【C++】详谈explicit关键字背后的隐式类型转换和编译器优化
开场白
本来想总结一下explicit关键字的用法,结果看了官方文档发现能给拷贝构造加explicit,我就去试了试
试了之后,又发现了两个大坑:隐式类型转换和编译器优化,本来我以为我很久以前就理解了这俩概念,但是一系列实验结果表明这并不是那么简单
这两个坑折磨得我欲仙欲死
首先贴一下我们一直说的编译器优化是什么,官网的定义
编译器优化学名叫:拷贝省略
Copy elision
Omits copy and move (since C++11) constructors, resulting in zero-copy pass-by-value semantics.
The compilers are required to omit the copy and move construction of class objects
注意,本博客基于VS2019进行实验
前言
相比于C语言的32个关键字,C++98开始陆续增加了很多C++关键字使得C++的新特性越来越多
我们今天来谈谈C++98增加的explicit关键字
根据以前的理解,在单参数构造函数之前加explicit会导致我们不能使用隐式类型转换的方式去实例化对象
那么我们来看一看官方文档是怎么说的
目录
- explicit的功能
- 代码分析
1.单参、拷贝都不加explicit
2.单参构造加explicit,拷贝构造不加explicit
3.拷贝构造和单参构造都加explicit
4.总结规律 - 总结
explicit的功能
根据官方文档 https://en.cppreference.com/w/cpp/language/explicit
explicit的作用是:
Specifies that a constructor or conversion function (since C++11) or deduction guide (since C++17) is explicit, that is, it cannot be used for implicit conversions and copy-initialization.
A constructor with a single non-default parameter (until C++11) that is declared without the function specifier explicit is called a converting constructor.
意思是用explicit修饰了构造函数后,就不支持隐式的
转换和拷贝初始化
不支持隐式类型转换我可以理解,那么不支持拷贝构造是什么意思呢?
(事后来看,我英文没看懂,而且没有明白隐式类型转换的真正含义。)
这句话的真正意思是:explicit关键字能让构造函数不可被隐式地调用, implicit conversions指的是隐式地用单个参数构造一个对象,copy-initialization指的是隐式地调用拷贝构造,用一个对象构造另一个对象
也就是说这两种构造对象的隐式调用都能被explicit禁!
但事情远没这么简单
代码研究
我们简单模拟了一个my_string的类,给了`单参构造和拷贝构造`class my_string {
public:
my_string(const char* str) {
size_t len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str, len + 1);
_size = _capacity = len;
}
my_string(const my_string& str) {
size_t len = strlen(str._str);
_str = new char[len + 1];
memcpy(_str, str._str, len + 1);
_size = _capacity = len;
private:
size_t _size;
size_t _capacity;
char* _str;
};
0.显示调用
在研究隐式调用之前首先明确一下什么是显示调用构造函数
my_string s2("abc"); //显示调用单参构造
my_string s3(s2); //显式调用拷贝构造
1.单参、拷贝都不加explicit
我们一般这样来初始化一个my_string对象:
类名 + 对象名(一个参数);
my_string s1("abc");
这样初始化毫无疑问,是按照单参构造函数来走的显式的初始化
但是我们还可以通过隐式类型转换进行初始化:
类名 + 对象名 = 一个参数;
my_string s2 = "abc";
可能我们会觉得,将一个char* 类型变量赋值给一个my_string类型变量很荒谬,但是,编译器做了隐式类型的转换,使得上面2种初始化是等价的,具体如下:
❗❗❗编译器会用"abc"调用构造函数先
构造一个临时的my_string对象,这个临时对象是无名对象;接着用这个临时对象去拷贝构造s2。
编译通过,但是,调试过程中,很奇怪的是:没有看见构造临时对象,也没有接下来的调用拷贝构造,而是直接去拿"abc"去构造s2

❗❗❗❗❗原因是,此时,编译器又回去做一个优化:编译器会避免这个临时对象的
构造过程及拷贝构造过程而直接用"abc"去(偷偷摸摸地)隐式地调用构造函数构造s2对象
所以说,
临时变量的创建的过程是隐式类型转换的过程,假如禁掉了单参数构造函数的隐式类型转换,临时变量就无法得以创建
而,
编译器优化之后的拿"abc"直接构造s2也是隐式类型转换的过程,假如禁掉了单参数构造函数的隐式类型转换,s2也同样无法得以创建
隐式调用构造函数有2种情形:(重申:构造函数包括单参构造与拷贝构造)
- 情景一
my_string s1 = "abc";
❗❗❗编译器会先隐式调用单参构造函数构造一个临时的my_string对象用以存储"abc",接着用这个临时对象去
拷贝构造s2。
这里的隐式调用是:单参构造+拷贝构造
- 情景二
my_string s2 = my_string("abc");
❗❗❗由于my_string(“abc”)是一个匿名对象,编译器会先隐式调用拷贝构造函数构造一个临时对象用以存储匿名对象,接着用这个临时对象去
拷贝构造s2。
那如何禁掉呢?
好,那我们分别给单参构造和拷贝构造加上explicit关键字看一下
2.单参构造加explicit,拷贝构造不加explicit
此时,单参构造的隐式调用被禁了
class my_string {
public:
explicit my_string(const char* str) {
size_t len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str, len + 1);
_size = _capacity = len;
}
my_string(const my_string& str) {
size_t len = strlen(str._str);
_str = new char[len + 1];
memcpy(_str, str._str, len + 1);
_size = _capacity = len;
}
private:
size_t _size;
size_t _capacity;
char* _str;
};
- 情景一
my_string s1 = "abc";
❗❗❗编译器会先隐式调用单参构造函数构造一个临时的my_string对象用以存储"abc",接着用这个临时对象去
拷贝构造s2。
这里的隐式调用是:单参构造+拷贝构造
由于单参构造的隐式调用被禁了,此时编译不通过
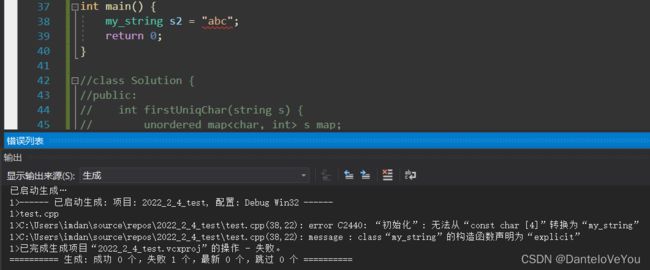
- 情景二
my_string s2 = my_string("abc");
❗❗❗由于my_string(“abc”)是一个匿名对象,编译器会先隐式调用
拷贝构造函数构造一个临时对象用以存储匿名对象,接着用这个临时对象去拷贝构造s2。
这里的隐式调用是:拷贝构造+拷贝构造
由于我们只禁了单参构造的隐式调用,没禁拷贝构造的隐式调用,此时编译通过

- 疑点1
但是奇怪的是,调试了一下,编译器的优化使的我们又将2次的拷贝构造变成了一次的构造:
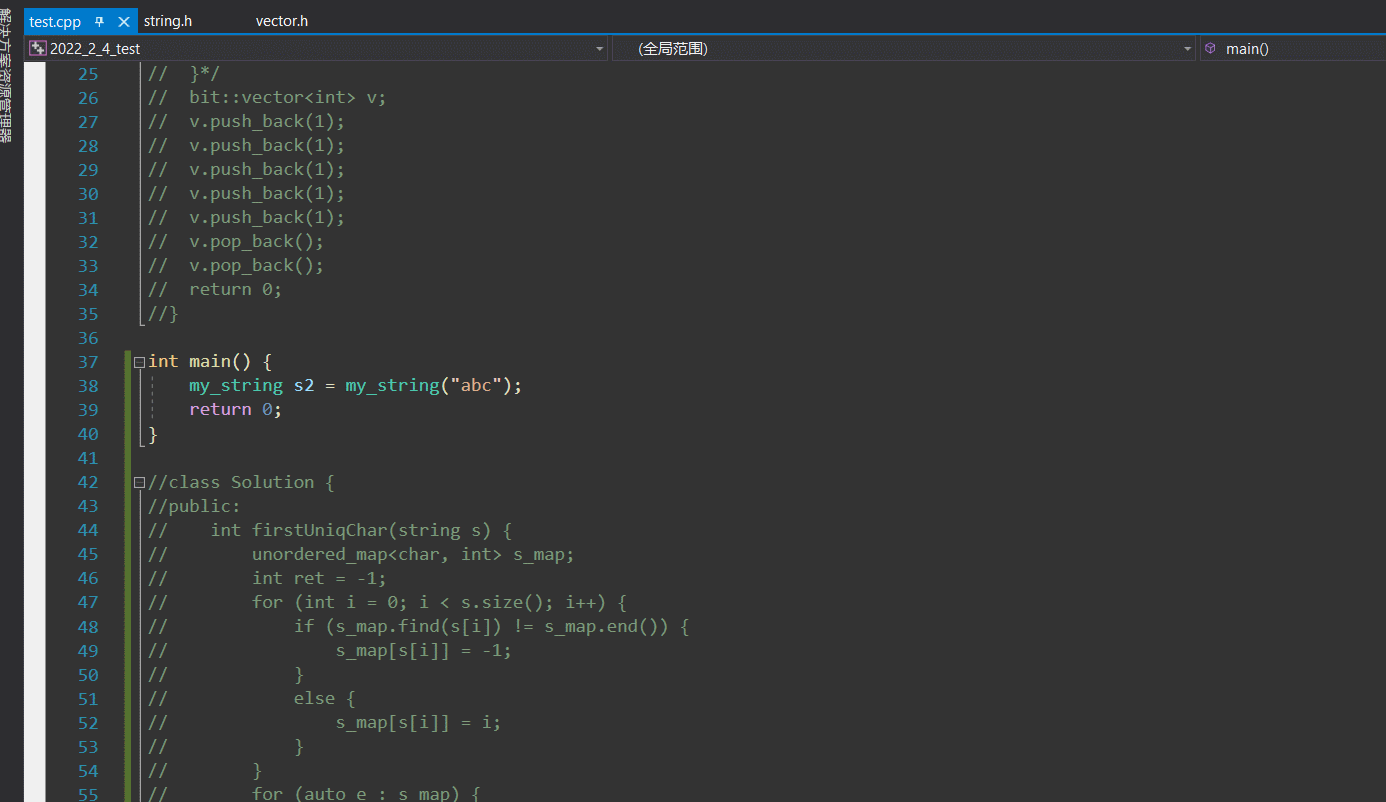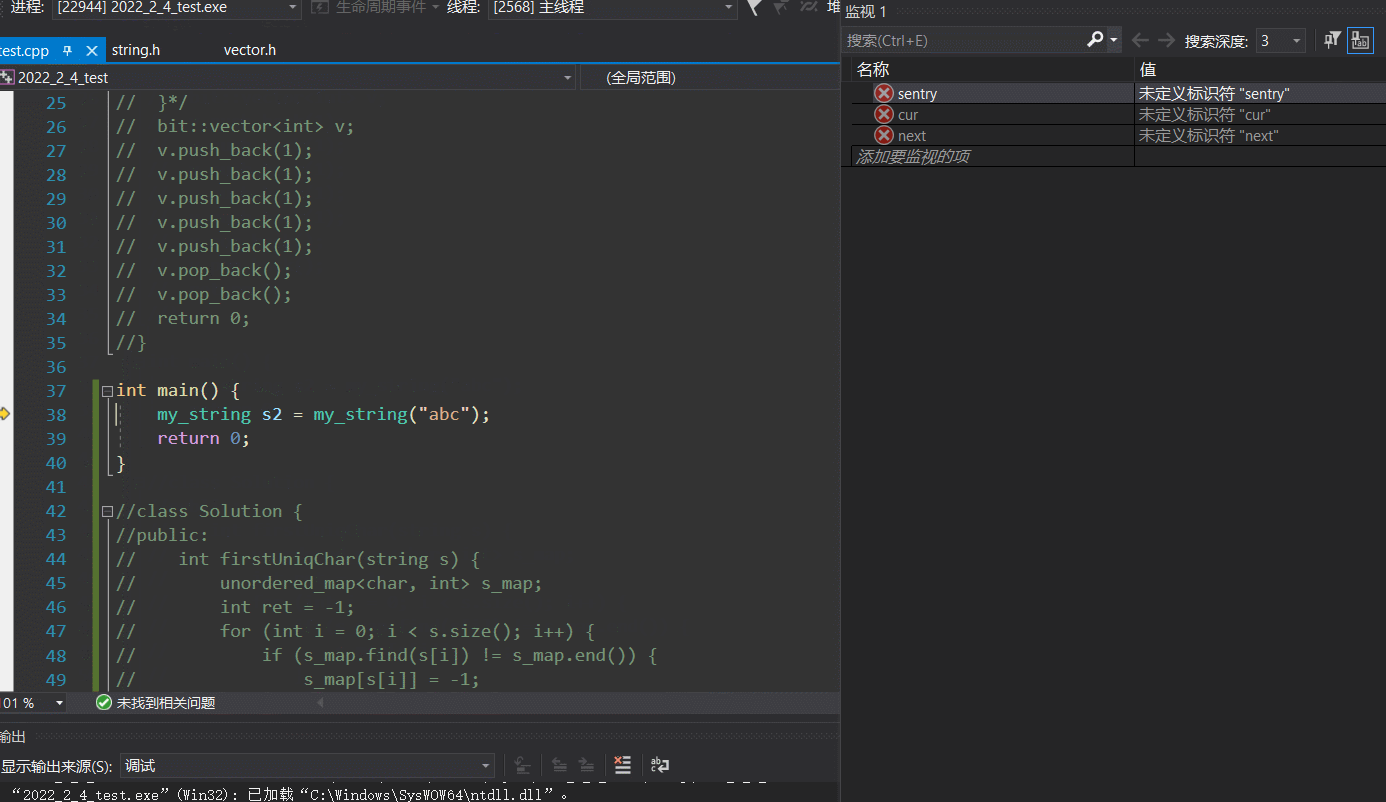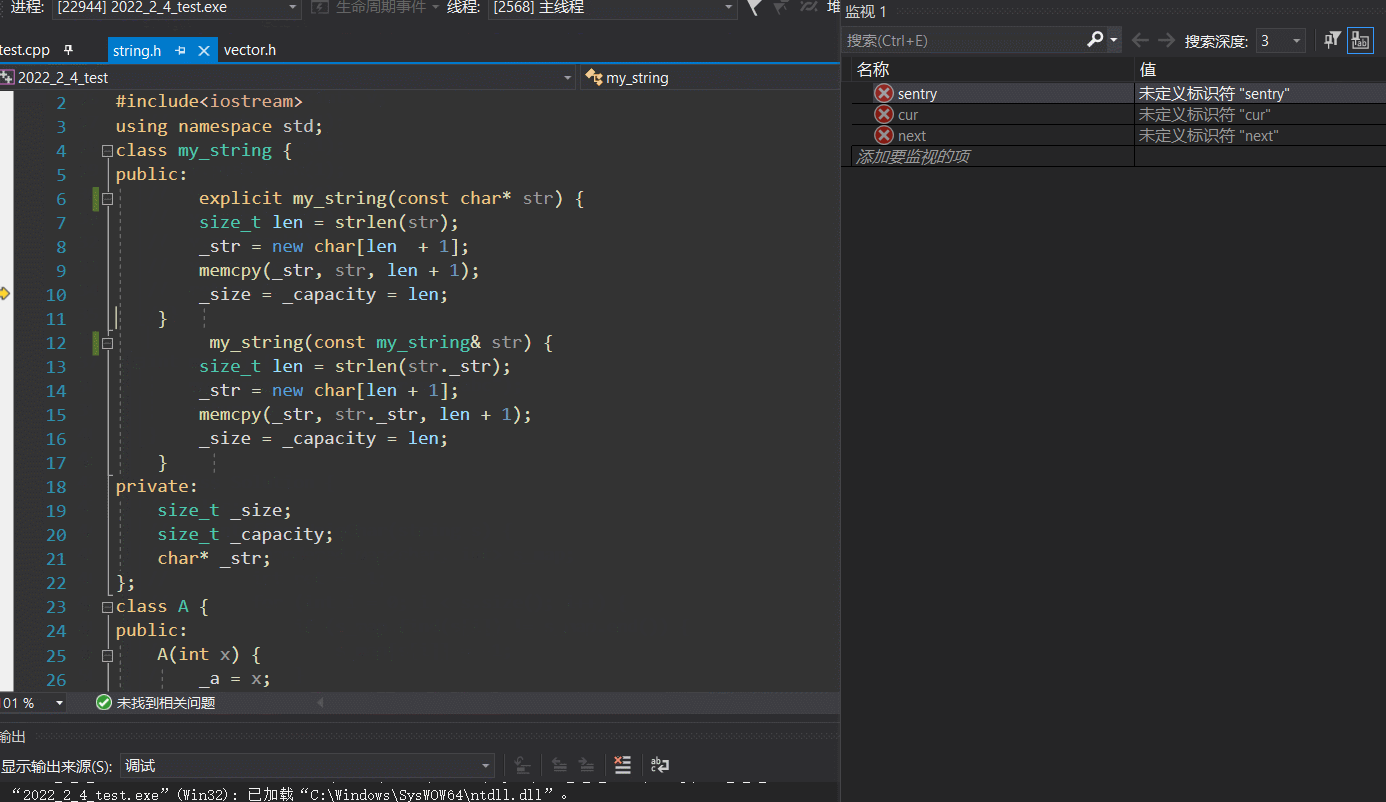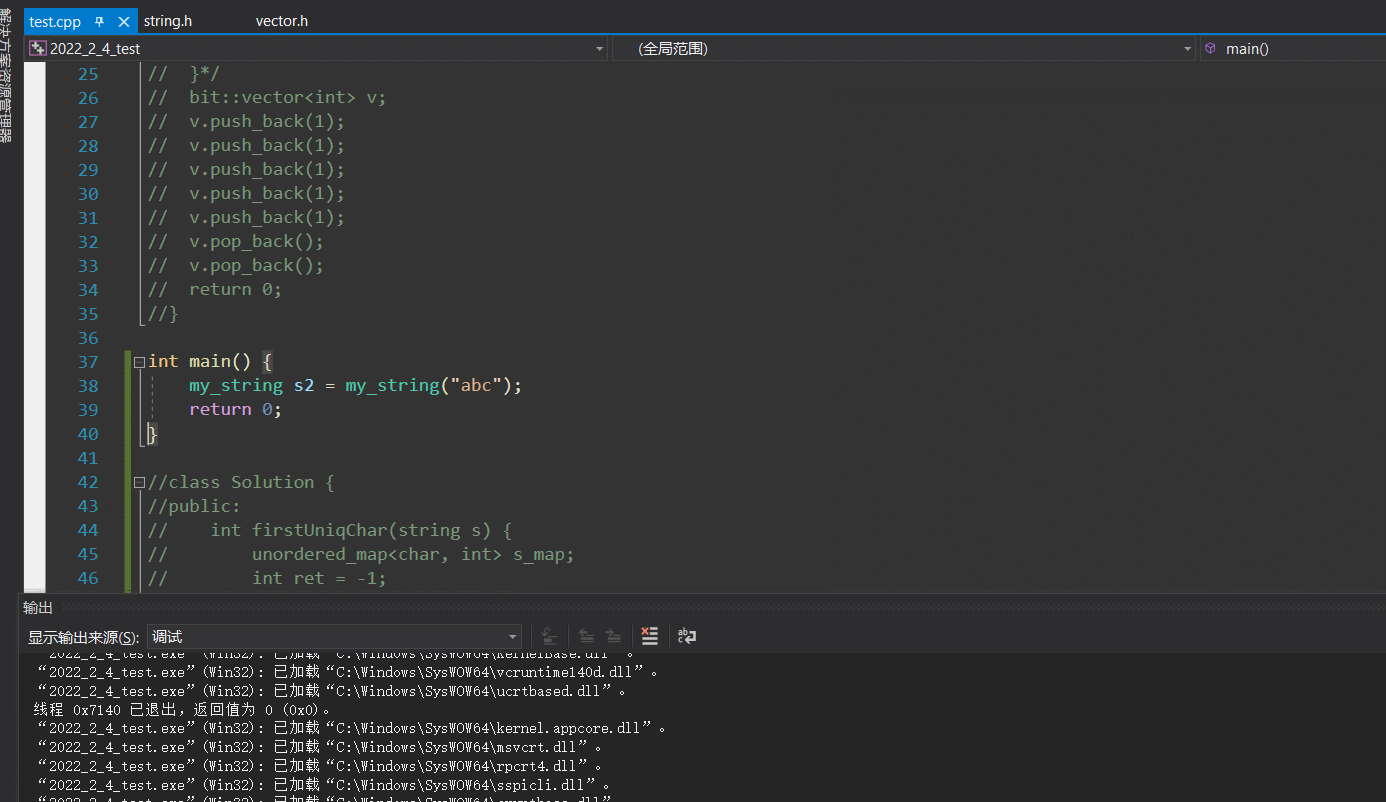
但明明我们禁了单参构造的隐式调用啊,而编译通过佐证了此过程不考虑优化的确是不去调单参构造的,确实加了explicit也不能去调单参构造,可是调试出来怎么看上去就是去调了单参构造呢???
在这种情形下,编译器的优化反而推翻了结论
2.拷贝构造加explicit,单参构造不加explicit
class my_string {
public:
my_string(const char* str) {
size_t len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str, len + 1);
_size = _capacity = len;
}
explicit my_string(const my_string& str) {
size_t len = strlen(str._str);
_str = new char[len + 1];
memcpy(_str, str._str, len + 1);
_size = _capacity = len;
}
private:
size_t _size;
size_t _capacity;
char* _str;
};
- 情景一
my_string s1 = "abc";
❗❗❗编译器会先隐式调用单参构造函数构造一个临时的my_string对象用以存储"abc",接着用这个临时对象去
拷贝构造s2。
这里的隐式调用是:单参构造+拷贝构造
如果不考虑编译器优化,第二步的拷贝构造的隐式调用应该会失败
事实是:编译成功

这时候,在编译器的优化下,单参构造+拷贝构造两步被优化成了单参构造,所以不会去调拷贝构造,我们禁了拷贝构造也没事。
在这种情形下,编译器的优化又能够解释清楚问题了
- 情景二
my_string s2 = my_string("abc");
❗❗❗由于my_string(“abc”)是一个匿名对象,编译器会先隐式调用
拷贝构造函数构造一个临时对象用以存储匿名对象,接着用这个临时对象去拷贝构造s2。
这里的隐式调用是:拷贝构造+拷贝构造
结果是编译不通过。
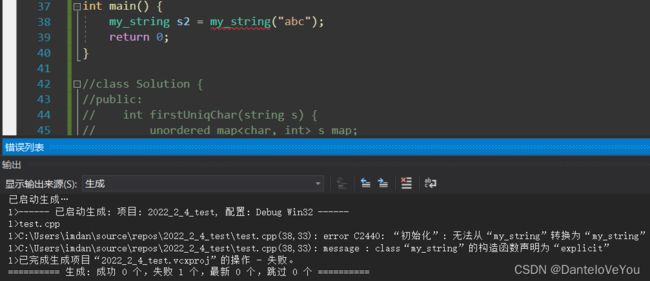
如果考虑编译器的优化,两次拷贝构造将被优化成为一步单参构造,应该能成功才对啊
3.拷贝构造和单参构造都加explicit
class my_string {
public:
explicit my_string(const char* str) {
size_t len = strlen(str);
_str = new char[len + 1];
memcpy(_str, str, len + 1);
_size = _capacity = len;
}
explicit my_string(const my_string& str) {
size_t len = strlen(str._str);
_str = new char[len + 1];
memcpy(_str, str._str, len + 1);
_size = _capacity = len;
}
private:
size_t _size;
size_t _capacity;
char* _str;
};
- 情景一
my_string s1 = "abc";
❗❗❗编译器会先隐式调用单参构造函数构造一个临时的my_string对象用以存储"abc",接着用这个临时对象去
拷贝构造s2。
这里的隐式调用是:单参构造+拷贝构造
结果编译成功
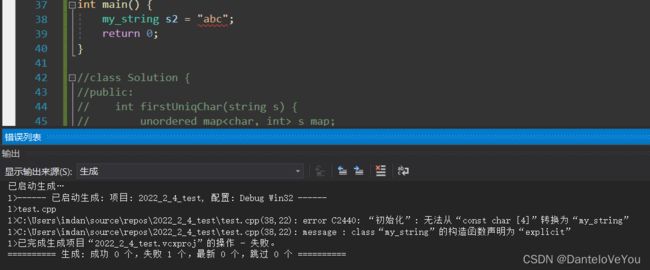
如果考虑编译器优化,单参构造+拷贝构造变为一步单参构造,也会失败
- 情景二
my_string s2 = my_string("abc");
❗❗❗由于my_string(“abc”)是一个匿名对象,编译器会先隐式调用
拷贝构造函数构造一个临时对象用以存储匿名对象,接着用这个临时对象去拷贝构造s2。
这里的隐式调用是:拷贝构造+拷贝构造
编译失败:
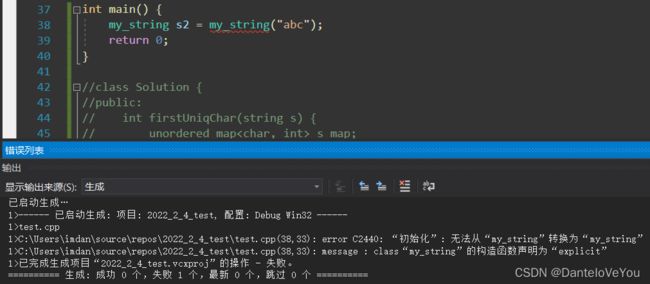
如果考虑编译器优化,两次拷贝构造变为一步单参构造,也会失败
4.总结规律
我们一共测试了加/不加explicit三种大情况6个情景
- 情景一
my_string s1 = "abc";
- 情景二
my_string s2 = my_string("abc");
红色表示可以用来解释编译结果的理由
| 编译器优化与否 | 单参加,拷贝不加 | 单参不加,拷贝加 | 单参拷贝全加 |
|---|---|---|---|
| 情景一不优化 | 单参构造 +拷贝 | 单参构造+拷贝 | 单参构造+拷贝 |
| 情景一优化 | 单参构造 | 单参构造 | 单参构造 |
| 情景二不优化 | 拷贝+拷贝 | 拷贝+拷贝 | 拷贝加拷贝 |
| 情景二优化 | 单参构造 | 单参构造 | 单参构造 |

可以看到,编译结果全都可以被解释
- 绿框里的只能用优化了的理由进行解释,用没优化的解释是矛盾的
- 蓝框里的只能用没优化的理由进行解释,用优化了的解释是矛盾的
- 而紫框里的都能解释
我做出以下猜想:
编译器在判定是否优化的时候,会这样想:
一、
哎呀,这小子没优化和优化结果是一样的。如果结果是能过编译的话就给他优化一下吧,不能过的话,那就不能过了呗(
解释了上图1、3、6)
二、
因为没有优化的步骤都是两步走,编译器会先看没优化的第一步:
哎呀,这小子没优化的第一步都过不了编译,不看了,不去给他优化了,编译不过就不过
这样就能解释为什么单参不加拷贝加的那种情况不去通过优化来过编译,因为编译器会先去看没优化的第一步能不能过编译解释了上图5
三、
哎呀,小子,你没优化的第二步过不了编译啊。嗯?没优化的第一步能够,而且优化了也就能过
如果没优化的第一步能过编译,那么纵使你没优化的第二步不能过编译,但是优化了能过编译,编译器就会看在第一步能过的份上给你去用优化过编译(解释了上图2)
三、
没优化的第一第二步都能够过编译,那么好了,即使你优化了是反而过不了编译,你当然还是能凭借没优化的去过,但是我调试的时候还是骗你一下:我优化了
解释了上图4
总结
所以说我们所谓的“隐式”二字,意思就是编译器去偷偷调用的意思也就是编译器去偷袭

而explicit就好比是一个保镖,专门防偷袭
但是呢,又因为存在了编译器优化这把神器,我们想要达到构造目的,不一定要去偷袭了,而是可以换条路走
那么编译器优化的规律便是:
不优化情况下的第一步构造是否被explicit挡掉了!
挡掉了,即使优化了能过,还是编译失败
没挡掉,只要优化了能过或是没优化的第二步也能过,就可以编译成功
编译器的优化能够减少拷贝构造,故它的学名叫copy elision而是单纯地调用一次构造即可
而判断能否去优化之前还得按照老规矩走上一步,看看没优化的第一步能不能过
对了,还学了个新单词,赚了
