hadoop大数据 - 2 HDFS高可用集群、RM高可用集群
1. 高可用简介
在任何时候,集群中只有一个NN处于Active状态是很重要的,否则在两个ActiveNN的状态下,NameSpace会出现分歧,这将会导致数据丢失以及其他不正确结果,为了保证这种情况不会发生,在任何时间,JNs 只允许一个 NN 当writer。在故障恢复期间,将要变成 Active 状态的 NN 将取得 writer 的角色,并阻止另外一个 NN 继续处于 Active状态。
在典型的 HA 集群中,通常有两台不同的机器充当 NN。在任何时间,只有一台机器处于Active 状态;另一台机器是处于 Standby 状态。Active NN 负责集群中所有客户端的操作;而 Standby NN 主要用于备用,它主要维持足够的状态,如果必要,可以提供快速的故障恢复。
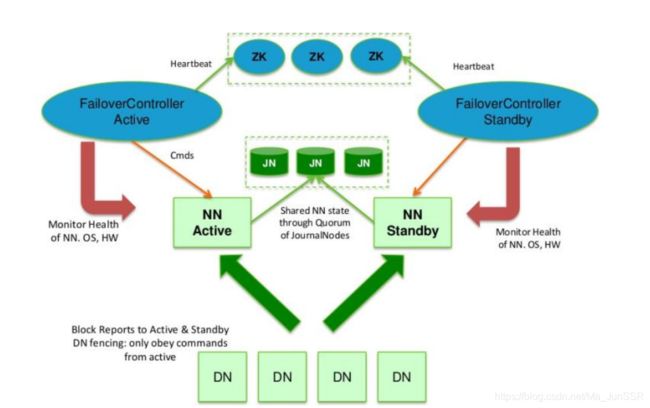
为了让 Standby NN 的状态和 Active NN 保持同步,即元数据保持一致,它们都将会和JournalNodes 守护进程通信。一旦 Active NN出现故障,Standby NN 将会保证从 JNs 中读出了全部的 Edits,然后切换成 Active 状态。Standby NN 读取全部的 edits 可确保发生故障转移之前,是和 Active NN 拥有完全同步的命名空间状态。
为了提供快速的故障恢复,Standby NN 也需要保存集群中各个文件块的存储位置。为了实现这个,集群中所有的 Database 将配置好 Active NN 和 Standby NN 的位置,并向它们发送块文件所在的位置及心跳,如下图所示:
为了部署 HA 集群,你需要准备以下事项:
(1)、NameNode machines:运行 Active NN 和 Standby NN 的机器需要相同的硬件配置;
(2)、JournalNode machines:也就是运行 JN 的机器。JN 守护进程相对来说比较轻量,所以这些守护进程可以可其他守护线程(比如 NN,YARN ResourceManager)运行在同一台机器上。在一个集群中,最少要运行 3 个 JN 守护进程,这将使得系统有一定的容错能力。当然,你也可以运行 3 个以上的 JN,但是为了增加系统的容错能力,你应该运行奇数个 JN(3、5、7 等),当运行 N 个 JN,系统将最多容忍(N-1)/2 个 JN 崩溃。在 HA 集群中,Standby NN 也执行 namespace 状态的 checkpoints,所以不必要运行Secondary NN、CheckpointNode 和 BackupNode;事实上,运行这些守护进程是错误的。
2、hadoop高可用
准备5个虚拟机,准备Zookeeper的压缩包
| 主机名 | IP | 角色 |
|---|---|---|
| vm1 | 172.25.10.11 | NameNode、ResourceManager、DFSZKFailoverController |
| vm5 | 172.25.10.15 | NameNode、ResourceManager、DFSZKFailoverController |
| vm2 | 172.25.10.12 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| vm3 | 172.25.10.13 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| vm4 | 172.25.10.14 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
(1)Zookeeper 集群搭建
首先清理之前的实验环境,停掉之前的jps进程,删除/tmp底下的数据,目的是清除hadoop的数据

vm2,vm3,vm4清除tmp目录下的数据
vm5创建hadoop用户,安装nfs

vm5挂载vm1上的/home/hadoop目录到自己的目录,切换用户
 vm1解压zookeeper,因为是nfs系统所以每个节点都可用
vm1解压zookeeper,因为是nfs系统所以每个节点都可用
 在vm2中进入zookeeper解压目录,复制一份配置文件,创建zookeeper存放数据目录,编辑文件
在vm2中进入zookeeper解压目录,复制一份配置文件,创建zookeeper存放数据目录,编辑文件
 默认数据目录dataDir,声明集群有三个节点,server.x,这个x是一个数字,与myid文件一致,2888是数据同步通信用的端口,3888是选举用的
默认数据目录dataDir,声明集群有三个节点,server.x,这个x是一个数字,与myid文件一致,2888是数据同步通信用的端口,3888是选举用的
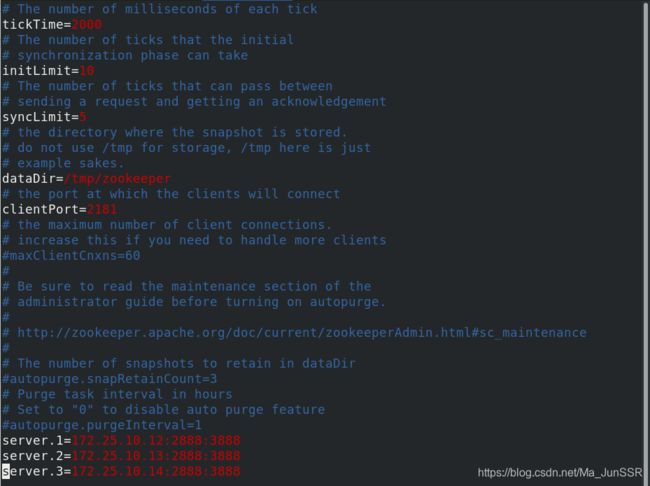
各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入
一个唯一的数字,取值范围在 1-255。
在vm2,vm3,vm4中分别创建目录/tmp/zookeeper,再在这个目录底下创建一个myid文件
vm2写入1,vm3写入2,vm4写入3



分别进入vm2,vm3,vm4的zookeeper目录,执行命令开启zookeeper,查看它们的状态
[hadoop@vm2 zookeeper-3.4.9]$ bin/zkServer.sh start
开启zookeeper
[hadoop@vm2 zookeeper-3.4.9]$ bin/zkServer.sh status
查看状态
注意:如果用status无法查看状态,需要等三个节点都启动了再查看,这里涉及到了leader选举的问题
vm2和vm4是follower,vm3是leader leader是随机选举产生的



(2)hadoop-HA搭建
编辑xml文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value> 指定 hdfs 的 namenode 为 masters
</property>
<property>
<name>ha.zookeeper.quorum</name> 指定 zookeeper 集群主机地址
<value>172.25.10.12:2181,172.25.10.13:2181,172.25.10.14:2181</value>
</property>
</configuration>
编辑文件
[hadoop@vm1 hadoop]$ cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value> 三个副本
</property>
<property>
<name>dfs.nameservices</name>
<value>masters</value> 指定hdfs的nameservices为masters,和core-site.xml文件中的设置保持一致
</property>
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value> masters 下面有两个 namenode 节点,分别是 h1 和 h2
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.10.11:9000</value> 指定 h1 节点的 rpc 通信地址
</property>
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.10.11:9870</value> 指定 h1 节点的 http 通信地址
</property>
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.10.15:9000</value> 指定 h2 节点的 rpc 通信地址
</property>
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.10.15:9870</value> 指定 h2 节点的 http 通信地址
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> 指定 NameNode 元数据在 JournalNode 上的存放位置
<value>qjournal://172.25.10.12:8485;172.25.10.13:8485;172.25.10.14:8485/masters</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value> 指定 JournalNode 在本地磁盘存放数据的位置
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name> 开启 NameNode 失败自动切换
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property> 配置失败自动切换实现方式
<property>
<name>dfs.ha.fencing.methods</name> 配置隔离机制方法,每个机制占用一行
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> 使用 sshfence 隔离机制时需要 ssh 免密码
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name> 配置 sshfence 隔离机制超时时间
<value>30000</value>
</property>
</configuration>
vm2,vm3,vm4依次开启journalnode,第一次启动 hdfs 必须先手动启动 journalnode(按照编号顺序依次开启)
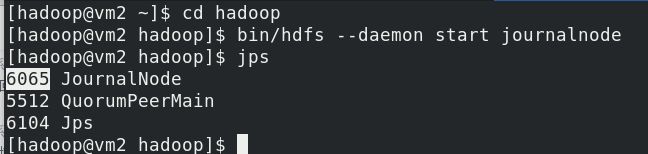
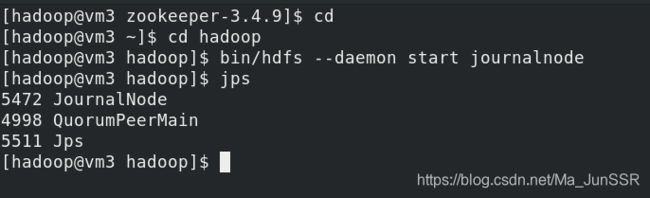

在vm1上的hadoop目录初始化HDFS集群
Namenode 数据默认存放在/tmp,vm1需要把数据拷贝到 vm5

vm1格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@vm1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@vm1 hadoop]$ bin/hdfs zkfc -formatZK
vm2进入zk,作为一个查询的窗口,不要退出

可以看到虚拟目录

vm1启动hdfs集群,jps查看进程,发现多了一个DFSZKFailoverController,这就是zk控制器

在vm2上查看,现在的主机是vm1,vm5是备用的
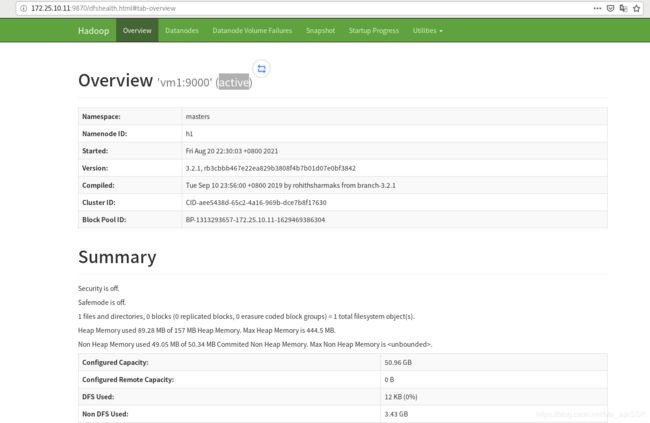
访问vm1IP 9870端口
vm1是active状态
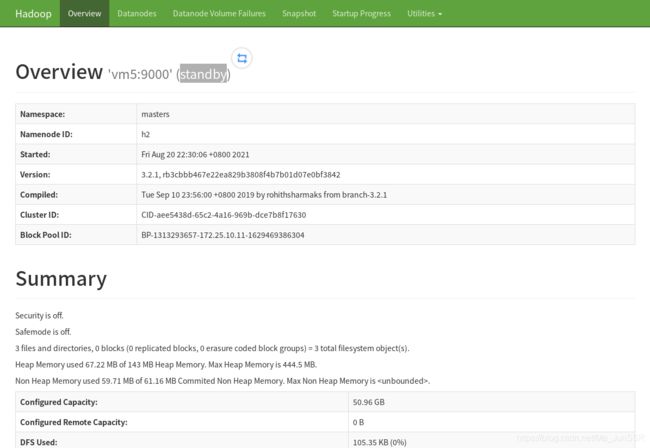
访问vm5 IP 9870端口
vm5是standby状态
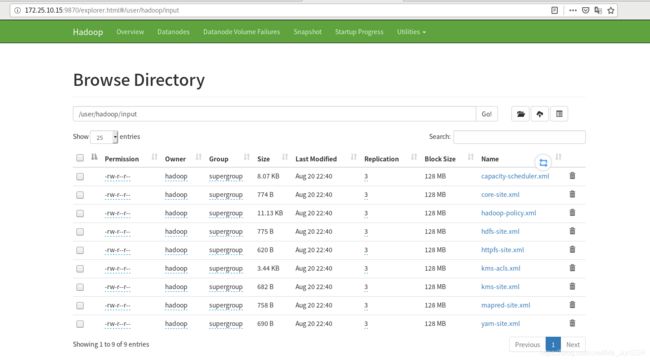
vm1上创建hadoop目录,上传input目录的内容到HDFS上
在vm1的HDFS页面可以看到上传的文件
(3)测试
kill掉vm1
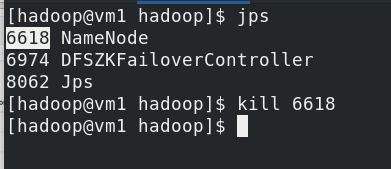
在vm2上查看,vm5代替了vm1作为master
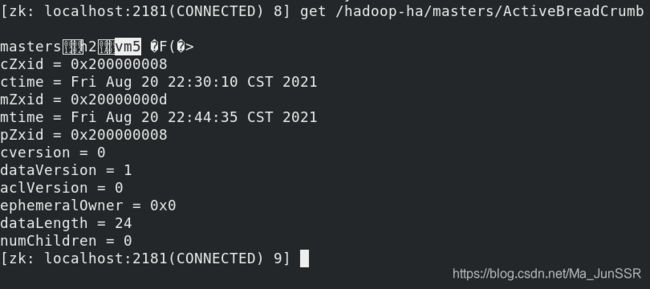
文件内容依然在
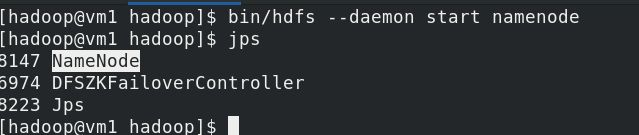
如果想要恢复vm1的状态,只要启动namenode就可以
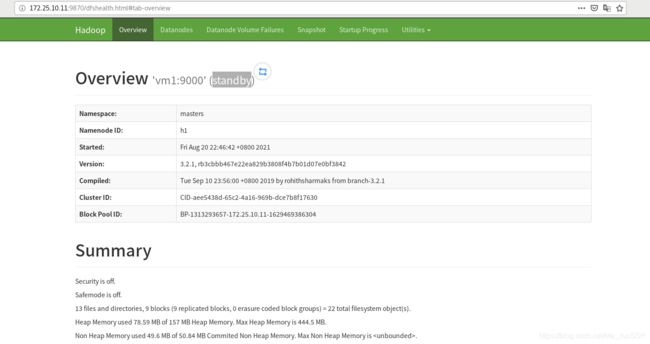
然而vm1是standby状态 ,这是因为没必要浪费资源来切换,vm1作为备用就可以了
这就是HDFS的高可用,hadoop自带的高可用,但是需要ZK集群支持
3、YARN – ResourceManager高可用
(1)RM资源管理器高可用部署
编辑文件
[hadoop@vm1 hadoop]$ cat yarn-site.xml
<?xml version="1.0"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<configuration>
<property> 配置可以在 nodemanager 上运行 mapreduce 程序
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property> 指定变量
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
<property> 激活 RM 高可用
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property> 指定 RM 的集群 id
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
<property> 定义 RM 的节点
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property> 指定 RM1 的地址
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.10.11</value>
</property>
<property> 指定 RM2 的地址
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.10.15</value>
</property>
<property> 激活 RM 自动恢复
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property> 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property> 配置为 zookeeper 存储时,指定 zookeeper 集群的地址
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.10.12:2181,172.25.10.13:2181,172.25.10.14:2181</value>
</property>
</configuration>
vm1开启yarn,jps查看RM开启
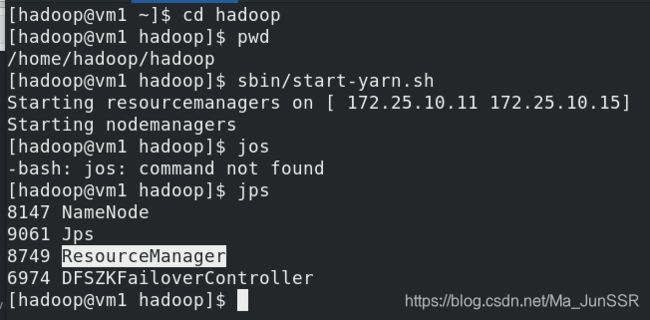
vm5上也有RM。

在vm2,3,4上都有NodeManager
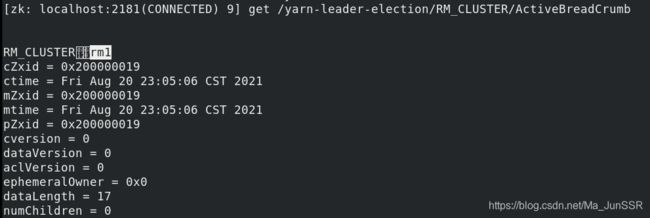
vm2上查看,此时rm1是active状态
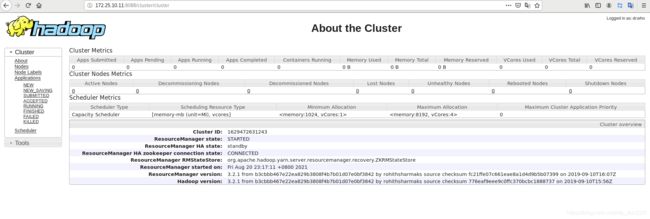
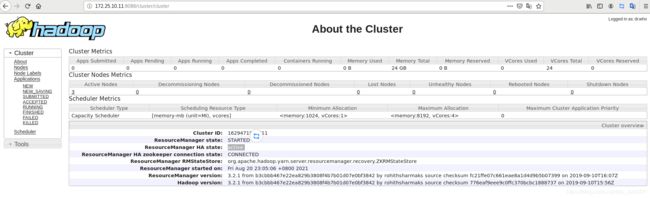
网页访问vm1的8088端口,此时是active状态
网页访问vm5的8088端口,此时是standby状态

(2)测试
kill掉vm1的RM
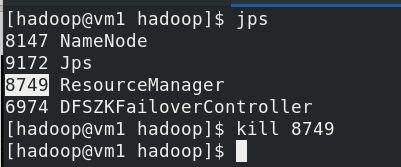
vm5立即成为active状态
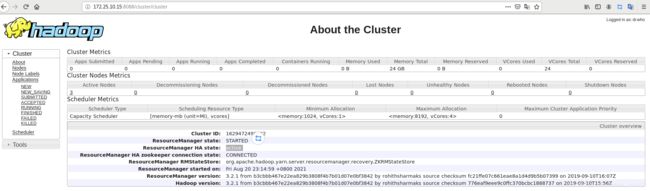
在vm2上查看,rm5已经接管了rm1成为了active状态
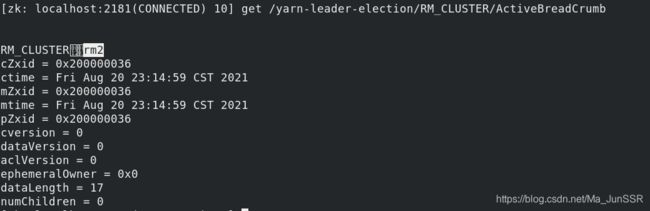
此时已经无法访问rm1
恢复rm1
rm1此时成为standby状态,为了不浪费资源,不会去接管rm5切换成active