重学C++笔记之(十四)string类和标准模板库
1. string类
string类是由头文件string支持的,C-风格字符串由string.h和cstring支持,但是C-风格不支持string类。string类包含的内容很多。
1.1 构造字符串
下面列举了常用的7个构造函数,以及C++11新增的两个构造函数。NBTS(null-terminated string)表示以空字符结束的字符串,也就是传统C字符串。

- 7个构造函数举例:
#include- C++11新增的构造函数
新增的第一个构造函数为移动构造函数(move constructor),在有些情况下,编译器可使用它,而不是复制构造函数,以优化性能。
新增的第二个构造函数string(initializer_listil),这是新增的C++11新增的初始化列表,下面举例:
string piano_man = {'L', 'i', 's' ,'z', 't' };
stringcomp_lang {'L', 'i', 's'};
1.2 string类输入
C-风格字符串有3种输入:
char info[100];
cin>>info;//读取一个word
cin.getline(info, 100);//读取一行,丢弃\n换行符
cin.get(info, 100);//读取一行,将\n保留在队列中
string对象,有两种输入:
string stuff;
cin>>struff;//读取一个单词word
getline(cin, stuff);//读取一行,丢弃\n换行符
这C-风格和string两个版本的输入还有一个可选参数,用于指定使用那个字符来确定输入的边界:
cin.getline(info, 100, ':');//一直到读取':',并丢弃:
getline(stuff, ':');//一直到读取':',并丢弃:
C-风格和string的两个版本区别:
- 第一:string可以自动调整大小,可以保存很长的字符串
- 第二:C-风格字符串的函数是istream类的方法,而string版本是独立的函数。也就是说c-风格的输入cin是调用对象;而对于string对象输入,cin是一个函数。
1.3 使用字符串
- 6个关系运算符
可以用于string和C-风格字符串:
string snake1("cobra");
string snake2("coral");
if(snake1 < snake2)//== 或者!=或<=
- 字符串长度
size()和length()成员函数都可以返回字符串中的字符数。length()成员来自较早版本的string类,而size()则是为提供STL兼容性而添加的。
if(snake.length() == snake2.size())
- find:搜索子字符串或字符
string::npos是字符串可存储的最大字符数,通常是无符号int或无符号long的最大取值。


string库提供了相关的方法。
- rfind():查找子字符串或字符最后一次出现的位置;
- find_first_of():查找字符串中查找参数中任何一个字符首次出现的位置;
- find_last_of():查找最后一次出现的位置;
- find_first_not_of:查找第一个不包含在参数中的字符。
int where = snake1.find_first_of("hark");
int where = snake1.last_first_of("hark");
int where = snake1.find_first_not_of("hark");
1.4 string提供的其他功能
string库提供了很多工具,比如删除部分或全部内容,替代字符串内容、插入等等下面举一个简单例子:
capacity()返回当前分配给字符串的内存的大小,而reserve()方法为请求内存块的最小长度。
#include输出:
SIZE:
empty: 0
small: small.size
larger: 34
Capacity:
empty: 15
small: 15
larger: 34
50
可以看到,最小分配内存为15个字符,比标准容量选择小1。
有一些情况必须使用C-风格的字符串,我们可以使用c_str()方法,将string转换为C-风格方法。
string filename;
cout<<"Enter file name: ";
cin>>filename;
ofstream fout;
fout.open(filename.c_str());//open必须使用c-风格
2. 智能指针模板类
智能指针是行为类似于指针的类对象。这里介绍3个可帮助管理动态内存分配的智能指针模板。
void remodel(std::string& str)
{
std::string* ps = new std::string(str);
...
return;
}
我们可以看到每次调用该函数都分配堆中的内存,但是从来不回收,从而导致内存泄露。所以我们需要在return之前添加:
delete ps;
但是有时候,我们确实会忘记删除或注释掉这些代码。
void remodel(std::string& str)
{
std::string* ps = new std::string(str);
if(weird_thing())
throw exception();
delete ps;
return;
}
上面的示例中,如果发生异常也不会执行delete操作,导致内存泄露。所以我们这里提出了3个智能指针,其中auto_ptr是c++98提供的解决方案,C++11已经将其摒弃。同时C++11提供了另外两种解决方案unique_ptr和shared_ptr。
2.1 使用智能指针
这3个智能指针都定义了类似指针的对象,可以将new获得的地址赋给这种对象。当智能指针过期时,其析构函数将使用delete来释放内存。
要创建智能指针,必须包含头文件memory。例如auto_ptr包含如下构造函数:
template<class X> class auto_ptr
{
public:
explicit auto_ptr(X* p = 0) throw();
}
throw()意味着构造函数不会引发异常;与auto_ptr一样,throw()也被摒弃。使用如下:
auto_ptr<double> pd(new double);
unique_ptr<double> pdu(new double);
shared_ptr<string> pss (new string );
2.2 智能指针的注意事项
实际上有4中智能指针,另外一种为weak_ptr。
先来看看为什么摒弃auto_ptr?先看下列代码:
auto_ptr<string> ps (new string ("I reigned lonely as a cloud."));
auto_ptr<string> vocation;
vocation = ps;
这种情况下,ps和vocation都指向同一个string对象。那么程序将试图删除同一个对象两次。所以在C++11中将其摒弃了。
2.3 unique_ptr为何优于auto_ptr
例如下列代码:
unique_ptr<string> ps (new string ("I reigned lonely as a cloud."));
unique_ptr<string> vocation;
vocation = ps;
编译器认为这是非法的。所以unique_ptr比auto_ptr更安全。编译阶段错误比潜在的程序崩溃更安全。如果unique_ptr是个临时右值时,则编译器允许这么做:
unique_ptr<string> demo(const char* s)
{
unique_ptr<string>temp (new string(s));
return temp;//临时变量,可以这么做。
}
unique_ptr<string> ps;
ps = demo("Uniquely special");//右值是临时,允许
下面的操作也是允许的:
unique_ptr<string>pu1<new string "Hi ho!");
unique_ptr<string>pu2;
pu2 = pu1;//#1 不允许,共同指向
unique_ptr<string> pu3;
pu3 = unique_ptr<string>(new string "Yo!");//右边新创建,不属于共同指向
如果确实想要进行#1的操作,可以使用C++新标准库函数std::move()。
unique_ptr<string>ps1, ps2;
ps1 = demo("Uniquely special");
ps2 = move(ps1);
ps1 = demo("and more");
cout<<*ps2<<*ps1<<endl;
unique_ptr的另一个优点,它还有new[]版本,而auto_ptr只有new的版本:
unique_ptr<double[]> pda(new double[5]);
总结注意点:
- 使用new分配内存时,才能使用auto_ptr和shared_ptr,使用new[]分配内存时,不能使用它们。
- 不使用new分配内存时,不能使用auto_ptr和shared_ptr;
- 不使用new或new[]分配内存时,不能使用unique_ptr。
2.4 选择智能指针
- 多个指向同一个对象的指针,应选择shared_ptr。如果编译器没有提供shared,可使用Boost库提供的shared_ptr。
- 如果不需要多个同一个对象的指针,则可使用unique_ptr。
在编译器没有提供unique_ptr时,则可以使用auto_ptr,其他情况最好使用unique_ptr进行替代。
模板shared_ptr包含一个显式的构造函数,可用于将右值的unique_ptr转换为shared_ptr。
shared_ptr<int> spr(make_int(rand()%1000);//make_int是一个返回unique_ptr指针的函数。
3. 标准模板库
STL提供了一组表示容器、迭代器、函数对象和算法的模板。容器是同质的,即存储的值的类型相同。STL不是面向对象的编程,而是一种泛型编程(generic programming)。STL的信息很多,无法用一章的篇幅全部介绍,这里只介绍一些有代表性的例子,并领会泛型编程方法的精神。
3.1 模板类vector
前面我们已经简要介绍过vector类,下面更详细的介绍它。要使类成为通用的,应将它设计为模板类,STL正是这么做的,它包含在头文件vector中。
vector类似于数组,可以用[]进行访问。下面来看看它的简单使用。
#include与string类似,各种STL容器模板都接受一个可选的模板参数,该参数指定使用哪个分配器对象来管理内存,例如:
template<class T, class Allocator = allocator<T> >
class vector{...
如果省略模板参数的值,则容器模板将默认使用allocator类。这个类使用new和delete。
3.2 对vector的操作
首先介绍迭代器的概念,它是一个广义指针。事实上,它也可以是指针,也可以是一个对其执行类似指针的操作,如解除引用(*)和递增(++)。要使用vector的double类型规范声明的一个迭代器:
vector<double>::iterator pd;
pd = scores.begin();//让它指向头部
在C++11中我们通常可以这么做:
auto pd = scores.begin();//C++11自动推断。
所有的STL容器都提供了一些基本的方法:
size():返回容器中元素数目;
swap():交换两个容器的内容;
begin():返回一个指向容器中第一个元素的迭代器;
end():返回一个表示超过容器尾的迭代器。
(1) push_back()和pop_back()
#include(2) erase()
删除给定区间的元素,它接受两个迭代器参数,这两个参数定义了要删除的区间。第一个迭代器指向区间的起始处,第二个迭代器位于区间终止处的后一个位置。第一个为闭区间,第二个为开区间。也就是[p1, p2)。所以区间[begin(), end())表示集合的所有内容。
下面表示删除第一个和第二个元素。
scores.erase(scores.begin(), scores.begin() + 2);
(3) insert()
插入操作接受3个参数,第一个参数表示新元素的出入位置,第二、三个迭代器表示表示被插入区间。将new_v中除第一个元素外的所有元素插入到old_v的第一个元素前面:
vector<int> old_v;
vector<int>new_v;
...
old_v.insert(old_v.begin(), new_v.begin() + 1, new_v.end() );
下面将介绍3个具有代表性的STL函数:for_each()、random_shuffle()和sort()。
(4) for_each()
for_each()接受3个参数。前两个表示区间的迭代器,最后一个是指向函数的指针。表示被指向的函数应用于容器区间中的各个元素。被指向的函数不能修改容器元素的值。可用for_each()函数来代替for。
vector<Review>::iterator pr;
for(pr = books.begin(); pr != books.end(); pr++)
ShowReview(*pr);
可以替换为:
for_each(books.begin(), books.end(), ShowReview);
(5) Random_shuffle()
该函数接受2个指定区间的迭代器参数,并随机排列该区间的元素。该函数包含在algorithm头文件中。例如:
random_shuffle(books.begin(), books.end());
与for_each不同,该函数要求容器允许随机访问,所以vector满足这一点要求!
(6) sort()
同样sort函数也要求支持随机访问。该函数有两个版本。
第一个版本为默认"<"排列,也就是升序排列。它接受两个定义区间的迭代器参数。
vector<int> coolstuff;
...
sort(coolstuff.begin(), coolstuff.end());
如果容器的元素使用自己定义的,则要使用sort(),必须定义能够处理该类型对象的operator<()函数。例如Review是一个结构,所以可以这么定义(成员或非成员函数都可以):
bool operator <(const Review& r1, const Review& r2)
{
if(r1,title < r2.title)
return true;
else if(r1.title == r2.title && r1.rating < r2.rating)
return true;
else
return false;
}
sort(books.begin(), books,end());
第二个版本,提供3个参数,可以人为确定升序或降序。
bool WorseThan(const Review& r1, const Review& r2)
{
if(r1.rating < r2.rating)
return true;
else
return false;
}
sort(books.begin(), books.end(), WorseThan);//最后一个参数表示函数指针
(7) 基于范围的for循环(C++11)
前面曾经介绍过,这种for循环是为STL而设计的。
double prices[5] = {2.4, 15.33, 34.34, 13.3};
for(double x : prices)
cout<<x<<endl;
for_each也可以用范围for循环
for_each(books.begin(), books.end(), ShowReview);
for(auto x : books) ShowReview(x);
不同于for_each的是,基于范围的for循环可修改容器的内容。
void InflateReview(Review& r){r.rating++}
for(auto& x : books)InflateReview(x);
4 泛型编程
有了一些使用STL的经验后,来看一看底层理念。STL是一种泛型编程(generic programming)。面向对象编程关注的是编程的数据方面,而泛型编程关注的是算法。
每个容器类(vector、list、deque等)定义了相应的迭代器类型,对于其中某个类,迭代器可能是指针;而对于另一个,则可能是对象。不管如何,迭代器都实现所需的操作,如*和++。实际上,作为一种编程风格,最好避免使用迭代器,而应尽可能使用STL函数(如for_each())来处理细节。也可以使用C++11新增的基于范围的for循环。
4.1 迭代器类型
STL定义了5种迭代器,并根据所需的迭代器类型对算法进行了描述。他们分别为输入迭代器、输出迭代器、正向迭代器、双向迭代器和随机访问迭代器。
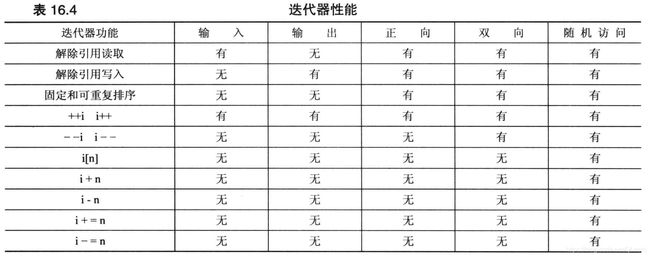
为何需要这么多迭代器呢?目的是为了在编写算法尽可能使用要求最低的迭代器,并让它适用于容器的最大区间。需要注意的是,各种迭代器的类型并不确定,而是一种概念性的描述。例如vector
4.2 容器的种类
STL具有容器概念和容器类型。
容器概念:具有名称的通用类型,比如容器、序列容器、关联容器;
容器类型:可用于创建具体容器对象的模板。
以前的11个容器类型分别为:deque、list、queue、priority_queue、stack、vector、map、multimap、set、multiset和bitset(比特级处理数据的容器,不讨论);
C++11新增forward_list、unordered_map、unordered_multimap、unordered_set和unordered_multiset。而且C++11不将bitset视为容器,而将其视为一种独立的类别。
序列有7中类型:deque,forward_list、list、queue、priority_queue、stack和vector。array也可被归类为序列容器,虽然它不满足序列的所有要求。序列要求元素按严格的线性顺序排列,所以数组和链表都是序列,但分支结构不是(每个节点都指向两个节点)。
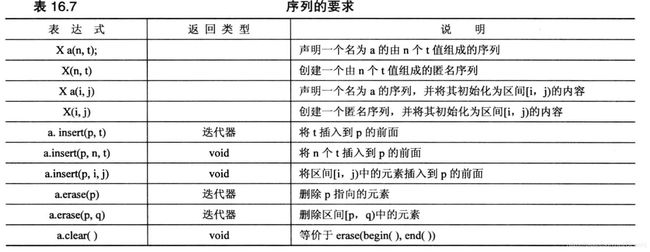
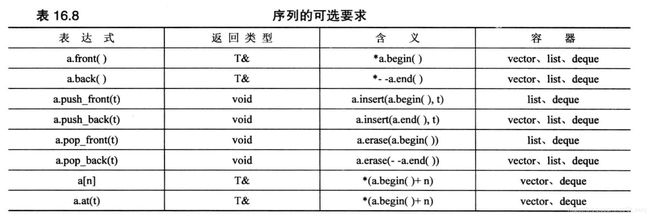
下面介绍7中序列容器类型。
(1)vector
在前面已经介绍过vector了,下面继续介绍一些没有介绍的概念。
vector可提供反转容器(reversible container),并使用方法rbegin()和rend()。前者表示反转序列的第一个元素迭代器,后者返回反转序列的超尾迭代器。假设dice为vector
for_each(dice.begin(), dice.end(), Show);//正向显示
cout << endl;
for_each(dice.rbegin();dice.rend(), Show);//反转显示
cout<<endl;
vector模板类是简单的序列类型,除非其他类型的特殊优点能够更好的满足程序的要求,否则应默认使用这种类型。
(2) deque
deque模板类(在deque头文件中声明)表示双端队列。它的多数操作发生在序列的起始和结尾处,从deque对象的开始位置插入和删除元素的时间是固定的。同样它支持随机访问。
vector在中部执行插入和删除操作速度要比deque快一些。
(3) list
list模板类(在list头文件中声明)表示双向链表。除了第一个和最后一个元素外,每个元素都与前后的元素相链接,这意味着可以双向遍历链表。list和vector之间关键区别在于,list链表中任一位置进行插入和删除的时间都是固定的。因此,vector强调的是通过随机访问进行快速访问,而list强调的是元素的快速插入和删除。
list模板类版还有链表专用的成员函数:

下面代码进行举例:
#include
#include(4) forward_list(C++11)
forward_list属于单链表,所以它需要正向迭代器,而不需要双向迭代器。因此,不同于vector和list,forward_list是不可反转的容器。
(5) queue
queue模板类(在头文件queue中声明)是一个适配器类。queue模板让底层类(默认为deque)展示典型的队列接口。
queue模板的限制比deque更多。它不仅不允许随机访问队列元素,甚至不允许遍历队列。它允许以下操作。
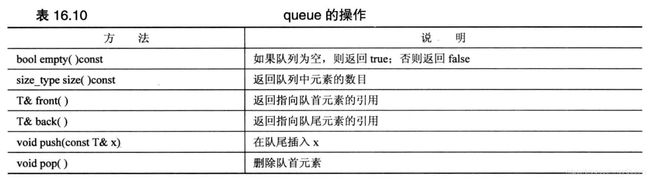
(6) priority_queue
priority_queue模板类(在queue头文件中)是另一个适配器类,它支持的操作与queue相同,两者主要的区别在于,在priority_queue中,最大的元素被移到队首。内部区别在于,默认的底层类是vector。可以修改用于确定哪个元素放在队首的比较方式。
priority_queue<int> pq1;//默认方式
priority_queue<int> pq2(greater<int>);//greater方式
(7) stack
与queue相似,stack(在头文件stack中声明)也是一个适配器类,它给底层类(默认为vector)提供典型的栈接口。
stack模板的限制比vector更多。它不仅不允许随机访问栈元素,甚至不允许遍历栈。它把使用限制在定义栈的基本操作上。下面列举了基本操作:

(8)array(C++11)
array模板类在头文件array中声明,它并非STL容器,因为其长度是固定的。没有push_back()和insert()操作。但是它可以进行operator[]和at()操作,而且可将很多标准STL算法用于array对象,比如copy()和for_each()。
4.2 关联容器
关联容器(associative container)是对容器的另一个改进。关联容器将值与健关联在一起,并使用健来查找值。关联容器允许插入新元素,但不能指定元素的插入位置。关联容器通常是使用某种树实现的。树的查找速度比链表块。
STL提供了4种关联容器:set、multiset、map和multimap。前两种在头文件set中,后两种在头文件map中定义。
- set:值类型与健相同,健是唯一的。对于set来说,值就是健。
- multiset:类似于set,只是可能有多个值的键相同。比如键和值的类型为int,则multiset对象包含的内容可以是1、2、2、2、3;
- map:值与健的类型不同。键是唯一的,每个键只对应一个值。
- multimap与map相似,只是一个键可以与多个值相关联。
下面举例set和multimap的例子
(1) set
set是关联集合,可反转,可排序,且键是唯一的,所以不能存储多个相同的值。有两种定义类型:
set<string> A;//存储值的类型为string
set<string, less<string>>A;
set排序举例:
#include集合的并集set_union
set_union(A.begin(), A.end(), B.begin(),B.end(),ostream_iterator<string, char> out(cout, " "));//显示并集
set_union(A.begin(), A.end(), B.begin(),B.end(),insert_iterator<set<string,> >(C, C.begin()));//并集放入C
交集和差集用法和并集相同
set_intersection():交集
set_difference():集合的差
set有两个有用的方法:
- lower_bound():将键作为参数并返回一个迭代器,该迭代器指向集合中第一个不小于键参数的成员。
- upper_bound():将键作为参数并返回一个迭代器,该迭代器指向集合中第一个不大于键参数的成员。
汇总代码如下:
#include输出:
Set A: buffon can for heavy thinkers
Set B: any deliver elegant food for metal
Union of A and B:
any buffon can deliver elegant food for heavy metal thinkers
Intersection of A and B:
for
Difference of A and B:
buffon can heavy thinkers
Set C:
any buffon can deliver elegant food for heavy metal thinkers
Set C after insertion:
any buffon can deliver elegant food for grungy heavy metal thinkers
Showing a range:
grungy heavy metal
(2) multimap
与set相似,multimap也是可反转的、经过排序的关联容器(按键排序),但键和值的类型不同,且同一个键可能与多个值相关联。
multimap<int , string>codes;//int为键类型,string为值类型。
和set一样,第三个参数也是可选的,将使用模板less。
为将信息结合在一起,STL使用模板类pair
pair(const int ,string> item(213,"Los Angles");
codes.insert(item);
也可以使用一条语句创建匿名pair对象并将它插入:
codes.insert(pair<const int,string> (213,"Los Angles"));
可使用first和second来方位其两个部分:
pair(const int ,string> item(213,"Los Angles");
cout<<item.first <<" " <<item.second<<endl;
multimap有一些功能性的成员函数:
- lower_bound():类似与set
- upper_bound():类似于set
- count():接受键作为参数,并返回该键的元素数目。
- equal_range():用键作为参数,并返回两个迭代器,返回的区间与键匹配。
使用代码如下:
#include输出:
Number of cities with area code 415: 2
415 San Francisco
415 San Rafael
510 Oakland
510 Berkeley
718 Brooklyn
718 Staten Island
Cites with area code 718:
Brooklyn
Staten Island
4.3 无序关联容器(C++11)
无需关联容器是对容器概念的另一种改进。无序关联容器也将值与键关联起来,并使用键来查找值。底层的差别在于,关联容器基于树结构,而无序关联容器基于数据结构哈希表的。有4种无序关联容器,它们分别是unordered_set、unordered_multiset、unordered_map和unordered_multimap。在课本附录G中介绍。
5. 函数对象
函数对象也成为函数符(functor)。函数符是可以以函数方式与()结合使用的任意对象。包括函数名、指向函数的指针和重载了()运算符的类对象(即定义了函数operator()()的类)。例如:
class Linear
{
private:
double slope;
double y0;
public:
Linear(double s1_=1, double y_ = 0):slope(s1_),y-(y_){}
double operator()(double x){return y0 + slope * x;}
};
这样,重载的()运算符将使得能够像函数那样使用Linear对象:
Linear f1;
Linear f2(2.4, 10.0);
double y1 = f1(12.5);//0 + 1*1*12.5
double y2 = f2(0.4);//10.0 + 2.5*0.4
上面介绍的for_each的第三个参数可以是普通函数,也可以是函数符。
for_each(books.begin(), books.end(), ShowReview);
5.1 函数符概念
生成器(generator)是不用参数就可以调用的函数符;
一元函数(unary function)是用一个参数可以调用的函数符;
二元函数(binary function)是用两个参数可以调用的函数符。
返回bool值的一元函数是谓词(predicate)
返回bool值的二元函数是二元谓词(binary predicate)
for_each的函数符使用一元函数,而sort()使用的是二元谓词。
bool WorseThan(const Review& r1, const Review& r2);
sort(books.begin(), books.end(), WorseThan);
list模板有一个将谓词作为参数的remove_if()成员,该函数将谓词应用于区间中的每个元素,如果谓词返回true,则删除这些元素。
bool tooBig(int n){return n > 100;}//删除大于100的元素
list<int> scores;
scores.remove_if(tooBig);
5.2 预定义的函数符
STL定义了多个基本函数符。考虑transform()函数,它有两个版本。
版本1:
接受4个参数,对区间内的每个元素进行开根号,并输出:
const int LIM = 5;
double arr[LIM] = {35, 39, 42, 45, 48};
vector<double> gr8(arr1, arr1 + LIM);
ostream_iterator<double, char> out(cout, " ");
transform(gr8.begin(), gr8.end(), out, sqrt);
版本2:
接受5个参数,对两组值进行求平均值:
transform(gr9.begin(), gr8.end(), m8.begin(), out, mean);
对于所有内置的算术运算符、关系运算符和逻辑运算符,STL都提供了等价的函数符。
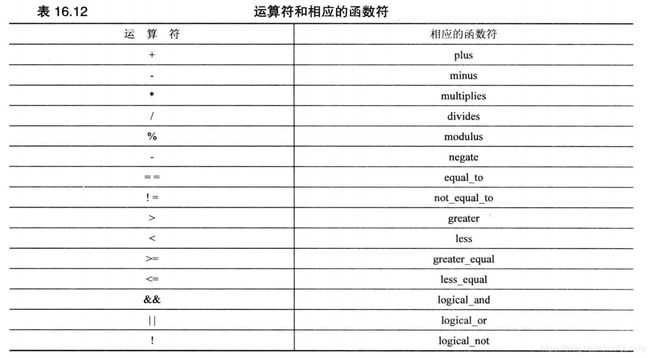
5.3 自适应函数符和函数适配器
这章节待补充
C++提供了函数指针和函数符的替代品,lambda表达式,这将在课本的第18章介绍。
6. 算法
STL包含了很多处理容器的非成员函数,前面已经介绍过的:sort()、copy()、find()、random_shuffle()、set_union()、set_intersection()、set_difference()和transform()。
对于算法函数设计,他们有两个主要的通用部分。
- 都是用模板来提供泛型
- 都是用迭代器来提供访问容器中数据的通用表示
6.1 算法组
STL将算法库分成4组:
- 非修改式序列操作;(algorithm头文件):对区间中的每个元素进行操作,不修改容器的内容,例如find()和for_each(),
- 修改式序列操作;(algorithm头文件):对区间中的每个元素进行操作,可以修改容器的内容,例如transform()、random_shuffle()和copy()。
- 排序和相关操作;(algorithm头文件):比如sort()
- 通用数字运算。(numeric头文件):区间内容累积、计算两个容器的内部乘积、计算相邻对象差的函数等。vector是最有可能使用这些操作的容器。
6.2 STL和string类
虽然string不是STL的组成部分,但设计它是考虑到了STL。例如,它包含begin()、end()、rbegin()和rend()等成员。
例如next_permutation()算法将区间内容转换为下一种排列方式。
while (next_permutation(letters.begin(),letters.end()))//letters为一个字符串
cout<<letters<<endl;//输出一个字符串的所有排列组合
7. 其他库
C++还提供了其他一些类库,它们比本章讨论的前面的例子更为专用。例如complex为复数提供类模板complex,包含用于float、long和long double的具体化。C++11新增的头文件random提供了更多的随机数功能。
前面介绍的valarray提供了模板类valarray。这个类模板被设计成用于表示数值数组,支持各数值数组操作,例如将两个数组的内容相加、对数组的每个元素应用数学函数以及数组进行线性代数运算。
7.1 vector、valarray和array
这三个数组模板由不同的小组开发的,用于不同目的。
- vector模板类:容器类和算法系统的一部分。
- valarray类模板:是面向数值计算的,不是STL的一部分。
- array:为替代内置数组而设计。
7.2 模板initializer_list(C++11)
它就是初始化列表操作。例如:
std::vector<double> payments {45.99, 39.2, 19.4, 34.5};
当然也可以在代码中使用initializer_list对象,那么必须包含头文件initializer_list。这个模板类包含成员函数begin()和end(),还有size()。
#include