的方式,对所有文档重新建立索引。新索引建立完成后,老的索引被遗弃释放,之后对用户查询的相应完全由新的搜索来负责
- 再合并策略:有新增文档进入搜索系统时,搜索系统在内存维护临时倒排索引来记录信息,当新增文档达到一定数量,或者指定大小的内存被消耗完,则把临时索引和老文档的倒排索引进行合并,以生成新的索引
- 原地更新策略:原地更新策略在索引合并时,并不生成新的索引文件,而是直接在原先老的索引文件里进行追加操作,将增量索引里单词的倒排列表项追加到老索引相应位置的末尾,这样就可以达到上述目标,即只更新增量索引里出现的单词相关信息,其他单词相关信息不做变动
- 混合策略:混合策略的出发点是能够结合不同索引更新策略的长处,将不同的索引更新策略混合,以形成更高效的方法。混合策略一般会将单词根据不同性质进行分类 ,不同类别单词,对其索引采取不同的索引更新策略
分词器
定义
- 把全文本转换为一系列单词的过程就叫分词,一般通过分析器来实现
- 分词器的作用就是将整篇文章按照一定语义切分为一条条的词条,目标是提升文档的召回率,降低无效数据的噪音
- recall:召回率,也叫可搜索性,指进行搜索时候能够增加搜索到结果的数量
- 降噪:指降低文章中的一些低相关性的词条对整体搜索排序结果的干扰
组成
分析器一般都由三个构建组成,包括字符过滤器、分词器、token过滤器组成
- 字符过滤器:预处理,比如过滤html标签
- 分词器:例如英文分词可以通过按照空格将单词分开,而中文分词就要复杂一些,一般通过机器学习算法来分词
- token过滤器:对分词后单词就行加工,比如大小写转换、去掉一些停用词如英文(a、and、the),中文(的、地、了)等
分词器
- 默认分词器:Standard Analyzer,基于Unicode文本分格算法,按词切分,小写处理,适用于大多数语言
- 简单分词器:Simple Analyzer,按照非字母切分符号过滤掉,小写处理
- 空格分词器:Whitespace Analyzer,按照空格进行分词,不转小写,中文不分词
- 停用词分析器:StopAnalyzer:小写处理,停用词过滤
- 常用语言分词器
- 自定义分词器
中文分词器
中文分词器目前比较推荐的是IK分词器,为何要进行分词,如果没有分词“我爱中国”就会被拆分为四个单独的子,显然不符合我们中文的语义
IK分词器源码地址 https://github.com/hutea/ikanalyzer
IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 IK Analyzer 2012特性:
- 采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和智能分词两种切分模式;
- 在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。
- 2012版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。
- 采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符
- 优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在2012版本,词典支持中文,英文,数字混合词语。
-
分ik_smart:最粗力度拆,也即是最少的拆分
-
ik_max_word:也即是最细的粒度拆分
Elasticsearch和Solr比较
- 如果对已有的数据进行搜索,则Solr速度更快
- 实时建立索引时,Solr会产生IO阻塞,查询性能较差,而这种场景Elasticsearch具有明显的优势
- 随着数据量增大,Solr的搜索效率的降低,而Elasticsearch却没有明显的变化
- Elasticsearch基本是开箱即用,比较简单,Solr则略微复杂一点
- Solr利用Zookeeper进行分布式管理,而Elasticsearch内置有分布式协调和管理功能
- Solr比Elasticsearch支持更多格式的数据如Json、XML、CSV,而目前Elasticsearch仅支持Json
- Solr提供功能较丰富,Elasticsearch则关注核心功能,高级功能可以使用第三方插件集成,比如图形化可以搭配Kibana使用
- Solr比较成熟有一个更多用户和开发者社区支持,而Elasticsearch是新兴的,开发维护者相对较少,且更新速度太快,学习成本暂时较高
- Solr查询快,但是更新索引较慢,适用于查询多更新不频繁的场景比如电商领域,是传统搜索应用的有力解决方案;而Elasticsearch建立索引快,即实时性查询快,更适用于新兴实时搜索应用如facebook、新浪等
- 经过大型互联网公司线上生产环境验证,将搜索引擎Solr替换为Elasticsearch后平均查询速度提升近50倍左右
Elasticsearch核心概念
Elasticsearch核心内容
- 数据类型:文档和索引
- 信息输出:搜索和数据分析
- 分布式特点:可伸缩性和弹性
文档和索引
我们拿关系数据库做层级的类比,在Elasticsearch集群中可以存在多个index(索引可类比为数据库或者表,index下type这个在6.x开始就不推荐且只有index只能有一个type,在7.x版本则是已去掉了,一个 index 中只有一个默认的 type,即 _doc),每个索引中可以包含多个document(记录可类比为行),每个document下又可以包含多个Field(字段类比列),mapping相当于我们表结构schema
- 索引 index
- 一个索引就是一个拥有几分相似特征的文档的集合。比如说,可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引
- 一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字
- 映射 mapping
- ElasticSearch中的映射(Mapping)用来定义一个文档
- mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的
- 字段Field
- 相当于是数据表的字段|列
- 字段类型 Type
- 每一个字段都应该有一个对应的类型,例如:Text、Keyword、Byte等
- 文档 document
- 一个文档是一个可被索引的基础信息单元,类似一条记录,文档以JSON(Javascript Object Notation)格式来表示;
- ElasticSearch是面向文档的,所以文档也是ElasticSearch搜索和索引数据的最小单位
- 有灵活的结构,可以动态添加文档的字段,不需要像关系数据库那样得先定义好字段
- 集群 cluster
- 一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能
- 节点 node
- 一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能
- 一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中
- 这意味着,如果在网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中
- 在一个集群里,可以拥有任意多个节点。而且,如果当前网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。所以在ES中,一个节点就可以是一个集群
- 分片和副本 shards&replicas
- 分片 shards
- 一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢,为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片
- 当创建一个索引的时候,可以指定你想要的分片的数量
- 每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上
- 分片很重要,主要有两方面的原因
- 允许水平分割/扩展你的内容容量
- 允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量
- 至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,作为用户来说,这些都是透明的
- 副本 replicas
- 在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且也是强烈推荐的。为此Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做副本
- 副本之所以重要,有两个主要原因
- 在分片/节点失败的情况下,提供了高可用性
- 注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的
- 扩展搜索量/吞吐量,因为搜索可以在所有的副本上并行运行
- 每个索引可以被分成多个分片。一个索引有0个或者多个副本
- 在分片/节点失败的情况下,提供了高可用性
- 一旦设置了副本,每个索引就有了主分片和副本分片,分片和副本的数量可以在索引,创建的时候指定,在索引创建之后,可以在任何时候动态地改变副本的数量,但是不能改变分片的数量
- 分片 shards
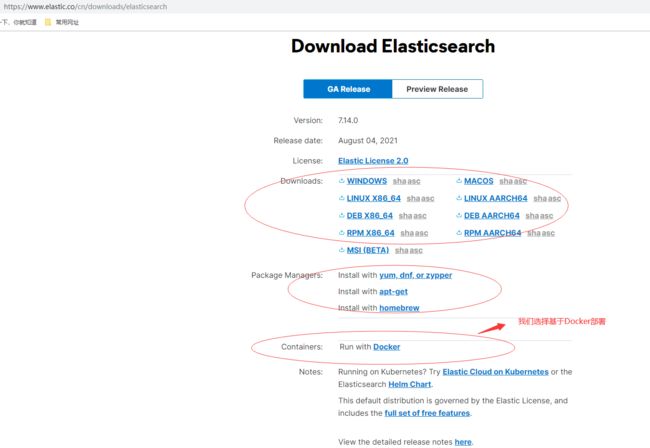
Elasticsearch部署
Elasticsearch官网下载地址
部署方式可以有多种,现在是容器化时代,由于之前文章我们已学习过Docker,所以我们选择基于Docker容器化部署,基于docker可以选择单机部署,基于K8S部署后续有时间再补充;可以选择单节点集群或多节点集群部署,我们直接选择官网例子基于单台宿主机docker-compose三个节点的集群部署

默认情况下,Elasticsearch会根据节点的角色和节点容器可用的总内存自动调整JVM堆的大小。对于大多数生产环境,我们建议使用此默认分级。如果需要,您可以通过手动设置JVM堆大小来覆盖默认大小。
要在生产中手动设置堆大小,绑定挂载在/usr/share/elasticsearch/config/ JVM .options下的JVM选项文件。D,其中包含所需的堆大小设置。
为了进行测试,您还可以使用ES_JAVA_OPTS环境变量手动设置堆大小。例如,要使用16GB,请指定-e
ES_JAVA_OPTS="-Xms16g -Xmx16g"与docker运行。ES_JAVA_OPTS变量覆盖所有其他JVM选项。ES_JAVA_OPTS变量覆盖所有其他JVM选项。我们不建议在生产环境中使用ES_JAVA_OPTS。
创建docker-compose.yml文档,在这个例子中使用ES_JAVA_OPTS环境变量手动设置堆大小为512MB。
version: '2.2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:7.14.0
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: docker.elastic.co/elasticsearch/elasticsearch:7.14.0
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
image: docker.elastic.co/elasticsearch/elasticsearch:7.14.0
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
运行docker-compose以启动集群,先创建网络
docker-compose up

运行后出现如下报错后退出了
es01 exited with code 78
es02 exited with code 78
es03 exited with code 78
我们通过其中一个容器查看日志 docker logs -tf --tail 10 052a5cf054a5
![]()
#通过root用户执行命令:
sysctl -w vm.max_map_count=262144
#查看结果:
sysctl -a|grep vm.max_map_count
#显示:
vm.max_map_count = 262144
#上述方法修改之后,如果重启虚拟机将失效,我们需要在 /etc/sysctl.conf文件最后添加一行vm.max_map_count=262144即可永久修改
重新执行即可正常使用,访问 http://192.168.50.94:9200/ ,至此我们安装完毕,非常简单
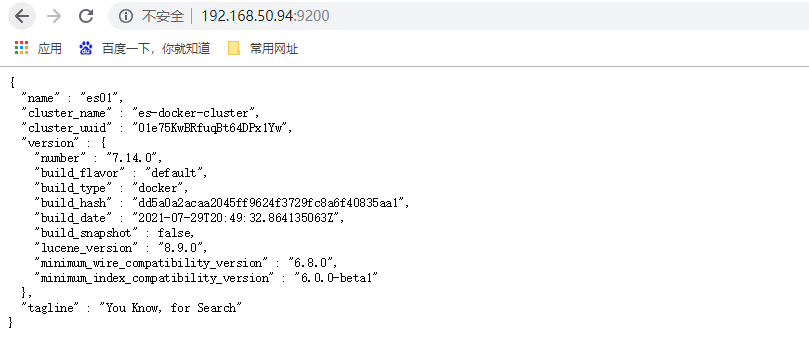
ES自身也提供很多集群维护查询命令,有兴趣可以自己查阅学习

安装Head插件
//docker下载elasticsearch-head:5插件
docker pull mobz/elasticsearch-head:5
//docker启动elasticsearch-head:5容器,elastic_search_elastic为我们上一节安装的docker网络
docker run -d --network elastic_search_elastic -p 9100:9100 mobz/elasticsearch-head:5

启动后在流量访问9100端口:http://192.168.50.94:9100/,设置连接访问任意一台ES服务(本文为http://192.168.50.94:9200/,也即是采用上一小节在192.168.50.94部署docker的ES集群且暴露的9200端口),查看浏览控制台输出跨域错误,因此我们解决跨域问题
通过docker ps 找到我们ES集群所有容器,逐个进入容器的内容修改config修改config/elasticsearch.yml文件,然后重新启动ES集群
Copy# 开启跨域
http.cors.enabled: true
# 允许所有
http.cors.allow-origin: "*"
再次访问就可以了
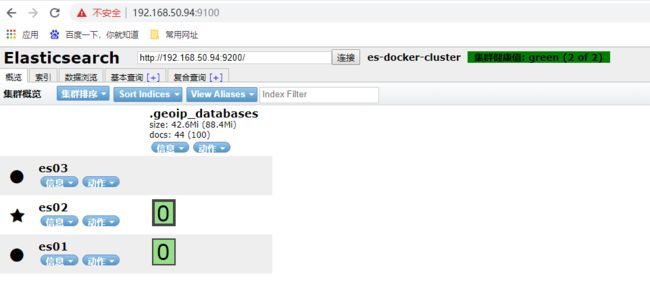
我们新建一个索引库,分片数为5副本数为2

五个主分片负载均衡分布在三个节点上,head插件也提供数据浏览、基本查询和符合查询,但我们基本不怎么使用,常用是使用Kibana的Devtools,下节我们安全后学习
安装Kibana
Kibana官网地址 https://www.elastic.co/cn/kibana/
基于docker安装Kibana https://www.elastic.co/guide/en/kibana/current/docker.html
新建kibana.yml
server.name: kibana
# kibana的主机地址 0.0.0.0可表示监听所有IP
server.host: "0.0.0.0"
# kibana访问es的URL
elasticsearch.hosts: ["http://es01:9200","http://es02:9200","http://es03:9200"]
# 显示登陆页面
xpack.monitoring.ui.container.elasticsearch.enabled: true
通过Kinana官网的安装说明指引,我们创建docker-compose.yml,es01、es02、es03为之前建立ES集群服务器名称,elastic_search_elastic为建立ES集群创建网络,这样可以通过主机名称访问
version: '2'
services:
kibana:
image: docker.elastic.co/kibana/kibana:7.14.1
volumes:
- /home/docker_resource/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml
ports:
- "5601:5601"
environment:
SERVER_NAME: kibana
ELASTICSEARCH_HOSTS: '["http://es01:9200","http://es02:9200","http://es03:9200"]'
networks:
default:
external:
name: elastic_search_elastic
然后在docker-compose.yml的目录下执行命令启动kibana容器服务
docker-compose up -d
访问Kibana暴露的端口地址:http://192.168.50.94:5601
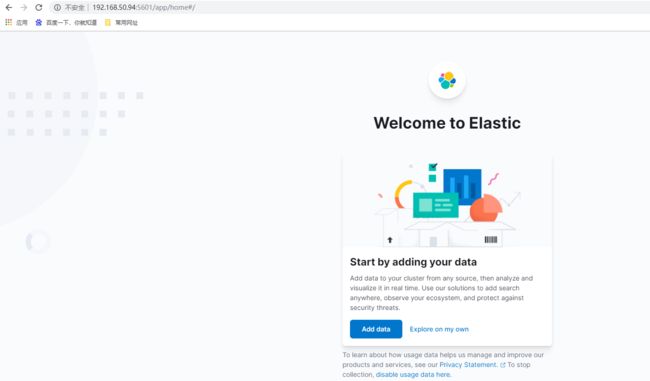
点击Dev tools进入到开发工具界面

安装elasticsearch-analysis-ik
elasticsearch-analysis-ik源码地址 https://github.com/medcl/elasticsearch-analysis-ik
通过GitHub上的安装说明我们下载预构建的包
预构建的包下载地址 https://github.com/medcl/elasticsearch-analysis-ik/releases
Analyzer: ik_smart, ik_max_word,
Tokenizer: ik_smart, ik_max_word
下载elasticsearch-analysis-ik-7.14.0.zip完毕后,在所有elasticsearch服务的安装目录下的plugins目录下新建ik目录,将上面zip包的内容全部放到ik
可以通过从宿主机拷贝到容器的方式
docker cp ik/ 9bad7f196e38:/usr/share/elasticsearch/plugins
拷贝到容器下的目录结构为下面所示

然后重启所有elasticsearch服务服务,每台elasticsearch服务会有出现这个日志信息,代表加载了ik插件
“message”: “loaded plugin [analysis-ik]”
还可以通过执行bin目录下./elasticsearch-plugin list 查看加载插件信息
通过kibana测试下ik
先试用ik_smart最粗力度拆分测试下
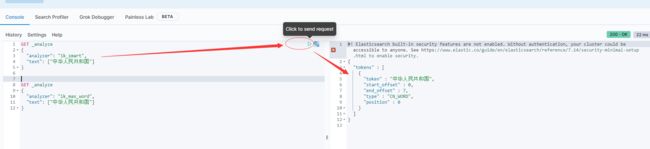
再使用ik_max_word最细的粒度拆分测试下

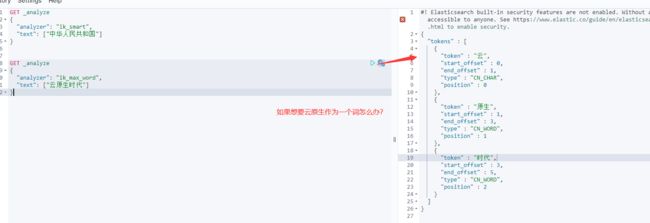
这就需要我们进行自定义拆分的词典,将自定义分词加到ik分词器的字典里
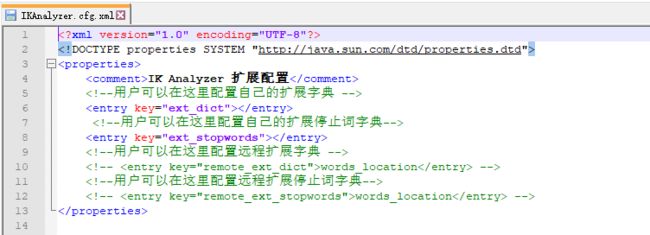
新建itxs.dic文件,在IKAnalyzer.cfg.xml修改如下内容itxs.dic
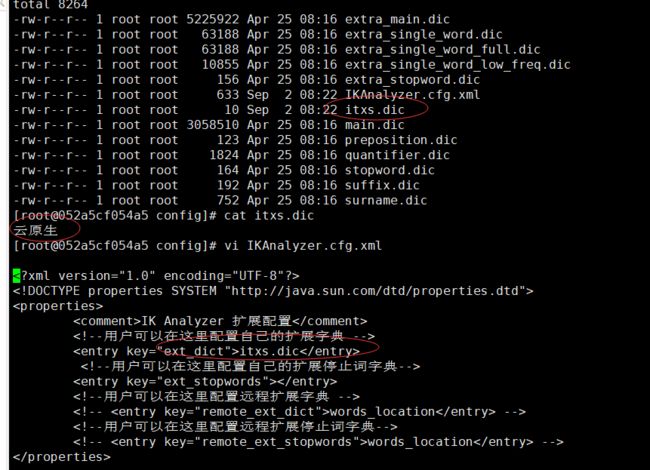
重启所有ES服务,查看ES服务的日志会发现有如下信息代表加载我们指定以分词字典文件
“message”: “[Dict Loading] /usr/share/elasticsearch/plugins/ik/config/itxs.dic”
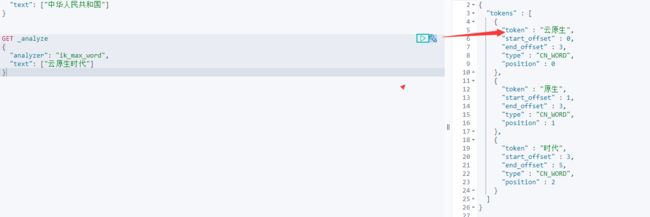
重新执行查询后发现"云原生"已经被拆分为一个单词了
Elasticsearch的使用
入门说明
Elasticsearch文档官网地址 https://www.elastic.co/guide/en/elasticsearch/reference/7.14/index.html
官方提供非常详细开发和维护使用的指南,官方上中文文档已经比较老了,建议用最新发布版本的英文文档,如需全面学习有兴趣可以自己研究,其中也有REST APIs接口


基本概念
-
text类型:会分词,先把对象进行分词处理,然后再再存入到es中。当使用多个单词进行查询的时候,当然查不到已经分词过的内容!
-
keyword:不分词,没有把es中的对象进行分词处理,而是存入了整个对象!这时候当然可以进行完整地查询!默认是256个字符!
-
动态映射:就是自动创建出来的映射,es 根据存入的文档,自动分析出来文档中字段的类型以及存储方式,这种就是动态映射
-
静态映射:在创建索引就指定好映射,属于明确的映射
基础操作
- 创建索引
格式: PUT /索引名称
PUT /es_dbtest
- 查询索引
格式: GET /索引名称
GET /es_dbtest
- 删除索引
格式: DELETE /索引名称
DELETE /es_dbtest
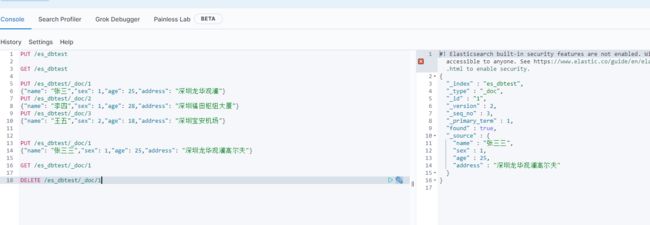
- 添加文档
格式: PUT /索引名称/类型/id
PUT /es_dbtest/_doc/1
{"name": "张三","sex": 1,"age": 25,"address": "深圳龙华观澜"}
PUT /es_dbtest/_doc/2
{"name": "李四","sex": 1,"age": 28,"address": "深圳福田枢纽大厦"}
PUT /es_dbtest/_doc/3
{"name": "王五","sex": 2,"age": 18,"address": "深圳宝安机场"}
- 修改文档
格式: PUT /索引名称/类型/id
PUT /es_dbtest/_doc/1
{"name": "张三三","sex": 1,"age": 25,"address": "深圳龙华观澜高尔夫"}
- 查询文档
格式: GET /索引名称/类型/id
GET /es_dbtest/_doc/1
- 删除文档
格式: DELETE /索引名称/类型/id
DELETE /es_dbtest/_doc/1
- POST和PUT都能起到创建/更新的作用
- 需要注意的是PUT需要对一个具体的资源进行操作也就是要确定id才能进行更新/创建,而POST是可以针对整个资源集合进行操作的,如果不写id就由ES生成一个唯一id进行创建新文档,如果填了id那就针对这个id的文档进行创建/更新
- PUT只会将json数据都进行替换, POST只会更新相同字段的值
- PUT与DELETE都是幂等性操作, 即不论操作多少次, 结果都一样
查询应用
Restful风格
Restful是一种面向资源的架构风格,可以简单理解为:使用URL定位资源,用HTTP动词(GET,POST,DELETE,PUT)描述操作。 基于Restful API ES和所有客户端的交互都是使用JSON格式的数据.其他所有程序语言都可以使用RESTful API,通过9200端口的与ES进行通信
-
GET查询
-
PUT添加
-
POST修改
-
DELETE删除
使用Restful的好处
-
透明性,暴露资源存在。
-
充分利用 HTTP 协议本身语义,不同请求方式进行不同的操作
请求体查询
- 查询当前类型中的所有文档
格式: GET /索引名称/类型/_search
GET /es_dbtest/_doc/_search
SQL: select * from student
- 条件查询
如要查询age等于28岁的
格式: GET /索引名称/类型/_search?q=age:28
GET /es_dbtest/_doc/_search?q=age:28
SQL: select * from student where age = 28
- 范围查询
如要查询age在25至26岁之间的
格式: GET /索引名称/类型/_search?q=age[25 TO 26] 注意: TO 必须为大写,
GET /es_dbtest/_doc/_search?q=age[25 TO 26]
SQL: select * from student where age between 25 and 26
- 根据多个ID进行批量查询 _mget
格式: GET /索引名称/类型/_mget ,相当于SQL
GET /es_dbtest/_doc/_mget{ "ids":["2","3"] }
SQL: select * from student where id in (2,3)
- 查询年龄小于等于28岁的 :<=
格式: GET /索引名称/类型/_search?q=age:<=28
GET /es_dbtest/_doc/_search?q=age:<=28
SQL: select * from student where age <= 28
- 查询年龄大于28前的 :>
格式: GET /索引名称/类型/_search?q=age:>26
GET /es_dbtest/_doc/_search?q=age:>26
SQL: select * from student where age > 28
- 分页查询
格式: GET /索引名称/类型/_search?q=age[25 TO 26]&from=0&size=1
GET /es_dbtest/_doc/_search?q=age[25 TO 26]&from=0&size=1
SQL: select * from student where age between 25 and 26 limit 0, 1
- 对查询结果只输出某些字段
格式: GET /索引名称/类型/_search?__source=字段,字段
GET /es_dbtest/_doc/_search?_source=name,age
SQL: select name,age from student
- 对查询结果排序
格式: GET /索引名称/类型/_search?sort=字段 desc
GET /es_dbtest/_doc/_search?sort=age:desc
SQL: select * from student order by age desc

查询搜索
我们实际场景很少使用到上面请求体查询,更多会使用基于body内容的搜索功能,我们这里就不一一举例,有兴趣学习伙伴可以参照官网学习

GET /es_dbtest/_doc/_search
{
"query":{
"match": {
"name" : "张三三"
}
}
}
GET /es_dbtest/_doc/_search
{
"sort":[
{
"age": {
"order":"asc"
}
}
],
"from": 0,
"size": 2
}
GET /es_dbtest/_doc/_search
{
"term" : {
"age" : 18
}
}
GET /es_dbtest/_doc/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"age" : 18
}
}
}
}
}
GET /es_dbtest/_doc/_search
{
"query" : {
"constant_score" : {
"filter" : {
"range" : {
"age" : {
"gte" : 5,
"lt" : 40
}
}
}
}
},
"sort":[
{
"age": {
"order":"asc"
}
}
],
"from": 0,
"size": 2
}
GET /es_dbtest/_doc/_search
{
"query": {
"bool": {
"must": {
"match": {
"age": 18
}
},
"filter": {
"term": {
"sex": 2
}
}
}
}
}
可以针对结果进行高亮显示
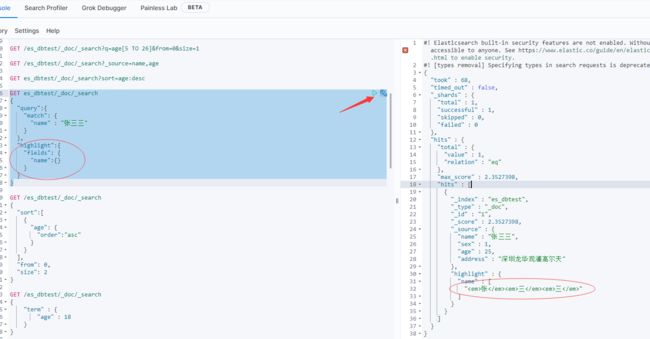
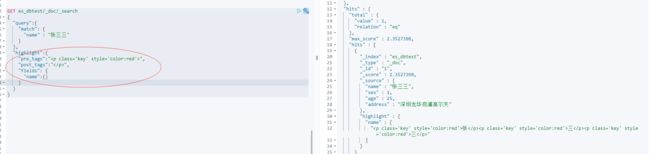
自定义搜索高亮
批量获取文档数据
通过_mget的API来实现的
- 请求方式:GET
- 请求地址:_mget
- 请求参数:
- 请求地址:_mget 在URL中不指定index和type
- 请求地址:/{{indexName}}/_mget 在URL中指定index
- 请求地址:/{{indexName}}/{{typeName}}/_mget 在URL中指定index和type
-
- docs : 文档数组参数
-
-
- _index : 指定index
- _type : 指定type
- _id : 指定id
- _source : 指定要查询的字段
-
bulk Api批量操作文档数据
批量对文档进行操作是通过_bulk的API来实现的
-
可以批量对多个索引进行增加或者删除等操作,减少网络请求次数,可以显著的提高索引的速度。
-
CURD只能对单条数据进行操作,如果是数据导入的情况下QPS会特别高。
-
多个API操作之间的结果互不影响。
-
bulk操作不能进行代码换行
-
bulk会将要处理的数据载入内存中,所以数据量是有限的,最佳的数据两不是一个确定的数据,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载,一般建议是1000-5000个文档,大小建议是5-15MB,默认不能超过100M
-
请求方式:POST
-
请求地址:_bulk
-
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
-
- 第一行参数为指定操作的类型及操作的对象(index,type和id)
- 第二行参数才是操作的数据
-
actionName:表示操作类型,主要有create,index,delete和update
| action(行为) | desc(描述) |
|---|---|
| create | 文档不存在时,创建 |
| update | 更新文档 |
| index | 创建新文档,或者替换已经有的文档 |
| delete | 删除一个文档 |
{"actionName":{"_index":"indexName", "_type":"typeName","_id":"id"}}{"field1":"value1", "field2":"value2"}
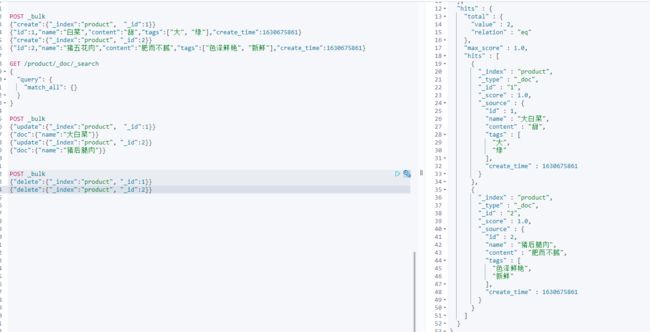
(1)批量创建文档create
POST _bulk
{"create":{"_index":"product", "_id":1}}
{"id":1,"name":"白菜","content":"甜","tags":["大", "绿"],"create_time":1630675861}
{"create":{"_index":"product", "_id":2}}
{"id":2,"name":"猪五花肉","content":"肥而不腻","tags":["色泽鲜艳", "新鲜"],"create_time":1630675861}
(2)批量修改update
POST _bulk
{"update":{"_index":"product", "_id":1}}
{"doc":{"name":"大白菜"}}
{"update":{"_index":"product", "_id":2}}
{"doc":{"name":"猪后腿肉"}}
(3)批量删除delete
POST _bulk
{"delete":{"_index":"product", "_id":1}}
{"delete":{"_index":"product", "_id":2}}
Spring Boot ES操作示例
概述
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html
找到官方提供客户端使用文档

简单示例程序
本示例主要基于Spring Data的启动器spring-boot-starter-data-elasticsearch为核心,构建一个简单Spring Boot程序
pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itxs</groupId>
<artifactId>elasticsearch-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.5.2</version>
</parent>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<elasticsearch.version>7.14.1</elasticsearch.version>
</properties>
<repositories>
<repository>
<id>es-snapshots</id>
<name>elasticsearch snapshot repo</name>
<url>https://snapshots.elastic.co/maven/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
</dependencies>
</project>
application.yml文件
spring: elasticsearch: rest: uris: http://192.168.50.94:9200
当然也可以使用配置类的方式,下面ElasticSearchClientConfig.java是例子
package com.itxs.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.50.94", 9200, "http")));
return client;
}
}
创建实体类User
package com.itxs.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private String name;
private Integer age;
private String address;
}
测试类
package com.itxs;
import com.alibaba.fastjson.JSON;
import com.itxs.pojo.User;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.core.TimeValue;
import org.elasticsearch.search.fetch.subphase.FetchSourceContext;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
@Slf4j
public class ElasticSearchTest {
private static String USER_INDEX_CONST ="user_index";
@Autowired
RestHighLevelClient restHighLevelClient;
//创建索引库
@Test
public void CreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest(USER_INDEX_CONST);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
log.info("创建索引:{}",createIndexResponse);
}
//检查索引库是否存在
@Test
public void GetIndexExists() throws IOException {
GetIndexRequest request = new GetIndexRequest(USER_INDEX_CONST);
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
log.info("获取索引是否成功:{}",exists);
}
//删除索引库
@Test
public void DeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest(USER_INDEX_CONST);
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
log.info("删除索引是否成功:{}",delete.isAcknowledged());
}
//索引库里添加文档
@Test
public void AddDocument() throws IOException {
User user = new User("段乐乐", 20, "北京朝阳");
IndexRequest request = new IndexRequest(USER_INDEX_CONST);
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
log.info("返回值内容:{},状态:{}",indexResponse.toString(),indexResponse.status());
}
//索引库里检查文档是否存在
@Test
public void GetDocumentExists() throws IOException {
GetRequest getRequest = new GetRequest(USER_INDEX_CONST, "1");
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
log.info("文档内容是否存在:{}",exists);
}
//查询索引库里文档内容
@Test
public void GetDocument() throws IOException {
GetRequest getRequest = new GetRequest(USER_INDEX_CONST, "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
log.info("文档内容:{},全部内容:{}",getResponse.getSourceAsString(),getResponse);
}
//更新索引库里文档内容
@Test
public void UpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest(USER_INDEX_CONST, "1");
updateRequest.timeout(TimeValue.timeValueSeconds(1));
User user = new User("张三丰", 18, "上海浦东");
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
log.info("更新文档结果状态:{}",updateResponse.status());
}
//删除索引库里文档内容
@Test
public void DeleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(USER_INDEX_CONST, "1");
deleteRequest.timeout(TimeValue.timeValueSeconds(1));
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
log.info("删除文档结果状态:{}",deleteResponse.status());
}
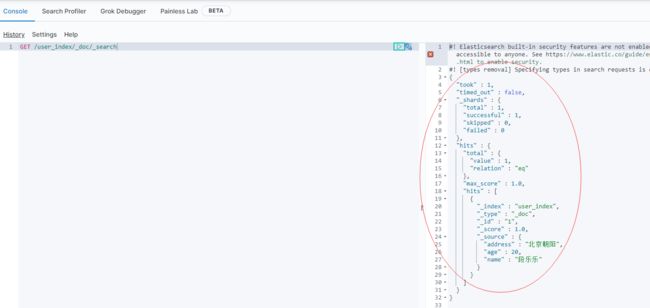
@Test
public void BulkDocument() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout(TimeValue.timeValueSeconds(1));
List<User> userList = new ArrayList<>();
userList.add(new User("韩梅梅",22,"长沙"));
userList.add(new User("马涛涛",25,"成都"));
userList.add(new User("李南",28,"南昌"));
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(new IndexRequest(USER_INDEX_CONST).id(""+ (i+10)).source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
log.info("批量添加文档结果状态:{}",bulk.status());
}
}


Elastic Stack(待续)
The Elastic Stack官方地址 https://www.elastic.co/cn/elastic-stack/
Elastic Stack核心产品包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elasticsearch是位于Elastic Stack核心的分布式搜索和分析引擎,Logstash和Beats有助于收集、聚合和丰富数据,并将其存储在Elasticsearch中。Kibana使您能够交互式地探索、可视化和共享对数据的见解,并管理和监控堆栈。Elasticsearch是索引、搜索和分析魔术发生的地方
本篇只是入门,下篇我们再来学习Elasticsearch进阶内容和ELK等Elastic Stack技术栈研究已经基于搜索引擎的项目实战,希望一起学习的伙伴觉得不错的可以关注下本人的博客网站