【Elasticsearch】基础概念(一)
简介:Elasticsearch(ES)是一个开源的分布式搜索和分析引擎,用于快速存储、搜索和分析大量数据。它具有高性能、可扩展性和灵活性的特点,被广泛用于构建实时搜索、日志分析、数据可视化等应用。
本人主要介绍Elasticsearch(ES)的部署方式和基础概念知识,使用docker compose搭建ES+Kibana环境,对ES中索引和类型进行的介绍。对后续检索等功能铺垫。
一、环境准备
版本
Docker version 20.10.22
elasticsearch:7.13.3
kibana:7.13.3
部署方式
docker-compose部署
version: '3.1'
services:
elasticsearch:
image: elasticsearch:7.13.3
container_name: elasticsearch
privileged: true
environment:
- "cluster.name=elasticsearch" #设置集群名称为elasticsearch
- "discovery.type=single-node" #以单一节点模式启动
- "ES_JAVA_OPTS=-Xms512m -Xmx1096m" #设置使用jvm内存大小
- bootstrap.memory_lock=true
volumes:
- ./es/plugins:/usr/local/dockercompose/elasticsearch/plugins #插件文件挂载
- ./es/data:/usr/local/dockercompose/elasticsearch/data:rw #数据文件挂载
- ./es/logs:/usr/local/dockercompose/elasticsearch/logs:rw
ports:
- 9200:9200
- 9300:9300
deploy:
resources:
limits:
cpus: "2"
memory: 1000M
reservations:
memory: 200M
kibana:
image: kibana:7.13.3
container_name: kibana
depends_on:
- elasticsearch #kibana在elasticsearch启动之后再启动
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200 #设置访问elasticsearch的地址
I18N_LOCALE: zh-CN
ports:
- 5601:5601
访问地址
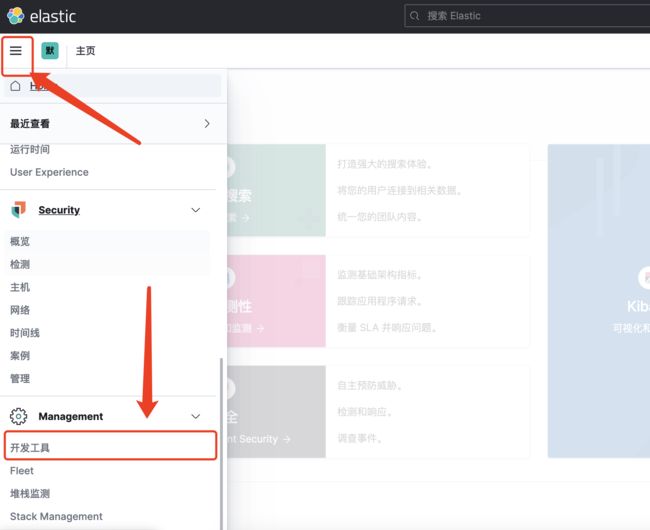
如图点击菜单栏,跳转到命令页面
地址:http://localhost:5601/app/home#/
二、基础概念
分片和副本
分片
索引分片就是把索引数据切分成多个小的索引块,这些小的索引块能够分发到同一个集群中的不同节点。
副本
分片副本用来应对不断攀升的吞吐量以及确保数据的安全性。
过度分片
在检索时,检索的结果是该索引每个分片上检索结果的总和。(假设查询10条数据,有5个分片,数据库实际输出了50条数据,取前10条实现的)对于数据量少的索引,这样无疑增加了工作量。但是在ES中创建了索引后,不允许进行修改,如果想修改只能新建索引通过导入的方式到新索引中。
分片数不宜太多也不能太少,一个简单的索引计算公式:
最大节点数 = 分片数 * (副本数 + 1)
换句话说,如果你计划用10个分片和2个分片副本,那么最大的节点数是30。
Index与Type
有人说index对应database,type对应table,其实是不准确的,最好不要与MySQL进行对应记忆。以一个问题来表述:
要存储一批新的数据时,应该在已有 index 里新建一个 type,还是给它新建一个 index?
Index
index的分片中,每一个都是一个Lucene Index,都需要消耗磁盘,内存和文件描述符。因此,一个大的 index 比多个小 index 效率更高:Lucene Index 的固定开销被摊分到更多文档上了。
多个index每个index还有分片的情况,在查询时需要更多的CPU和内存来处理查询结果,所以 index 少一点间接提高性能。
Type
在Elasticsearch 7.x 后,type已经正式废除,新增时会自动添加类型 _doc。
从另外一个角度来讲:
- 在index创建多个type,不同type间字段是相同的,会影响查询结果分数和多冗余字段。
- es对冗余出的空字段支持不高,会影响性能。
与MySQL对应概念(不推荐)
| ElasticSearch | MySQL |
|---|---|
| Index(索引) | Database(数据库) |
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(属性) | Column(列) |
| Mapping | Schema |
三、字段类型
ES中的字段类型
一般使用常用字段中的前四个。
- 常用字段:
- Text:存储长文本或短语,进行全文本搜索。
- Keyword:存储关键字、标签或其他短文本,用于精确匹配和排序。
- Date:存储日期和时间信息。
- Long:存储长整型数据。
- Double:存储双精度浮点数数据。
- Boolean:存储布尔值。
- IP:存储IP地址。
- 其他字段:
- Object:存储一个 JSON 对象,可以嵌套其他字段。
- Nested:存储一个数组对象,可以嵌套其他字段。
- Geo Point:存储经纬度坐标信息,用于地理位置相关的查询。
- Geo Shape:存储复杂的地理形状数据,例如多边形和圆形。
- Completion:用于实现搜索建议和自动完成功能。
- Binary:存储二进制数据,如图像、文件等。
- Array:存储数组或多个值。
四、索引
创建索引
创建索引,my_test_index,分别有三个字段id、name、remark
PUT:代表请求方式为 put 类型
my_test_index:代表索引的名称
number_of_shards:分片数
number_of_replicas:副本数
正如上述所说,put请求是restful请求中的类型,也就是说es支持http请求的方式执行命令,只需在
/前添加es的地址即可。
PUT /my_test_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id": {
"type": "integer"
},
"name": {
"type": "keyword"
},
"remark": {
"type": "text"
}
}
}
}
// 执行结果
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "my_test_index"
}
索引修改
添加字段
注意使用 _mapping 来添加字段
POST /my_test_index/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}
// 执行结果
{
"acknowledged" : true
}
修改字段
es是不允许修改字段的,如下
POST /my_test_index/_mapping
{
"properties": {
"age": {
"type": "keyword"
}
}
}
// 执行结果
{
"error" : {
"root_cause" : [
{
"type" : "illegal_argument_exception",
"reason" : "mapper [age] cannot be changed from type [integer] to [keyword]"
}
],
"type" : "illegal_argument_exception",
"reason" : "mapper [age] cannot be changed from type [integer] to [keyword]"
},
"status" : 400
}
默认添加字段
对索引中没有字段进行保存时,es能够自动添加字段
POST /my_test_index/_doc
{
"id": "1",
"name": "张三",
"gender": "F"
}
// 执行结果
{
"_index" : "my_test_index",
"_type" : "_doc",
"_id" : "8deesYoBBTGuuZu3TwAp",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
通过命令查询es索引信息
再返回结果中发现字段类型为 text,但是还有名为 keyword 的子字段,实际上可以作为两种字段来使用,正常使用当做 text 字段进行全文检索。
当使用时按照 gender.keyword 来使用,字段类型为 keyword,但是长度不能超过256,超过的部分不计作 keyword 内的数据。
GET /my_test_index
// 返回结果
{
"my_test_index" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "integer"
},
"gender" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
// 省略其他字段
}
}
}
}
五、总结
- ES中分片数和副本数需要按照实际情况进行合理分配,参考上述公式。
- ES中的type默认填写_doc即可,相比于index变多不如使index更大更有利于ES查询。
- 记忆ES索引和文档时,尽量不要与MySQL相关概念一起记忆。
- ES在已有索引上只能新增字段可以通过命令或者ES自动创建来实现,不允许修改字段。