解决GC毛刺问题——转转搜索推荐服务JDK17升级实践
解决GC毛刺问题——转转搜索推荐服务JDK17升级实践
-
- 1 升级背景
- 2 JDK17简介
-
- 2.1 新语法简介
- 2.2 新GC算法简介
- 3 升级过程
-
- 3.1 升级步骤
- 3.2 遇到问题及解决方法
- 4 升级效果
-
- 4.1 整体耗时对比
- 4.2 分节点耗时对比
- 4.3 GC停顿时长对比
- 4.4 堆空间占用对比
- 5 总结
1 升级背景
随着转转业务规模的不断增长,我们的搜索推荐服务正在面临严峻的垃圾回收(Garbage Colletion, GC)带来的服务接口耗时毛刺问题。
我们当前所使用的JDK1.8版本中的CMS和G1收集器,在应对请求高峰时均不理想,经常出现的停顿问题直接影响了服务的可用性及用户体验。
我们面临的核心挑战是:
- 服务请求流量激增时,GC次数频繁是我们的一大痛点,每分钟有可能达到十几次以上。另一方面,单次GC停顿时间也较长,可高达数十毫秒。这不但降低了服务的可用性,也限制了服务的吞吐量,对于我们的在线服务是难以接受的。
- 同时GC参数的调优工作遇到瓶颈,尽管还可以通过减少新对象创建速率等方式继续优化,但整体投入产出比偏低。
为此,我们计划通过升级JDK版本来实现GC问题的改善。JDK新版本带来了如ZGC、Shenandoah等新一代GC算法,它们能够提供极低的GC停顿时间,有望解决我们的在线服务目前的GC毛刺问题。
我们的升级目标是利用新版本JDK中的新GC算法,将搜索推荐服务的GC停顿时间降低90%以上,保证高流量服务的可用性和吞吐量,进一步提升用户体验。
2 JDK17简介
我们选择将JDK版本升级到JDK17,主要原因有:
- 一方面,JDK17是目前最新的长期支持(Long Term Support,LTS)版本,相比其他版本,它能提供更稳定和持久的支持,同时也有大量企业应用了JDK17,有丰富成熟的使用经验。可以预见JDK17在未来一段时间也将会是主流版本,能得到更好的社区支持。
- 另一方面,JDK17作为新一代版本,与旧版JDK8相比,既能与现有代码上保持兼容性,又在语法和GC算法等多个方面做出了重要改进和优化。如JDK17包含了可用于生产环境的ZGC,且它的性能在历代版本迭代下,得到大幅增强。
2.1 新语法简介
具体来看,此次JDK 17的升级在语法上带来了以下几个值得注意的新特性:
类型推断
从JDK10版本开始,引入了局部变量类型推断(Local Variable Type Inference)功能,它可以让我们在声明局部变量时省略变量类型,而由编译器根据变量初始化的值自动推断出类型。
// 传统变量声明方法
String str = "hello";
// 使用类型推断的变量声明方法
var str = "hello";
Stream API的增强
JDK新版本对Stream API进行了一些增强,主要有:
takeWhile和dropWhile会对流中每个元素逐一校验,遇到第一个不符合条件的元素终止,takeWhile返回终止位置前面的所有元素,而dropWhile则返回包含终止位置后面的所有元素。它们功能虽然与filter类似,区别是前者并非对整个流进行校验,可以提升过滤效率,但需要注意流内元素的顺序。
var list = List.of(1,2,3,4,5,6);
// 输出:1,2;
list.stream().takeWhile(n -> n < 3).forEach(System.out::println);
// 输出:3,4,5,6
list.stream().dropWhile(n -> n < 3).forEach(System.out::println);
iterate可以生成一个无限的流,它在JDK9之前需要limit()等操作来配合终止,否则将无限递归下去。在JDK9中iterate新增了一个重载方法,现在支持使用条件来终止,它在语法上更简洁,也提供了更多的灵活性。
// 输出:1,2,4,8,...,512,1024
Stream.iterate(1, n -> n <= 1024, n -> n * 2).forEach(System.out::println);
集合API新增方法
操作集合将更加方便,如可以更加简洁的创建List和Map,但需要注意这种方式创建的集合均是不可变的。
var list = List.of(1, 2, 3, 4, 5);
var map1 = Map.of("a", 1, "b", 2);
var map2 = Map.ofEntries(Map.entry("a", 1), Map.entry("b", 2));
}
同时新增了多种Collector方法,如可以通过groupingBy新增的重载方法实现多级分组,假设Product类有Cate、Brand、Model成员,则可以做如下多层分组收集:
// 按Cate、Brand分组,收集Model列表
List<Product> products = new ArrayList<>();
Map<Cate, Map<Brand, List<Model>>> result = products.stream()
.collect(Collectors.groupingBy(Product::getCate,
Collectors.groupingBy(Product::getBrand,
Collectors.mapping(Product::getModel, Collectors.toList()))));
Swtich新语法
JDK12开始,switch语句增加了新的语法形式,允许使用更灵活的表达式匹配,并可以返回值,提升了代码的简洁性。
int month = ...;
String days = switch(month) {
case 1, 3, 5, 7, 8, 10, 12 -> "31 days";
case 4, 6, 9, 11 -> "30 days";
case 2 -> "28 or 29 days";
}
文本块
JDK13开始提供了一种新的字符串格式,用户可以选择用三个双引号(“”")作为字符串开头及结尾,直接编写多行文本,它为JSON、SQL等格式的字符串编写提升了简洁性和便利性。
String textBlock = """
This is a text block
spanning multiple lines.
""";
Record类型
JDK14中新增的Record提供了更简洁的语法来生成只用于数据存储的类,并自动生成访问方法、equals和hashCode比较方法以及toString方法,它可以在类内部或方法内部生成。它相比class类更轻量简洁,相比Pair、Triple等组合类Record的语义上更加明确、代码可读性更强。
void someMethod() {
record Product(long id, String category);
Product product = new Product(101L, "phone");
long productId = product.getId();
String productCategory = product.getCategory();
}
模式匹配新语法
JDK14版本引入了模式匹配新语法,避免了冗余的类型转换语句。
Object obj = ...;
if (obj instanceof String s) {
System.out.println("String: " + s.length());
} else if (obj instanceof Integer i) {
System.out.println("Integer: " + i);
} else {
System.out.println("Unknown object");
}
JDK17版本后,新的模式匹配方式也可以在Switch语句中使用了。
Object obj = ...;
switch(obj) {
case String s -> System.out.println("String: " + s.length());
case Integer i -> System.out.println("Integer: " + i);
default -> System.out.println("Unknown object");
}
密封类
密封类(Sealed Class)是JDK15引入的新特性,当使用sealed关键字修饰一个抽象类时,表示这个抽象类只允许指定的类来继承实现。
如下ProductField类只允许Cate、Brand、Model类继承,这种特性避免了意料外的类型扩展,提升了类型安全性。
sealed abstract class ProductField permits Cate, Brand, Model {
//...
}
此外,JDK新版本还有向量API等新特性和诸多改进等待我们探索发现。
2.2 新GC算法简介
ZGC介绍
ZGC在JDK11作为实验性的GC算法被引入时,最初的设计目标是实现10毫秒以内的最大停顿时间。在过去一段时间里,ZGC经过JDK版本的数次迭代,在JDK15中被宣布为可用于生产,目前据官方介绍已经可以实现亚毫秒级的最大停顿时间,且停顿时间不随堆内存、存活对象集合或GCRoot集合大小的增加而增加,它可以处理从8MB到16TB的大范围堆内存。
在官方介绍里,ZGC是并发的、基于区域的(Region-based)、压缩的(Compacting)、NUMA感知(NUMA-aware)的垃圾回收器。它主要使用了染色指针(Colored Pointor)和读屏障(Load Barriers)技术,并在新一代的JDK21版本中实现了分代回收,它的主要工作是在用户线程工作执行时完成的,这大大降低了GC对应用响应时间的影响。
使用如下JVM启动参数可以快速应用ZGC:
-XX:+UseZGC
Shenandoah GC介绍
Shenandoah GC是一种全新的低延迟垃圾收集器,在JDK 8的部分版本可用,从JDK 11版本正式引入,它通过读写屏障和并发标记技术,可以极大缩短GC时的应用程序停顿。
相比CMS、G1等算法,其停顿时间更短,支持超大内存,非常适合对响应时间敏感类型的服务。由于Shenandoah使用了读写屏障技术,虽然可能导致吞吐量略降,但总体来说是更有效的GC算法之一。
使用如下参数可以快速应用Shenandoah GC:
-XX:+UseShenandoahGC
3 升级过程
JDK版本升级无需做太多代码改动,但要平滑过渡到新版本,也需要做充分准备和规划。本节将分享我们升级到JDK17的具体步骤,在此过程中遇到的问题及解决方法,以及对ZGC相关问题的分析。
3.1 升级步骤
安装JDK17
我们在本地测试时选择了Eclipse Temurin Build版本,根据官网介绍它是由基于OpenJDK的开源Java SE产生的构建版本,这里根据开发环境的机器配置下载并安装了jdk-17.0.7+7 macos aarch64版本。
调整IDE配置
在使用IntelliJ Idea开发环境时,可以在文件–项目结构配置中,将SDK选项调整到刚刚安装的JDK版本。

调整项目配置
由于我们的项目是Maven项目,需要选择POM文件,修改Maven的编译插件的source和target配置到17。
<properties>
<jdk.version>17jdk.version>
properties>
...
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>${java.version}source>
<target>${java.version}target>
configuration>
plugin>
plugins>
部署测试
本地编译测试通过后,意味着可以到测试环境进行部署和验证了,验证内容包括全场景的功能验证、DIFF验证、压力性能测试等等(由于部署功能是由公司其他系统提供,不展开叙述)。
升级JDK17后,JVM启动参数需要调整,一些旧参数被废弃,同时增加新的参数,我们用于测试环境部署的参数为:
-Xms6g -Xmx6g -XX:MetaspaceSize=256m -XX:MaxMetaspaceSize=512m -Xss256k -XX:+UseZGC -XX:ParallelGCThreads=12
生产环境部署及效果数据回收
升级JDK后,回收线上服务的效果数据至关重要,我们主要关注服务延时表现、GC暂停表现以及内存消耗表现。
我们选择服务集群的50%节点来部署JDK17,另外50%节点保持JDK8不变作为对照组,分配节点时,保持各组的节点机器配置情况一致,将实验变量控制在仅JDK版本的切换上。
同时将服务访问的延时信息、GC暂停信息、堆内存使用信息上报到日志收集系统。由于前者的日志规模庞大,为了获取更精确的统计信息,通过上报到大数据平台并使用HiveSql分析,后两者则通过上报Promethues监控平台来实现实时信息收集。
3.2 遇到问题及解决方法
在实际编译和部署的过程中,还可能会遇到各种各样的问题,下面我们对遇到的问题及解决方法做了一些梳理。
以下为编译期间遇到的一些问题:
非法字符引发的异常
Maven编译期间遇见如下报错:
[ERROR] Internal error: java.lang.IllegalArgumentException: Malformed \uxxxx encoding. -> [Help 1]
问题原因:这是Maven在加载一些配置文件时遇到了不兼容的编码字符导致的。本地Maven仓库路径下的resolver-status.properties文件中存在格式不正确的unicode编码字符,这些字符在JDK 17的字符串处理方式下无法解析。
解决方法:使用以下命令,递归删除本地仓库下所有的resolver-status.properties文件:
find ~/.m2/ -name resolver-status.properties -delete
包不存在引发的异常
编译器期间提示包不存在:
import javafx.util.Pair
问题原因:javafx等包在JDK新版本中被默认移除。
解决方法:可以使用apache.commons提供的Pair类替代,也可以手动引入被移除的依赖,其他被移除的类也可以通过类似的方法解决。
以下为部署期间遇到的问题:
JVM参数引发的异常
启动阶段可能遇到类似如下问题:
Unrecognized VM option 'UseGCLogFileRotation'
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
问题原因:部分JVM参数在新版本不再兼容,导致不能识别。
解决方法:从启动参数里将不兼容的参数移除即可,同时寻找替代参数。
反射访问引发的异常
如以下日志所示,我们在初始化apollo配置中心组件时遇到了启动异常,从异常描述看是程序反射访问期间引起的。
java.lang.IllegalArgumentException: Cannot instantiate interface org.springframework.context.ApplicationContextInitializer : com.ctrip.framework.apollo.spring.boot.ApolloApplicationContextInitializer
...
at com.bj58.spat.scf.server.bootstrap.Main.main(Main.java:27) [zzscf.server-2.7.12.jar:?]
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [com.ctrip.framework.apollo.spring.boot.ApolloApplicationContextInitializer]: Constructor threw exception; nested exception is com.ctrip.framework.apollo.exceptions.ApolloConfigException: [ARCH_APOLLO_CLIENT]Unable to load instance for com.ctrip.framework.apollo.spring.config.ConfigPropertySourceFactory!
at org.springframework.beans.BeanUtils.instantiateClass(BeanUtils.java:154) ~[spring-beans-4.3.12.RELEASE.jar:4.3.12.RELEASE]
at org.springframework.boot.SpringApplication.createSpringFactoriesInstances(SpringApplication.java:409) ~[spring-boot-1.5.8.RELEASE.jar:1.5.8.RELEASE]
... 8 more
...
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed module @5e265ba4
at java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354) ~[?:?]
at java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297) ~[?:?]
at java.lang.reflect.Method.checkCanSetAccessible(Method.java:199) ~[?:?]
at java.lang.reflect.Method.setAccessible(Method.java:193) ~[?:?]
...
问题原因:新版本JDK引入了模块访问控制,跨模块时无法简单的直接通过反射访问了,上述异常是想要通过反射访问Java内部模块而抛出的
解决方法:对于此类问题,可以通过临时增加如下启动参数解决,也可以查阅依赖包的新版本,了解它们是否已对JDK新版本做出了适配
--add-opens java.base/java.lang=ALL-UNNAMED
java.base/java.lang是本次异常需要用到的模块参数,在解决此类异常时,需要根据实际要访问的模块名进行调整,以下为我们收集的一些启动参数,可以按需增加启动参数配置。
--add-opens java.base/java.lang=ALL-UNNAMED --add-opens java.base/java.io=ALL-UNNAMED --add-opens java.base/java.math=ALL-UNNAMED --add-opens java.base/java.net=ALL-UNNAMED --add-opens java.base/java.nio=ALL-UNNAMED --add-opens java.base/java.security=ALL-UNNAMED --add-opens java.base/java.text=ALL-UNNAMED --add-opens java.base/java.time=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/jdk.internal.access=ALL-UNNAMED --add-opens java.base/jdk.internal.misc=ALL-UNNAMED
注解类型被默认移除引发的异常
启动过程中,发现抛出了如下空指针异常
Caused by: java.lang.NullPointerException: Cannot invoke "String.length()" because "s" is null
at java.base/java.net.URLEncoder.encode(URLEncoder.java:224)
at java.base/java.net.URLEncoder.encode(URLEncoder.java:196)
at com.bj58.zhuanzhuan.arch.service.manager.sdk.client.CallPermissionService.initUri(CallPermissionService.java:192)
at com.bj58.zhuanzhuan.arch.service.manager.sdk.client.CallPermissionService.(CallPermissionService.java:72)
at com.bj58.spat.scf.server.filter.BlackKeyRequestFilter.afterPropertiesSet(BlackKeyRequestFilter.java:120)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.invokeInitMethods(AbstractAutowireCapableBeanFactory.java:1687)
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.initializeBean(AbstractAutowireCapableBeanFactory.java:1624)
... 15 more
问题原因:分析调用链路后发现,问题发生在一个上下文类,它的init方法是通过@PostConstruct注解触发执行的,该注解在JDK新版本中被默认移除了,导致init方法未能执行
解决方法:短期可以通过手动引入以下依赖方式解决,长期同样可以查阅依赖包维护方的更新日志,或与维护方进行沟通,将依赖更新到已适配版本。
javax.annotation
javax.annotation-api
1.3.2
此外我们在发布到生产环境后,还遇到了以下问题:
ZGC的虚拟内存申请的疑问
我们的服务升级JDK并在实际生产环境部署后,同物理节点的其他服务曾出现了一次短暂的资源耗尽异常,当时我们怀疑导致问题原因之一是ZGC申请了过多的虚拟内存。
针对ZGC申请过多虚拟内存问题,我们经过排查发现,这并不是JDK17存在的问题,而是由ZGC自身的实现机制所导致的。ZGC通过染色指针和多重映射技术来实现高吞吐低延迟的GC。
为了实现染色指针,ZGC需要使用地址高位额外的bit来记录对象状态,所以需要的虚拟内存空间远高于实际堆大小。此外,以目前JDK17版本,它还会为不同状态的对象分配独立的虚拟内存,以实现并发回收,具体来说需要为remapped、marked0、marked1三种状态申请三份独立虚拟内存空间。
以4TB堆为例,ZGC需要4bit用于染色,所以需要4TB * 2^4 = 128TB虚拟内存。它还会为每种染色状态各自申请128TB空间。所以4TB堆最终会申请128TB * 3约等于384TB的虚拟内存。
本例中我们的服务实际使用6GB堆,通过与内存工具Native Memory Tracking输出结果比对,发现跟公式计算结果一致,ZGC申请了约300GB的虚拟内存,符合其技术实现的需要。
所以结论是ZGC申请虚拟内存并非JDK问题,是其特有的技术实现方式导致。
4 升级效果
以下是我们在转转的通用推荐服务升级过程中,持续对比三个全天收集到的效果数据,我们设立50%节点升级到JDK17作为实验组,另50%节点不升级作为对照组。
4.1 整体耗时对比
首先看下服务的整体耗时数据,如下图所示,可以看到该服务升级JDK17后tp999及tp9999时间有显著降低。
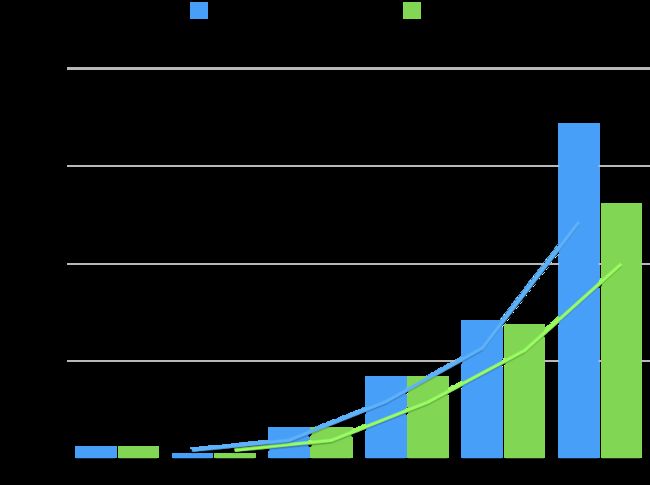
整体耗时对比
通过新版本GC算法的引入,服务处理请求的尾部延时情况得到了改善,响应时间的毛刺问题明显减轻。
下表为详细数据:
| 指标/版本 | JDK8 | JDK17 | 降幅 |
|---|---|---|---|
| AVG耗时 | 22ms | 22ms | 持平 |
| TP50耗时 | 11ms | 11ms | 持平 |
| TP90耗时 | 57ms | 57ms | 持平 |
| TP99耗时 | 149ms | 148ms | 0.67% |
| TP999耗时 | 249ms | 242ms | 2.81% |
| TP9999耗时 | 601ms | 458ms | 23.78% |
4.2 分节点耗时对比
在分节点的指标对比上,我们发现应用JDK17的节点在tp999和tp9999这两个高延迟分位数指标上的表现更加平稳。
如下图所示,相比保持JDK8的对照组节点,升级到JDK17的实验组节点,其tp999和tp9999指标的变化曲线更加平坦。
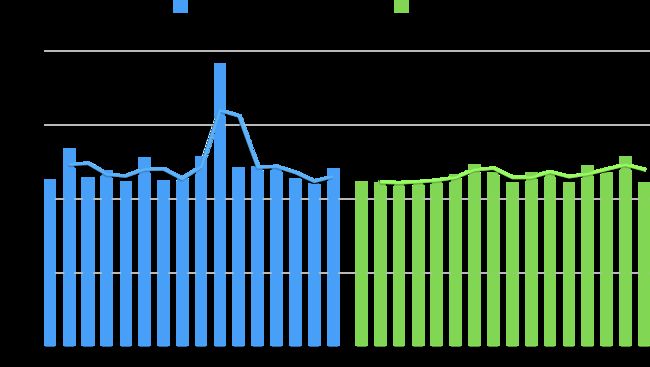
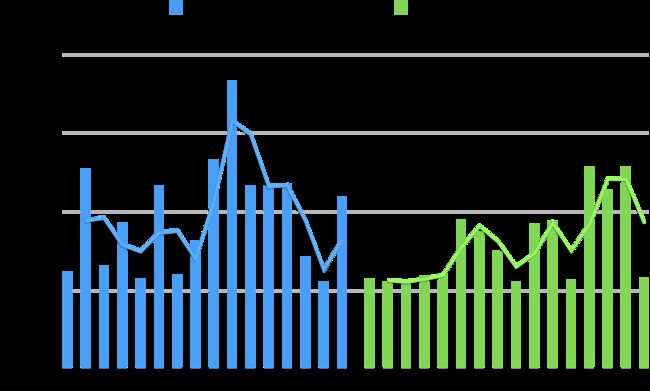
4.3 GC停顿时长对比
对于GC数据,我们收集了服务晚间4小时JDK8和JDK17版本的GC停顿数据。JDK8统计了其Young GC的暂停时间,而JDK 17统计了ZGC Pause时间。
从下表可以明显看出,使用JDK17的ZGC算法后,GC停顿时长大幅减少。JDK8下YGC每分钟平均暂停时间为221ms,而JDK 17下的ZGC只有0.37ms,降幅高达99.83%。
| 指标/版本 | JDK8 | JDK17 | 降幅 |
|---|---|---|---|
| 统计口径 | YGC时间 | ZGC Pause时间 | - |
| 总时长 | 106250ms | 221ms | 99.67% |
| 每分钟平均时长 | 355ms | 0.37ms | 99.83% |
停顿时间的降低不仅提高了服务的可用性,也使系统吞吐量获得大幅提升。
4.4 堆空间占用对比
从下表统计数据可以看出,使用JDK 17后,相同堆空间配置下,实际堆内存占用有所降低,堆空间的利用效率得到提高。
在同为6G堆大小情况下,JDK 8堆占用平均为2.92G,占比48.7%;而JDK 17堆占用平均减少至2.42G,占比降至40.3%。堆内存占用比降低了17.2%。
这表明在不改变堆区设置的前提下,JDK 17可以提高堆空间的利用效率,降低内存占用,为系统留出更多可用内存空间,从而提高系统稳定性。
| 指标/版本 | JDK8 | JDK17 | 降幅 |
|---|---|---|---|
| 堆空间申请 | 6G | 6G | - |
| 每分钟平均堆占用 | 2.922G | 2.419G | 17.20% |
| 每分钟平均堆占用比 | 48.70% | 40.32% | 17.20% |
另外ZGC提供了-XX:SoftMaxHeapSize参数,用于弹性调节堆空间的最大值,当堆大小未超出设定值时可以释放更多空闲内存。
5 总结
截止至发文,服务已成功部署应用JDK17并平稳运行一月有余。通过本次升级,我们获得了显著的GC停顿时间和内存占用率的改善效果,有效解决了服务GC问题,进而降低了服务高分位延迟指标,充分验证了JDK17新版本GC算法的优势。
同时,我们也积累了语法改进、升级中跨部门协调、问题排查等方面的宝贵经验。升级过程中遇到了服务稳定性问题,也让我们意识到需要对新特性有更深入的理解,平稳地应用到生产环境。
后续我们将继续关注JDK新版本的特性改进,并逐步将搜索推荐核心服务完全升级到JDK17新版本,以获得更好的开发体验和服务运行效果。
关于作者
曾祥瑞,转转搜索推荐研发工程师
锐意进取,勇于试验,与时俱进。
转转研发中心及业界小伙伴们的技术学习交流平台,定期分享一线的实战经验及业界前沿的技术话题。
关注公众号「转转技术」(综合性)、「大转转FE」(专注于FE)、「转转QA」(专注于QA),更多干货实践,欢迎交流分享~