MySQL数据库管理
常用的数据类型:
| 类型 | 含义 |
|---|---|
| tinyint(n) | 1个字节,范围(-128~127) |
| smallint(n) | 2个字节,范围(-32768~32767) |
| mediumint(n) | 3个字节,范围(-8388608~8388607) |
| int(n) | 4个字节(32个比特位),整数型,范围(-2147483648~2147483647) |
| bigint(n) | 8个字节,整数型,范围(+-9.22*10的18次方) |
| float(m,d) | 单精度浮点,8位精度,4字节32位。m数字总个数,d小数位 |
| double(m,d) | 双精度浮点,16位精度,8字节64位 。m总个数,d小数位 |
| char | 固定长度的字符类型 |
| varchar | 可变长度的字符类型 |
| text | 文本 |
| image | 图片 |
| decimal(5,2) | 5个有效长度数字,小数点后面有2位(例如123.56) |
常用数据类型介绍
1、int(N)
int(N)中的N不是限制字段取值范围的,int的取值范围是固定的(0至4294967295)或(-2147483648至2147483647)。N这个值是为了zerofill在字段中的值不够时补零的。
int默认是signed(有符号),取值范围(-2147483648至2147483647)。如果加了unsigned( 无符号)参数那么取值范围就为(0至4294967295)。
2、float(m,d)
设一个字段定义为float(6,3),表示6个有效长度数字,小数点后面有3位。如果插入一个数123.45678,实际数据库里存的是123.457,但总个数还以实际为准,即6位。如果插入数12.123456,存储的是12.123,如果插入12.12,存储的是12.120。
整数部分最大是3位,如果插入1234.56,会插入失败。
3、char与varchar
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
下表显示了将各种字符串值保存到CHAR(4)和VARCHAR(4)列后的结果,说明了CHAR和VARCHAR之间的差别:
| 值 | CHAR(4) | 存储需求 | VARCHAR(4) | 存储需求 |
|---|---|---|---|---|
| '' | ' ' | 4个字节 | '' | 1个字节 |
| 'ab' | 'ab ' | 4个字节 | 'ab ' | 3个字节 |
| 'abcd' | 'abcd' | 4个字节 | 'abcd' | 5个字节 |
| 'abcdefgh' | 'abcd' | 4个字节 | 'abcd' | 5个字节 |
- char无论是否有值,都会占用固定长度的字节大小,保存在磁盘上都是4字节。
- varchar在保存字符时,默认会加一个隐藏的结束符,因此结束符会多算一个字节。
数据库操作
查看数据库
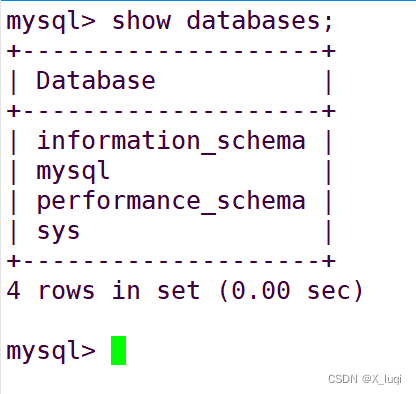
创建数据库

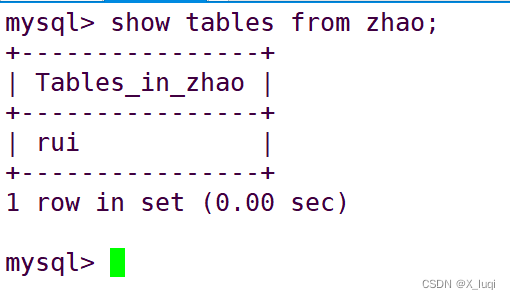
查看表的方法
法一:
use 库名; #切换库
show tables; #查看表
法二:
show tables from 数据库名; #直接查看某个库中的表

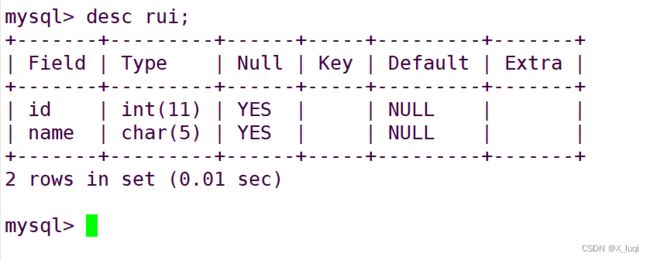
查看表的结构
desc 表名;
SQL语言分类
1、DDL:数据定义语言(Data Definition Language),用于创建数据库对象,如库、表、索引等。
例如:CREATE,DROP,ALTER 等。
2、DML:数据操纵语言(Data Manipulation Language),用于对表中的数据进行管理。
例如: SELECT、UPDATE、INSERT、DELETE 等。
3、DQL:数据查询语言( Data Query Languag ),用于从数据表中查找符合条件的数据记录。
例如: SELECT
4、DCL:数据控制语言(Data Control Language),用于设置或者更改数据库用户或角色权限
例如: GRANT,REVOKE
5、TCL:事务控制语言(Transaction Control Language),用于管理数据库中的事务。 TCL经常被用于快速原型开发、脚本编程、GUI和测试等方面。
例如: COMMIT,ROLLBACK,SAVEPOINT
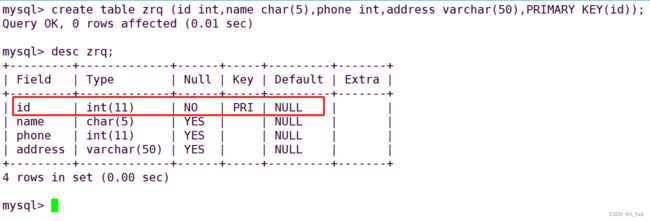
创建与删除数据表
CREATE TABLE 表名(字段1 数据类型,字段2 数据类型[,...] [,PRIMARY KEY (主键名)]);
#主键一般选择能代表唯一性的字段,不允许取空值(NULL),值也不允许重复,主键字段的值是唯一的。一个表只能有一个主键。
删除表
DROP TABLE [数据库名.]表名;


删除数据库
DROP DATABASE 数据库名;

插入表数据
方法一:为所有字段插入值 insert into 表名 values (所有字段的值); #每个字段值用逗号相隔;
方法二:为指定字段插入值 INSERT INTO 表名(字段1,字段2[,...]) VALUES (字段1的值,字段2的值,...); #注意字段的属性not null,则必须为该字段插入值

查询表数据
select * from 表名;

修改/更新表数据
UPDATE 表名 SET 字段名1=字段值1[,字段名2=字段值2] [WHERE 条件表达式];

修改表名和表结构
修改表名
ALTER TABLE 旧表名 RENAME 新表名;

扩展表结构,增加字段
ALTER TABLE 表名 ADD 字段名 数据类型;
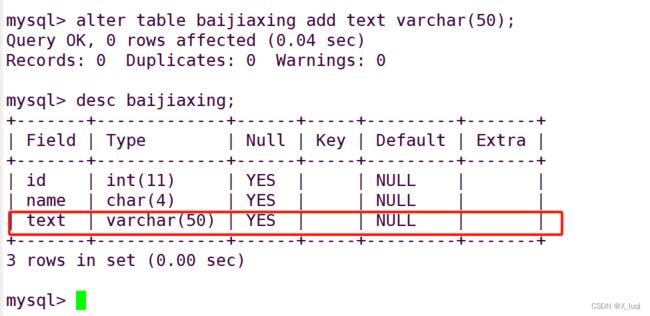
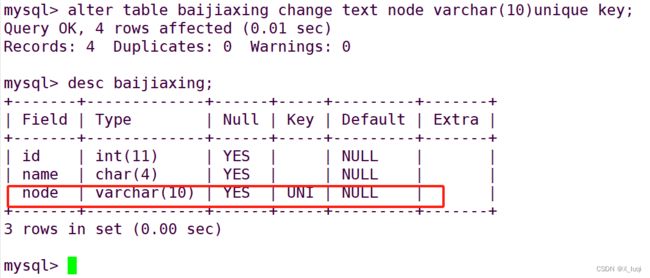
修改字段名,添加唯一键
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 [数据类型] [约束];
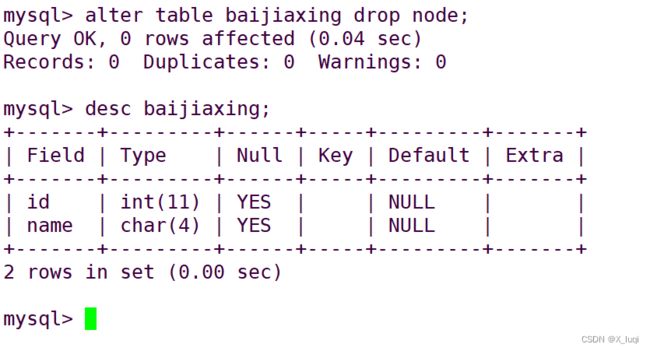
删除字段
ALTER TABLE 表名 DROP 字段名;
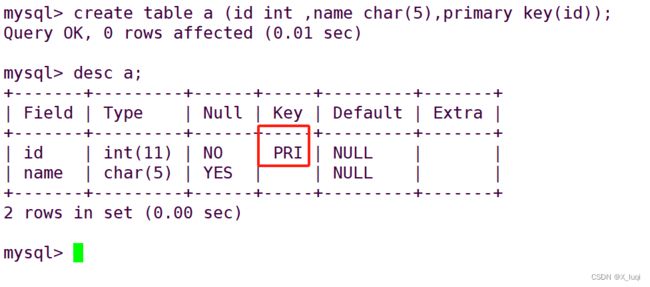
添加主键约束
法一
create table 表名(字段1 XXX, 字段2 XXX, ....primary key(字段));
法二
create table 表名(字段1 XXX primary key, . . ..); #将主键作为字段1的属性
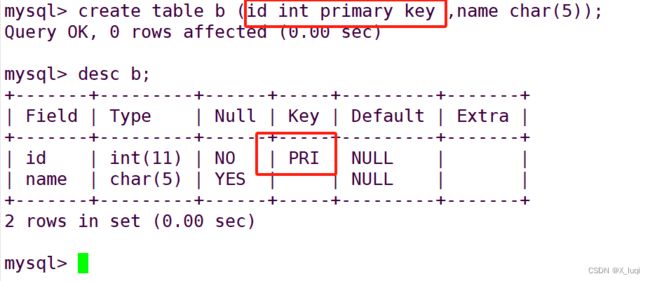
主键primary key 和 唯一键unique key:
共同点:字段的值都是唯一的,不允许有重复值。
不同点:
- 自定义的表中只能有一个主键,但是可以有多个唯一键。
- 主键字段中不允许有null值,唯一键允许有null值。
MYSQL常见的约束
- 主键约束(primary key) PK
- 自增长约束(auto_increment)
- 非空约束(not null)
- 唯一性约束(unique)
- 默认值约束(default)
- 零填充约束(zerofill)
- 外键约束(foreign key)FK
克隆表
create table 新表 like 旧表; 通过like方法复制旧表的表结构
insert into 新表 (select * from 旧表); 向新表插入旧表查询的数据
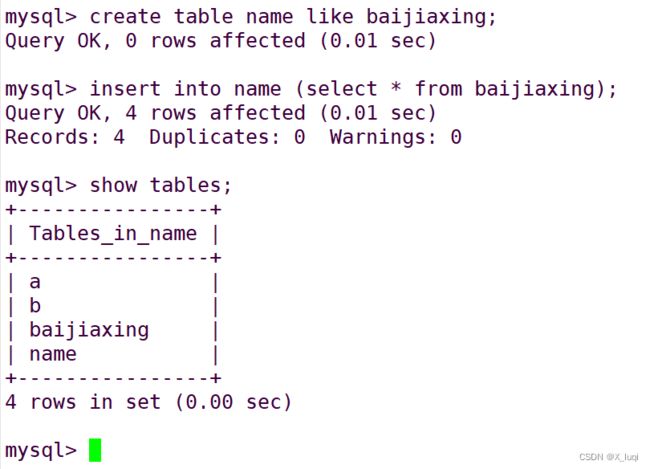
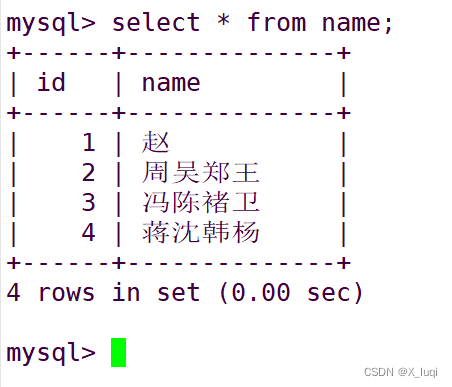
清空数据表
delete from 表名; 一行一行的删除数据记录,删除效率较慢,执行完后会返回删除的记录条目数;删完后再插入数据记录,自增字段仍然会以原来的最大记录自增
truncate table 表名; 直接重建表,清空速度比delete更快,执行完后不会返回记录条目数;清空表后再插入数据,自增字段会重新从1开始递增