数据量过大时的深度分页优化以及前端优化
一、引言
最近做了个练手的项目叫大唐软件任务管理系统,主要功能有三个,分别是人员管理、任务管理、计划管理。经过一段时间,把项目的功能依据文档完成的差不多了,之后,开始往里面插入一定量的随机数据(100万条),点击最后一页,那查询速度太慢了,要是1000万条数据,查询时间不得乘个10?变得超级慢,所以,需要对sql查询语句进行优化。
二、sql查询语句优化
1.在任务管理界面展示页中点击最后一页,执行的查询语句是select * from task where publisherId = 5 limit 1000000,10 将这条语句放到Navicat Premium里面执行为4.359s。分析其原因,是因为limit 1000000,10语句执行时会扫描满足条件的1000010条数据,然后扔掉前面的1000000条数据,返回最后的10条,并不是直接跳到指定位置去取10条数据,所以越是往后的页数查询就越慢
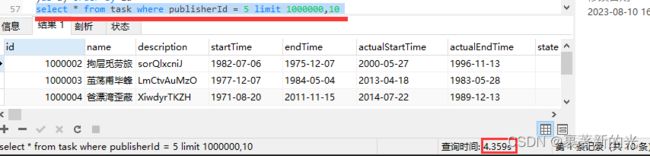
2.首先我想到的第一种方法是内嵌子查询,通过覆盖索引查出符合条件的所有id,然后通过id来查询所要的数据,由于id是主键,这样就能直接走最快的聚簇索引,提高查询速度,优化后的sql查询语句为select * from task where id in (select id from (select id from task where publisherId = 5 limit 1000000,10) as a) order by id
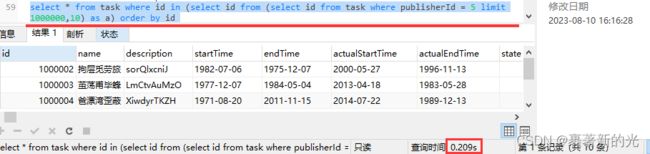
查询时间缩短到了0.209s,速度大约是原来的21倍!
3.于是,我将嵌套子查询id的方式应用到了其他的查询语句上,比如在计划管理页面查询计划plan的语句,原语句是select p.* from plan p join task t on p.taskId=t.id where t.userId=8 limit 500000,10 查询时间为 1.387s

优化后的语句为select * from plan where id in(select id from(select p.id from plan p join task t on p.taskId=t.id where t.userId=8 limit 500000,10) as a) order by id 查询时间为0.667s
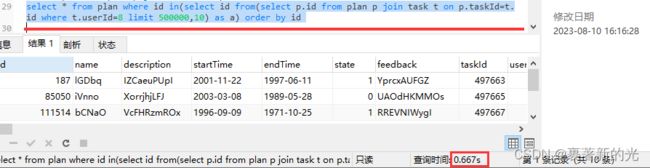
可见查询时间还是太长,这时我考虑到这个查询查的全是plan里的列名,join task只是提供了一个查询条件t.userId=8,可以尝试把联表查询优化为单表查询。于是,我修改了plan的表结构,在plan后面添加了列名userId,重新向表plan里面插入数据,所以现在的查询语句变成了select * from plan p where p.userId=8 order by id limit 500000,10 查询时间为0.23s
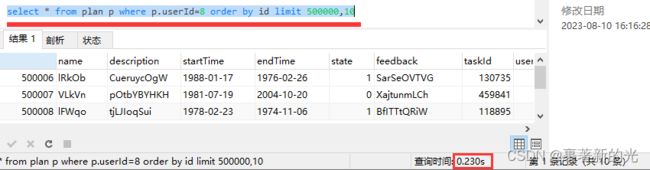
以及嵌套子循环查id的查询语句为 select * from plan where id in (select id from(select id from plan p where p.userId=8 limit 500000,10) as a) order by id 查询时间为0.129s

4.第二种方式,与第一种方式差不多,都是先通过覆盖索引查主键id,再根据主键id关联原表获取所需要的行,只是语句有所不同,查询时间上相差不大

5.另外,还有种更快的优化方式,就是不用limit ?,? 而是限制id的范围后再limit ?将查询条件变成where id > ? limit ?,这种方法需要拿到上一页最后一条数据的id来限制id大于多少,并且只能支持一页一页的翻,不能跳页
6.如果想要用刚才的方法进行跳页的话,可以选择用limit ?,? 的第一个参数来限制id的范围,比如原语句为select * from task where publisherId = 5 limit 1000000,10 查询时间为4.359s
改为select * from task where publisherId = 5 and id>1000000 limit 10 查询时间为0.021s
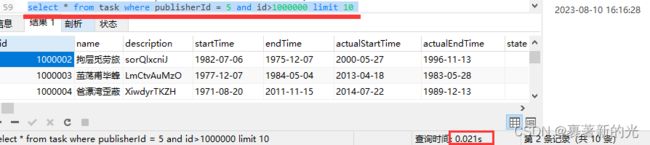
这速度直接提升200多倍啊,比嵌套子查询查id快多了啊,不过很明显,这种方式查出来的数据可能会因为id不连续或者添加了其他查询条件或者其他方面的原因而导致不准确,比如点击最后一页,出现的最后一条数据很可能不是真正的最后一条数据,以及翻页会出现重复的数据。不过,在真实的web项目中,我想没人会一页一页翻个几十几百万页来找数据吧,直接给个搜索框查询不就完了?
三、将语句优化作用到项目中
1.此项目用的分页插件为pagehelper插件,此插件会自动在sql语句后面添加limit ?,? 。所以需要找到pagehelper插件中拼接sql语句添加limit的方法,并进行重写。经过代码调试,发现拼接方法在包com.github.pagehelper.dialect.helper的类MySqlDialect中,因为是class文件,所以重写需要建立同名的包目录以及在包里建立同名类MySqlDialect.java,将插件类MySqlDialect代码全复制到建立的同名类MySqlDialect.java里面,重写其中的getPageSql方法,对要分页的sql语句进行重新拼接优化
四、对搜索框进行中文汉字查询的优化
1.由于数据库任务表task表的列名任务名name里面的数据是中文汉字,而中文汉字是无法简单建立二级索引的,并且模糊查询like '%name%'也不会走索引,我的解决方案是自己手动创建一个倒排索引。

2.先把所需task表数据行中的所有id和name都拿到,用jieba分词器分别对每行的name进行分词得到list
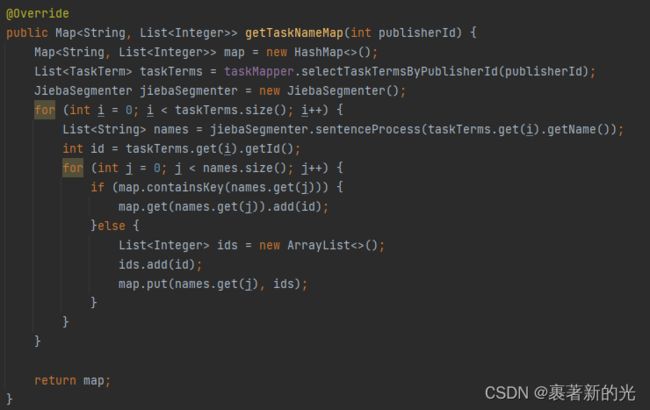
3.接下来就是如何使用的问题了,在Controller中接收到的查询条件为中文汉字的name,用jieba分词器对name进行分词为names(元素为names[i]),然后通过map.get(names[i])返回多个list,通过对list取交集赋值给List
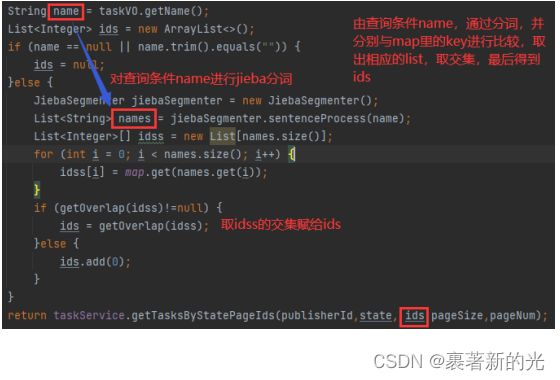



查询时间7ms,简直快到起飞,不过缺点就是要先加载数据到内存中创建装了大量键值对的Map,相当于用内存空间去换时间了
五、前端优化
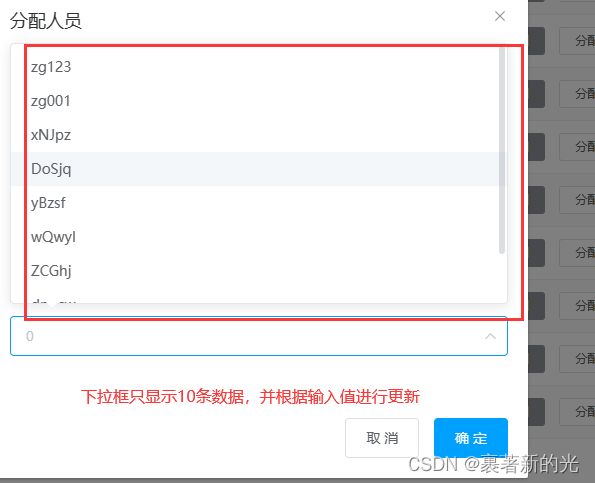
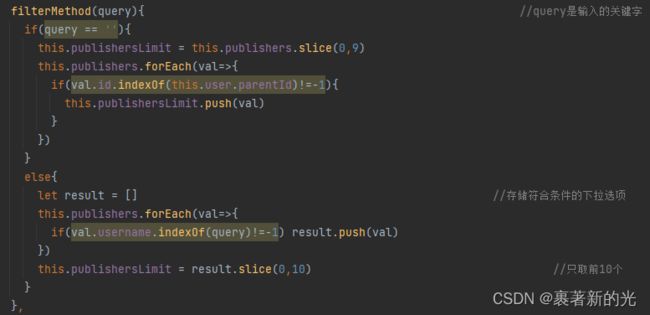
1.前端优化主要是一些显示的问题,比如下拉框里面的选项太多了(几百万行),导致一点开页面就会卡住未响应,第一种解决方案是将下拉框去掉,改成搜索框,就不需要传那么多数据到下拉框展示了。然后是我选择的第二种解决方案,虽然下拉框有那么多行数据,但只要在前端页面上限制下拉框只显示其中的前十条,并打开下拉框的搜索功能,通过输入的值更新下拉框展示的十条数据,即完成优化,既可下拉选择,又可搜索输入后再下拉选择,也不会再卡顿了。

六、总结
1.对于数据量过大导致的深度分页问题,可以使用延迟关联(内嵌子查询id或查id再关联原表)的方式来提高查询速度;如果不要求跳页,可以每次分页查询记录本页最后一条数据的id,作为下一页的查询条件来用,限制id大于上一页最后一条数据的id,然后再limit ?来取相应的条数;如果严格限制表中每条数据的id,使之能与相应的页数对上的话,可以直接将分页limit ?,? 的第一个参数限制id大于它,然后再limit ? 来取相应的条数。
2.能不用join就不用join,单表查询比联表查询快多了。
3.对于以中文汉字为条件的模糊查询,可以通过建立倒排索引来进行查询优化。
4.前端下拉框可以改为搜索框或者限制下拉框展示条数来防止页面卡顿。