毕业设计-基于计算机视觉的垃圾分类识别系统
目录
前言
课题背景和意义
实现技术思路
一、单目标垃圾图像识别研究
二、多目标垃圾图像识别研究
三、垃圾分类检测系统应用程序设计
四、系统功能设计
实现效果图样例
最后
前言
大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
毕业设计-基于计算机视觉的垃圾分类识别系统
课题背景和意义
垃圾分类是将日常生活、生产中产生的垃圾,经过分类投放、存储 和运输等一系列过程,使之转变成可供利用的公共资源。一直以来,国内垃圾分类的宣传力度不够,大部分民众环保意识薄弱, 难以养成日常生活垃圾分类的习惯。对于目前实行的垃圾“四分类”方 法,少部分有意识参与垃圾分类的人觉得繁琐,直接将各类垃圾混装处 理,而长期坚持垃圾分类的人更少。这使得垃圾后端处理工作量增大, 制约了后端设备运行效率。以人工智能为代表的技术创新已成为未来的发展趋势,作为人工智 能最为有力的表现形式,计算机视觉广泛应用于安防、金融、互联网、 交通、医疗等领域。计算机视觉技术是将图像输入装置与计算机相连 接,识别、跟踪预定目标,后续经过图像处理,使计算机能够从图像或 者多维数据中获取有用信息。借助计算机视觉来研究垃圾分类识别系 统,对垃圾图像进行识别、检测,从源头上对生活垃圾进行分类收集, 提高各类垃圾的回收利用率,也可在垃圾处理后端省却复杂的分选工 作,有效节省了垃圾处理的费用。
实现技术思路
一、单目标垃圾图像识别研究
单目标垃圾图像数据集构建

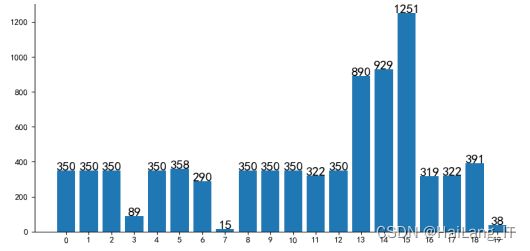
20 个小类的数据分布情况如图所示,数据分布总体上较均匀, 只有个别类别的数量或少或多。
基于特征融合的垃圾图像识别
对于图像的特征提取采用方向梯度直方图特征(HOG)和灰度共生 矩阵(GLCM)两者融合特征作为图像特征。
1、垃圾图像特征提取算法
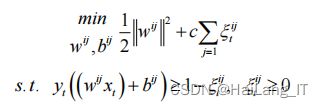
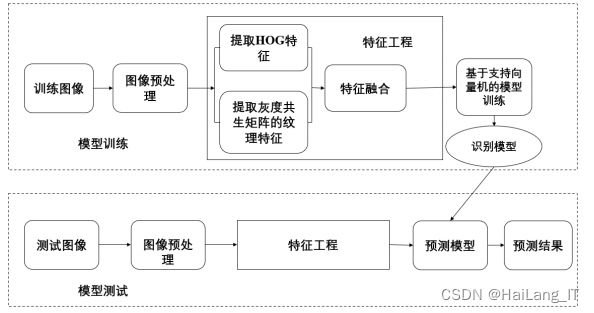
特征提取出的垃圾图像的 HOG 和 GLCM 的合并特征,用 SVM 分 类器训练,经训练后的具有垃圾分类识别能力的分类器对输入的未知单 目标垃圾图像进行识别,并输出相应的识别结果。具体的识别流程框图 如图所示。
基于卷积神经网络的垃圾图像识别
深度学习在图像分类中的应用主要是通过卷积神经网络来实现,采 用有监督的方法让计算机去学习表达某张图像的特征。
1、卷积神经网络模型结构
用于图像分类问题的卷积神经网络层结构主要包括:卷积层、池化 层、和全连接层。通过堆叠这些层级结构组成了一个较为完整的卷积 神经网络模型,如图所示。

在卷积神经网络结构中,卷积层占据核心地位,绝大部分计算都在 该层中完成。网络中的卷积层是由若干大小不同的卷积核构成,卷积层 的基础参数包括核大小、扫描步长和边缘填充数。这三者共同决定了卷 积层输出特征的尺寸大小。
2、卷积神经网络分类模型
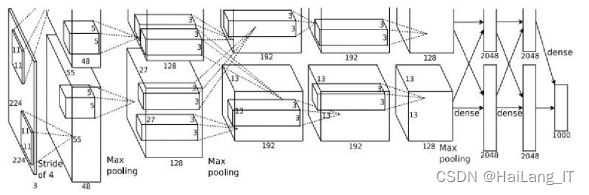
AlexNet 模型是由 Alex Krizhevsky 提出的一种深度神经网络模型。 作为 ILSVRC2012 的获胜者,AlexNet 为 8 层结构,由 5 层卷积层和 3 层全连接层组成。最后的 Softmax 分类层是一个输出 1000 类别的全连 接层。此外,它在每个卷积层后面添加了 Relu 激活函数,并应用了 dropout 层,减轻了模型的过拟合。AlexNet 网络模型结构如图所示:
VGGNet 也是一种深度卷积神经网 络。VGGNet 包含多层网络结构,深度从 11 层到 19 层不等,较为常用的是 VGG16 和 VGG19, VGG16 的网络结构如图所示。它继承了 AlexNet 的思路,以 AlexNet 为基础,建立了一个层次更多,结构更深 的网络。

ResNet 作为 2015 年 ImageNet 竞赛的冠军,由何凯明等人提出,借助残差模块能够训练出高达 152 层深的神经网络。其设计思路来源于: 随着神经网络结构不断加深,准确率会先上升然后达到饱和状态,继续 增加网络深度会出现模型准确率下降的情况。

3、迁移学习
对于深度学习的图像分类来说,经验法则是每个类别至少需要 1000 张图像,由于收集的数据图像不足,所以引入迁移学习来解决这一问题。迁移学习一般针对的是目标任务训练数据较少的情况,通过加载预训练 模型,结合更少的数据进行再次训练,它可以有效地迁移到这种训练数 据量不足的视觉任务,从而优化分类的效果。
二、多目标垃圾图像识别研究
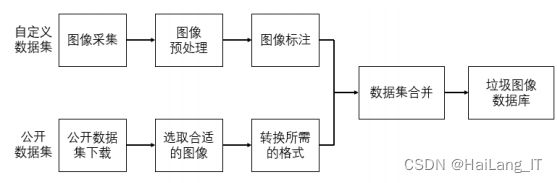
多目标垃圾图像数据集建立
目前对于垃圾图像分类的研究大多数为单目标垃圾图像,网上公开 的垃圾数据集也以单目标垃圾为主。为了扩大垃圾图像分类识别的应用 范围,针对在一张图像中对多个垃圾目标进行识别检测研究。为此,在研究中建立了一个多目标垃圾图像数据集。
标注垃圾的类别主要有 6 个小类,分别为烟蒂、塑料袋、塑料瓶、玻璃瓶、易拉罐、菜叶,共计 2000 张图片。图为多目标垃圾图像 数据集样本示例。

该数据集的格式按照 PASCAL VOC 数据集格式制作而成。VOC 数 据 集 的 格 式 包 含 三 个 重 要 的 部 分 : Annotations 、 JPEGImages 和 ImageSets。使用标注工具 LabelImg 对多目标垃圾图片进行标注,图片标注后 自动生成 xml 文件,标注工具界面如图所示。

YOLO 算法
双阶段目标检测算法(two-stage)和单阶段目标检测算法(one-stage) 是两类常见的目标检测算法作为一种端到端的目标检测算法,单阶段目标检测算法通过卷积神经网络提取特征后完成分类和回归,从而确定目标的位置和类 别信息。如图所示,分别为双阶段目标检测算法和单阶段 目标检测算法的基本流程图。
双阶段目标检测算法流程图

单阶段目标检测算法流程图

1、YOLO v3
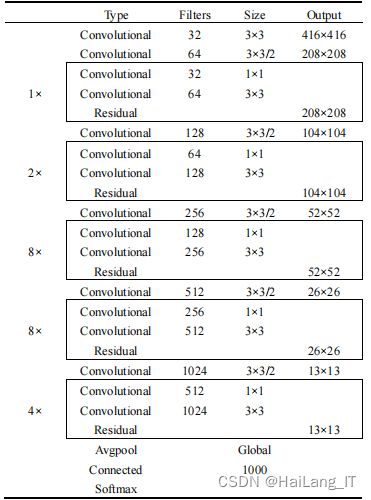
YOLO v3是在 YOLO v2 的基础上做了一些改进,所使用的主干 特征提取网络为 Darknet53,是在 YOLO v2 的 Darknet19 的基础上添加 了残差单元Residual结构。
Darknet53 的网络结构如表所示。 输入原始图像尺寸为 416×416 时,在经过多层的运算后,会获得尺 度大小为 13×13、26×26 和 52×52 的三个特征图。
2、YOLO v4
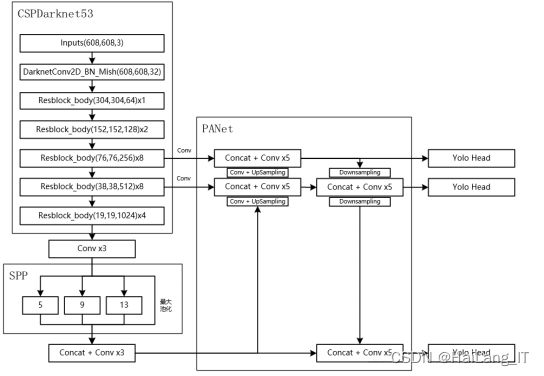
YOLO v4的使用的是 CSPDarknet53,与 YOLO v3 相比,多了 CSP 结构,即跨阶段局部网络。CSPNet 解决了其他卷积神经网络 Backbone 中网络优化的梯度信息重复问题,将梯度的变化集成到特征图中,因此 减少了模型的参数量,既保证了推理速度和准确率,又减小了模型尺寸。YOLO v4 整体结构如图所示。
基于注意力机制的 YOLO 模型改进
对于人类视觉来说,通常会花费更多的时间和精力,聚焦于重要目 标和重点区域。以便得到更多的细节信息,而忽略其它不相关信息。这 样能够在有限的视野范围内,快速获取到高价值、有意义的信息,使大 脑处理信息的效率得到大幅度提升。
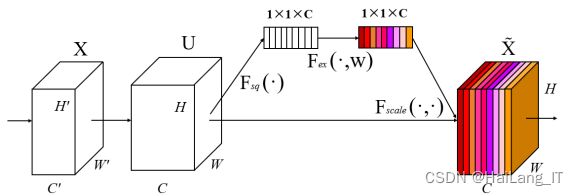
1、通道注意力机制
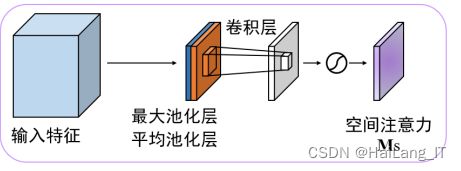
SENet是通道注意力机制的典型实现,其结构如图所示,对 于输入进来的特征层,就 SENet 而言,其重点是获得输入进来的特征层, 每一个通道的权值。
2、CBAM 注意力机制
CBAM是一种同时关注通道注意力机制和空间注意力机制的卷 积模块,相比于 SENet 只关注通道注意力能取得更好的效果,可以用于 卷积神经网络结构中,来提升特征层的特征表达能力。
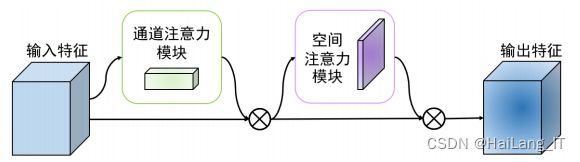
下图分别是通道注意力机制和空间注意力机制的具体实 现方式:
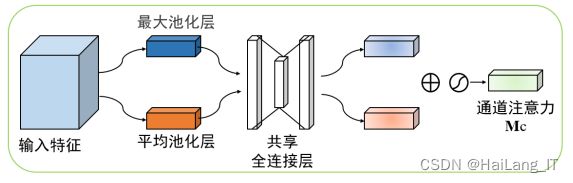
空间注意力模块:
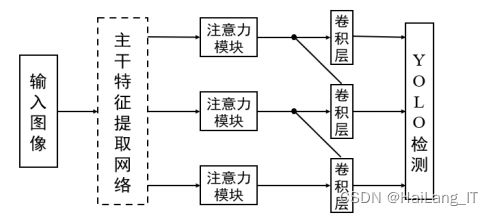
3、改进模型结构
注意力机制可以作为即插即用的模块添加到网络架构中,本文对于 YOLO 模型的改进是将注意力模块添加到 YOLO v3 主干特征提取网络 Darknet53 之后,用于加强从主干网络提取出来的三个有效特征图,以 便提高模型对垃圾图像重要特征的学习能力。改进模型结构如图所示。
三、垃圾分类检测系统应用程序设计
程序设计工具介绍
1、PyQt5 简介
为了方便使用 Python 语言开发创建图形用户界面(GUI)应用程序, PyQt5将Digia Qt5与Python融合于一身。作为Python的一个模块,PyQt5 可以通过 Python 语句调用 Qt 库中的应用程序接口(API)。因此,在开发 效率和运行效率上都有非常可观的表现,并且开发过程可实现可视化操 作。
2、Qt Designer 简介
在 PyQt5 中,应用程序设计既可以敲打纯代码来编写,也可以通过 Qt Designer 来实现。Qt Designer 的设计完全遵循 MVC 的基本结构,做 到了视图与逻辑面的完全分开,并采用了拖拽的方法实现复杂的界面设 计,同时还能够随时预览并查看页面的效果。
四、系统功能设计
系统在功能上主要分为:注册登录、垃圾图像检测、视频检测、实 时摄像头检测、检测结果保存。在程序设计上,采用模块化编程方式,通过编写不同的子程序来逐步实现各个功能模块,系统总体流程如图所示。
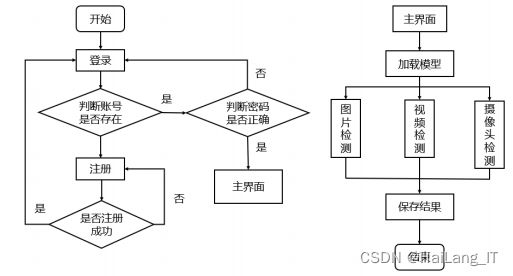
系统界面
1、注册与登陆界面
运行系统程序,弹出登录界面。将初始账号设为:admin,密码为: admin。若有新用户使用该系统,需要重新注册账号,设置密码。用户 可点击注册按钮弹出注册界面。在登陆界面的输入框内分别输入用户名 和密码点击登录即可完成登录功能。注册和登陆界面如图所示。

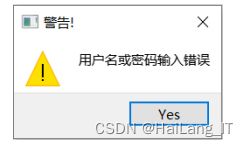
对该系统的任何操作,需要用户在登陆后才能继续完成,而且必须 在用户名、密码同时输入正确的情况下才能登录成功,若有错误则无法 正常登录该系统。若登录不成功,原因为用户名或者密码输入错误,会 弹出对话框进行提示,如图所示。
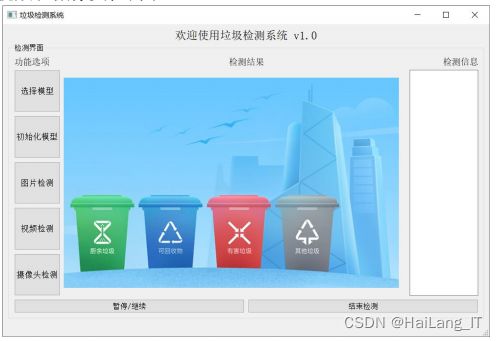
2、系统主界面
当用户成功登录后系统自动跳转到主界面,如图所示。该界面 主要由以下几个区域组成,分别为:系统标题区域、系统检测界面显示 区域、功能选项显示区域、检测结果显示区域以及检测信息输出区域。
垃圾分类检测系统测试
系统测试是对该系统各个功能分别进行检查和测试,保证系统能正 常运行,并能正常完成相应的功能。
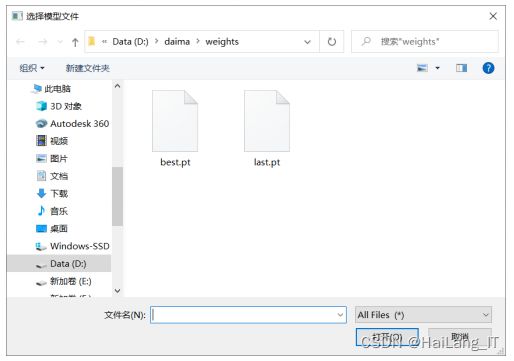
1、模型选择
利用 YOLO 算法训练自创的垃圾数据集,经过训练后 会在 weights 文件夹下得到 best.pt 和 last.pt 两种模型,如图所示。
2、模型初始化
点击“初始化模型”,使用 opt 中的默认参数设置来对模型进行初始 化,也可以修改相关参数后对模型进行初始化。
3、图片检测
点击“图片检测”,弹出待检测的垃圾图像的文件夹,如图所 示。

图片格式支持.jpg 和.png 格式。 例如选择“1.jpg”图片文件并打开,垃圾检测界面如图所示。

4、视频和摄像头检测
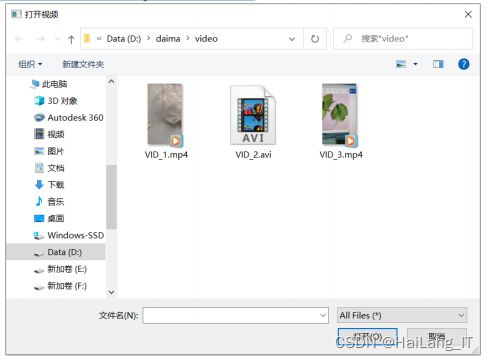
点击“视频检测”,可弹出待检测的垃圾视频的文件夹,如图所示。视频格式支持.mp4 和.avi 格式。
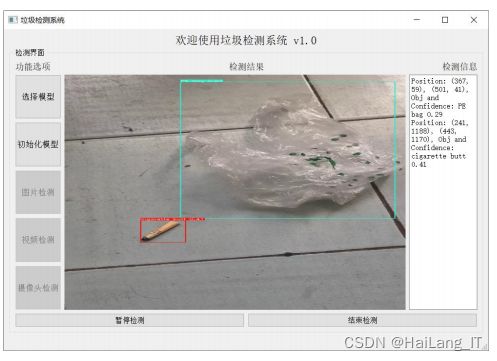
选中其中“VID_1.mp4”视频文件打开,在系统界面可播放检测, 视频检测时按下“暂停/继续”键,视频停止播放,如图所示。
5、检测结果保存
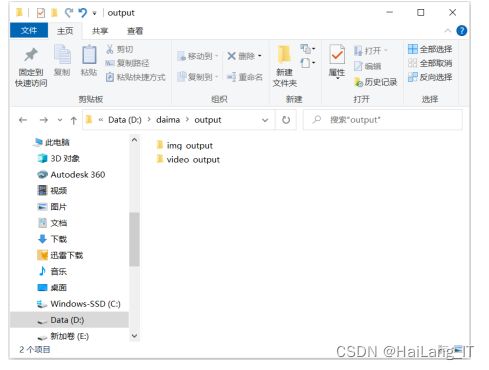
当系统完成图片、视频和摄像头检测后,系统会自动保存经过检测 框中的图像或视频文件,保存在“output”文件夹下,如图所示。
实现效果图样例
垃圾分类识别系统:

我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!