浅谈Redis内存淘汰机制
浅谈 Redis 内存淘汰机制
在讲解 Redis 内存淘汰机制之前,相信大家都了解过 Redis 键的过期策略,其实,这两者是完全不同的东西。Redis 过期策略指的是 Redis 采用哪种策略来删除已经过期的键值对;而 Redis 内存淘汰机制是当 Redis 的运行内存超过 Redis 设置的最大内存之后,将采用什么策略来删除符合条件的键值对,以此来保障 Redis 高效的运行。
所以,今天让我们谈谈 Redis 的内存淘汰机制
一、Redis 最大运行内存
只有在 Redis 的运行内存达到了某个阀值,才会触发内存淘汰机制,这个阀值就是我们设置的最大运行内存,此值在 Redis 的配置文件中可以找到,配置项为 maxmemory。
内存淘汰执行流程,如下图所示:
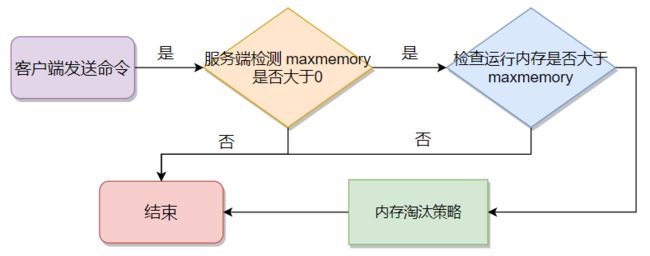
1、查询最大运行内存
我们可以使用命令 config get maxmemory 来查看设置的最大运行内存,命令如下:
127.0.0.1:6379> config get maxmemory
1) "maxmemory"
2) "0"
我们发现此值竟然是 0,这是 64 位操作系统默认的值,当 maxmemory 为 0 时,表示没有内存大小限制。
小贴士:32 位操作系统,默认的最大内存值是 3GB。
二、内存淘汰策略
我们可以使用 config get maxmemory-policy 命令,来查看当前 Redis 的内存淘汰策略,命令如下:
127.0.0.1:6379> config get maxmemory-policy
1) "maxmemory-policy"
2) "noeviction"
可以看出此 Redis 使用的是 noeviction 类型的内存淘汰机制,它表示当运行内存超过最大设置内存时,不淘汰任何数据,但新增操作会报错。
1、内存淘汰策略分类
早期版本的 Redis 有以下 6 种淘汰策略:
- noeviction:不淘汰任何数据,当内存不足时,新增操作会报错,Redis 默认内存淘汰策略;
- allkeys-lru:淘汰整个键值中最久未使用的键值;
- allkeys-random:随机淘汰任意键值;
- volatile-lru:淘汰所有设置了过期时间的键值中最久未使用的键值;
- volatile-random:随机淘汰设置了过期时间的任意键值;
- volatile-ttl:优先淘汰更早过期的键值。
在 Redis 4.0 版本中又新增了 2 种淘汰策略:
- volatile-lfu:淘汰所有设置了过期时间的键值中,最少使用的键值;
- allkeys-lfu:淘汰整个键值中最少使用的键值。
以 volatile 开头的策略只针对设置了过期时间的数据,即使缓存没有被写满,如果数据过期也会被删除。
以 allkeys 开头的策略是针对所有数据的,如果数据被选中了,即使过期时间没到,也会被删除。当然,如果它的过期时间到了但未被策略选中,同样会被删除。
2、修改 Redis 内存淘汰策略
设置内存淘汰策略有两种方法,这两种方法各有利弊,需要使用者自己去权衡。
- 方式一:通过“
config set maxmemory-policy策略”命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。 - 方式二:通过修改 Redis 配置文件修改,设置“
maxmemory-policy策略”,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效。
三、内存淘汰算法
从内测淘汰策略分类上,我们可以得知,除了随机删除和不删除之外,主要有两种淘汰算法:LRU 算法和 LFU 算法。
LRU 算法
LRU 全称是 Least Recently Used 译为最近最少使用,是一种常用的页面置换算法,选择最近最久未使用的页面予以淘汰,说人话就是会将最不常用的数据筛选出来,保留最近频繁使用的数据。
1. LRU 算法实现
LRU 算法需要基于链表结构,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要内存淘汰时,只需要删除链表尾部的元素即可,如图:
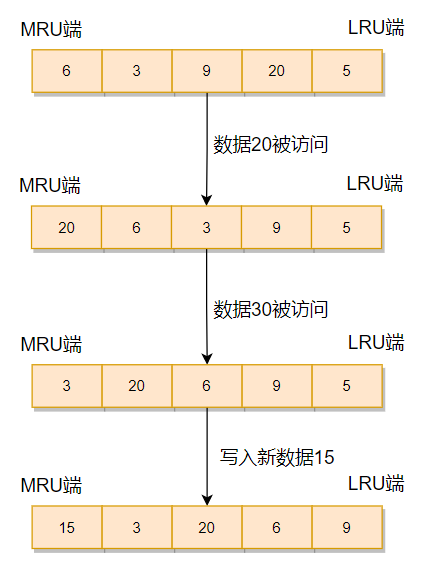
注意:LRU 算法在实际实现时,需要用链表管理所有的缓存数据,这会带来额外的空间开销。而且,当有数据被访问时,需要在链表上把该数据移动到 MRU 端,如果有大量数据被访问,就会带来很多链表移动操作,会很耗时,进而会降低 Redis 缓存性能,所以 Redis 采用了下面的 近 LRU 算法
2. 近 LRU 算法
Redis 使用的是一种近似 LRU 算法,目的是为了更好的节约内存,它的实现方式是给现有的数据结构添加一个额外的字段,用于记录此键值的最后一次访问时间,Redis 内存淘汰时,会使用随机采样的方式来淘汰数据,它是随机取 n 个值(此值可配置),然后使用 LRU 算法淘汰最久没有使用的那个。这个配置参数是 maxmemory-samples :
CONFIG SET maxmemory-samples 100
这样一来,Redis 缓存不用为所有的数据维护一个大链表,也不用在每次数据访问时都移动链表项,提升了缓存的性能
3. LRU 算法缺点
LRU 算法有一个缺点,比如说很久没有使用的一个键值,如果最近被访问了一次,那么它就不会被淘汰,即使它是使用次数最少的缓存,那它也不会被淘汰,因此在 Redis 4.0 之后引入了 LFU 算法,下面我们一起来看。
到这里我们讲完了 LRU 算法,这里给出三个使用建议:
- 优先使用
allkeys-lru策略。这样,可以充分利用 LRU 这一经典缓存算法的优势,把最近最常访问的数据留在缓存中,提升应用的访问性能。如果你的业务数据中有明显的冷热数据区分,我建议你使用allkeys-lru策略。 - 如果业务应用中的数据访问频率相差不大,没有明显的冷热数据区分,建议使用
allkeys-random策略,随机选择淘汰的数据就行。 - 如果你的业务中有置顶的需求,比如置顶新闻、置顶视频,那么,可以使用
volatile-lru策略,同时不给这些置顶数据设置过期时间。这样一来,这些需要置顶的数据一直不会被删除,而其他数据会在过期时根据 LRU 规则进行筛选
LFU 算法
LFU 全称是 Least Frequently Used 翻译为最不常用的,最不常用的算法是根据总访问次数来淘汰数据的,它的核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。
LFU 解决了偶尔被访问一次之后,数据就不会被淘汰的问题,相比于 LRU 算法也更合理一些。
在 Redis 中每个对象头中记录着 LFU 的信息,源码如下:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;
在 Redis 中 LFU 存储分为两部分,16 bit 的 ldt(last decrement time)和 8 bit 的 logc(logistic counter)。
- logc 是用来存储访问频次,8 bit 能表示的最大整数值为 255,它的值越小表示使用频率越低,越容易淘汰;
- ldt 是用来存储上一次 logc 的更新时间。
四、如何处理被淘汰的数据?
一般来说,一旦被淘汰的数据选定后,如果这个数据是干净数据,那么我们就直接删除;如果这个数据是脏数据,我们需要把它写回数据库。
那怎么判断一个数据到底是干净的还是脏的呢?
干净数据和脏数据的区别就在于,和最初从后端数据库里读取时的值相比,有没有被修改过。干净数据一直没有被修改,所以后端数据库里的数据也是最新值。在替换时,它可以被直接删除。而脏数据就是曾经被修改过的,已经和后端数据库中保存的数据不一致了。此时,如果不把脏数据写回到数据库中,这个数据的最新值就丢失了,就会影响应用的正常使用。这么一来,缓存替换既腾出了缓存空间,用来缓存新的数据,同时,将脏数据写回数据库,也保证了最新数据不会丢失。
注意:对于 Redis 来说,它决定了被淘汰的数据后,会把它们删除。即使淘汰的数据是脏数据,Redis 也不会把它们写回数据库。所以,我们在使用 Redis 缓存时,如果数据被修改了,需要在数据修改时就将它写回数据库。否则,这个脏数据被淘汰时,会被 Redis 删除,而数据库里也没有最新的数据了
五、小结
通过本文我们了解到,Redis 内存淘汰策略和过期回收策略是完全不同的概念,内存淘汰策略是解决 Redis 运行内存过大的问题的,通过与 maxmemory 比较,决定要不要淘汰数据,根据 maxmemory-policy 参数,决定使用何种淘汰策略,在 Redis 4.0 之后已经有 8 种淘汰策略了,默认的策略是 noeviction 当内存超出时不淘汰任何键值,只是新增操作会报错。
一般来说,缓存系统对于选定的被淘汰数据,会根据其是干净数据还是脏数据,选择直接删除还是写回数据库。但是,在 Redis 中,被淘汰数据无论干净与否都会被删除,所以,这是我们在使用 Redis 缓存时要特别注意的:当数据修改成为脏数据时,需要在数据库中也把数据修改过来
到这里我们的 Redis 内存淘汰机制就讲完了,如果你还有啥不懂的,其实我也不会
巨人的肩膀:http://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/Redis%20%E6%A0%B8%E5%BF%83%E5%8E%9F%E7%90%86%E4%B8%8E%E5%AE%9E%E6%88%98/23%20%E5%86%85%E5%AD%98%E6%B7%98%E6%B1%B0%E6%9C%BA%E5%88%B6%E4%B8%8E%E7%AE%97%E6%B3%95.md
https://time.geekbang.org/column/intro/100056701