Hive 表 DML 操作
第1关:将文件中的数据导入(Load)到 Hive 表中
导入命令语法:
Load操作执行copy/move命令把数据文件copy/move到Hive表位于 HDFS上的目录位置,并不会对数据内容执行格式检查或格式转换操作。Load命令语法为:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=vall,partcol2=val2 …)];
文件路径filepath可以是指向HDFS的相对路径或是绝对路径,也可以是指向本地文件系统(Linux文件系统)相对路径(当前工作目录)或绝对路径。
若filepath指向HDFS,LOAD执行的是move操作(即执行LOAD后filepath中的文件不再存在);若filepath指向本地文件系统,LOAD执行的是copy操作(即执行LOAD后filepath中的文件仍然存在),但需要指定LOCAL关键字。
若filepath指向一个文件,LOAD会copy或move相应的文件到表tablename;若filepath指向一个目录,LOAD会copy或move相应目录下的所有文件到表tablename。若创建表时指定了分区列,使用 LOAD 命令加载数据时也要为所有分区列指定特定值。
针对LOAD语句中指明LOCAL关键字,INPATH参数可以使用下述方式确定:
-
Hive 会在本地文件系统中查找
filepath -
用户可以设置
filepath为文件绝对路径,如file:///user/hive/data
针对LOAD语句中未指明LOCAL关键字,INPATH参数可以使用下述方式确定:
-
若
filepath为相对路径,Hive会解析成为/user//filepath -
filepath未指定模式或文件系统类型(如hdfs://namenode:9000/),Hive会把${fs.default.name}值作为Namenode URL
若语句带OVERWRITE关键字,目标表或分区中的原始数据会被删除,替换成新数据;若未指定OVERWRITE关键字,新数据会以追加的方式被添加到表中。
若表或分区中的任何一个文件与filepath中的任何一个文件同名,则表或分区中的同名文件会被filepath中的同名文件替换。
将本地txt文件导入到分区表中(例子)
创建数据库shopping:

- 如假设本地文件
/home/shoppings.txt内容为: 
-
字段间分隔符
,根据表中设置FIELDS TERMINATED BY ','确定的。如果表中设置FIELDS TERMINATED BY '\t',那么字段间就应该用Tab键间隔开 -
集合分隔符
-根据表中设置COLLECTION ITEMS TERMINATED BY '-'确定的。如果表中设置COLLECTION ITEMS TERMINATED BY ',',那么字段间就应该用逗号,键间隔开
- 使用
LOAD命令加载本地文件数据到items_info2表相应的分区中(PARTITION关键字指定内容): 
执行LOAD命令后,Hive会在 HDFS 的/hive/shopping/items2/路径下创建目录p_category=shoes/p_brand=playboy/,并且会把items_info.txt文件复制到上述创建的目录下

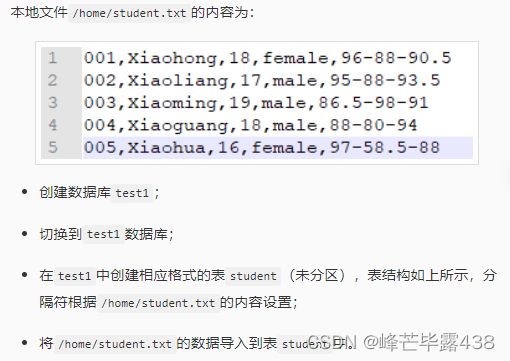

代码块:
/********* Begin *********/
/*创建数据库*/
CREATE DATABASE IF NOT EXISTS test1
LOCATION '/hive/test1'; /*指定数据库位置*/
USE test1;
/*建表*/
CREATE TABLE IF NOT EXISTS test1.student(
Sno INT COMMENT 'student sno',
name STRING COMMENT 'student name' ,
age INT COMMENT 'student age',
sex STRING COMMENT 'student sex',
score STRUCT COMMENT 'student score')
COMMENT 'students information tabe'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-';
/*插入数据*/
load data local inpath '/home/student.txt' overwrite into table student;
/********* End *********/
select * from student; 第2关:Select 操作
select 语法格式:
SELECT [ALL | DISTINCT] select_expr,select_expr,… FROM table_reference[WHERE where_condition] [GROUP BY col_list] [CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]] [LIMIT number]


代码块:
--Begin
use test2;
--查询student表中所有的行和列
select * from student;
--查询年龄age > 17的女生female
select * from student where age>17 and sex="female";
--查询语文成绩Chinese > 90的记录
select * from student where score.chinese>90;
--从student表中查询前3条记录
select * from student limit 3;
--返回按年龄降序的前2条记录
select * from student sort by age desc limit 2;
--End第3关:将 select 查询结果插入 hive 表中
单表插入语法:
INSERT OVERWRITE TABLE tablename [PARTITION (partcol1=val1,partcol2=val2,……) [IF NOT EXISTS]] SELECT select_statement FROM from_statement;
该方法会 覆盖 表或分区中的数据(若对特定分区指定IF NOT EXISTS将不执行覆盖操作)。
单表插入语法( 追加 方式):
INSERT INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2,……) ] SELECT select_statement FROM from_statement;
该方法以追加的方式把SELECT子句返回的结果添加到表或分区中
多表插入:
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1,partcol2=val2…) [IF NOT EXISTS]] SELECT select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION … [IF NOT EXISTS]] SELECT select_statement2]
[INSERT INTO TABLE tablename2 [PARTITION … ] SELECT select_statement2]…;
多表插入操作的开始第一条命令指定所有表执行的SELECT命令所对应的FROM 子句,针对同一个表,既可以执行INSERT OVERWRITE操作,也可以执行 INSERT INTO操作(如表tablename2)。
多表插入操作可以降低源表的扫描次数,Hive可以通过仅扫描一次数据源表,然后针对不同的Hive表应用不同的查询规则从扫描结果中获取目标数据插入到不同的Hive表中。


代码块:
--Begin
--使用test3数据库
use test3;
--复制student表两份,分别名为:student2、student3
CREATE TABLE IF NOT EXISTS student2
LIKE student;
CREATE TABLE IF NOT EXISTS student3
LIKE student;
--以覆盖插入的方式把student表中前两条数据插入到student2中
insert overwrite table student2
select * from student limit 2;
--评测代码,勿删
select * from student2;
--以追加插入的方式把student表中前两条数据插入到student2中
insert into table student2
select * from student limit 2;
--评测代码,勿删
select * from student2;
--以覆盖插入的方式把student表中年龄大于17岁的数据插入到student2、student3中
from student ii
insert overwrite table student2
select * where ii.age>17
insert overwrite table student3
select * where ii.age>17;
--评测代码,勿删
select * from student2;
select * from student3;
--以追加插入的方式把student表中的男生数据插入到student2,以覆盖插入的方式把女生数据插入到student3中
from student ii
insert into table student2
select * where ii.sex='male'
insert overwrite table student3
select * where ii.sex='female';
--评测代码,勿删
select * from student2;
select * from student3;
--End第4关:将 select 查询结果写入文件
单文件写入:
INSERT OVERWRITE [LOCAL] DIRECTORY directory[ROW FORMAT row_format] [STORED AS file_format]SELECT select_statement FROM from_statements;
若指定LOCAL关键字,查询结果写入本地文件系统中(OS 文件系统);否则,查询结果写入到分布式文件系统中(HDFS)。
多文件写入:
FROM from_statement INSERT OVERWRITE [LOCAL] DIRECTORY directory1SELECT select_statement1[INSERT OVERWRITE [LOCAL] DIRECTORY directory2SELECT select_statement2];

代码块:
--使用test4数据库
use test4;
--Begin
--查询student表中的前两条数据写入到本地文件/home/test4目录下
insert overwrite local directory '/home/test4'
select * from student limit 2;
--查询student表中男生的数据写入到本地文件/home/test4_1目录下,
--女生的数据写入到本地文件/home/test4_2目录下
FROM student
INSERT OVERWRITE LOCAL DIRECTORY '/home/test4_1'
SELECT * where sex='male'
INSERT OVERWRITE LOCAL DIRECTORY '/home/test4_2'
SELECT * where sex='female' ;
--End