基于PaddleOCR开发懒人精灵文字识别插件
目的
懒人精灵是 Android 平台上的一款自动化工具,它通过编写 lua 脚本,结合系统的「 无障碍服务 」对 App 进行自动化操作。在文字识别方面它提供的有一款OCR识别插件,但是其中有识别速度慢,插件大的缺点,所以这里将讲解一下如何集成基于PaddleOCR文字识别开发的插件,阅读本篇文字需要对PaddleOCR有个基本的了解,还需要有一点Android开发基础,文章最后有相关插件下载地址。
准备工作
1、android studio最新版本即可
下载地址:Download Android Studio & App Tools - Android Developers
2、下载PaddleOCR提供的安卓版文字识别demo
下载地址:PaddleOCR/deploy/android_demo at release/2.5 · PaddlePaddle/PaddleOCR · GitHub
3、导入Android studio并成功运行
以上三步工作完成后,将开始我们的懒人精灵文字识别插件开发。
插件开发
1、项目结构对比
修改前 VS 修改后,调整了一些文件,去除了Activity入口。
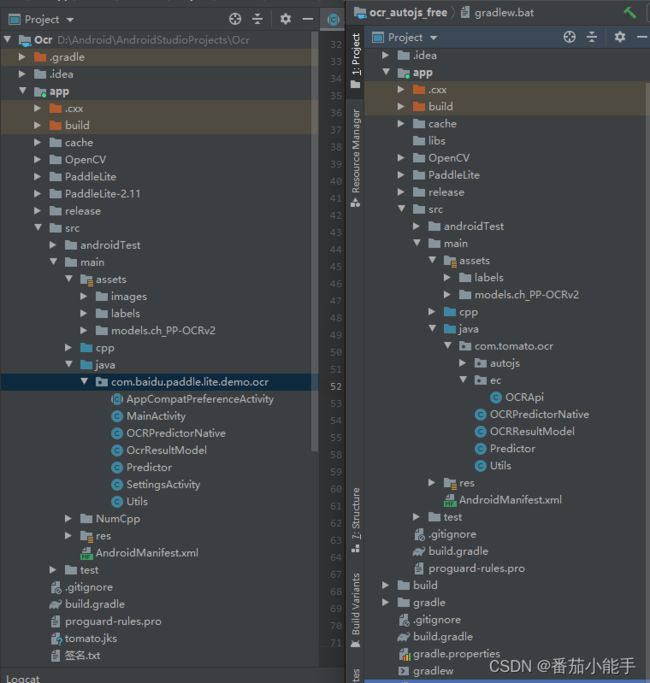
2、插件SDK集成
在项目的build.gradle文件中添加:
allprojects {
repositories {
// ...
maven { url 'https://jitpack.io' }
}
}在app的build.gradle文件中添加
dependencies {
// ...
implementation 'com.alibaba:fastjson:1.1.46.android'
}3、删除无用的Activity文件

4、修改AndroidManifest.xml
两处包名替换成自己的包名,其他地方如下代码不动。
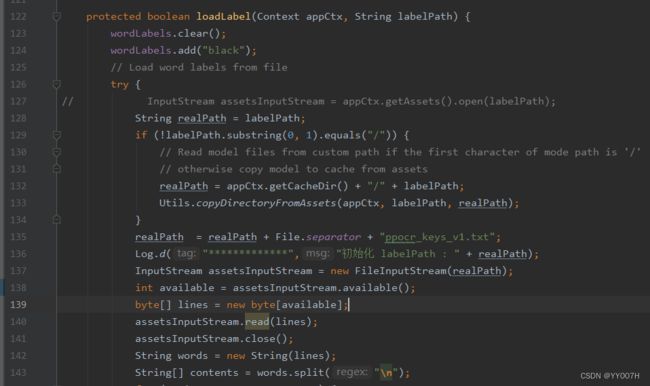
5、修改Predictor文件
添加这两行文件:


调整loadLabel代码如下:
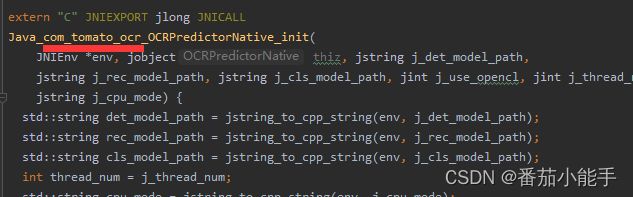
6、修改cpp包名
修改native.cpp文件,将官方的_com_baidu_paddle_lite_demo_ocr_替换成我们自己的包名,如_com_tomato_ocr_,如下截图:

7、新建OCRApi接口类
package com.tomato.ocr.ec;
import android.content.Context;
import android.graphics.Bitmap;
import android.graphics.BitmapFactory;
import android.graphics.Point;
import android.media.ExifInterface;
import android.util.Log;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import com.tomato.ocr.OCRResultModel;
import com.tomato.ocr.Predictor;
import com.tomato.ocr.Utils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class OCRApi {
private final int useOpencl = 0;
private final int cpuThreadNum = 1;
private final String cpuPowerMode = "LITE_POWER_HIGH";
private final int detLongSize = 960;
private final float scoreThreshold = 0.1f;
// 检测
protected int run_det = 1;
// 分类
protected int run_cls = 1;
// 识别
protected int run_rec = 1;
private final String assetModelDirPath = "models/ch_PP-OCRv2";
private String assetlabelFilePath = "labels/ppocr_keys_v1.txt";
private Context mContext;
private Predictor mPredictor;
private static OCRApi ocrApi;
public static OCRApi init(Context mContext) {
if (ocrApi == null) {
ocrApi = new OCRApi(mContext);
}
return ocrApi;
}
public OCRApi(Context mContext) {
this.mContext = mContext;
try {
String path = Utils.setPathForDefaultDataForLr(mContext, this.getClass());
Log.d("OCR加载路径", path);
} catch (IOException e) {
e.printStackTrace();
}
this.mPredictor = new Predictor();
boolean flag = this.mPredictor.init(this.mContext, assetModelDirPath, assetlabelFilePath, useOpencl, cpuThreadNum,
cpuPowerMode,
detLongSize, scoreThreshold);
if (!flag) {
Log.d("*************", "初始化失败");
} else {
Log.d("*************", "初始化成功");
}
}
public void release() {
if (mPredictor != null) {
mPredictor.releaseModel();
}
if (ocrApi != null) {
ocrApi = null;
}
}
public String ocrFile(final String imagePath) {
return this.ocrFile(imagePath, -1);
}
public String ocrFile(final String imagePath, int type) {
if (type == 0) {
// 只检测
return this.ocrFile(imagePath, 1, 0, 0).toJSONString();
} else if (type == 1) {
// 方向分类 + 识别
return this.ocrFile(imagePath, 0, 1, 1).toJSONString();
} else if (type == 2) {
// 只识别
return this.ocrFile(imagePath, 0, 0, 1).toJSONString();
} else if (type == 3) {
// 检测 + 识别
return this.ocrFile(imagePath, 1, 0, 1).toJSONString();
}
// 默认 检测 + 方向分类 + 识别
return this.ocrFile(imagePath, 1, 1, 1).toJSONString();
}
private JSONArray ocrFile(final String imagePath, int run_det, int run_cls, int run_rec) {
try {
Bitmap image;
if (imagePath.contains(".jpg") || imagePath.contains(".JPG") || imagePath.contains(".jpeg") || imagePath.contains(".JPEG")) {
ExifInterface exif = null;
exif = new ExifInterface(imagePath);
int orientation = exif.getAttributeInt(ExifInterface.TAG_ORIENTATION,
ExifInterface.ORIENTATION_UNDEFINED);
image = BitmapFactory.decodeFile(imagePath);
image = Utils.rotateBitmap(image, orientation);
} else {
image = BitmapFactory.decodeFile(imagePath);
}
this.mPredictor.setInputImage(image);
boolean flag = runModel(run_det, run_cls, run_rec);
if (!flag) {
Log.d("****************", "无法运行!");
return new JSONArray();
}
return transformOCRResult(this.mPredictor.outputResultList);
} catch (IOException e) {
e.printStackTrace();
}
return new JSONArray();
}
public String ocrBitmap(final Bitmap bitmap) {
return this.ocrBitmap(bitmap, -1);
}
public String ocrBitmap(final Bitmap bitmap, int type) {
if (type == 0) {
// 只检测
return this.ocrBitmap(bitmap, 1, 0, 0).toJSONString();
} else if (type == 1) {
// 方向分类 + 识别
return this.ocrBitmap(bitmap, 0, 1, 1).toJSONString();
} else if (type == 2) {
// 只识别
return this.ocrBitmap(bitmap, 0, 0, 1).toJSONString();
} else if (type == 3) {
// 检测 + 识别
return this.ocrBitmap(bitmap, 1, 0, 1).toJSONString();
}
// 默认 检测 + 方向分类 + 识别
return this.ocrBitmap(bitmap, 1, 1, 1).toJSONString();
}
private JSONArray ocrBitmap(Bitmap bitmap, int run_det, int run_cls, int run_rec) {
this.mPredictor.setInputImage(bitmap);
boolean flag = runModel(run_det, run_cls, run_rec);
if (!flag) {
Log.d("****************", "无法运行!");
return new JSONArray();
}
return transformOCRResult(this.mPredictor.outputResultList);
}
private boolean runModel(int run_det, int run_cls, int run_rec) {
return this.mPredictor.runModel(run_det, run_cls, run_rec);
}
private JSONArray transformOCRResult(List ocrResultModelList) {
JSONArray jsonArray = new JSONArray();
for (OCRResultModel ocrResultModel : ocrResultModelList) {
JSONObject jsonObject = new JSONObject();
jsonObject.put("words", ocrResultModel.getLabel());
JSONArray objects = new JSONArray();
for (Point point : ocrResultModel.getPoints()) {
JSONArray points = new JSONArray();
points.add(point.x);
points.add(point.y);
objects.add(points);
}
jsonObject.put("location", objects);
jsonObject.put("score", ocrResultModel.getConfidence());
jsonArray.add(jsonObject);
}
Log.d("OCR", jsonArray.toJSONString());
return jsonArray;
}
}
8、打包插件
执行:Build->Build Bundle(s)/APKS->Build APK(S)
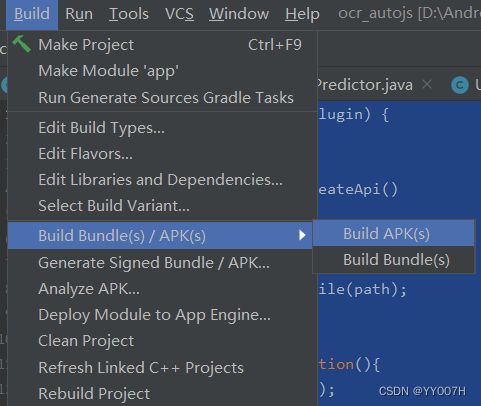
一个10M以下的插件就完成了。
9、在懒人精灵应用中编写lua代码
首先将apk文件放到资源目录下,然后用loadApk()加载该插件
// ***************************************************************************
// ********************加入群【754442166、469843332】可获取最新版本!!!*********************
// ***************************************************************************
import('java.io.File')
import('java.lang.*')
import('java.util.Arrays')
import('android.content.Context')
import('android.hardware.Sensor')
import('android.hardware.SensorEvent')
import('android.hardware.SensorEventListener')
import('android.hardware.SensorManager')
import('com.nx.assist.lua.LuaEngine')
local loader = LuaEngine.loadApk("TomatoOCR.apk")
local OCR = loader.loadClass("com.tomato.ocr.lr.OCRApi")
local ocr = OCR.init(LuaEngine.getContext())
local type = -1;
-- type 可传可不传
-- type=0 : 只检测
-- type=1 : 方向分类 + 识别
-- type=2 : 只识别
-- type=3 : 检测 + 识别
-- 只检测文字位置:type=0
-- 全屏识别: type=3或者不传type
-- 截取单行文字识别:type=1或者type=2
-- 例子一
local result1 = ocr.ocrFile("/storage/emulated/0/0.jpg", type)
-- local result1 = ocr.ocrFiles(["/storage/emulated/0/0.jpg","/storage/emulated/0/0.jpg",...],type)
printEx(result1);
-- 例子二
local result2 = ocr.ocrBitmap("bitmap对象", type)
-- local result2 = ocr.ocrBitmaps(["bitmap对象","bitmap对象",...],type)
printEx(result2);
-- 例子三
local result3 = ocr.ocrBase64("图片base64字符串", type)
-- local result3 = ocr.ocrBase64s(["图片base64字符串","图片base64字符串",...],type)
printEx(result3);
-- 释放
ocr.release()完毕!!!
总结
相对来说,在熟悉PaddleOCR和Android开发的情况下,进行懒人精灵插件开发还是比较容易的,而且通过自己开发插件的形式可以集成更多的功能,比如只进行文本检测、其他语言识别模型、身份识别模型等等,相对来说比较自由,这是官方提供不了的。今天就分享到这里,感谢支持!