catalog
0. 引言 1. windows下开发apache模块 2. mod进阶: 接收客户端数据的 echo 模块 3. mod进阶: 可配置的 echo 模块 4. mod进阶: 过滤器
0. 引言
Apache httpd 从 2.0 之后,已经不仅仅局限于一个 http 的服务器,更是一个完善而强大,灵活而健壮,且容易扩展的开发平台。开发人员通过定制 Apache 模块,可以几乎无限制的扩展 Apache httpd,使其更好的与实际应用场景匹配,而又无需考虑底层的网络传输细节。这样既可以提高开发效率,节省开发成本,又能充分利用 Apache 本身的健壮性及可靠性
0x1: Apache httpd 开发平台简介
Apache httpd 自 2.0 之后,针对 1.0 做了大量的改进,包括对自身内核的改造,扩展机制的改进,APR(Apache Portable Runtime) 的剥离(使得 Apache 成为一个真正意义的跨平台服务器)。Apache 2.0 成为一个很容易扩展的开发平台
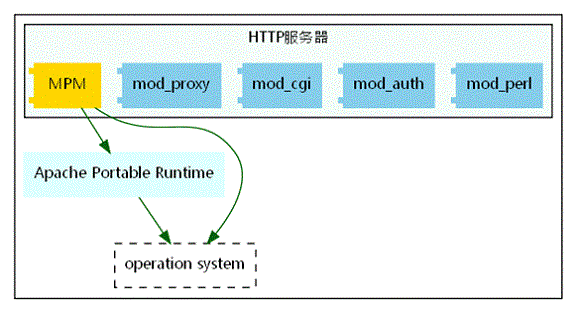
Apache 中包含了大量的扩展模块(module),如 mod_cgi 用以处理 cgi 脚本、mod_perl 用以处理 perl 脚本,将 perl 的能力与 Apache httpd 结合起来等等。用户可以通过一定的开发标准(接口规范)来开发符合自己业务场景的模块,并动态的加载到 Apache 中,Apache 会根据配置文件中的规则来定位,调用模块,完成客户端请求,简单来说,apache的扩展编写可以分类一下几类
1. apache httpd 模块: 编写模块往往要比编写过滤器要复杂一点,可以看成是一种原始的apache扩展编写方式,但是灵活性更高 2. 输出过滤器: apache在模块的基础上进行了API封装,使得过滤器的代码编写变得更简单 3. 输入过滤器
0x2: Apache httpd 模块机制
Apache httpd 由一个内核和大量的模块组成,包括用以加载其他模块的功能单元自身也是一个模块,模块是Apache扩展的基础机制(理论上模块可以实现任何功能)。一般而言,一个 HTTP 服务器的工作序列是这样的
1. 接受客户端请求 可能是请求一个部署在 HTTP 服务器程序可访问的文件,读取该文件作为响应返回,我们在浏览器的地址栏中输入类似这样的 URL:http://host/index.html,浏览器将会尝试与 host 指定的 HTTP 服务器的 80 端口建立连接,如果成功,则发送 HTTP 请求,获取 index.html 页面。如果成功,则在浏览器中解析该 HTML 文件 这种工作方式在静态页面的场景下没有任何问题。但是实际应用往往会与数据库交互,动态生成页面内容。如服务端较为流行的 cgi/php 脚本等。这就需要更高级,更灵活的内容生成器做支持 2. 预处理 1) 权限校验 2) HTTP 头信息识别等 3. 内容生成 通过与操作系统其他资源交互 ( 如文件读写,数据库访问等 ) 来完成动态内容的生成 4. 其他善后操作等 进行日志记录,资源释放等操作
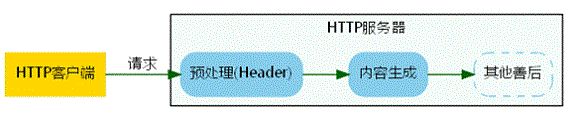
通常注册模块以处理配置文件中的特殊文件类型或其它此类标准
AddHandler cgi-script .cgi //php、python都是通过配置指定特定后缀扩展名的处理模块
Apache 为每个请求调用所有处理程序,因此每个处理程序应该迅速决定请求是否是冲着它来的。因此,大多数头文件都从类似下面的语句开始
if (!req->handler || strcmp(req->handler, "target-module")) return DECLINED;
0x3: Apache 2.0之后的过滤器机制
在大多数时候,apache扩展开发者并不需要很复杂的收包/发包逻辑,而仅仅需要对HTTP Header、Body进行检测,为了提高效率,apache开发者对模块代码进行了API封装
Apache 2.0 有专门的 API 用于开发模块,这些模块只需修改对用户响应的内容,或者只需修改用户的 HTTP 请求的详细信息。这些 API 分别被称为
1. 输出过滤器 输出过滤器最为常见,一个好的示例是标准 Apache 2.0 模块,它被用于计算返回给用户的内容的长度以便更新适当的头和日志项。另一个示例是用于对出站内容进行自动拼写检查的模块 2. 输入过滤器 典型的WEB WAF
从严格意义上来说,基于WEB SERVER的Mod(扩展模块)WAF是一种HTTP全生命周期的检测/过滤/拦截/记录机制,它需要综合利用"输出过滤器"、"输入过滤器"
Relevant Link:
http://www.ibm.com/developerworks/cn/opensource/os-cn-apachehttpd/
1. windows下开发apache模块
0x1: windows下安装apache
http://apache.dataguru.cn//httpd/binaries/win32/ //一定要custom全部安装,否则就不会有include和lib目录
0x2: 安装Perl
将要使用的apx包要用到perl解析编译,所以,需先安装perl
http://www.activestate.com/activeperl
0x3: 安装apxs
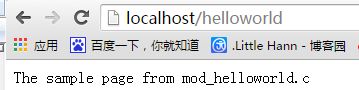
1. http://www.apachelounge.com/download/apxs_win32.zip 2. 解压到: D:\apxs 3. pushd D:\apxs 4. perl Configure.pl --with-apache2=D:\wamp\bin\apache\apache2.4.9 --with-apache-prog=httpd.exe /* apxs.bat has been created under D:\wamp\bin\apache\APACHE~1.9\bin. apr-1-config.pl.bat has been created under D:\wamp\bin\apache\APACHE~1.9\bin. apu-1-config.pl.bat has been created under D:\wamp\bin\apache\APACHE~1.9\bin. */ 5. pushd D:\wamp\bin\apache\apache2.4.9\bin 6. apxs(出现下列提示则说明安装成功) /* Use of assignment to $[ is deprecated at apxs.bat line 120. Usage: apxs -g [-S =] -n */ 7. 配置apxs编译环境 D:\wamp\bin\apache\apache2.4.9\build\config_vars.mk CC = D:\CODEBL~1\MinGW\bin\gcc.exe 改为: CC = cl.exe LD = D:\CODEBL~1\MinGW\bin\g++.exe 改为: LD = link.exe CPP = gcc -E 改为: CPP = LDFLAGS = kernel32.lib /nologo /subsystem:windows /dll /machine:I386 /libpath:"D:\wamp\bin\apache\APACHE~1.9\lib" 改为: LDFLAGS = kernel32.lib /nologo /subsystem:windows /dll /machine:X64 /libpath:"D:\wamp\bin\apache\APACHE~1.9\lib" 8. 使用apxs生成mod框架模版 Visual Studio 命令提示(2010) pushd D:\安全部工作\服务器waf模块mod研究 D:\wamp\bin\apache\apache2.4.9\bin\apxs -g -n helloworld /* Use of assignment to $[ is deprecated at D:\wamp\bin\apache\apache2.4.9\bin\apxs.bat line 120. Creating [DIR] helloworld Creating [FILE] helloworld/Makefile Creating [FILE] helloworld/mod_helloworld.c Creating [FILE] helloworld/.deps */ 9. 进入helloworld目录,编辑mod_helloworld.c(这就是我们要开发的内容) cd helloworld D:\wamp\bin\apache\apache2.4.9\bin\apxs -c -i -a mod_helloworld.c libapr-1.lib libaprutil-1.lib libapriconv-1.lib libhttpd.lib 10. 将mod_helloworld.so拷贝到Apache2.2\modules下 11. 打开conf文件夹下的httpd.conf文件 /* LoadModule helloworld_module "D:/wamp/bin/apache/APACHE~1.9/modules/mod_helloworld.so"apxs -q [-v] [-S = ] ... apxs -c [-S = ] [-o ] [-D [= ]] [-I ] [-L ] [-l ] [-Wc, ] [-Wl, ] [-p] ... apxs -i [-S = ] [-a] [-A] [-n ] ... apxs -e [-S = ] [-a] [-A] [-n ] ... SetHandler helloworld */ 12. 重启apache 13. http://localhost/helloworld
0x4: mod通用模板代码框架
#include "httpd.h" #include "http_config.h" #include "http_protocol.h" #include "ap_config.h" /* The sample content handler 首先需要一个实际处理客户端请求的函数 (handler),命名方式一般为”模块名 _handler”,接收一个 request_rec 类型的指针,并返回一个 int 类型的状态值 request_rec 指针中包括所有的客户端连接信息及 Apache 内部的指针,如连接信息表,内存池等,这个结构类似于 J2EE 开发中 servlet 的 HttpRequest 对象及 HttpResponse 对象。通过 request_rec,我们可以读取客户端请求数据 / 写入响应数据,获取请求中的信息 ( 如客户端浏览器类型,编码方式等 ) */ static int helloworld_handler(request_rec *r) { if (strcmp(r->handler, "helloworld")) { return DECLINED; } r->content_type = "text/html"; if (!r->header_only) ap_rputs("The sample page from mod_helloworld.c\n", r); return OK; } //注册函数,一般命名为”模块名 _register_hooks”,传入参数为 Apache 的内存池指针。这个函数用于通知 Apache 在何时,以何种方式注册响应函数 (handler) static void helloworld_register_hooks(apr_pool_t *p) { ap_hook_handler(helloworld_handler, NULL, NULL, APR_HOOK_MIDDLE); } /* Dispatch list for API hooks 模块的定义,Apache 模块加载器通过这个结构体中的定义来在适当的时刻调用适当的函数以处理响应。应该注意的是,第一个成员默认填写为 STANDARD20_MODULE_STUFF,最后一个成员为注册函数 */ module AP_MODULE_DECLARE_DATA helloworld_module = { STANDARD20_MODULE_STUFF, NULL, /* create per-dir config structures */ NULL, /* merge per-dir config structures */ NULL, /* create per-server config structures */ NULL, /* merge per-server config structures */ NULL, /* table of config file commands */ helloworld_register_hooks /* register hooks */ };
0x5: apache mod核心数据结构: request_rec
The request_rec request record is the heart and soul of the Apache API. It contains everything you could ever want to know about the current request and then some.
\apache2.4.9\include\httpd.h
/** * @brief A structure that represents the current request */ struct request_rec { /** The pool associated with the request This is a resource pool that is valid for the lifetime of the request. Your request-time handlers should allocate memory from this pool. */ apr_pool_t *pool; /** The connection to the client This is a pointer to the connection record for the current request, from which you can derive information about the local and remote host addresses, as well as the username used during authentication */ conn_rec *connection; /** The virtual host for this request This is a pointer to a server record server_rec structure, from which you can gather information about the current server. */ server_rec *server; /* Under various circumstances, including subrequests and internal redirects, Apache will generate one or more subrequests that are identical in all respects to an ordinary request. When this happens, these fields are used to chain the subrequests into a linked list. 1. The next field points to the more recent request (or NULL, if there is none), 2. and the prev field points to the immediate ancestor of the request. 3. main points back to the top-level request. */ /** Pointer to the redirected request if this is an external redirect */ request_rec *next; /** Pointer to the previous request if this is an internal redirect */ request_rec *prev; /** Pointer to the main request if this is a sub-request * (see http_request.h) */ request_rec *main; /* Info about the request itself... we begin with stuff that only * protocol.c should ever touch... */ /** First line of request This contains the first line of the request, for logging purposes. */ char *the_request; /** HTTP/0.9, "simple" request (e.g. GET /foo\n w/no headers) */ int assbackwards; /** A proxy request (calculated during post_read_request/translate_name) possible values PROXYREQ_NONE, PROXYREQ_PROXY, PROXYREQ_REVERSE, PROXYREQ_RESPONSE If the current request is a proxy request, then this field will be set to a true (nonzero) value. Note that mod_proxy or mod_perl must be configured with the server for automatic proxy request detection. You can also set it yourself in order to activate Apache's proxy mechanism */ int proxyreq; /** HEAD request, as opposed to GET This field will be true if the remote client made a head-only request (i.e., HEAD). You should not change the value of this field. */ int header_only; /** Protocol version number of protocol; 1.1 = 1001 */ int proto_num; /** Protocol string, as given to us, or HTTP/0.9 This field contains the name and version number of the protocol requested by the browser, for example HTTP/1.0. */ char *protocol; /** Host, as set by full URI or Host: This contains the name of the host requested by the client, either within the URI (during proxy requests) or in the Host header. The value of this field may not correspond to the canonical name of your server or the current virtual host but can be any of its DNS aliases. For this reason, it is better to use the ap_get_server_name() API function call described under "Processing Requests." hostname访问可能直接DNS域名访问 */ const char *hostname; /** Time when the request started This is the time that the request started as a C time_t structure. */ apr_time_t request_time; /** Status line, if set by script This field holds the full text of the status line returned from Apache to the remote browser, for example 200 OK. Ordinarily you will not want to change this directly but will allow Apache to set it based on the return value from your handler. However, you can change it directly in the rare instance that you want your handler to lie to Apache about its intentions (e.g., tell Apache that the handler processed the transaction OK, but send an error message to the browser). */ const char *status_line; /** Status line */ int status; /* Request method, two ways; also, protocol, etc.. Outside of protocol.c, * look, but don't touch. */ /** M_GET, M_POST, etc. */ int method_number; /** Request method (eg. GET, HEAD, POST, etc.) */ const char *method; /** * 'allowed' is a bitvector of the allowed methods. * * A handler must ensure that the request method is one that * it is capable of handling. Generally modules should DECLINE * any request methods they do not handle. Prior to aborting the * handler like this the handler should set r->allowed to the list * of methods that it is willing to handle. This bitvector is used * to construct the "Allow:" header required for OPTIONS requests, * and HTTP_METHOD_NOT_ALLOWED and HTTP_NOT_IMPLEMENTED status codes. * * Since the default_handler deals with OPTIONS, all modules can * usually decline to deal with OPTIONS. TRACE is always allowed, * modules don't need to set it explicitly. * * Since the default_handler will always handle a GET, a * module which does *not* implement GET should probably return * HTTP_METHOD_NOT_ALLOWED. Unfortunately this means that a Script GET * handler can't be installed by mod_actions. */ apr_int64_t allowed; /** Array of extension methods */ apr_array_header_t *allowed_xmethods; /** List of allowed methods */ ap_method_list_t *allowed_methods; /** byte count in stream is for body */ apr_off_t sent_bodyct; /** body byte count, for easy access */ apr_off_t bytes_sent; /** Last modified time of the requested resource */ apr_time_t mtime; /* HTTP/1.1 connection-level features */ /** The Range: header */ const char *range; /** The "real" content length */ apr_off_t clength; /** sending chunked transfer-coding */ int chunked; /** Method for reading the request body * (eg. REQUEST_CHUNKED_ERROR, REQUEST_NO_BODY, * REQUEST_CHUNKED_DECHUNK, etc...) */ int read_body; /** reading chunked transfer-coding */ int read_chunked; /** is client waiting for a 100 response? */ unsigned expecting_100; /** The optional kept body of the request. */ apr_bucket_brigade *kept_body; /** For ap_body_to_table(): parsed body */ /* XXX: ap_body_to_table has been removed. Remove body_table too or * XXX: keep it to reintroduce ap_body_to_table without major bump? */ apr_table_t *body_table; /** Remaining bytes left to read from the request body */ apr_off_t remaining; /** Number of bytes that have been read from the request body */ apr_off_t read_length; /* MIME header environments, in and out. Also, an array containing * environment variables to be passed to subprocesses, so people can * write modules to add to that environment. * * The difference between headers_out and err_headers_out is that the * latter are printed even on error, and persist across internal redirects * (so the headers printed for ErrorDocument handlers will have them). * * The 'notes' apr_table_t is for notes from one module to another, with no * other set purpose in mind... */ /** MIME header environment from the request */ apr_table_t *headers_in; /** MIME header environment for the response */ apr_table_t *headers_out; /** MIME header environment for the response, printed even on errors and * persist across internal redirects */ apr_table_t *err_headers_out; /** Array of environment variables to be used for sub processes */ apr_table_t *subprocess_env; /** Notes from one module to another */ apr_table_t *notes; /* content_type, handler, content_encoding, and all content_languages * MUST be lowercased strings. They may be pointers to static strings; * they should not be modified in place. */ /** The content-type for the current request */ const char *content_type; /* Break these out --- we dispatch on 'em */ /** The handler string that we use to call a handler function */ const char *handler; /* What we *really* dispatch on */ /** How to encode the data */ const char *content_encoding; /** Array of strings representing the content languages */ apr_array_header_t *content_languages; /** variant list validator (if negotiated) */ char *vlist_validator; /** If an authentication check was made, this gets set to the user name. */ char *user; /** If an authentication check was made, this gets set to the auth type. */ char *ap_auth_type; /* What object is being requested (either directly, or via include * or content-negotiation mapping). */ /** The URI without any parsing performed */ char *unparsed_uri; /** The path portion of the URI, or "/" if no path provided */ char *uri; /** The filename on disk corresponding to this response */ char *filename; /* XXX: What does this mean? Please define "canonicalize" -aaron */ /** The true filename, we canonicalize r->filename if these don't match */ char *canonical_filename; /** The PATH_INFO extracted from this request */ char *path_info; /** The QUERY_ARGS extracted from this request */ char *args; /** * Flag for the handler to accept or reject path_info on * the current request. All modules should respect the * AP_REQ_ACCEPT_PATH_INFO and AP_REQ_REJECT_PATH_INFO * values, while AP_REQ_DEFAULT_PATH_INFO indicates they * may follow existing conventions. This is set to the * user's preference upon HOOK_VERY_FIRST of the fixups. */ int used_path_info; /** A flag to determine if the eos bucket has been sent yet */ int eos_sent; /* Various other config info which may change with .htaccess files * These are config vectors, with one void* pointer for each module * (the thing pointed to being the module's business). */ /** Options set in config files, etc. */ struct ap_conf_vector_t *per_dir_config; /** Notes on *this* request */ struct ap_conf_vector_t *request_config; /** Optional request log level configuration. Will usually point * to a server or per_dir config, i.e. must be copied before * modifying */ const struct ap_logconf *log; /** Id to identify request in access and error log. Set when the first * error log entry for this request is generated. */ const char *log_id; /** * A linked list of the .htaccess configuration directives * accessed by this request. * N.B. always add to the head of the list, _never_ to the end. * that way, a sub request's list can (temporarily) point to a parent's list */ const struct htaccess_result *htaccess; /** A list of output filters to be used for this request */ struct ap_filter_t *output_filters; /** A list of input filters to be used for this request */ struct ap_filter_t *input_filters; /** A list of protocol level output filters to be used for this * request */ struct ap_filter_t *proto_output_filters; /** A list of protocol level input filters to be used for this * request */ struct ap_filter_t *proto_input_filters; /** This response can not be cached */ int no_cache; /** There is no local copy of this response */ int no_local_copy; /** Mutex protect callbacks registered with ap_mpm_register_timed_callback * from being run before the original handler finishes running */ apr_thread_mutex_t *invoke_mtx; /** A struct containing the components of URI */ apr_uri_t parsed_uri; /** finfo.protection (st_mode) set to zero if no such file */ apr_finfo_t finfo; /** remote address information from conn_rec, can be overridden if * necessary by a module. * This is the address that originated the request. */ apr_sockaddr_t *useragent_addr; char *useragent_ip; };
Relevant Link:
http://www.cnblogs.com/QRcode/p/3193397.html http://blog.csdn.net/hxsstar/article/details/19820029 https://publib.boulder.ibm.com/iseries/v5r1/ic2924/info/rzaie/APR/structrequest__rec.html http://docstore.mik.ua/orelly/apache_mod/128.htm http://blog.csdn.net/wind_cludy/article/details/6557776 http://docstore.mik.ua/orelly/apache_mod/128.htm#listing10_1
2. mod进阶: 接收客户端数据的 echo 模块
如果Apache模块只能产生内容,那么使用普通的HTML文件(即使用httpd默认的内容生成器)也可以完成。模块存在的意义在于,它可以轻松地处理客户端传递的数据,并将这些数据加工,然后响应客户端请求
/* ** mod_helloworld.c -- Apache sample helloworld module ** [Autogenerated via ``apxs -n helloworld -g''] ** ** To play with this sample module first compile it into a ** DSO file and install it into Apache's modules directory ** by running: ** ** $ apxs -c -i mod_helloworld.c ** ** Then activate it in Apache's httpd.conf file for instance ** for the URL /helloworld in as follows: ** ** # httpd.conf ** LoadModule helloworld_module modules/mod_helloworld.so **** SetHandler helloworld ** ** ** Then after restarting Apache via ** ** $ apachectl restart ** ** you immediately can request the URL /helloworld and watch for the ** output of this module. This can be achieved for instance via: ** ** $ lynx -mime_header http://localhost/helloworld ** ** The output should be similar to the following one: ** ** HTTP/1.1 200 OK ** Date: Tue, 31 Mar 1998 14:42:22 GMT ** Server: Apache/1.3.4 (Unix) ** Connection: close ** Content-Type: text/html ** ** The sample page from mod_helloworld.c */ #include "httpd.h" #include "http_config.h" #include "http_protocol.h" #include "ap_config.h" #define DFT_BUF_SIZE 1024 /** * @brief read_post_data 从 request 中获取 POST 数据到缓冲区 * * @param req apache request_rec 对象 * @param post 接收缓冲区 * @param post_size 接收缓冲区长度 * * @return */ static int read_post_data(request_rec *req, char **post, size_t *post_size) { char buffer[DFT_BUF_SIZE] = {0}; size_t bytes, count, offset; bytes = count = offset = 0; if(ap_setup_client_block(req, REQUEST_CHUNKED_DECHUNK) != OK) { return HTTP_BAD_REQUEST; } if(ap_should_client_block(req)) { //通过 Apache 提供的 API:ap_get_client_block 将请求中 POST 的数据读入到缓冲区 for(bytes = ap_get_client_block(req, buffer, DFT_BUF_SIZE); bytes > 0; bytes = ap_get_client_block(req, buffer, DFT_BUF_SIZE)) { //如果预分配的缓冲区不够,则重新分配内存存放,并同时修改缓冲区的实际长度 count += bytes; if(count > *post_size) { *post = (char *)realloc(*post, count); if(*post == NULL) { return HTTP_INTERNAL_SERVER_ERROR; } } *post_size = count; offset = count - bytes; memcpy((char *)*post+offset, buffer, bytes); } } else { *post_size = 0; return OK; } return OK; } /* The sample content handler 首先需要一个实际处理客户端请求的函数 (handler),命名方式一般为”模块名 _handler”,接收一个 request_rec 类型的指针,并返回一个 int 类型的状态值 request_rec 指针中包括所有的客户端连接信息及 Apache 内部的指针,如连接信息表,内存池等,这个结构类似于 J2EE 开发中 servlet 的 HttpRequest 对象及 HttpResponse 对象。通过 request_rec,我们可以读取客户端请求数据 / 写入响应数据,获取请求中的信息 ( 如客户端浏览器类型,编码方式等 ) */ static int helloworld_handler(request_rec *r) { int ret; char *post = NULL; size_t post_size = 0; if (strcmp(r->handler, "helloworld")) { return DECLINED; } //只接收GET、POST请求 if((r->method_number != M_GET) && (r->method_number != M_POST)) { return HTTP_METHOD_NOT_ALLOWED; } post = (char *)malloc(sizeof(char) * DFT_BUF_SIZE); post_size = DFT_BUF_SIZE; if(post == NULL) { return HTTP_INTERNAL_SERVER_ERROR; } memset(post, '\0', post_size); //读取POST数据 ret = read_post_data(r, &post, &post_size); if(ret != OK) { free(post); post = NULL; post_size = 0; return ret; } ap_set_content_type(r, "text/html;charset=utf-8"); ap_set_content_length(r, post_size); if(post_size == 0) { ap_rputs("no post data found", r); return OK; } ap_rputs(post, r); free(post); post = NULL; post_size = 0; return OK; } //注册函数,一般命名为”模块名 _register_hooks”,传入参数为 Apache 的内存池指针。这个函数用于通知 Apache 在何时,以何种方式注册响应函数 (handler) static void helloworld_register_hooks(apr_pool_t *p) { ap_hook_handler(helloworld_handler, NULL, NULL, APR_HOOK_MIDDLE); } /* Dispatch list for API hooks 模块的定义,Apache 模块加载器通过这个结构体中的定义来在适当的时刻调用适当的函数以处理响应。应该注意的是,第一个成员默认填写为 STANDARD20_MODULE_STUFF,最后一个成员为注册函数 */ module AP_MODULE_DECLARE_DATA helloworld_module = { STANDARD20_MODULE_STUFF, NULL, /* create per-dir config structures */ NULL, /* merge per-dir config structures */ NULL, /* create per-server config structures */ NULL, /* merge per-server config structures */ NULL, /* table of config file commands */ helloworld_register_hooks /* register hooks */ };

Relevant Link:
http://www.ibm.com/developerworks/cn/opensource/os-cn-apachehttpd/
3. mod进阶: 可配置的 echo 模块
我们继续扩展上例中的 echo_post 模块,我们将 echo_post 扩展为可配置的模块,通过修改配置文件 httpd.conf 中设置 ConvertType 的值,可以使得模块在运行时的行为发生变化
0x1: 配置信息读取
typedef struct{ int convert_type; // 转换类型 }cust_config_t;
这个结构体仅有一个成员,convert_type, 表示转换类型,如果在配置文件中该值被设置为 0,则将客户端 POST 的数据转换为大写,如果为 1,则转换为小写。这样即可通过配置信息修改模块运行时的行为
//create_config 函数用以创建一个用户自定义的结构体 static void *create_config(apr_pool_t *pool, server_rec *server); //set_mod_config 函数用以设置配置结构体中的成员,这个函数注册在 command_rec 数组中 static const char *set_mod_config(cmd_parms *params, void *config, const char *arg); //而 command_rec 数组则保存在模块声明结构体中: 定义一个 command_rec 结构体类型的数组 static const command_rec cust_echo_cmds[] = { AP_INIT_TAKE1("ConvertType", set_mod_config, NULL, RSRC_CONF, "convert type of post data"), {0} }; //注册模块回调函数 /* Dispatch list for API hooks */ module AP_MODULE_DECLARE_DATA cust_echo_post_module = { STANDARD20_MODULE_STUFF, NULL, /* create per-dir config structures */ NULL, /* merge per-dir config structures */ create_config, /* create per-server config structures */ NULL, /* merge per-server config structures */ cust_echo_cmds, /* table of config file commands */ cust_echo_post_register_hooks /* register hooks */ };
0x2: Code
/* ** mod_cust_echo_post.c -- Apache sample cust_echo_post module ** [Autogenerated via ``apxs -n cust_echo_post -g''] ** ** To play with this sample module first compile it into a ** DSO file and install it into Apache's modules directory ** by running: ** ** $ apxs -c -i mod_cust_echo_post.c ** ** Then activate it in Apache's httpd.conf file for instance ** for the URL /cust_echo_post in as follows: ** ** # httpd.conf ** LoadModule cust_echo_post_module modules/mod_cust_echo_post.so **** SetHandler cust_echo_post ** ** ** Then after restarting Apache via ** ** $ apachectl restart ** ** you immediately can request the URL /cust_echo_post and watch for the ** output of this module. This can be achieved for instance via: ** ** $ lynx -mime_header http://localhost/cust_echo_post ** ** The output should be similar to the following one: ** ** HTTP/1.1 200 OK ** Date: Tue, 31 Mar 1998 14:42:22 GMT ** Server: Apache/1.3.4 (Unix) ** Connection: close ** Content-Type: text/html ** ** The sample page from mod_cust_echo_post.c */ #include "httpd.h" #include "http_config.h" #include "http_protocol.h" #include "ap_config.h" #define DFT_BUF_SIZE 4096 module AP_MODULE_DECLARE_DATA cust_echo_post_module; static void *create_config(apr_pool_t *pool, server_rec *server); static const char *set_mod_config(cmd_parms *params, void *config, const char *arg); typedef struct { int convert_type; //转换类型 }cust_config_t; static const command_rec cust_echo_cmds[] = { AP_INIT_TAKE1("ConvertType", set_mod_config, NULL, RSRC_CONF, "convert type of post data"), {0} }; static void *create_config(apr_pool_t *pool, server_rec *server) { cust_config_t *config; config = (cust_config_t *)apr_pcalloc(pool, sizeof(cust_config_t)); return (void *)config; } static const char *set_mod_config(cmd_parms *params, void *conf, const char *arg) { cust_config_t *config = ap_get_module_config(params->server->module_config, &cust_echo_post_module); if(strcmp(params->cmd->name, "ConvertType") == 0) { config->convert_type = atoi((char *)arg); } return NULL; } /** * @brief read_post_data 从request中获取POST数据到缓冲区 * * @param req apache request_rec对象 * @param post 接收缓冲区 * @param post_size 接收缓冲区长度 * * @return */ static int read_post_data(request_rec *req, char **post, size_t *post_size){ char buffer[DFT_BUF_SIZE] = {0}; size_t bytes, count, offset; bytes = count = offset = 0; if(ap_setup_client_block(req, REQUEST_CHUNKED_DECHUNK) != OK){ return HTTP_BAD_REQUEST; } if(ap_should_client_block(req)){ for(bytes = ap_get_client_block(req, buffer, DFT_BUF_SIZE); bytes > 0; bytes = ap_get_client_block(req, buffer, DFT_BUF_SIZE)){ count += bytes; if(count > *post_size){ *post = (char *)realloc(*post, count); if(*post == NULL){ return HTTP_INTERNAL_SERVER_ERROR; } } *post_size = count; offset = count - bytes; memcpy((char *)*post+offset, buffer, bytes); } }else{ *post_size = 0; return OK; } return OK; } /* The sample content handler */ static int cust_echo_post_handler(request_rec *req) { if (strcmp(req->handler, "cust_echo_post")) { return DECLINED; } if((req->method_number != M_GET) && (req->method_number != M_POST)) { return HTTP_METHOD_NOT_ALLOWED; } char *post = (char *)malloc(sizeof(char)*DFT_BUF_SIZE); size_t post_size = DFT_BUF_SIZE; if(post == NULL) { return HTTP_INTERNAL_SERVER_ERROR; } memset(post, '\0', post_size); int ret = read_post_data(req, &post, &post_size); if(ret != OK) { free(post); post = NULL; post_size = 0; return ret; } ap_set_content_type(req, "text/html;charset=utf-8"); ap_set_content_length(req, post_size); if(post_size == 0) { ap_rputs("no post data found", req); return OK; } cust_config_t *config = ap_get_module_config(req->server->module_config, &cust_echo_post_module); if(config == NULL) { return HTTP_INTERNAL_SERVER_ERROR; } //make a copy of user post data char *converted = strdup(post); int i = 0; //convert it according to convert_type switch(config->convert_type) { case 0: for(i = 0; i < post_size; i++) { converted[i] = toupper(((char *)post[i])); } break; case 1: for(i = 0; i < post_size; i++) { converted[i] = tolower(((char *)post[i])); } break; default: break; } ap_rputs(converted, req); free(converted); converted = NULL; free(post); post = NULL; post_size = 0; return OK; } static void cust_echo_post_register_hooks(apr_pool_t *p) { ap_hook_handler(cust_echo_post_handler, NULL, NULL, APR_HOOK_MIDDLE); } /* Dispatch list for API hooks */ module AP_MODULE_DECLARE_DATA cust_echo_post_module = { STANDARD20_MODULE_STUFF, NULL, /* create per-dir config structures */ NULL, /* merge per-dir config structures */ create_config, /* create per-server config structures */ NULL, /* merge per-server config structures */ cust_echo_cmds, /* table of config file commands */ cust_echo_post_register_hooks /* register hooks */ };
运行可配置 echo 模块
LoadModule cust_echo_post_module "D:/wamp/bin/apache/APACHE~1.9/modules/mod_cust_echo_post.so"SetHandler cust_echo_post #configure for cust_echo_post ConvertType 0
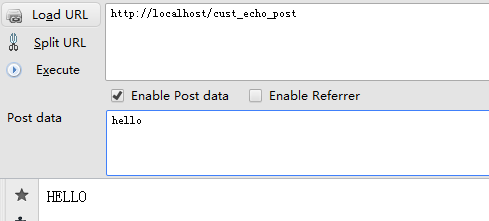
LoadModule cust_echo_post_module "D:/wamp/bin/apache/APACHE~1.9/modules/mod_cust_echo_post.so"SetHandler cust_echo_post #configure for cust_echo_post ConvertType 1

Relevant Link:
http://www.ibm.com/developerworks/cn/opensource/os-cn-apachehttpd/
4. mod进阶: 过滤器
过滤器事实上是另一种形式的模块,Apache对通用的数据结构都做过一些封装,并以库的方式提供(即APR(Apache Portable Runtime))。在过滤器中,有两个比较重要的数据结构
1. apr_bucket 2. apr_bucket_brigade: apr_bucket_birgade 相当于一个环状队列,而 apr_bucket 是队列中的元素
所有的过滤器形成一个长链,数据从上一个过滤器流入,进行过滤,然后将加工过的数据流入下一个过滤器,处理一个 HTTP 事务期间可能会多次调用某个过滤器,就象不同的块通过“桶队列”。对于所有最普通的过滤器来说,这意味着过滤器必须能够在两次调用之间保存某种上下文
我们的过滤器非常简单,从上一个过滤器中读到数据,将数据中的字符串转换为大写,然后将桶 (apr_bucket) 传递给下一个过滤器。Apache 提供了丰富的 API 来完成这一系列的操作
0x1: 大小写转换过滤器
static apr_status_t case_filter(ap_filter_t *filter, apr_bucket_brigade *bbin) { request_rec *req = filter->r; conn_rec *con = req->connection; apr_bucket *bucket; apr_bucket_brigade *bbout; //create brigade bbout = apr_brigade_create(req->pool, con->bucket_alloc); //iterate the full brigade APR_BRIGADE_FOREACH(bucket, bbin) { if(APR_BUCKET_IS_EOS(bucket) || APR_BUCKET_IS_FLUSH(bucket)) { APR_BUCKET_REMOVE(bucket); APR_BRIGADE_INSERT_TAIL(bbout, bucket); return ap_pass_brigade(filter->next, bbout); } char *data, *buffer; apr_size_t data_len; //read content of current bucket in brigade apr_bucket_read(bucket, &data, &data_len, APR_NONBLOCK_READ); buffer = apr_bucket_alloc(data_len, con->bucket_alloc); int i; for(i = 0; i < data_len; i++) { //convert buffer[i] = apr_toupper(data[i]); } apr_bucket *temp_bucket; temp_bucket = apr_bucket_heap_create(buffer, data_len, apr_bucket_free, con->bucket_alloc); APR_BRIGADE_INSERT_TAIL(bbout, temp_bucket); } return APR_SUCCESS; }
0x2: 注册过滤器
static void filter_echo_post_register_hooks(apr_pool_t *p) { ap_register_output_filter(filter_name, case_filter, NULL, AP_FTYPE_RESOURCE); }
0x3: 运行过滤器模块
对过滤器的配置要稍微复杂一些,在 httpd.conf 中,不但要使用 LoadModule 指令加载过滤器模块,还要使用 SetOutputFilter 指令来指定过滤器的应用场景
LoadModule filter_echo_post_module modules/mod_filter_echo_post.so AddOutputFilter CaseFilter .cf //指令中指定,CaseFilter 这个过滤器仅对扩展名为 .cf 的 URL 请求做过滤,其他请求则不过滤
0x4: Code Example
/* ** mod_filter_echo_post.c -- Apache sample filter_echo_post module ** [Autogenerated via ``apxs -n filter_echo_post -g''] ** ** To play with this sample module first compile it into a ** DSO file and install it into Apache's modules directory ** by running: ** ** $ apxs -c -i mod_filter_echo_post.c ** ** Then activate it in Apache's httpd.conf file for instance ** for the URL /filter_echo_post in as follows: ** ** # httpd.conf ** LoadModule filter_echo_post_module modules/mod_filter_echo_post.so **** SetHandler filter_echo_post ** ** ** Then after restarting Apache via ** ** $ apachectl restart ** ** you immediately can request the URL /filter_echo_post and watch for the ** output of this module. This can be achieved for instance via: ** ** $ lynx -mime_header http://localhost/filter_echo_post ** ** The output should be similar to the following one: ** ** HTTP/1.1 200 OK ** Date: Tue, 31 Mar 1998 14:42:22 GMT ** Server: Apache/1.3.4 (Unix) ** Connection: close ** Content-Type: text/html ** ** The sample page from mod_filter_echo_post.c */ #include "httpd.h" #include "http_config.h" #include "http_request.h" #include "http_protocol.h" #include "ap_config.h" #include "apr_general.h" #include "apr_buckets.h" #include "apr_lib.h" #include "util_filter.h" static const char *filter_name = "CaseFilter"; static apr_status_t case_filter(ap_filter_t *filter, apr_bucket_brigade *bbin){ request_rec *req = filter->r; conn_rec *con = req->connection; apr_bucket *bucket; apr_bucket_brigade *bbout; bbout = apr_brigade_create(req->pool, con->bucket_alloc); APR_BRIGADE_FOREACH(bucket, bbin){ if(APR_BUCKET_IS_EOS(bucket) || APR_BUCKET_IS_FLUSH(bucket)){ APR_BUCKET_REMOVE(bucket); APR_BRIGADE_INSERT_TAIL(bbout, bucket); return ap_pass_brigade(filter->next, bbout); } char *data, *buffer; apr_size_t data_len; apr_bucket_read(bucket, &data, &data_len, APR_NONBLOCK_READ); buffer = apr_bucket_alloc(data_len, con->bucket_alloc); int i; for(i = 0; i < data_len; i++){ buffer[i] = apr_toupper(data[i]); } apr_bucket *temp_bucket; temp_bucket = apr_bucket_heap_create( buffer, data_len, apr_bucket_free, con->bucket_alloc); APR_BRIGADE_INSERT_TAIL(bbout, temp_bucket); } return APR_SUCCESS; } /* static apr_status_t case_filter(ap_filter_t *filter, apr_bucket_brigade *bbin){ request_rec *req = filter->r; conn_rec *con = req->connection; apr_bucket *bucket; //the bucket of data apr_bucket_brigade *bbout; bbout = apr_brigade_create(req->pool, con->bucket_alloc); for(bucket = APR_BRIGADE_FIRST(bbin); bucket != APR_BRIGADE_SENTINEL(bbin); bucket = APR_BUCKET_NEXT(bucket)){ char *data, *buffer; apr_size_t data_len; apr_bucket *temp_bucket; if(APR_BUCKET_IS_EOS(bucket)){ apr_bucket *eos = apr_bucket_eos_create(con->bucket_alloc); APR_BRIGADE_INSERT_TAIL(bbout, eos); continue; } apr_bucket_read(bucket, &data, &data_len, APR_BLOCK_READ); buffer = apr_bucket_alloc(data_len, con->bucket_alloc); int i; for(i = 0; i < data_len; i++){ buffer[i] = apr_toupper(data[i]); } temp_bucket = apr_bucket_heap_create( buffer, data_len, apr_bucket_free, con->bucket_alloc); APR_BRIGADE_INSERT_TAIL(bbout, temp_bucket); } return ap_pass_brigade(filter->next, bbout); } */ static void filter_echo_post_register_hooks(apr_pool_t *p) { ap_register_output_filter(filter_name, case_filter, NULL, AP_FTYPE_RESOURCE); } /* Dispatch list for API hooks */ module AP_MODULE_DECLARE_DATA filter_echo_post_module = { STANDARD20_MODULE_STUFF, NULL, /* create per-dir config structures */ NULL, /* merge per-dir config structures */ NULL, /* create per-server config structures */ NULL, /* merge per-server config structures */ NULL, /* table of config file commands */ filter_echo_post_register_hooks /* register hooks */ };
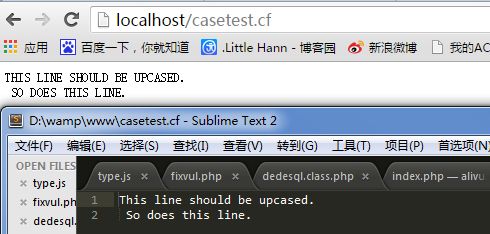
过滤器将该文件中的字符串转换为大写字母输出
Relevant Link:
http://www.ibm.com/developerworks/cn/opensource/os-cn-apachehttpd/ http://www.ibm.com/developerworks/cn/linux/middleware/l-apache/
Copyright (c) 2015 LittleHann All rights reserved