Kafka Log存储解析以及索引机制
1.概述
在Kafka架构,不管是生产者Producer还是消费者Consumer面向的都是Topic。Topic是逻辑上的概念,而Partition是物理上的概念。每个Partition逻辑上对应一个log文件,该log文件存储是Producer生产的数据。Producer生产的数据被不断追加到该log文件末端,且每条数据都有自己的offset。Kafka对于log文件是采取分片和索引机制。
2.Kafka的topic
启动kafka集群,集群中有三台Broker; 设置3个分区,3个副本;
2.1 创建hy-test-topic
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic hy-test-topic
2.2 发送消息到topic
public static void main(String[] args) {
//1.创建kakfa生产者的配置对象
Properties prop = new Properties();
//2.给生产者配置对象添加配置信息
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
prop.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
prop.put(ProducerConfig.LINGER_MS_CONFIG, 1);
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//3.创建生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(prop);
//4.调用send方法,发送消息
for (int i = 0; i < 5; i++) {
kafkaProducer.send(new ProducerRecord<String,String>("hy-test-topic",Integer.toString(i),Integer.toString(i)));
}
//5.关闭资源
kafkaProducer.close();
}
查看log.dirs
![]()
2.3 查看topic的分区和副本
bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic hy-test-topic
![]()
可以看出:
- 分区Partition-0 在
broker.id=4中,其余都是副本Replicas2,3 - 分区Partition-1 在
broker.id=2中,其余都是副本Replicas3,4 - 分区Partition-2 在
broker.id=3中,其余都是副本Replicas4,2
通过zookeeper查看leader在那个broker上
[zk: localhost:2181(CONNECTED) 14] get /kafka/brokers/topics/hy-test-topic/partitions/0/state
{"controller_epoch":49,"leader":4,"version":1,"leader_epoch":0,"isr":[4,2,3]}
2.4 分区文件

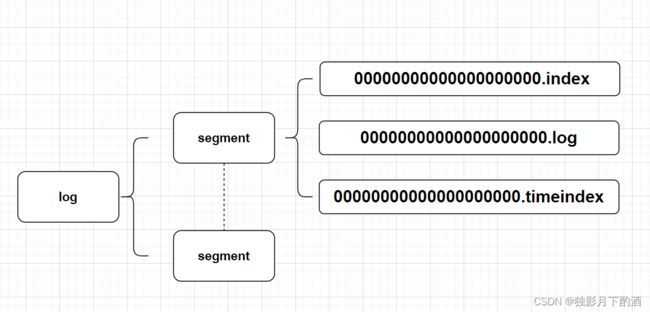
| 名称 | 描述 | 类型 | 默认 |
|---|---|---|---|
| log.segment.bytes | 单个日志文件的最大大小 | int | 1073741824(1G) |
继续发送消息会生成新的segment

可以看出
- 第一个segment文件
00000000000000000000.log快要达到log.segment.bytes时,开始创建00000000000000001187.log .log和.index、.timeindex文件是一起出现; 并且名称是以文件第一个offset命名的。- .log存储消息文件
- .index存储消息的索引
- .timeIndex,时间索引文件,通过时间戳做索引
2.5 分区下文件内容
使用kafka自带工具bin/kafka-run-class.sh 来读取分区下的文件内容
2.5.1 消息文件.log
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log

最后一行显示的是
baseOffset: 1186 position: 1072277020 CreateTime: 1695792070168
2.5.2 消息索引文件.index
bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index
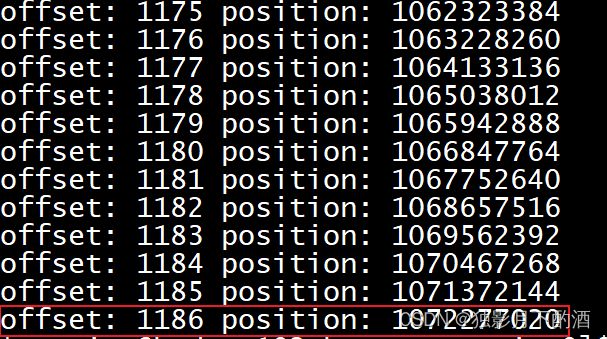
offset: 1186 position: 1072277020
2.5.3 时间索引文件.timeindex
/opt/module/kafka/bin/kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.timeindex

2.5.4 Kafka如何查找指定offset的Message
借用博主@lizhitao 博客上的一张图来展示是如何查找Message的。

比如:要查找绝对offset为7的Message:
- 首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
- 打开这个Segment的index文件,用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
- 打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
该机制是建立在offset是有序的。索引文件被映射到内存中,所以查找的速度还是很快的。
Kafka的Message存储采用了分区(partition),分段(LogSegment)和稀疏索引来达到了查找的高效性。
参考链接:https://cloud.tencent.com/developer/article/1846773