【云原生K8S】Kubernetes来去今生与基础理论
目录
一、公有云类别
Ⅰ、IAAS
Ⅱ、PAAS
Ⅲ、SAAS
二、资源管理器
Ⅰ、Apache-MESOS
Ⅱ、Docker-SWARM
Ⅲ、Kubernetes
三、Kubernetes框架
Ⅰ、Master组件
(1)apiserver
(2)ControllerManager控制管理中心
(3)scheduler调度器
(4)etcd
Ⅱ、Node组件
(1)Pod
(2)Kube-proxy
(3)Kubelet
Ⅲ、其他一些重要的K8S组件
一、公有云类别
Ⅰ、IAAS
Infrastructure As A Service
基础设施即服务
代表:阿里云、AWS
Ⅱ、PAAS
Platform As A Service
平台即服务
代表:新浪云(号称免运维)
Ⅲ、SAAS
Software As A Service
软件即服务
代表:Microsoft Office 365
二、资源管理器
在容器化技术出现后,为了更好的去管理、应用这项技术,“资源管理器”应运而生
Ⅰ、Apache-MESOS
apache开源协议,需要和Marathon结合使用,作为资源管理器被推特选用,2019年5月后被替换为kubernetes,虽然后续MESOS支持了内部管理kubernetes,但已无力回天,逐渐退出历史舞台

Ⅱ、Docker-SWARM
容器化高级选手docker母公司自己推出的一个专为docker而做的非常轻量级的容器编排工具,集成在docker内部(高版本),但相较于kubernetes对于企业应用方面的功能还是非常不足例如k8s 的 滚动更新、回滚,可以实现,但是很复杂,除此之外大规模集群的使用和管理还是很强大的;2019年7月份,阿里云宣布将Docker Swarm 从选择列表中剔除

Ⅲ、Kubernetes
由谷歌推出,谷歌内部borg的翻写版本,并开源给了容器基金会。采用go语言编写,语言层面上奠定了kubernetes的轻量级特点(相对于其他语言)。当前以及未来架构平台的首选。

三、Kubernetes框架
Kubernetes(下文简称K8S) 是属于典型的C/S架构,Master 节点负责集群的调度、管理和运维。Node节点则被称为 Worker Node 节点,每个 Node 都会被 Master 分配一些工作负载。
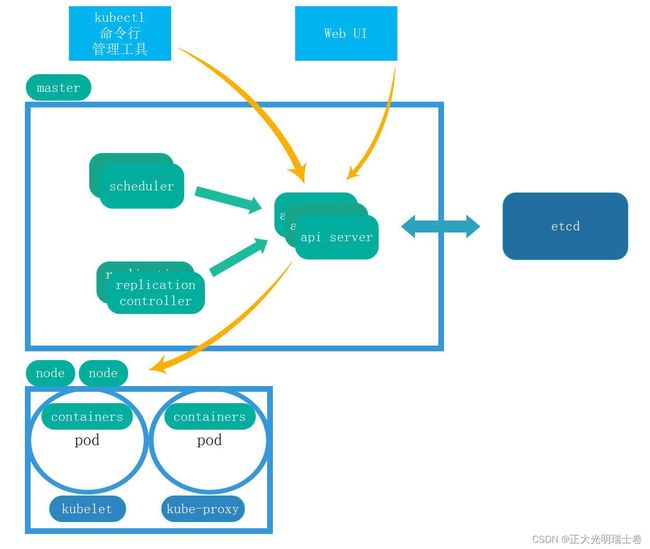
Ⅰ、Master组件
APIserver:所有服务访问的统一入口
ControllerManager:由一系列控制器组成,通过API Server监控整个集群的状态,并确保集群处于预期的工作状态
Scheduler:负责分配任务,选择合适的节点进行调度
Etcd:键值对数据库,储存K8S集群所有的信息数据(持久化)
(1)apiserver
用于暴露Kubernetes API,任何资源请求或调用操作都是通过kube-apiserver 提供的接口进行。以HTTP Restful API提供接口服务,所有对象资源的增删改查和监听操作都交给API Server 处理后再提交给Etcd 存储(相当于分布式数据库,以键值对方式存储)。
可以理解成API Server 是K8S的请求入口服务。API server负责接收K8S所有请求(来自UI界面或者CLI 命令行工具),然后根据用户的具体请求,去通知其他组件干活。可以说API server 是K8S集群架构的大脑。
(2)ControllerManager控制管理中心
| 控制器 | 功能 |
| Node Controller | (节点控制器)负责在节点出现故障时发现和响应 |
| Replication Controller | (副本控制器)负责保证集群中一个RC (资源对象ReplicationController) |
| Endpoints Controller | (端点控制器)填充端点(Endpoints)对象(即加入 Service 与 Pod) |
| Service Account & Token Controllers |
(服务帐户和令牌控制器)为新的命名空间创建默认帐户和API访问令牌 |
| Service Controller | (服务控制器)属于K8S集群与外部的云平台之间的一个接口控制器 |
(3)scheduler调度器
是 Kubernetes 集群的默认调度器,并且是集群 控制面 的一部分。 如果你真得希望或者有这方面的需求,kube-scheduler 在设计上允许你自己编写一个调度组件并替换原有的 kube-scheduler。
对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的节点去运行这个 Pod。 然而,Pod 内的每一个容器对资源都有不同的需求, 而且 Pod 本身也有不同的需求。因此,Pod 在被调度到节点上之前, 根据这些特定的调度需求,需要对集群中的节点进行一次过滤。
在一个集群中,满足一个 Pod 调度请求的所有节点称之为 可调度节点。 如果没有任何一个节点能满足 Pod 的资源请求, 那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。
调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分, 选出其中得分最高的节点来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做 绑定。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局部性、负载间的干扰等等。
(4)etcd
-
分布式键值存储系统(特性:服务自动发现)。用于保存集群状态数据,比如Pod、Service等对象信息
-
k8s中仅API Server 才具备读写权限,其他组件必须通过API Server 的接口才能读写数据
*:etcd V2版本:数据保存在内存中
v3版本:引入本地volume卷的持久化(可根据磁盘进行恢复),服务发现,分布式(方便扩容,缩容)
但kubernetes 1.11版本前不支持v3
ETCD一般会做为3副本机制(奇数方式),分布在三台master上
Ⅱ、Node组件
Kubelet:直接与容器引擎交互实现容器的生命周期
Kube-proxy:负责写入iptables、IPVS规则来实现服务端口映射关系
Pod:kubernetes的最小控制单元,容器(Container)都是运行在pod中
(1)Pod
pod是K8S的最小管理单元,一个pod中可运行一个或者一组容器。pod内的容器共享使用pod的唯一ip地址和一组存储卷。同一pod内的容器使用localhost进行通信;而与pod外的容器通信时,需要pod内的容器协调使用pod的端口进行通信
pod有生命周期,当一个pod生命周期结束后,该pod将不复存在,k8s会重新部署一个新的pod提供和该pod一样的服务。这样就用到service概念用于标记k8s集群提供一组服务的pod。
pod控制器
Pod控制器是Pod启动的一种模版,用来保证在K8S里启动的Pod应始终按照用户的预期运行(副本数、生命周期、健康状态检查等)
K8s内提供了众多的Pod控制器,常用的有以下几种:
Deployment:无状态应用部署。Deployment 的作用是管理和控制Pod和ReplicaSet, 管控它们运行在用户期望的状态中。
Replicaset: 确保预期的Pod 副本数量。Replicaset 的作用就是管理和控制Pod, 管控他们好好干活。但是,ReplicaSet 受控于Deployment。
可以理解成Deployment 就是总包工头,主要负责监督底下的工人Pod 干活,确保每时每刻有用户要求数量的Pod在工作。如果一旦发现某个工人Pod 不行了,就赶紧新拉一个Pod 过来替换它。而ReplicaSet 就是总包工头手下的小包工头。
从K8S使用者角度来看,用户会直接操作Deployment 部署服务,而当Deployment 被部署的时候,K8S 会自动生成要求的ReplicaSet和Pod。用户只需要关心Deployment 而不操心ReplicaSet。资源对象Replication Controller 是ReplicaSet 的前身,官方推荐用Deployment 取代Replication Controller 来部署服务。
Daemonset: 确保所有节点运行同一类Pod,保证每 个节点上都有一个此类Pod运行,通常用于实现系统级后台任务。
Statefulset: 有状态应用部署
Job:一次性任务。 根据用户的设置,Job管理的Pod把任务成功完成就自动退出了。
Cronjob: 周期性计划性任务
(2)Kube-proxy
Kubernetes 网络代理在每个节点上运行。网络代理反映了每个节点上 Kubernetes API 中定义的服务,并且可以执行简单的 TCP、UDP 和 SCTP 流转发,或者在一组后端进行 循环 TCP、UDP 和 SCTP 转发。 当前可通过 Docker-links-compatible 环境变量找到服务集群 IP 和端口, 这些环境变量指定了服务代理打开的端口。 有一个可选的插件,可以为这些集群 IP 提供集群 DNS。 用户必须使用 apiserver API 创建服务才能配置代理。
(3)Kubelet
kubelet 是在每个 Node 节点上运行的主要 “节点代理”。它可以使用以下之一向 apiserver 注册: 主机名(hostname);覆盖主机名的参数;某云驱动的特定逻辑。
kubelet 是基于 PodSpec 来工作的。每个 PodSpec 是一个描述 Pod 的 YAML 或 JSON 对象。 kubelet 接受通过各种机制(主要是通过 apiserver)提供的一组 PodSpec,并确保这些 PodSpec 中描述的容器处于运行状态且运行状况良好。 kubelet 不管理不是由 Kubernetes 创建的容器。
除了来自 apiserver 的 PodSpec 之外,还可以通过以下三种方式将容器清单(manifest)提供给 kubelet。
- 文件(File):利用命令行参数传递路径。kubelet 周期性地监视此路径下的文件是否有更新。 监视周期默认为 20s,且可通过参数进行配置。
- HTTP 端点(HTTP endpoint):利用命令行参数指定 HTTP 端点。 此端点的监视周期默认为 20 秒,也可以使用参数进行配置。
- HTTP 服务器(HTTP server):kubelet 还可以侦听 HTTP 并响应简单的 API (目前没有完整规范)来提交新的清单。
Ⅲ、其他一些重要的K8S组件
ClusterDNS/CoreDNS:为集群中的SVC创建一个域名-IP的对应关系解析
Kubesphere/Dashboard:给K8S集群提供一个B/S结构访问体系、ui管理界面
INGRESS CONTROLLER:实现七层代理
FEDERATION:提供一个可以跨集群中心多K8S统一管理功能
Prometheus:提供监控K8S功能
ELK:提供K8S集群日志分析系统
Harbor:镜像仓库