MySQL千万级数据深度分页优化
看完此篇文章,你可以对MySQL深度分页有特别透彻的理解,对面试此类问题对答入流。
阿亮出品,必出精品
1.准备工作
1.1建表
#创建一个存储名称的表,因为我是使用mysql8.0版本,所以bigint无需指定长度
CREATE TABLE `tb_name` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`add_time` bigint NOT NULL,
`update_time` bigint DEFAULT NULL,
`del` tinyint NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
KEY `idx_name_del_update` (`name`,`del`,`update_time`) USING BTREE,
KEY `idx` (`update_time`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;1.2新建一个存储过程
建议插入数据前先别建立索引,数据插入完成后再新建,新建数据快一点。
可以在mysql连接工具中开启十几个会话并行执行
#创建一个存储过程方法
CREATE DEFINER=`root`@`localhost` PROCEDURE `test_insert`()
BEGIN
#定义变量
DECLARE i INT DEFAULT 1;
#条件判断
WHILE i<10000000
#执行
DO
#SQL
INSERT INTO `tb_name`(`name`, `add_time`, `update_time`, `del`)
VALUES (CONCAT("itlgitlg",SUBSTRING(MD5(RAND()),1,30)),
(SELECT 1419955200- (FLOOR(1 + (RAND() * 12)) * 2678400) - (FLOOR(1 + (RAND() * 31)) * 86400) - FLOOR(1 + (RAND() * 86400))),
(SELECT 1419955200- (FLOOR(1 + (RAND() * 12)) * 2678400) - (FLOOR(1 + (RAND() * 31)) * 86400) - FLOOR(1 + (RAND() * 86400))), 0);
#变量增加
SET i=i+1;
#结束循环
END WHILE ;
#提交
commit;
#结束
END函数创建成功之后,使用下面命令执行
#执行
CALL test_insert();你会使用到的命令
#查看存储过程
SHOW PROCEDURE STATUS;
#查看创建存储过程的语句
SHOW CREATE PROCEDURE test_insert;
#删除存储过程
DROP PROCEDURE test_insert;准备工作完成后,查看数据是否符合要求
2 sql深度分页优化
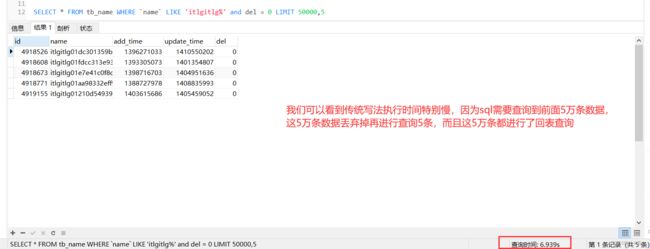
SELECT * FROM tb_name WHERE `name` LIKE 'itlgitlg%' and del = 0 LIMIT 50000,5;sql执行结果如下图,6.9s
现在我们来看看走覆盖索引,速度如下图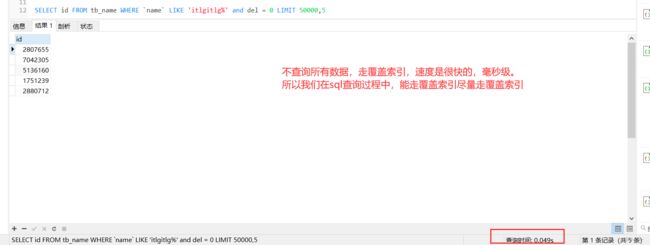
根据上述sql,所以我们可以使用子查询优化
2.1 子查询优化
SELECT * FROM tb_name WHERE id >= (SELECT id FROM tb_name tn WHERE tn.`name`
LIKE 'itlgitlg%' and del = 0 LIMIT 30000,1)
AND `name` LIKE 'itlgitlg%' AND del = 0 LIMIT 5 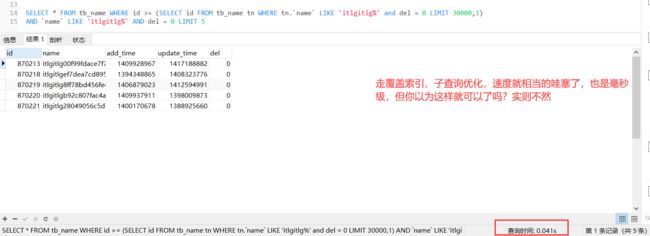
2.2 子查询优化带来的问题
实际项目过程中,我们知道,一般的列表查询,可能会对更新时间或其他字段进行排序,那么排序后还能这么快吗?
子查询优化带排序sql如下
SELECT * FROM tb_name WHERE id >= (SELECT id FROM tb_name tn WHERE tn.`name`
LIKE 'itlgitlg%' and del = 0 ORDER BY update_time LIMIT 30000,1)
AND `name` LIKE 'itlgitlg%' AND del = 0 ORDER BY update_time LIMIT 10 sql执行如下图:
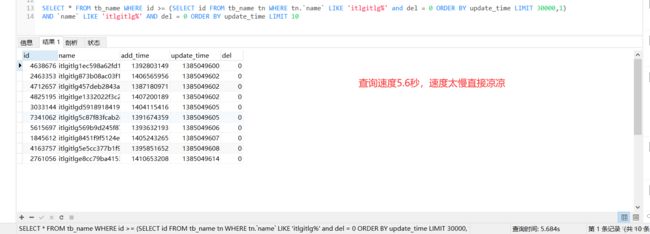
其实这种sql,从根本上来说就是错误的写法,所以我们在看博客的时候,需要自己全新弄一遍才能理解透彻与发现别人的问题。我们既然是根据update_time进行排序查询了,那就不是id大于多少,而是更新时间大于多少。所以在数据库设计中,没有特别要求,时间尽量使用时间戳。
2.3 MySQL的书签查询优化(最终解决方案)
(也有点局限性,随意乱跳页如第一次第1页,第二次50万页,第三次第3页,但是可以避免一直深度慢查询的情况)
既然你是根据update_time进行排序查询的,所以我们可以在分页查询接口添加一个入参。上一次分页查询最后那一条数据的更新时间,也会有一定的局限性。
实际项目中,我们一般以更新时间字段进行降序排序。所以我们如果需要使用mysql进行深度分页,则可以将update_time字段设置为时间戳,update_time字段格式位置为:时间戳+19位永不重复增长id。然后分页sql即可写为
SELECT * FROM tb_name WHERE `name`='itlgitlg9' AND update_time>1400785890 1521425214521456321 ORDER BY update_time LIMIT 10
上一段落标红的字体为:时间戳+19位永不重复增长数,当数据新增或者修改时,会在update_time新生成一个雪花算法id,保证update_time字段不会重复。每次查询的update_time的值为上一次分页的最后一条数据的update_time。
总结

最后有一点需要声明下,MySQL 本身并不适合单表大数据量业务
因为 MySQL 应用在企业级项目时,针对库表查询并非简单的条件,可能会有%itlgcml%模糊查询,此类模糊查询只能够使用倒排索引。大数据量时存在频繁新增或更新操作,维护索引或者数据 ACID 特性上必然存在性能牺牲。
如果设计初期能够预料到库表的数据增长,理应构思合理的重构优化方式,比如 ES 配合查询、分库分表、TiDB 等解决方式。