使用自己数据集复现U-Net,R2U-Net,Att U-net,Att R2U-net过程。(代码参考: LeeJunHyun / Image_Segmentation )
主要就是dataset.py和dataloader.py里面改改就可以。main.py可以根据自己的需要修改相应的参数。注意自己使用的数据集的图片类型即可。
文章目录
- 前言
- 一、Load Data
- 二、Training
-
- 1.Define Neural Network
- 2.Loss function
- 3.Optimization Algorithm
- 三、Validation
- 四、Testing
- 五、Evaluation
- Main.py
- 进度条函数
- 总结
前言
环境配置,就是安装好驱动,创建个虚拟环境,安装pytorch,cv2,PIL应该就可以。
pip install torch torchvision -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com pillow
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
在开始之前要先确认一下自己数据集图片的类型。
你看自己图片windows的话,右击图片属性,摘要,点击详细属性,里面有位深度一项。如果是RGB图,位深度是24;如果是灰度和索引图,位深度是8;灰度是白灰黑表示的图,索引图有可能是彩色的,但也是8位深。
我是在Ubuntu中,就用了python,判别是单通道还是多通道。
import cv2
import torch
import torchvision.transforms as transforms
path = '自己数据集图片的路径'
img = cv2.imread(path+'ISIC_0001769_segmentation.png',-1)#后面那个-1的意思是按着图片本身的属性来读取,单通道就类似于这种(256,256),三通道就是(3,256,256)。
print(img.shape)
#你要是想看看自己图片是不是二值还是灰度看下面这个代码
transf = transforms.ToTensor()
img = transf(img)#变成tensor
img_max = torch.max(img)
img_min = torch.min(img)
num_max = torch.sum(img == img_max)
num_min = torch.sum(img == img_min)
num_max_min = num_max + num_min
print(img.shape)#tensor的形状是(C,H,W)
print(torch.sum(num_max_min)/(img.shape[1]*img.shape[2])) #这个等于1,说明这个图片除了最大值就是最小值,是二值图像(就可以直接用原作者的代码了),否则就是灰度图像(自己变换成二值)。
阿巴阿巴,就是我用的数据集的图片本身是单通道,这个代码处理的是三通道的,所以一直报错。你们要是也有这个问题就用下面这个代码。处理好后,再运行模型。
import cv2
import os
import numpy as np
path = 'XXXX/' # 源文件所在目录 图片文件
savefilepath = 'XXXXX/' # 输出文件所在目录 图片文件
datanames = os.listdir(path)
for i in datanames:
img = cv2.imread(path + '/' + str(i))
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img2 = np.zeros_like(img)
img2[:, :, 0] = gray
img2[:, :, 1] = gray
img2[:, :, 2] = gray
cv2.imwrite(savefilepath + i, img2)
mask不是二值是灰度图像的话,读取完mask之后,再处理一下就好,变成tensor后,加上下面这一句。里面0.9是我看着我这个随便取的。可以换成0.5。就是二值了。之后BCE等计算都没问题了。
GT = torch.where(GT > 0.9, torch.ones_like(GT), torch.zeros_like(GT))
这个模型的mask是二值图像。下面是转换为二值图像的代码。额,就是变成二值图像保存出了问题。还未解决,下面这个代码就变成3通道的了。之后慢慢看怎么修改。找到一个方法但是看不懂。/(ㄒoㄒ)/~~图片保存:torchvision.utils.save_image(img, imgPath)我太菜了,不会用。走一步看一步吧。后面感觉要是保持这个mask为灰度图的话,后面用比较运算,应该也是可以继续进行的吧,大概。如果你们的mask本身就是二值图像就直接跳过好吧。
目前情况是我看了看我数据集的mask是一个不太标准的二值图像,至于为什么运行他的evaluation.py出来错误的结果,我记得当时主要在GT==torch.max(GT)好像这个都是False,没办法自己改了他的evaluation。
下面是我的mask的像素值分布。

import cv2
import os
import torchvision
def charge(input_path, ouput_path):
flies = os.listdir(input_path) # 获取所有图片的名称,保存为列表
for ii in range(len(flies)):
im = cv2.imread(input_path + '/' + flies[ii]) # 读取图片
ret, binary = cv2.threshold(im, 127, 255, cv2.THRESH_BINARY)
cv2.imwrite(ouput_path + '/' + str(ii) + ".jpg", binary) # 保存为jpg
if __name__ == '__main__':
input_path = 'D:/data/Thyroid Dataset all/tn3k/test_mask_1' # 读取图片输入路径
ouput_path = 'D:/data/Thyroid Dataset all/tn3k/test-mask' # 图片输出路径
charge(input_path, ouput_path)
一、Load Data
首先看dataset部分,它的作用是把数据集分成训练集(train set),验证集(validation set),测试集(test set)。
def rm_mkdir(dir_path):#删除文件夹
if os.path.exists(dir_path):
shutil.rmtree(dir_path)
print('Remove path - %s' % dir_path)
os.makedirs(dir_path)
print('Create path - %s' % dir_path)
接下来是主函数,从自己的数据集中抽取数据形成训练集、验证集、测试集。注意这里读取图片的名字每个数据集是不同的,我的数据集原始图片和mask图片的名字是相同的,就只需要换个路径即可。
原来的代码是mask的名字比原始图片多几个字符,而且后缀也不同。
for filename in filenames:
ext = os.path.splitext(filename)[-1]#os.path.splitext(“文件路径”) 分离文件名与扩展名;默认返回(fname,fextension)元组,可做分片操作,-1的意思是取这个列表中的后一个就是扩展名
if ext =='.jpg':#意思就是找这个文件路径中的所有的jpg文件
filename = filename.split('_')[-1][:-len('.jpg')]#ISIC的图片名称为'ISIC_0012169.jpg'.split() 通过指定分隔符对字符串进行切片,返回字符串列表。split执行完['ISIC','0012169.jpg']这个列表[-1]就是'0012169.jpg',对这个字符串进行切片操作[:-len('.jpg')]就是去掉.jpg。最后只留下了'0012169'
data_list.append('ISIC_'+filename+'.jpg') # image的文件名
GT_list.append('ISIC_'+filename+'_segmentation.png') # mask的文件名
而我的Image的文件名和mask的文件名相同(eg:image名字:0001.jpg,mask名字:0001.jpg),所以我用basename()提取他们的文件名,换一下路径就可以通过image的路径找到对应的mask的路径了。
#os.path.basename(filename)返回path最后的文件名
for filename in filenames:
ext = os.path.splitext(filename)[-1]
if ext == '.jpg':#找出所有的jpg文件
filename = os.path.basename(filename)#如果filename='/下载/code/tg3k/0001.jpg',经过os.path.basename后就变成了'0001.jpg'
data_list.append(filename)
GT_list.append(filename)
def main(config):
rm_mkdir(config.train_path)#如果原来存在train_data的路径则删除,重新建立训练集、验证集、测试集
rm_mkdir(config.train_GT_path)
rm_mkdir(config.valid_path)
rm_mkdir(config.valid_GT_path)
rm_mkdir(config.test_path)
rm_mkdir(config.test_GT_path)
filenames = os.listdir(config.origin_data_path)
data_list = [] #存储image的容器
GT_list = [] #存储mask的容器
for filename in filenames:
ext = os.path.splitext(filename)[-1]
if ext == '.jpg':
filename = os.path.basename(filename)
data_list.append(filename)
GT_list.append(filename) # image和mask同事存入对应的列表
num_total = len(data_list) #总的数据量
num_train = int((config.train_ratio / (config.train_ratio + config.valid_ratio + config.test_ratio)) * num_total) #指定的训练集、验证集、测试集的比例,按照这个比例划分数据集,计算出训练集、验证集、测试集的数据量
num_valid = int((config.valid_ratio / (config.train_ratio + config.valid_ratio + config.test_ratio)) * num_total)
num_test = num_total - num_train - num_valid
print('\nNum of train set : ', num_train)
print('\nNum of valid set : ', num_valid)
print('\nNum of test set : ', num_test)
Arange = list(range(num_total))
random.shuffle(Arange)# random.shuffle()用于将一个列表中的元素打乱顺序,值得注意的是使用这个方法不会生成新的列表,只是将原列表的次序打乱。
for i in range(num_train):#随机抽取一定数量的数据形成训练集
idx = Arange.pop() # Arange进行了顺序打乱,pop出来的数据是乱序,抽取相应的数据后,把该数据从列表中删除
src = os.path.join(config.origin_data_path, data_list[idx]) # os.path.join()函数用于路径拼接文件路径
dst = os.path.join(config.train_path, data_list[idx])
copyfile(src, dst)#把原来数据集的图片转移到自己创建的训练数据集文件中
src = os.path.join(config.origin_GT_path, GT_list[idx])
dst = os.path.join(config.train_GT_path, GT_list[idx])
copyfile(src, dst)#把原来数据集的mask转移到自己创建的训练数据集文件中
printProgressBar(i + 1, num_train, prefix='Producing train set:', suffix='Complete', length=50)#进度条
for i in range(num_valid):#同样的逻辑生成验证数据集
idx = Arange.pop()
src = os.path.join(config.origin_data_path, data_list[idx])
dst = os.path.join(config.valid_path, data_list[idx])
copyfile(src, dst)
src = os.path.join(config.origin_GT_path, GT_list[idx])
dst = os.path.join(config.valid_GT_path, GT_list[idx])
copyfile(src, dst)
printProgressBar(i + 1, num_valid, prefix='Producing valid set:', suffix='Complete', length=50)
for i in range(num_test):#同样的逻辑生成测试数据集
idx = Arange.pop()
src = os.path.join(config.origin_data_path, data_list[idx])
dst = os.path.join(config.test_path, data_list[idx])
copyfile(src, dst)
src = os.path.join(config.origin_GT_path, GT_list[idx])
dst = os.path.join(config.test_GT_path, GT_list[idx])
copyfile(src, dst)
printProgressBar(i + 1, num_test, prefix='Producing test set:', suffix='Complete', length=50)
下面用了argparse,argparse是一个Python模块:命令行选项、参数和子命令解析器。用add_argument()函数添加参数,parse_args()解析参数。
具体看这个博主写的文章:argparse.ArgumentParser()用法解析。把相应的参数都配置好,就可以运行了。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# model hyper-parameters
parser.add_argument('--train_ratio', type=float, default=0.6)
parser.add_argument('--valid_ratio', type=float, default=0.2)
parser.add_argument('--test_ratio', type=float, default=0.2)
# data path
parser.add_argument('--origin_data_path', type=str, default='D:/data/Thyroid Dataset all/tg3k/thyroid-image')
parser.add_argument('--origin_GT_path', type=str, default='D:/data/Thyroid Dataset all/tg3k/thyroid-mask_1')
parser.add_argument('--train_path', type=str, default='./dataset/train/')
parser.add_argument('--train_GT_path', type=str, default='./dataset/train_GT/')
parser.add_argument('--valid_path', type=str, default='./dataset/valid/')
parser.add_argument('--valid_GT_path', type=str, default='./dataset/valid_GT/')
parser.add_argument('--test_path', type=str, default='./dataset/test/')
parser.add_argument('--test_GT_path', type=str, default='./dataset/test_GT/')
config = parser.parse_args()
print(config)
main(config)
运行dataset.py,你的文件夹下应该就出现了6个文件夹。
然后看data_loader.py。里面包含了读取图片和数据增强。
import os
import random
from random import shuffle
import numpy as np
import torch
from torch.utils import data
from torchvision import transforms as T
from torchvision.transforms import functional as F
from PIL import Image
class ImageFolder(data.Dataset):#getitem函数返回图像+标签
def __init__(self, root, image_size=224, mode='train', augmentation_prob=0.4):
"""Initializes image paths and preprocessing module."""
self.root = root
# GT : Ground Truth
self.GT_paths = root[:-1] + '_GT/'#不管是训练验证测试数据集,它的图片和mask的文件夹都是差了个'_GT',先去掉最后一个字符'/'添加'_GT/'就可以得到mask的图片路径。
self.image_paths = list(map(lambda x: os.path.join(root, x), os.listdir(root)))#读取图片,存于列表中
'''lambda匿名函数 eg:
map(lambda x: x**2, [1, 2, 3, 4, 5])
结果:[1,4,9,16,25]
前面是函数,后面是输入。得到输出
'''
'''os.listdir()方法用于返回指定文件夹包含的文件或文件夹名字的列表,他不包括.和..即使它在文件夹中
os.lisdir(path)
'''
self.image_size = image_size
self.mode = mode
self.RotationDegree = [0, 90, 180, 270]#图像翻转,数据增强
self.augmentation_prob = augmentation_prob #augmentation_prob:数据增强的比例
print("image count in {} path :{}".format(self.mode, len(self.image_paths)))
def __getitem__(self, index):
#,__getitem__函数接收一个index,然后返回图片数据和标签,这个index通常是指一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息
#index是一个索引,这个索引的取值范围是要根据__len__这个返回值确定的
"""Reads an image from a file and preprocesses it and returns."""
image_path = self.image_paths[index]
filename = os.path.basename(image_path)
GT_path = self.GT_paths + filename#我的图片和标签名字相同,根据不同数据集的改即可
image = Image.open(image_path)
GT = Image.open(GT_path)
aspect_ratio = image.size[1] / image.size[0]
#https://blog.csdn.net/xijuezhu8128/article/details/106142126
#上面有对不同图片读取方式的形状相关参数顺序
Transform = []
ResizeRange = random.randint(300, 320)
Transform.append(T.Resize((int(ResizeRange * aspect_ratio), ResizeRange)))#这个没反吗怎么理解?和上面size[0],size[1]的数据不一样吗?
# 上面是数字增强
p_transform = random.random() #随机生成一个数,来判断要不要进行下一个旋转
if (self.mode == 'train') and p_transform <= self.augmentation_prob:
RotationDegree = random.randint(0, 3)
RotationDegree = self.RotationDegree[RotationDegree]
if (RotationDegree == 90) or (RotationDegree == 270):
aspect_ratio = 1 / aspect_ratio#高宽对调
Transform.append(T.RandomRotation((RotationDegree, RotationDegree)))
RotationRange = random.randint(-10, 10)
Transform.append(T.RandomRotation((RotationRange, RotationRange)))
CropRange = random.randint(250, 270)
Transform.append(T.CenterCrop((int(CropRange * aspect_ratio), CropRange)))
Transform = T.Compose(Transform) #torchvision.transforms是图像预处理包,compose是表示把多个处理结合在一起
image = Transform(image)
GT = Transform(GT)
ShiftRange_left = random.randint(0, 20)
ShiftRange_upper = random.randint(0, 20)
ShiftRange_right = image.size[0] - random.randint(0, 20)
ShiftRange_lower = image.size[1] - random.randint(0, 20)
image = image.crop(box=(ShiftRange_left, ShiftRange_upper, ShiftRange_right, ShiftRange_lower))
GT = GT.crop(box=(ShiftRange_left, ShiftRange_upper, ShiftRange_right, ShiftRange_lower))
if random.random() < 0.5:
image = F.hflip(image)
GT = F.hflip(GT)
if random.random() < 0.5:
image = F.vflip(image)
GT = F.vflip(GT)
Transform = T.ColorJitter(brightness=0.2, contrast=0.2, hue=0.02)
image = Transform(image)
Transform = []
Transform.append(T.Resize((int(256 * aspect_ratio) - int(256 * aspect_ratio) % 16, 256)))
Transform.append(T.ToTensor())
Transform = T.Compose(Transform)
image = Transform(image)
GT = Transform(GT)
GT = (GT>127)*255.0# 我的mask是灰度图,所以用这个转化一下,和我情况不同的就注释掉。
#print(GT)
Norm_ = T.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))#先计算出其方差与均值,然后再将其每一个通道内的每一个数据减去均值,再除以方差,得到归一化后的结果。
#有3个通道所以有3个0.5
image = Norm_(image)
return image, GT
def __len__(self):
"""Returns the total number of font files."""
return len(self.image_paths)
def get_loader(image_path, image_size, batch_size, num_workers=2, mode='train', augmentation_prob=0.4):
"""Builds and returns Dataloader."""
dataset = ImageFolder(root=image_path, image_size=image_size, mode=mode, augmentation_prob=augmentation_prob)#读取数据
data_loader = data.DataLoader(dataset=dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers)#加入批量
return data_loader
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
学习率衰减(learning rate decay)
为了防止学习率过大,在收敛到全局最优点的时候会来回摆荡,所以要让学习率随着训练轮数不断按指数级下降,收敛梯度下降的学习步长。
数据增强有机会好好学学,整理整理。
介绍transforms中的函数
Resize:把给定的图片resize到given size
Normalize:Normalized an tensor image with mean and standard deviation
ToTensor:convert a PIL image to tensor (HWC) in range [0,255] to a torch.Tensor(CHW) in the range [0.0,1.0]
ToPILImage: convert a tensor to PIL image
Scale:目前已经不用了,推荐用Resize
CenterCrop:在图片的中间区域进行裁剪
RandomCrop:在一个随机的位置进行裁剪
RandomHorizontalFlip:以0.5的概率水平翻转给定的PIL图像
RandomVerticalFlip:以0.5的概率竖直翻转给定的PIL图像
RandomResizedCrop:将PIL图像裁剪成任意大小和纵横比
Grayscale:将图像转换为灰度图像
RandomGrayscale:将图像以一定的概率转换为灰度图像
FiceCrop:把图像裁剪为四个角和一个中心
TenCrop
Pad:填充
ColorJitter:随机改变图像的亮度对比度和饱和度
以上来自:torchvision.transforms 的CenterCrop():在图片的中间区域进行裁剪
二、Training
1.Define Neural Network
Network我就照搬了。可以看模型结构图,写代码。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
def init_weights(net, init_type='normal', gain=0.02):#如何初始化权重,看网络中用到的模块
def init_func(m):
classname = m.__class__.__name__
if hasattr(m, 'weight') and (classname.find('Conv') != -1 or classname.find('Linear') != -1):
if init_type == 'normal':
init.normal_(m.weight.data, 0.0, gain)
elif init_type == 'xavier':
init.xavier_normal_(m.weight.data, gain=gain)
elif init_type == 'kaiming':
init.kaiming_normal_(m.weight.data, a=0, mode='fan_in')
elif init_type == 'orthogonal':
init.orthogonal_(m.weight.data, gain=gain)
else:
raise NotImplementedError('initialization method [%s] is not implemented' % init_type)
if hasattr(m, 'bias') and m.bias is not None:
init.constant_(m.bias.data, 0.0)
elif classname.find('BatchNorm2d') != -1:
init.normal_(m.weight.data, 1.0, gain)
init.constant_(m.bias.data, 0.0)
print('initialize network with %s' % init_type)
net.apply(init_func)
class conv_block(nn.Module):
def __init__(self, ch_in, ch_out):
super(conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True),
nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class up_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x
class Recurrent_block(nn.Module):
def __init__(self, ch_out, t=2):
super(Recurrent_block, self).__init__()
self.t = t
self.ch_out = ch_out
self.conv = nn.Sequential(
nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
for i in range(self.t):
if i == 0:
x1 = self.conv(x)
x1 = self.conv(x + x1)
return x1
class RRCNN_block(nn.Module):
def __init__(self, ch_in, ch_out, t=2):
super(RRCNN_block, self).__init__()
self.RCNN = nn.Sequential(
Recurrent_block(ch_out, t=t),
Recurrent_block(ch_out, t=t)
)
self.Conv_1x1 = nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.Conv_1x1(x)
x1 = self.RCNN(x)
return x + x1
class single_conv(nn.Module):
def __init__(self, ch_in, ch_out):
super(single_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(ch_out),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class Attention_block(nn.Module):
def __init__(self, F_g, F_l, F_int):
super(Attention_block, self).__init__()
self.W_g = nn.Sequential(
nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.W_x = nn.Sequential(
nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(F_int)
)
self.psi = nn.Sequential(
nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.relu = nn.ReLU(inplace=True)
def forward(self, g, x):
g1 = self.W_g(g)
x1 = self.W_x(x)
psi = self.relu(g1 + x1)
psi = self.psi(psi)
return x * psi
class U_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1):
super(U_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
class R2U_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1, t=2):
super(R2U_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Upsample = nn.Upsample(scale_factor=2)
self.RRCNN1 = RRCNN_block(ch_in=img_ch, ch_out=64, t=t)
self.RRCNN2 = RRCNN_block(ch_in=64, ch_out=128, t=t)
self.RRCNN3 = RRCNN_block(ch_in=128, ch_out=256, t=t)
self.RRCNN4 = RRCNN_block(ch_in=256, ch_out=512, t=t)
self.RRCNN5 = RRCNN_block(ch_in=512, ch_out=1024, t=t)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Up_RRCNN5 = RRCNN_block(ch_in=1024, ch_out=512, t=t)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Up_RRCNN4 = RRCNN_block(ch_in=512, ch_out=256, t=t)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Up_RRCNN3 = RRCNN_block(ch_in=256, ch_out=128, t=t)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Up_RRCNN2 = RRCNN_block(ch_in=128, ch_out=64, t=t)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.RRCNN1(x)
x2 = self.Maxpool(x1)
x2 = self.RRCNN2(x2)
x3 = self.Maxpool(x2)
x3 = self.RRCNN3(x3)
x4 = self.Maxpool(x3)
x4 = self.RRCNN4(x4)
x5 = self.Maxpool(x4)
x5 = self.RRCNN5(x5)
# decoding + concat path
d5 = self.Up5(x5)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_RRCNN5(d5)
d4 = self.Up4(d5)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_RRCNN4(d4)
d3 = self.Up3(d4)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_RRCNN3(d3)
d2 = self.Up2(d3)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_RRCNN2(d2)
d1 = self.Conv_1x1(d2)
return d1
class AttU_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1):
super(AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Conv1 = conv_block(ch_in=img_ch, ch_out=64)
self.Conv2 = conv_block(ch_in=64, ch_out=128)
self.Conv3 = conv_block(ch_in=128, ch_out=256)
self.Conv4 = conv_block(ch_in=256, ch_out=512)
self.Conv5 = conv_block(ch_in=512, ch_out=1024)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
class R2AttU_Net(nn.Module):
def __init__(self, img_ch=3, output_ch=1, t=2):
super(R2AttU_Net, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2)
self.Upsample = nn.Upsample(scale_factor=2)
self.RRCNN1 = RRCNN_block(ch_in=img_ch, ch_out=64, t=t)
self.RRCNN2 = RRCNN_block(ch_in=64, ch_out=128, t=t)
self.RRCNN3 = RRCNN_block(ch_in=128, ch_out=256, t=t)
self.RRCNN4 = RRCNN_block(ch_in=256, ch_out=512, t=t)
self.RRCNN5 = RRCNN_block(ch_in=512, ch_out=1024, t=t)
self.Up5 = up_conv(ch_in=1024, ch_out=512)
self.Att5 = Attention_block(F_g=512, F_l=512, F_int=256)
self.Up_RRCNN5 = RRCNN_block(ch_in=1024, ch_out=512, t=t)
self.Up4 = up_conv(ch_in=512, ch_out=256)
self.Att4 = Attention_block(F_g=256, F_l=256, F_int=128)
self.Up_RRCNN4 = RRCNN_block(ch_in=512, ch_out=256, t=t)
self.Up3 = up_conv(ch_in=256, ch_out=128)
self.Att3 = Attention_block(F_g=128, F_l=128, F_int=64)
self.Up_RRCNN3 = RRCNN_block(ch_in=256, ch_out=128, t=t)
self.Up2 = up_conv(ch_in=128, ch_out=64)
self.Att2 = Attention_block(F_g=64, F_l=64, F_int=32)
self.Up_RRCNN2 = RRCNN_block(ch_in=128, ch_out=64, t=t)
self.Conv_1x1 = nn.Conv2d(64, output_ch, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# encoding path
x1 = self.RRCNN1(x)
x2 = self.Maxpool(x1)
x2 = self.RRCNN2(x2)
x3 = self.Maxpool(x2)
x3 = self.RRCNN3(x3)
x4 = self.Maxpool(x3)
x4 = self.RRCNN4(x4)
x5 = self.Maxpool(x4)
x5 = self.RRCNN5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5, x=x4)
d5 = torch.cat((x4, d5), dim=1)
d5 = self.Up_RRCNN5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4, x=x3)
d4 = torch.cat((x3, d4), dim=1)
d4 = self.Up_RRCNN4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3, x=x2)
d3 = torch.cat((x2, d3), dim=1)
d3 = self.Up_RRCNN3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2, x=x1)
d2 = torch.cat((x1, d2), dim=1)
d2 = self.Up_RRCNN2(d2)
d1 = self.Conv_1x1(d2)
return d1
2.Loss function
这个项目中用的BCELoss,单标签二分类。所以GT二值化是有必要的。
3.Optimization Algorithm
用的Adam算法。
李宏毅视频中提到过 Training Loop。如下所示。
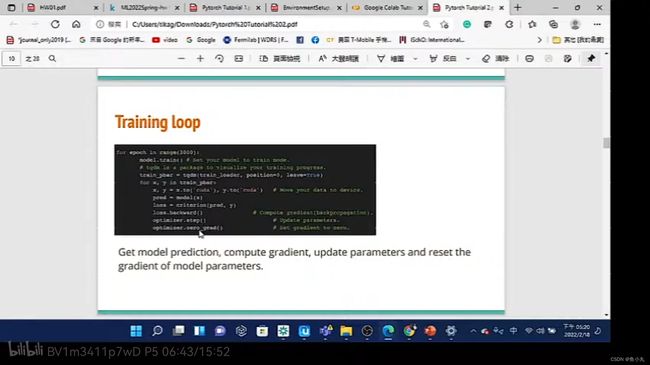
我们看他的solver.py
import os
import numpy as np
import time
import datetime
import torch
import torchvision
from torch import optim
from torch.autograd import Variable
import torch.nn.functional as F
from evaluation import *
from network import U_Net, R2U_Net, AttU_Net, R2AttU_Net
import csv
class Solver(object):
def __init__(self, config, train_loader, valid_loader, test_loader):#前面在初始化一大堆参数
# Data loader
self.train_loader = train_loader
self.valid_loader = valid_loader
self.test_loader = test_loader
# Models
self.unet = None
self.optimizer = None
self.img_ch = config.img_ch
self.output_ch = config.output_ch
self.criterion = torch.nn.BCELoss()
self.augmentation_prob = config.augmentation_prob
# Hyper-parameters
self.lr = config.lr
self.beta1 = config.beta1
self.beta2 = config.beta2
# Training settings
self.num_epochs = config.num_epochs
self.num_epochs_decay = config.num_epochs_decay
self.batch_size = config.batch_size
# Step size
self.log_step = config.log_step
self.val_step = config.val_step
# Path
self.model_path = config.model_path
self.result_path = config.result_path
self.mode = config.mode
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model_type = config.model_type
self.t = config.t
self.build_model()
def build_model(self):#建立自己选定的模型
"""Build generator and discriminator."""
if self.model_type == 'U_Net':
self.unet = U_Net(img_ch=3, output_ch=1)
elif self.model_type == 'R2U_Net':
self.unet = R2U_Net(img_ch=3, output_ch=1, t=self.t)
elif self.model_type == 'AttU_Net':
self.unet = AttU_Net(img_ch=3, output_ch=1)
elif self.model_type == 'R2AttU_Net':
self.unet = R2AttU_Net(img_ch=3, output_ch=1, t=self.t)
self.optimizer = optim.Adam(list(self.unet.parameters()),
self.lr, [self.beta1, self.beta2])
self.unet.to(self.device)
# self.print_network(self.unet, self.model_type)
def print_network(self, model, name):#打印模型结构+名称及参数数
"""Print out the network information."""
num_params = 0
for p in model.parameters():
num_params += p.numel()
print(model)
print(name)
print("The number of parameters: {}".format(num_params))
def to_data(self, x):
"""Convert variable to tensor."""
if torch.cuda.is_available():
x = x.cpu()#我以为他available就用gpu,他用的cpu,不知道怎么理解,呜呜
return x.data
def update_lr(self, g_lr, d_lr):#更新学习率,可能训练的时候会改self.lr,self.lr改变然后更新参数里面的lr
for param_group in self.optimizer.param_groups:
param_group['lr'] = self.lr
def reset_grad(self):#是不是测试会用到
"""Zero the gradient buffers."""
self.unet.zero_grad()
def compute_accuracy(self, SR, GT):
SR_flat = SR.view(-1)
GT_flat = GT.view(-1)
acc = GT_flat.data.cpu() == (SR_flat.data.cpu() > 0.5)
def tensor2img(self, x):
img = (x[:, 0, :, :] > x[:, 1, :, :]).float()
img = img * 255
return img
def train(self):
"""Train encoder, generator and discriminator."""
# ====================================== Training ===========================================#
# ===========================================================================================#
unet_path = os.path.join(self.model_path, '%s-%d-%.4f-%d-%.4f.pkl' % (
self.model_type, self.num_epochs, self.lr, self.num_epochs_decay, self.augmentation_prob))
# U-Net Train
if os.path.isfile(unet_path):
# Load the p
# retrained Encoder
self.unet.load_state_dict(torch.load(unet_path))#注意选择不同的模型,就会读取不同的模型文件,如果之前训练过的话
print('%s is Successfully Loaded from %s' % (self.model_type, unet_path))
else:
# Train for Encoder
lr = self.lr
for epoch in range(self.num_epochs):
self.unet.train(True)
epoch_loss = 0
#每次训练把指标都清零
acc = 0. # Accuracy
SE = 0. # Sensitivity (Recall)
SP = 0. # Specificity
PC = 0. # Precision
F1 = 0. # F1 Score
JS = 0. # Jaccard Similarity
DC = 0. # Dice Coefficient
length = 0
for i, (images, GT) in enumerate(self.train_loader):
#enumerate()函数用于
# GT : Ground Truth
images = images.to(self.device)
GT = GT.to(self.device)
# SR : Segmentation Result
SR = self.unet(images)
SR_probs = torch.sigmoid(SR)
SR_flat = SR_probs.view(SR_probs.size(0), -1)
GT_flat = GT.view(GT.size(0), -1)
loss = self.criterion(SR_flat, GT_flat)#定义好loss
epoch_loss += loss.item()
# Backprop + optimize
self.reset_grad()
loss.backward() #train的时候要回传
self.optimizer.step()# 优化
acc += get_accuracy(SR, GT)
SE += get_sensitivity(SR, GT)
SP += get_specificity(SR, GT)
PC += get_precision(SR, GT)
F1 += get_F1(SR, GT)
JS += get_JS(SR, GT)
DC += get_DC(SR, GT)
length += images.size(0)
acc = acc / length
SE = SE / length
SP = SP / length
PC = PC / length
F1 = F1 / length
JS = JS / length
DC = DC / length
# Print the log info
print(
'Epoch [%d/%d], Loss: %.4f, \n[Training] Acc: %.4f, SE: %.4f, SP: %.4f, PC: %.4f, F1: %.4f, JS: %.4f, DC: %.4f' % (
epoch + 1, self.num_epochs, \
epoch_loss, \
acc, SE, SP, PC, F1, JS, DC))
print(SR)
# Decay learning rate
if (epoch + 1) > (self.num_epochs - self.num_epochs_decay):
lr -= (self.lr / float(self.num_epochs_decay))
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
print('Decay learning rate to lr: {}.'.format(lr))
# ===================================== Validation ====================================#
self.unet.train(False)# Validation的时候为False,不梯度回传
self.unet.eval()
acc = 0. # Accuracy
SE = 0. # Sensitivity (Recall)
SP = 0. # Specificity
PC = 0. # Precision
F1 = 0. # F1 Score
JS = 0. # Jaccard Similarity
DC = 0. # Dice Coefficient
length = 0
for i, (images, GT) in enumerate(self.valid_loader):
images = images.to(self.device)
GT = GT.to(self.device)
SR = F.sigmoid(self.unet(images))
acc += get_accuracy(SR, GT)
SE += get_sensitivity(SR, GT)
SP += get_specificity(SR, GT)
PC += get_precision(SR, GT)
F1 += get_F1(SR, GT)
JS += get_JS(SR, GT)
DC += get_DC(SR, GT)
length += images.size(0)
acc = acc / length
SE = SE / length
SP = SP / length
PC = PC / length
F1 = F1 / length
JS = JS / length
DC = DC / length
unet_score = JS + DC
print('[Validation] Acc: %.4f, SE: %.4f, SP: %.4f, PC: %.4f, F1: %.4f, JS: %.4f, DC: %.4f' % (
acc, SE, SP, PC, F1, JS, DC))
'''
torchvision.utils.save_image(images.data.cpu(),
os.path.join(self.result_path,
'%s_valid_%d_image.png'%(self.model_type,epoch+1)))
torchvision.utils.save_image(SR.data.cpu(),
os.path.join(self.result_path,
'%s_valid_%d_SR.png'%(self.model_type,epoch+1)))
torchvision.utils.save_image(GT.data.cpu(),
os.path.join(self.result_path,
'%s_valid_%d_GT.png'%(self.model_type,epoch+1)))
'''
# Save Best U-Net model
best_unet_score=0
if unet_score > best_unet_score:
best_unet_score = unet_score
best_epoch = epoch
best_unet = self.unet.state_dict()
print('Best %s model score : %.4f' % (self.model_type, best_unet_score))
torch.save(best_unet, unet_path)
# ===================================== Test ====================================#
del self.unet
del best_unet
self.build_model()
self.unet.load_state_dict(torch.load(unet_path))
self.unet.train(False)
self.unet.eval()
acc = 0. # Accuracy
SE = 0. # Sensitivity (Recall)
SP = 0. # Specificity
PC = 0. # Precision
F1 = 0. # F1 Score
JS = 0. # Jaccard Similarity
DC = 0. # Dice Coefficient
length = 0
for i, (images, GT) in enumerate(self.valid_loader):
images = images.to(self.device)
GT = GT.to(self.device)
SR = F.sigmoid(self.unet(images))
acc += get_accuracy(SR, GT)
SE += get_sensitivity(SR, GT)
SP += get_specificity(SR, GT)
PC += get_precision(SR, GT)
F1 += get_F1(SR, GT)
JS += get_JS(SR, GT)
DC += get_DC(SR, GT)
length += images.size(0)
acc = acc / length
SE = SE / length
SP = SP / length
PC = PC / length
F1 = F1 / length
JS = JS / length
DC = DC / length
unet_score = JS + DC
f = open(os.path.join(self.result_path, 'result.csv'), 'a', encoding='utf-8', newline='')
wr = csv.writer(f)
wr.writerow([self.model_type, acc, SE, SP, PC, F1, JS, DC, self.lr, self.num_epochs,
self.num_epochs_decay, self.augmentation_prob])#在lr后面
f.close()
三、Validation
都在solver.py中。
四、Testing
都在solver.py中。
五、Evaluation
可以看出训练、验证、测试的时候都用到了相应的指标进行模型评价。
evaluation.py中。
import torch
# SR : Segmentation Result
# GT : Ground Truth
def get_accuracy(SR,GT,threshold=0.5):
SR = SR > threshold
GT = GT == torch.max(GT)
corr = torch.sum(SR==GT)
tensor_size = SR.size(0)*SR.size(1)*SR.size(2)*SR.size(3)
acc = float(corr)/float(tensor_size)
return acc
def get_sensitivity(SR,GT,threshold=0.5):
# Sensitivity == Recall
SR = SR > threshold
GT = GT == torch.max(GT)
# TP : True Positive
# FN : False Negative
TP = ((SR==1)+(GT==1))==2
FN = ((SR==0)+(GT==1))==2
print("%.4f",torch.sum(TP))
print("%d", torch.sum(FN))
SE = float(torch.sum(TP))/(float(torch.sum(TP+FN)) + 1e-6)
return SE
def get_specificity(SR,GT,threshold=0.5):
SR = SR > threshold
GT = GT == torch.max(GT)
# TN : True Negative
# FP : False Positive
TN = ((SR==0)+(GT==0))==2
FP = ((SR==1)+(GT==0))==2
SP = float(torch.sum(TN))/(float(torch.sum(TN+FP)) + 1e-6)
return SP
def get_precision(SR,GT,threshold=0.5):
SR = SR > threshold
GT = GT == torch.max(GT)
# TP : True Positive
# FP : False Positive
TP = ((SR==1)+(GT==1))==2
FP = ((SR==1)+(GT==0))==2
PC = float(torch.sum(TP))/(float(torch.sum(TP+FP)) + 1e-6)
return PC
def get_F1(SR,GT,threshold=0.5):
# Sensitivity == Recall
SE = get_sensitivity(SR,GT,threshold=threshold)
PC = get_precision(SR,GT,threshold=threshold)
F1 = 2*SE*PC/(SE+PC + 1e-6)
return F1
def get_JS(SR,GT,threshold=0.5):
# JS : Jaccard similarity
SR = SR > threshold
GT = GT == torch.max(GT)
Inter = torch.sum((SR+GT)==2)
Union = torch.sum((SR+GT)>=1)
JS = float(Inter)/(float(Union) + 1e-6)
return JS
def get_DC(SR,GT,threshold=0.5):
# DC : Dice Coefficient
SR = SR > threshold
GT = GT == torch.max(GT)
Inter = torch.sum((SR+GT)==2)
DC = float(2*Inter)/(float(torch.sum(SR)+torch.sum(GT)) + 1e-6)
return DC
Main.py
按需要设置自己想要的参数就好。
argparse是一个Python模块:命令行选项、参数和子命令解析器。
argparse 模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数,然后 argparse 将弄清如何从 sys.argv 解析出那些参数。 argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息。
import argparse
import os
from solver import Solver
from data_loader import get_loader
from torch.backends import cudnn
import random
def main(config):
cudnn.benchmark = True
if config.model_type not in ['U_Net','R2U_Net','AttU_Net','R2AttU_Net']:
print('ERROR!! model_type should be selected in U_Net/R2U_Net/AttU_Net/R2AttU_Net')
print('Your input for model_type was %s'%config.model_type)
return
# Create directories if not exist
if not os.path.exists(config.model_path):
os.makedirs(config.model_path)
if not os.path.exists(config.result_path):
os.makedirs(config.result_path)
config.result_path = os.path.join(config.result_path,config.model_type)
if not os.path.exists(config.result_path):
os.makedirs(config.result_path)
lr = random.random()*0.0005 + 0.0000005
augmentation_prob= random.random()*0.
#epoch = random.choice([100,150,200,250])
epoch = 30
decay_ratio = random.random()*0.8
decay_epoch = int(epoch*decay_ratio)
config.augmentation_prob = augmentation_prob
config.num_epochs = epoch
config.lr = lr
config.num_epochs_decay = decay_epoch
print(config)
train_loader = get_loader(image_path=config.train_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='train',
augmentation_prob=config.augmentation_prob)
valid_loader = get_loader(image_path=config.valid_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='valid',
augmentation_prob=0.)
test_loader = get_loader(image_path=config.test_path,
image_size=config.image_size,
batch_size=config.batch_size,
num_workers=config.num_workers,
mode='test',
augmentation_prob=0.)
solver = Solver(config, train_loader, valid_loader, test_loader)
# Train and sample the images
if config.mode == 'train':
solver.train()
elif config.mode == 'test':
solver.test()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
# model hyper-parameters
parser.add_argument('--image_size', type=int, default=224)
parser.add_argument('--t', type=int, default=3, help='t for Recurrent step of R2U_Net or R2AttU_Net')
# training hyper-parameters
parser.add_argument('--img_ch', type=int, default=3)
parser.add_argument('--output_ch', type=int, default=1)
parser.add_argument('--num_epochs', type=int, default=100)
parser.add_argument('--num_epochs_decay', type=int, default=70)
parser.add_argument('--batch_size', type=int, default=1)
parser.add_argument('--num_workers', type=int, default=8)
parser.add_argument('--lr', type=float, default=0.0002)
parser.add_argument('--beta1', type=float, default=0.5) # momentum1 in Adam
parser.add_argument('--beta2', type=float, default=0.999) # momentum2 in Adam
parser.add_argument('--augmentation_prob', type=float, default=0.4)
parser.add_argument('--log_step', type=int, default=2)
parser.add_argument('--val_step', type=int, default=2)
# misc
parser.add_argument('--mode', type=str, default='train')
parser.add_argument('--model_type', type=str, default='U_Net', help='U_Net/R2U_Net/AttU_Net/R2AttU_Net')
parser.add_argument('--model_path', type=str, default='./models')
parser.add_argument('--train_path', type=str, default='./dataset/train/')
parser.add_argument('--valid_path', type=str, default='./dataset/valid/')
parser.add_argument('--test_path', type=str, default='./dataset/test/')
parser.add_argument('--result_path', type=str, default='./result/')
parser.add_argument('--cuda_idx', type=int, default=1)
config = parser.parse_args()
main(config)
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
学习率衰减(learning rate decay)
为了防止学习率过大,在收敛到全局最优点的时候会来回摆荡,所以要让学习率随着训练轮数不断按指数级下降,收敛梯度下降的学习步长。
进度条函数
misc.py
def printProgressBar (iteration, total, prefix = '', suffix = '', decimals = 1, length = 100, fill = '█'):
"""
Call in a loop to create terminal progress bar
@params:
iteration - Required : current iteration (Int)j
total - Required : total iterations (Int)
prefix - Optional : prefix string (Str)
suffix - Optional : suffix string (Str)
decimals - Optional : positive number of decimals in percent complete (Int)
length - Optional : character length of bar (Int)
fill - Optional : bafr fill character (Str)
"""
percent = ("{0:." + str(decimals) + "f}").format(100 * (iteration / float(total)))
filledLength = int(length * iteration // total)
bar = fill * filledLength + '-' * (length - filledLength)
print('\r%s |%s| %s%% %s' % (prefix, bar, percent, suffix), end = '\r')
# Print New Line on Complete
if iteration == total:
print()
总结
主要就是dataset.py和dataloader.py里面改改就可以,改成自己的路径。main.py可以根据自己的需要修改相应的参数。注意自己使用的数据集的图片类型即可。
参考:
- https://github.com/LeeJunHyun/Image_Segmentation
- https://www.jianshu.com/p/351445570056