Pandas 基础教程
目录
1 Pandas 简介
2 Pandas 数据结构 - Series
3 Pandas 数据结构 - DataFrame
4 Pandas CSV 文件
1 Pandas 简介
Pandas 是 Python 语言的一个扩展程序库,用于数据分析。
Pandas 是一个开放源码、BSD 许可的库,提供高性能、易于使用的数据结构和数据分析工具。
Pandas 名字衍生自术语 "panel data"(面板数据)和 "Python data analysis"(Python 数据分析)。
Pandas 一个强大的分析结构化数据的工具集,基础是 Numpy(提供高性能的矩阵运算)。
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域。
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
Series 是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
2 Pandas 数据结构 - Series
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
# data:一组数据(ndarray 类型)。
# index:数据索引标签,如果不指定,默认从 0 开始。
# dtype:数据类型,默认会自己判断。
# name:设置名称。
# copy:拷贝数据,默认为 False。import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar)输出结果:

从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
import pandas as pd
a = [1, 2, 3]
myvar = pd.Series(a)
print(myvar[1])
2我们可以指定索引值,如下实例:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar)输出结果:

根据索引值读取数据:
import pandas as pd
a = ["Google", "Runoob", "Wiki"]
myvar = pd.Series(a, index = ["x", "y", "z"])
print(myvar["y"])
Runoob我们也可以使用 key/value 对象,类似字典来创建 Series:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)输出结果:

从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下实例:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)输出结果:

设置 Series 名称参数:
import pandas as pd
sites = {1: "Google", 2: "Runoob", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="RUNOOB-Series-TEST" )
print(myvar)输出结果:

3 Pandas 数据结构 - DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。
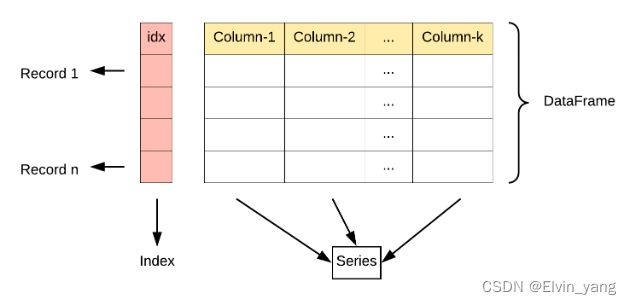
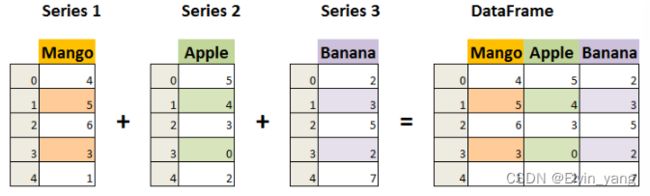
DataFrame 构造方法如下:
pandas.DataFrame( data, index, columns, dtype, copy)
# data:一组数据(ndarray、series, map, lists, dict 等类型)。
# index:索引值,或者可以称为行标签。
# columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
# dtype:数据类型。
# copy:拷贝数据,默认为 False。import pandas as pd
data = [['Google',10],['Runoob',12],['Wiki',13]]
df = pd.DataFrame(data,columns=['Site','Age'],dtype=float)
print(df)输出结果:

以下实例使用 ndarrays 创建,ndarray 的长度必须相同, 如果传递了 index,则索引的长度应等于数组的长度。如果没有传递索引,则默认情况下,索引将是range(n),其中n是数组长度。
import pandas as pd
data = {'Site':['Google', 'Runoob', 'Wiki'], 'Age':[10, 12, 13]}
df = pd.DataFrame(data)
print (df)输出结果:

从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列):

还可以使用字典(key/value),其中字典的 key 为列名:
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print (df)
a b c
0 1 2 NaN
1 5 10 20.0没有对应的部分数据为 NaN。
Pandas 可以使用 loc 属性返回指定行的数据,如果没有设置索引,第一行索引为 0,第二行索引为 1,以此类推:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行
print(df.loc[0])
# 返回第二行
print(df.loc[1])
calories 420
duration 50
Name: 0, dtype: int64
calories 380
duration 40
Name: 1, dtype: int64注意:返回结果其实就是一个 Pandas Series 数据。
也可以返回多行数据,使用 [[ ... ]] 格式, ... 为各行的索引,以逗号隔开:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
# 数据载入到 DataFrame 对象
df = pd.DataFrame(data)
# 返回第一行和第二行
print(df.loc[[0, 1]])
calories duration
0 420 50
1 380 40注意:返回结果其实就是一个 Pandas DataFrame 数据。
我们可以指定索引值,如下实例:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
print(df)
calories duration
day1 420 50
day2 380 40
day3 390 45Pandas 可以使用 loc 属性返回指定索引对应到某一行:
import pandas as pd
data = {
"calories": [420, 380, 390],
"duration": [50, 40, 45]
}
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
# 指定索引
print(df.loc["day2"])
calories 380
duration 40
Name: day2, dtype: int644 Pandas CSV 文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
Pandas 可以很方便的处理 CSV 文件,本文以 nba.csv 为例,你可以下载 nba.csv 或Numpy 查看。以下是一部分数据:
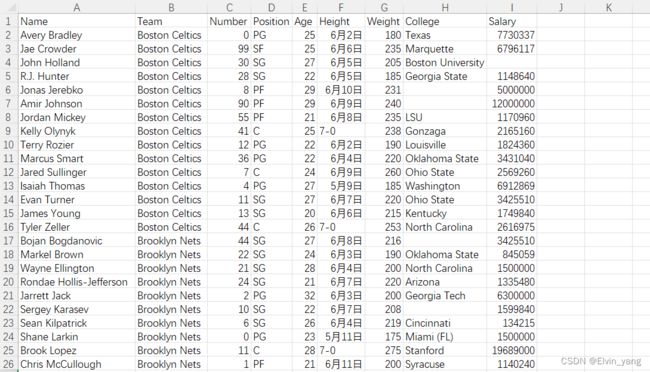
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.to_string())to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 ... 代替。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df)输出结果:

我们也可以使用 to_csv() 方法将 DataFrame 存储为 csv 文件:
import pandas as pd
# 三个字段 name, site, age
nme = ["Google", "Runoob", "Taobao", "Wiki"]
st = ["www.google.com", "www.runoob.com", "www.taobao.com", "www.wikipedia.org"]
ag = [90, 40, 80, 98]
# 字典
dict = {'name': nme, 'site': st, 'age': ag}
df = pd.DataFrame(dict)
# 保存 dataframe
df.to_csv('site.csv')执行成功后,我们打开 site.csv 文件,显示结果如下:

数据处理
head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(10))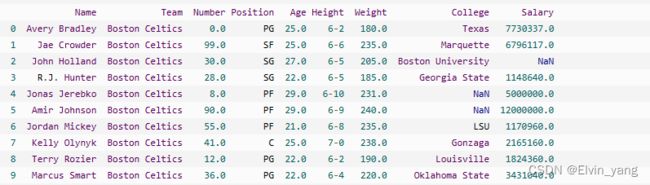
tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN。
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.tail(10))
info() 方法返回表格的一些基本信息:
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.info())
non-null 为非空数据,我们可以看到上面的信息中,总共 458 行,College 字段的空值最多。
参考资料:Pandas 教程 | 菜鸟教程 (runoob.com)