初识 Elasticsearch7.16.x(二)
什么是 REST 接口
相信很多做过微服务架构的开发者来说,你们可能对 REST 接口再熟悉不过了。
REST 即表述性状态传递(英文:Representational State Transfer,简称 REST)是 Roy Fielding 博士在2000年他的博士论文中提出来的一种软件架构风格。REST 是一种规范。即参数通过封装后进行传递,响应也是返回的一个封装对象。一个 REST 的接口就像如下的接口:
http://example.com/user/1
我们可以通过:
HTTP GET
HTTP POST
HTTP PUT
HTTP DELETE
HTTP PATCH
来对数据进行增加(Create),查询(Read),更新(Update)及删除(Delete)。也就是我们通常说是的 CRUD。
Elasticsearch 里的接口都是通过 REST 接口来实现的。
回顾概念
索引 Index
一个索引就是一个拥有几分相似的文档的集合。 比如说,你可以有一个商品数据的索引,一个订单数据的索引,还有一个用户数据的索引。一个索引由一个名字来标识(必须全都是小写字母的),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
映射 Mapping
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。 在默认配置下,ES可以根据插入的数据**自动地创建mapping,也可以手动创建mapping。**mapping中主要包含字段名、文档类型等
文档 Document
文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元。 ES中的文档采用了轻量级的JSON格式数据来表示。
基本操作
索引 Index
创建 PUT
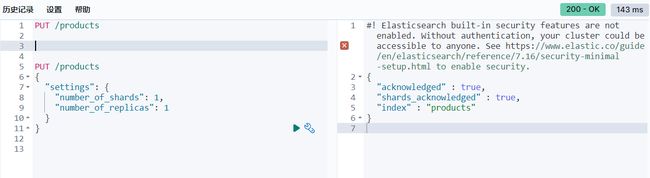
# 1. 创建索引
PUT /索引名
# 2. 创建索引并进行索引分片配置
PUT /索引名
{
"settings": {
"number_of_shards": 1, # 指定主分片的数量
"number_of_replicas": 1 # 指定副本分片的数量
}
}
查看 GET
# 查看 es 中所有索引
GET /_cat/indices
注意:
- ES中索引健康状态:red(索引不可以)、yellow(索引可用,存在风险)、green(健康)。
- 默认ES在创建索引时会为索引创建一个副本索引和一个主索引。
删除 DELETE
# 删除索引
DELETE /索引名
当我们执行完这一条语句后,所有的在索引中的所有的文档都将被删除。
映射 Mapping
创建 PUT
Elasticsearch 的数据类型
- text:全文搜索字符串
- keyword:用于精确字符串匹配和聚合
- date 及 date_nanos:格式化为日期或数字日期的字符串
- byte, short, integer, long:整数类型
- boolean:布尔类型
- float,double,half_float:浮点数类型
有关 Elasticsearch 的数据类型,可以参考链接。
# 创建索引和映射
PUT /products
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"title": {
"type": "keyword"
},
"price": {
"type": "double"
},
"created_at": {
"type": "date"
},
"description": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
查看 GET
# 查看某个索引的映射信息
GET /products/_mapping
文档 Document
创建 PUT
# 1. 指定文档id
POST /products/_doc/1
## 示例
POST /products/_doc/1
{
"title": "元旦快乐",
"price": 9999.99,
"created_at": "2022-01-01",
"description": "新年快乐,元旦快乐"
}
如果指定文档id,当多次执行后,可以看到响应的版本(_version)会自动加1,之前的版本被抛弃。如果这个不是我们想要的,那么我们可以使用 _create 接口来实现:
# 如果文档已经存在的话,我们会收到一个错误的信息
PUT /products/_create/1
{
"title": "元旦快乐",
"price": 9999.99,
"created_at": "2022-01-01",
"description": "新年快乐,元旦快乐"
}
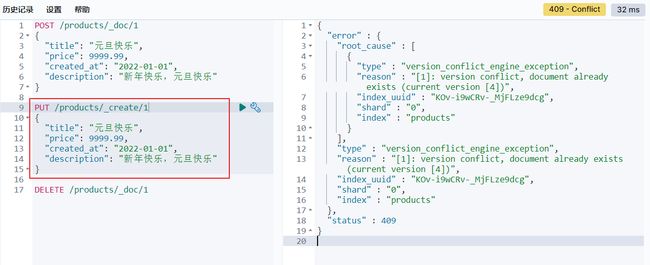
在上面,我特意为我们的文档分配了一个 ID。其实在实际的应用中,这个并不必要。相反,当我们分配一个 ID 时,在数据导入的时候会检查这个 ID 的文档是否存在,如果是已经存在,那么就更新到版本。如果不存在,就创建一个新的文档。如果我们不指定文档的 ID,转而让 Elasticsearch 自动帮我们生成一个 ID,这样的速度更快。在这种情况下,我们必须使用 POST,而不是 PUT。比如:
# 2. 自动生成文档id
POST /products/_doc
# 示例
POST /products/_doc/
{
"title": "元旦快乐2",
"price": 9999.98,
"created_at": "2022-01-02",
"description": "新年快乐,元旦快乐2"
}
查看 GET
在 Elasticsearch 7.0 之后,在 type 最终要被废除的情况下,所以省略_doc
# 1. 查询索引下文档
GET /products/_search
# 2. 按id查询
GET /products/1
如果我们只想得到这个文档的 _source 部分,我们可以使用如下的命令格式:
# 查看_source部分
GET /products/_source/1
删除 DELETE
# 按id删除文档
DELETE /products/_doc/1
在关系数据库中,我们通常是对数据库进行搜索,让后才进行删除。在这种情况下,我们事先通常并不知道文档的 id。我们需要通过查询的方式来进行查询,让后进行删除。ES 也提供了相应的 REST 接口。
# 查询后删除文档
POST products/_delete_by_query
{
"query": {
"match": {
"title": "新年"
}
}
}
这样我们就把所有的 title 是新年的文档都删除了。
更新 POST
当修改一个文档时,我们通常会使用 PUT 来进行操作,并且,我们需要指定一个指定的 id 来进行修改:
# 说明:这种更新方式是先删除原始文档,再将更新文档以新的内容创建
PUT /products/_doc/1
{
"price": 8888.88
}
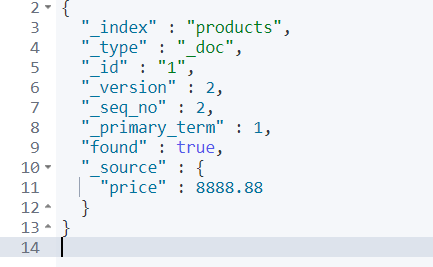
我们使用 PUT 的这个方法,每次修改一个文档时,我们需要把文档的每一项都要写出来。这对于有些情况来说,并不方便,我们可以使用如下的方法来进行修改:
# 说明:这种更新方式可以保存原始数据,并在此基础进行更新
POST /products/_update/1/
{
"doc": {
"price": 666.66
}
}

批量操作 POST
上面我们已经了解了如何使用 REST 接口来创建一个 index,并为之创建,读取,修改,删除文档(CRUD)。因为每一次操作都是一个 REST 请求,对于大量的数据进行操作的话,这个显得比较慢。ES 创建一个批量处理的命令给我们使用。这样我们在一次的 REST 请求中,我们就可以完成很多的操作。这无疑是一个非常大的好处。下面,我们来介绍一下这个 _bulk 命令。
# 批量创建文档(注意格式)
POST /products/_bulk
{"index": {"_id": "3"}}
{"title": "元旦快乐3","price": 9999.33,"created_at": "2022-01-03","description": "新年快乐,元旦快乐3"}
{"index": {"_id": "4"}}
{"title": "元旦快乐4","price": 9999.44,"created_at": "2022-01-04","description": "新年快乐,元旦快乐4"}
注意:在输入命令时,我们需要特别的注意:千万不要添加除了换行以外的空格,否则会导致错误。
有时候我们想知道一个文档是否存在,我们可以使用如下的方法:
HEAD products/_doc/1
其他
_count
我们可以通过使用 _count 命令来查询有多少条数据:
GET products/_count
{
"count" : 2,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
_settings
我们可以通过如下的接口来获得一个 index 的 settings
GET /products/_settings
从这里我们可以看到我们的 products 索引有多少个 shards 及多少个 replicas。我们也可以通过如下的接口来设置:
PUT products
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
一旦我们把 number_of_shards 定下来了,我们就不可以修改了,除非把 index 删除,并重新 index 它。这是因为每个文档存储到哪一个 shard 是和 number_of_shards这个数值有关的。一旦这个数值发生改变,那么之后寻找那个文档所在的 shard 就会不准确。
_mapping
Elasticsearch 号称是 schemaless,在实际所得应用中,每一个 index 都有一个相应的 mapping。这个 mapping 在我们生产第一个文档时已经生产。它是对每个输入的字段进行自动的识别从而判断它们的数据类型。我们可以这么理解 schemaless:
- 不需要事先定义一个相应的 mapping 才可以生产文档。字段类型是动态进行识别的。这和传统的数据库是不一样的
- 如果有动态加入新的字段,mapping 也可以自动进行调整并识别新加入的字段
自动识别字段有一个问题,那就是有的字段可能识别并不精确,比如对于我们例子中的位置信息。那么我们需要对这个字段进行修改。
我们可以通过如下的命令来查询目前的 index 的 mapping:
GET products/_mapping
注意:我们不能为已经建立好的 index 动态修改 mapping。这是因为一旦修改,那么之前建立的索引就变成不能搜索的了。一种办法是 reindex 从而重新建立我们的索引。如果在之前的 mapping 加入新的字段,那么我们可以不用重新建立索引。
为了能够正确地创建我们的 mapping,我们必须先把之前的 products 索引删除掉,并同时使用 settings 来创建这个 index。具体的步骤如下:
# 删除索引
DELETE products
# 创建索引
PUT products
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
}
}
# 指定映射
PUT products/_mapping
{
"properties": {
"description": {
"type": "text",
"analyzer": "ik_max_word"
},
"created_at": {
"type": "date"
},
"price": {
"type": "double"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
filter_path
我们可以通过 filter_path 来控制输出的较少的字段,比如:
GET /products/_search?filter_path=hits.total
{
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
}
}
}
fields
在实际的使用中,我们可以使用 fields 来指定返回的字段,而不用 _source。这样做更加高效。上面的搜索可以写成如下的格式:
# 我们可以可以通过设置 _source 为 false,这样不返回任何的 _source 信息
GET /products/_search
{
"_source": false,
"fields": [
"title",
"description"
],
"query": {
"match_all": {}
}
}
详细阅读,可以参阅文章 “Elasticsearch:从搜索中获取选定的字段 fields”。
查询示例
说明
ES中提供了一种强大的检索数据方式,这种检索方法称之为 Query DSL,利用Rest API传递JSON格式的请求体数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大、更简洁。
语法
GET /索引名/_doc/_search
{
json格式请求体数据
}
查询文档
# 查询所有文档
GET /products/_search
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : { // 命中信息
"total" : { // 总条数信息
"value" : 2, // 命中2条
"relation" : "eq"
},
"max_score" : 1.0, // 命中最高得分
"hits" : [
{
"_index" : "products", // 索引
"_type" : "_doc", // 类型
"_id" : "6nEkHn4B51yzcdzVsU8y", // 主键
"_score" : 1.0, // 表示我们搜索结果的相关度。这个分数值越高,表明我们搜索匹配的相关度越高
"_source" : { // 文档详情
"title" : "元旦快乐2",
"price" : 9999.98,
"created_at" : "2022-01-02",
"description" : "新年快乐,元旦快乐2"
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "元旦快乐",
"price" : 666.66,
"created_at" : "2022-01-01",
"description" : "新年快乐,元旦快乐"
}
}
]
}
}
在上面,我们可以看到 relation 字段的值为 eq,它表明搜索的结果为2个文档。这也是满足条件的所有文档,但是针对许多的大数据搜索情况,有时我们的搜索结果会超过10000个,那么这个返回的字段值将会是 gte:
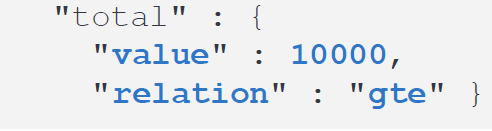
它表明搜索的结果超过 10000。如果我们想得到所有的结果,我们需要参考文章 “如何在搜索时得到精确的总 hits 数”。
# 查询指定id文档
GET /products/1
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_version" : 5,
"_seq_no" : 5,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "元旦快乐",
"price" : 666.66,
"created_at" : "2022-01-01",
"description" : "新年快乐,元旦快乐"
}
}
常见索引
查询数据(match)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query.html
# 返回索引中适合的数据,text会分词
GET /products/_search
{
"query": {
"match": {
"description": "元旦"
}
}
}
## 或者
GET /products/_search
{
"query": {
"match": {
"description": {
"query": "元旦新年 Happy birthday",
"operator": "or",
"minimum_should_match": 2
}
}
}
}
## 提高权重
GET /products/_search
{
"query": {
"match": {
"description": {
"query": "元旦",
"boost": 3
}
}
}
}
- 在我们使用 match query 时,默认的操作是 OR,如果想提高精度,可以改为 AND。
- 我们也可以设置参数 minimum_should_match 来设置至少匹配的 term,达到控制精度效果,我们可以将其设置为某个具体数字(2),更常用的做法是将其设置为一个百分数(75%),因为我们无法控制用户搜索时输入的单词数量。
- Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。
- 我们可以通过指定
boost来控制任何查询语句的相对的权重,boost的默认值为1,大于1会提升一个语句的相对权重。
查询数据(match_phrase)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-match-query-phrase.html
就像 match 查询对于标准全文检索是一种最常用的查询一样,当你想找到彼此邻近搜索词的查询方法时,就会想到 match_phrase 查询。
GET /products/_search
{
"query": {
"match_phrase": {
"description": "Happy birthday"
}
}
}
在这里,我们可以看到我们使用了match_phrase。它要求 Happy后面必须是birthday才符合要求。
模糊匹配
精确短语匹配 或许是过于严格了。也许我们想要包含 Happy new birthday 的文档也能够匹配 Happy birthday , 尽管情形不完全相同。
GET /products/_search
{
"query": {
"match_phrase": {
"description": {
"query": "Happy birthday",
"slop": 1
}
}
}
}
slop 参数告诉 match_phrase 查询词条相隔多远时仍然能将文档视为匹配 。 相隔多远的意思是为了让查询和文档匹配你需要移动词条多少次?
我们以一个简单的例子开始吧。 为了让查询 quick fox 能匹配一个包含 quick brown fox 的文档, 我们需要 slop 的值为 1:
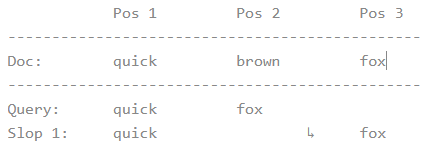
尽管在使用了 slop 短语匹配中所有的单词都需要出现, 但是这些单词也不必为了匹配而按相同的序列排列。 有了足够大的 slop 值, 单词就能按照任意顺序排列了。
为了使查询 fox quick 匹配我们的文档, 我们需要 slop 的值为 3:

注意:fox 和 quick 在这步中占据同样的位置。 因此将 fox quick 转换顺序成 quick fox 需要两步, 或者值为 2 的 slop 。
查询所有(match_all)
# 返回索引中的全部文档
GET /products/_search
{
"query": {
"match_all": {}
}
}
SELECT * FROM products
在这里,我们可以看到,这跟GET /products/_search的结果没有区别,可以简单理解为简写。
关键词查询(term)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html
Term query 会在给定字段中进行精确的字词匹配。 因此,您需要提供准确的术语以获取正确的结果。
# 使用关键词查询
# 1. 对于keyword或其他类型,不进行分词并查询
# 2. 只有text类型,进行分词并查询
GET /products/_search
{
"query": {
"term": {
"title": {
"value": "元旦快乐"
}
}
}
}
SELECT * FROM products WHERE title = '元旦快乐'
通常当查找一个精确值的时候,我们不希望对查询进行评分计算。只希望对文档进行包括或排除的计算,所以我们会使用 constant_score 查询以非评分模式来执行 term 查询并以一作为统一评分。
最终组合的结果是一个 constant_score 查询,它包含一个 term 查询:
GET /products/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"title": "元旦快乐"
}
}
}
}
}
查询置于 filter 语句内不进行评分或相关度的计算,所以所有的结果都会返回一个默认评分 1
关键词查询(terms)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-terms-query.html
term 查询对于查找单个值非常有用,但通常我们可能想搜索多个值,应该怎么处理呢?
不需要使用多个 term 查询,我们只要用单个 terms 查询(注意末尾的 s ), terms 查询好比是 term 查询的复数形式(以英语名词的单复数做比)。
它几乎与 term 的使用方式一模一样,与指定单个价格不同,我们只要将 term 字段的值改为数组即可:
GET /products/_search
{
"query": {
"terms": {
"title": [
"元旦",
"快乐",
"元旦快乐"
]
}
}
}
一定要了解 term 和 terms 是 包含(contains) 操作,而非 等值(equals) (判断)。
范围查询(range)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-range-query.html
在 ES 中,我们可以对数字或日期进行范围查询。我们可以根据设定的范围来对数据进行查询:
# 查询指定范围的文档
GET /products/_search
{
"query": {
"range": {
"price": {
"gte": 1000,
"lte": 10000
}
}
}
}
SELECT * FROM products WHERE price BETWEEN 1000 AND 10000
range 查询可同时提供包含(inclusive)和不包含(exclusive)这两种范围表达式,可供组合的选项如下:
gt:>大于(greater than)lt:<小于(less than)gte:>=大于或等于(greater than or equal to)lte:<=小于或等于(less than or equal to)
前缀查询(prefix)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-prefix-query.html
prefix 查询是一个词级别的底层的查询,它不会在搜索之前分析查询字符串,它假定传入前缀就正是要查找的前缀。
默认状态下,
prefix查询不做相关度评分计算,它只是将所有匹配的文档返回,并为每条结果赋予评分值1。它的行为更像是过滤器而不是查询。prefix查询和prefix过滤器这两者实际的区别就是过滤器是可以被缓存的,而查询不行。
# 检索包含指定前缀的文档
GET /products/_search
{
"query": {
"prefix": {
"title": {
"value": "元旦"
}
}
}
}
# 您可以通过组合 和 value 参数来简化前缀查询语法。
GET /products/_search
{
"query": {
"prefix": {
"title": "元旦"
}
}
}
SELECT * FROM products WHERE title like '元旦%'
通配符查询(wildcard)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-wildcard-query.html
与 prefix 前缀查询的特性类似, wildcard 通配符查询也是一种底层基于词的查询,与前缀查询不同的是它允许指定匹配的正则式。
它使用标准的 shell 通配符查询: ? 匹配任意字符, * 匹配 0 或多个字符。
# 通配符查询
GET /products/_search
{
"query": {
"wildcard": {
"title": {
"value": "*元旦*"
}
}
}
}
SELECT * FROM products WHERE title like '%元旦%'
多id查询(ids)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-ids-query.html
根据文档ID返回文档。此查询使用存储在 _id 字段中的文档id。
# 值为数组类型,根据一组id获取多个对应的文档
GET /products/_search
{
"query": {
"ids": {
"values": ["1", "73F7Hn4B51yzcdzVw0_G"]
}
}
}
SELECT * FROM products WHERE id in ('1', '73F7Hn4B51yzcdzVw0_G')
模糊查询(fuzzy)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-fuzzy-query.html
用来模糊查询含有指定关键词的文档
# 用来模糊查询含有指定关键词的文档
GET /products/_search
{
"query": {
"fuzzy": {
"description": "新年快落"
}
}
}
- 最大模糊错误,必须在0-2之间
- 搜索关键词长度为2,不允许存在模糊
- 搜索关键词长度为3-5,允许一次模糊
- 搜索关键词大于5,允许最多两次模糊
复合过滤器(compound filter)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/compound-queries.html
布尔过滤器
一个 bool 过滤器由三部分组成:
{
"bool" : {
"must" : [],
"should" : [],
"must_not" : [],
"filter" : [],
}
}
must
所有的语句都 必须(must) 匹配,与 AND 等价,并计算评分。
must_not
所有的语句都 不能(must not) 匹配,与 NOT 等价。 子句在过滤器上下文中执行,这意味着忽略评分并考虑缓存子句。 因为忽略了评分,所以返回所有文档的 0 分。
should
至少有一个语句要匹配,与 OR 等价,并计算评分。
-
filter和
must类似,但查询的分数将被忽略。过滤器子句在过滤器上下文中执行,这意味着忽略评分并考虑缓存子句。因为忽略了评分,所以返回所有文档的 0 分。
就这么简单! 当我们需要多个过滤器时,只须将它们置入 bool 过滤器的不同部分即可。
一个
bool过滤器的每个部分都是可选的(例如,我们可以只有一个must语句),而且每个部分内部可以只有一个或一组过滤器。
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"description": "元旦快乐"
}
}
],
"must_not": [
{
"term": {
"price": {
"value": "9999.99"
}
}
}
]
}
}
}
SELECT * FROM products WHERE description = '元旦快乐' AND price != 9999.99
嵌套布尔过滤器
尽管 bool 是一个复合的过滤器,可以接受多个子过滤器,需要注意的是 bool 过滤器本身仍然还只是一个过滤器。 这意味着我们可以将一个 bool 过滤器置于其他 bool 过滤器内部,这为我们提供了对任意复杂布尔逻辑进行处理的能力。
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"description": "新年快乐"
}
},
{
"bool": {
"must": [
{
"term": {
"title": "元旦快乐"
}
},
{
"term": {
"price": "9999.99"
}
}
]
}
}
]
}
}
}
SELECT * FROM products WHERE description = '元旦快乐' OR (title = '元旦快乐' AND price = 9999.99)
- 因为
match和bool过滤器是兄弟关系,他们都处于外层的布尔逻辑should的内部,返回的命中文档至少须匹配其中一个过滤器的条件。 - 这两个
term语句作为兄弟关系,同时处于must语句之中,所以返回的命中文档要必须都能同时匹配这两个条件。
查询类型对 hits 及 _score 的影响
在使用上面的复合查询时,bool 请求通常是 must,must_not, should 及 filter 的一个或其中的几个一起组合形成的。我们必须注意的是:
| Clause | 影响 hits | 影响 _score |
|---|---|---|
| must | Yes | Yes |
| must_not | Yes | No |
| should | No | Yes |
| filter | Yes | No |
多字段查询(multi_match)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-multi-match-query.html
multi_match多匹配查询的类型有多种,其中的三种恰巧与了解我们的数据中介绍的三个场景对应,即:best_fields、most_fields和cross_fields(最佳字段、多数字段、跨字段)。
在上面的搜索之中,我们特别指明一个专有的 field 来进行搜索,但是在很多的情况下,我们并不知道是哪一个 field 含有这个关键词,那么在这种情况下,我们可以使用 multi_match 来进行搜索:
# 对多个字段进行查询
# 如果字段支持分词,则分词查询,如果不支持,则完整查询
GET /products/_search
{
"query": {
"multi_match": {
"query": "元旦",
"fields": ["title", "description^3"],
"type": "best_fields" # 默认
}
}
}
SELECT * FROM products WHERE title = '元旦' OR description = '元旦'
默认情况下,查询的类型是 best_fields ,这表示它会为每个字段生成一个 match 查询,然后将它们组合到 dis_max 查询的内部。
在上面,我们可以同时对两个 fields: title和description进行搜索,但是我们对 description 含有 “元旦” 的文档的分数进行3倍的加权(可以使用 ^ 字符语法为单个字段提升权重,在字段名称的末尾添加 ^boost ,其中 boost 是一个浮点数)。
高亮查询(highlight)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/highlighting.html
突出显示(highlighting)使你能够从搜索结果中的一个或多个字段中获取突出显示的片段,以便向用户显示查询匹配的位置。 当你请求突出显示时,响应包含每个搜索命中的附加突出显示元素,其中包括突出显示的字段和突出显示的片段。
# 可以让符合条件的文档中的关键词高亮
## 使用 pre_tags 和 post_tags 自定义标签
## 使用 require_field_match 开启多个字段高亮
GET /products/_search
{
"query": {
"multi_match": {
"query": "元旦",
"fields": ["title", "description"]
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"description": {}
}
}
}
在上面,要使用默认高亮器在每个搜索命中中获取 description字段的高亮显示,请在请求正文中包含一个 highlight 对象,用于指定内容字段。返回结果如下:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.10745377,
"hits" : [
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.10745377,
"_source" : {
"title" : "元旦快乐",
"price" : 9999.99,
"created_at" : "2022-01-01",
"description" : "新年快乐,元旦快乐"
},
"highlight" : {
"description" : [
"新年快乐,元旦快乐"
]
}
},
{
"_index" : "products",
"_type" : "_doc",
"_id" : "73F7Hn4B51yzcdzVw0_G",
"_score" : 0.099543065,
"_source" : {
"title" : "元旦快乐2",
"price" : 9999.98,
"created_at" : "2022-01-02",
"description" : "新年快乐,元旦快乐2"
},
"highlight" : {
"description" : [
"新年快乐,元旦快乐2"
]
}
}
]
}
}
默认情况下的返回结果,是用 em 来进行高亮显示的。
返回指定条数(size)
# 指定查询结果中返回条数,默认10条
GET /products/_search
{
"query": {
"match_all": {}
},
"size": 5
}
# 或者
GET /products/_search?size=5
{
"query": {
"match_all": {}
}
}
SELECT * FROM products LIMIT 5
分页查询(form)
# 用来指定起始位置,和size关键字一起使用实现分页效果
## 公式:from = (page - 1) * size
GET /products/_search
{
"query": {
"match_all": {}
},
"size": 5,
"from": 0
}
# 或者
GET /products/_search?size=5&from=0
{
"query": {
"match_all": {}
}
}
SELECT * FROM products LIMIT 0,5
指定字段排序(sort)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/sort-search-results.html
# 对指定字段进行排序
GET /products/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
SELECT * FROM products ORDER BY price DESC
返回指定字段(_source)
# 返回指定字段
GET /products/_search
{
"query": {
"match_all": {}
},
"_source": ["title", "description"]
}
处理 Null 值(exists)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-exists-query.html
说明:constant_score 可选
存在查询
可以使用exists查询
GET /products/_search
{
"query": {
"exists": {
"field": "tags"
}
}
}
SELECT * FROM products WHERE tags IS NOT NULL
缺失查询
若要查找缺少字段索引值的文档,请将 must_not 查询与 exists 查询一起使用。
GET /products/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "tags"
}
}
]
}
}
}
SELECT * FROM products WHERE tags IS NULL
位置查询(geo)
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/geo-queries.html
SQL 查询
文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/7.16/xpack-sql.html
对于与很多已经习惯用 RDMS 数据库的工作人员,他们更喜欢使用 SQL 来进行查询。Elasticsearch 也对 SQL 有支持:
GET /_sql?
{
"query": """
SELECT * FROM products
WHERE price > 5000
"""
}
过滤查询
ES中的查询操作分为两种:查询(query)和过滤(filter)。查询即是之前提到的query查询,默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算得分,而且它可以缓存文档。所以,单从性能考虑,过滤比查询更快。
换句话说过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时,应先使用过滤,后使用查询。
语法
# 如果 filter 和 query 同时存在,会先执行 filter,后执行 query
# es会自动缓存经常使用的过滤器,以加快性能
GET /products/_search
{
"query": {
"bool": {
# 查询条件
"must": [
{
"match_all": {}
}
],
# 过滤条件
"filter": [
{}
]
}
}
}
类型
常见的过滤类型有term、terms、range、exists、ids等
term、terms
# term单个过滤,terms多个过滤后,再进行查询
# term filter用法与查询一致
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"term": {
"description": "元旦"
}
}
]
}
}
}
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"terms": {
"description": [
"新年",
"元旦"
]
}
}
]
}
}
}
range
# 按范围过滤后,再进行查询
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"range": {
"price": {
"gte": 1000,
"lte": 10000
}
}
}
]
}
}
}
exists
# 获取字段不为空的索引记录
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"exists": {
"field": "description"
}
}
]
}
}
}