Flink-经典案例WordCount快速上手以及安装部署
2 Flink快速上手
2.1 批处理api
- 经典案例WordCount
public class BatchWordCount {
public static void main(String[] args) throws Exception {
//1.创建一个执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2.从文件中读取数据
//得到数据源,DataSource底层是DataSet这个数据集
DataSource<String> lineDataSource = env.readTextFile("input/words.txt");
//3.将每行数据进行分词,转换成二元组类型
//FlatMapOperator返回的是一个算子,底层是DataSet这个数据集
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
//将一行文本进行分词
String[] words = line.split(" ");
for (String word : words) {
//collect是收集器的用法,of是构建二元组的实例,并输出
out.collect(Tuple2.of(word, 1L));
}
}) //泛型擦除,指定tuple的类型
.returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.按照word进行分组
//和spark不一样,没有groupby,所以要根据索引指定key
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
//5.所以分组内进行聚合统计
//也是需要索引指定需要对哪一个求和,然后得到一个聚合算子
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
//6.打印输出
sum.print();
}
}
- 说明
以上的代码还是基于DataSet的api,但是DataSet的api已经处于软弃用,默认流处理,需要批处理的时候,将提交任务时通过执行模式设为batch进行,脚本如下
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
2.2 流处理
2.2.1 有界流
- 代码
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/words.txt");
//3.转换计算
//底层是DataStream
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.分组
//keyby传一个lambda表达式,Tuple提取当前第一个字段,Tuple的第一个字段定义分别是f0,f1
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6.打印输出
sum.print();
//7.启动执行
//一直处于流状态,需要给他启动
env.execute();
}
- 输出结果
10> (flink,1)
4> (hello,1)
2> (java,1)
4> (hello,2)
7> (world,1)
4> (hello,3)
最后结果和批处理一样,并伴随中间过程,而且乱序
代码使用多线程模拟的分布式集群,也就是并行度(默认是电脑cpu的核数),数字表示数字槽
2.2.2 无界流
- 代码
主要注意1,2,3到最后都是跟上面一样
public class StreamWordCount {
public static void main(String[] args) throws Exception {
//1.创建流失执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取文本流
DataStreamSource<String> lineDataStream = env.socketTextStream("192.168.60.132", 7777);
//3.转换计算
//底层是DataStream
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStream.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
String[] words = line.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
//4.分组
//keyby传一个lambda表达式,Tuple提取当前第一个字段,Tuple的第一个字段定义分别是f0,f1
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
//5.求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
//6.打印输出
sum.print();
//7.启动执行
//一直处于流状态,需要给他启动
env.execute();
}
}
- 或者直接配置好主机名和端口号的参数
- 代码编写
//从参数提取主机名和端口号
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
Integer port = parameterTool.getInt("port");
- idea设置
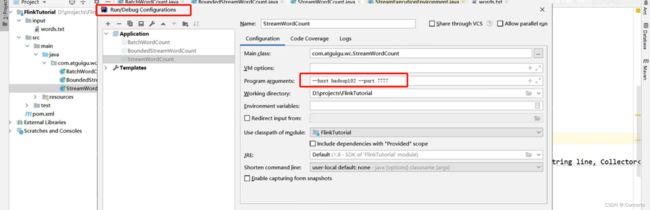
3 Flink部署
3.1 部署模式
- 会话模式
- 内容
先确定集群,并且资源确定,提交的作业会竞争集群中的集群
- 缺点
资源不够,提交作业失败
- 使用范围
会话模式使用与单个规模小,执行时间短的大量作业
- 单作业模式
- 内容
每个作业启动后启动集群,运行结束后,集群就会关闭
- 条件
单作业需要借助资源管理器
- 应用模式
- 内容
根据一个应用而后启动集群,直接交给JobManager
3.2 独立模式(standalone)的部署
- 会话模式
就刚刚的那些代码,先启动集群,在提交的作业
- 单作业模式
没有
- 应用模式部署
- 先把jar包放到/lib下
- 然后根据flink自带的jar包启动,会去自动扫描lib下的jar启动
- 启动taskmanager
- 停掉集群
3.3 yarn模式
3.3.1 总体流程
- 客户端把flink应用提交给Yarn的ResourceManager,然后RM再向NodeManager申请容器
- flink会部署JobManager和TaskManager的实例
- Flink会根据运行在JobManager上的作业所需要的Slot数量动态分配TaskManager资源
3.3.2 安装部署
- 解压
[hadoop1@hadoop2 software]$ tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/
- 分发
[hadoop1@hadoop2 module]$ xsync flink/
- 启动
[hadoop1@hadoop2 bin]$ ./start-cluster.sh
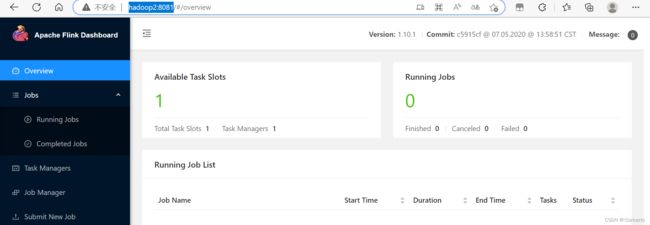
- 网页看下
http://hadoop2:8081/
- 配置环境变量
- hadoop
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath
- 激活
source /etc/profile.d/my_env.sh
- 分发
sudo /home/hadoop1/bin/xsync /etc/profile.d/my_env.sh
- 群起hadoop
[hadoop1@hadoop2 bin]$ hdp.sh start
=================== 启动 hadoop集群 ===================
--------------- 启动 hdfs ---------------
Starting namenodes on [hadoop2]
Starting datanodes
Starting secondary namenodes [hadoop4]
--------------- 启动 yarn ---------------
Starting resourcemanager
Starting nodemanagers
hadoop4: nodemanager is running as process 2335. Stop it first.
--------------- 启动 historyserver ---------------
- 检查情况
[hadoop1@hadoop2 bin]$ xcall jps
--------- hadoop2 ----------
3092 JobHistoryServer
2901 NodeManager
3174 Jps
2366 NameNode
2527 DataNode
--------- hadoop3 ----------
2032 DataNode
2258 ResourceManager
2888 Jps
2478 NodeManager
--------- hadoop4 ----------
2149 Jps
2070 SecondaryNameNode
1945 DataNode
2854 NodeManager
3.3.3 会话模式部署
- 去bin下启动会话
[hadoop1@hadoop2 flink]$ ls bin/
bash-java-utils.jar jobmanager.sh pyflink-shell.sh stop-zookeeper-quorum.sh
config.sh kubernetes-entry.sh sql-client.sh taskmanager.sh
find-flink-home.sh kubernetes-session.sh standalone-job.sh yarn-session.sh
flink mesos-appmaster-job.sh start-cluster.sh zookeeper.sh
flink-console.sh mesos-appmaster.sh start-scala-shell.sh
flink-daemon.sh mesos-taskmanager.sh start-zookeeper-quorum.sh
historyserver.sh pyflink-gateway-server.sh stop-cluster.sh
[hadoop1@hadoop2 flink]$ ./bin/yarn-session.sh -nm test -d
- 网页

http://hadoop2:46082/ UI对应随着启动而变
- 提交参数

-n参数和-s参数表示TaskManager和slot数量,原来可以指定,到了flink1.11.0版本后,进行动态分配,避免资源设置过大造成的浪费
- 提交作业
- 将jar包打包到flink
- 执行脚本
./bin/flink run -c com.atguigu.wc.StreamWordCount ./FlinkTutorial-1.0-SNAPSHOT.jar
会出现启动running的网页

- 在hadoop2的7777端口输入一些数据
![]()
会出现结果

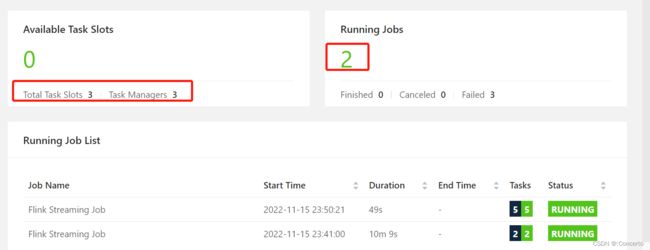
- 继续提交作业并且并行度设为2
[hadoop1@hadoop3 flink]$ ./bin/flink run -c com.atguigu.wc.StreamWordCount -p 2 ./FlinkTutorial-1.0-SNAPSHOT.jar
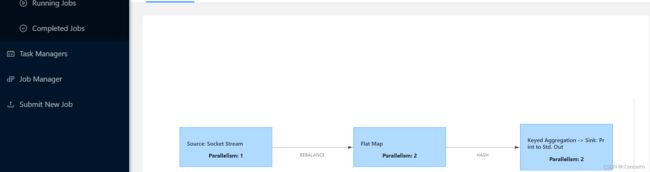
3.3.4 单作业模式部署
- 提交
yarn-per-job表示作业模式
in/flink run -d -t yarn-per-job -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT.jar
3.3.5 应用模式
- 提交
run-application表示应用模式
$ bin/flink run-application -t yarn-application -c com.atguigu.wc.StreamWordCount
FlinkTutorial-1.0-SNAPSHOT.jar