在虚拟机中搭建高可用集群,超详解,保姆级教学
配置hadoop环境看我这篇博客
CSDN
关于zookeeper搭建看我这篇博客。包括呢单机集群
CSDN
先确定你的高可用集群分布表
我的是,一定要记住自己的到时候配置xml的时候要对照自己的来
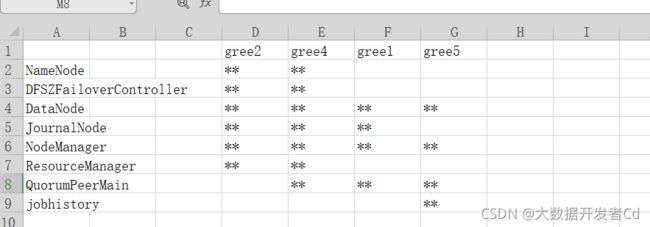
接着启动虚拟机开始搭建,准备4台虚拟机

首先进入
[root@gree2 soft]# cd ./hadoop260/etc/hadoop
开始配置xml和jdk环境变量
首先修改下面三个里面的Java变量
[root@gree2 hadoop]# vi ./hadoop-env.sh 在25行
[root@gree2 hadoop]# vi ./mapred-env.sh 在16行前面的#删掉
[root@gree2 hadoop]# vi ./yarn-env.sh 在23行#删掉
带有如下行的吧后面的路径改为jdk安装目录路径
export JAVA_HOME=/opt/soft/jdk180
举例[root@gree2 hadoop]# vi ./hadoop-env.sh里面的java_home路径。其他2个一样

接着配置
[root@gree2 hadoop]# vi ./core-site.xml
fs.defaultFS
hdfs://mycluser/
hadoop.tmp.dir
/opt/soft/hadoop260/hadooptmp/
ha.zookeeper.quorum
gree4:2181,gree1:2181,gree5:2181
hadoop.proxyuser.bigdata.hosts
*
hadoop.proxyuser.bigdata.groups
*

然后配置[root@gree2 hadoop]# vi ./hdfs-site.xml
dfs.replication
3
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
gree2:9000
dfs.namenode.http-address.mycluster.nn1
gree2:50070
dfs.namenode.rpc-address.mycluster.nn2
gree4:9000
dfs.namenode.http-address.mycluster.nn2
gree4:50070
dfs.journalnode.edits.dir
/opt/soft/hadoop260/journaldata
dfs.namenode.shared.edits.dir
qjournal://gree2:8485;gree4:8485;gree1:8485/mycluster
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.conect-timeout
30000
dfs.webhdfs.endbled
true

复制一份方便使用
[root@gree2 hadoop]# mv mapred-site.xml.template mapred-site.xml
配置
[root@gree2 hadoop]# vi ./mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
gree5:10020
mapreduce.jobhistory.webapp.address
gree5:19888
最后配置[root@gree2 hadoop]# vi ./yarn-site.xml
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
gree2
yarn.resourcemanager.hostname.rm2
gree4
yarn.resourcemanager.zk-address
gree4:2181,gree1:2181,gree5:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore

添加gree,将localhost改为你的本机名
[root@gree2 hadoop]# vi ./slaves 将localhost改为所有集群别名

在[root@gree2 hadoop]# cd /usr/bin,下编写三个脚本,方便直接
将写好的xml发给其他虚拟机,在bin目录下写是为了这种脚本可以在所有目录下都能用
第一个脚本xsync。进行循环拷贝
[root@gree2 bin]# vi ./xsync
#!/bin/bash
argCount=$#
if [ $argCount == 0 ]; then
echo 'no args'
exit 0
fi
# 获取文件名称
f=$1
fname=`basename $f`
echo $fname
# 获取文件的绝对路径
pdir=`cd -P $(dirname $f ); pwd`
echo $pdir
# 获取当前用户
user=`whoami`
echo $user
# 循环拷贝
for host in gree4 gree5 gree1 //这边代表运行这文件后循环拷贝到的集群
do
echo "------$host------"
rsync -av $pdir/$fname $user@$host:$pdir
done
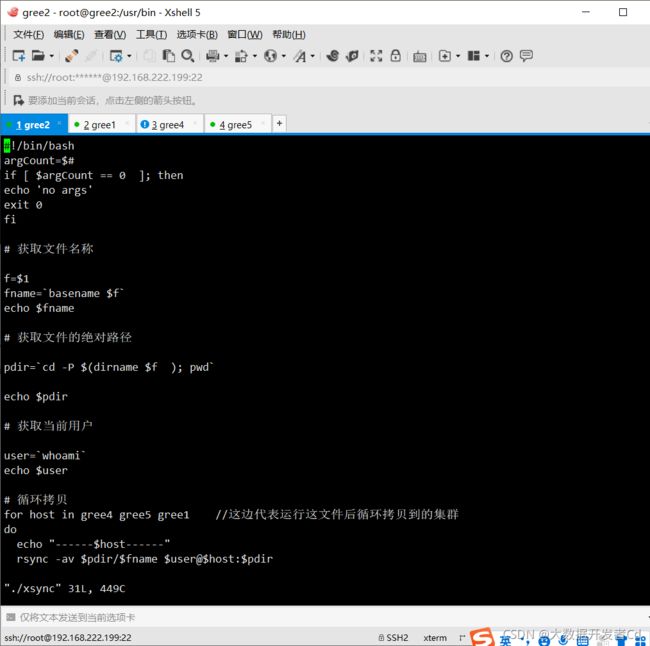
第二个脚本方便通过一台虚拟机进行查询启动操作
#!/bin/bash
for host in gree1 gree4 gree2 gree5
do
echo "**** $host 指令信息 ****"
ssh $host "source /etc/profile;$*"
done
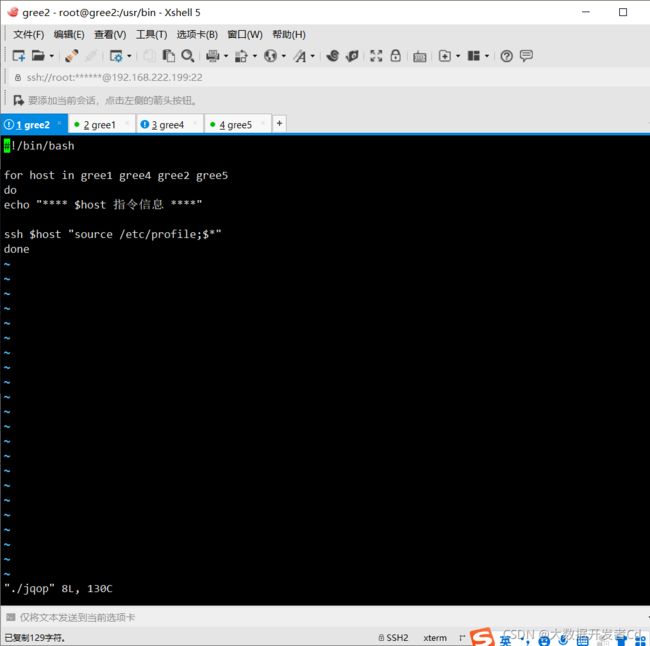
第三个脚本
[root@gree2 bin]# vi ./zkop
为了启动集群,查看集群状态
#!/bin/bash
for host in gree4 gree1 gree5
do
case $1 in
"start"){
echo "---------------$host zookeeper start-----------------"
ssh $host "source /etc/profile;zkServer.sh start"
};;
"stop"){
echo "---------------$host zookeeper stop-----------------"
ssh $host "source /etc/profile;zkServer.sh stop"
};;
"status"){
echo "---------------$host zookeeper status-----------------"
ssh $host "source /etc/profile;zkServer.sh status"
};;
esac
done

写完之后给脚本赋予权限
[root@gree6 bin]# chmod 777 xsync
[root@gree6 bin]# chmod 777 zkop
[root@gree6 bin]# chmod 777 jqop
回到soft目录下
运行脚本进行循环拷贝
运行脚本进行循环拷贝,会给三台虚拟机拷贝,如果不是说明脚本写的不对,没有对应
[root@gree2 soft]# xsync ./hadoop260/
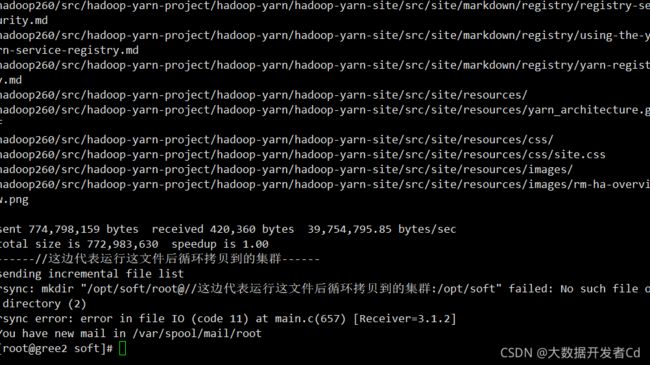
拷贝完之后将hadoop环境配置好
[root@gree2 hadoop]# vi /etc/profile

并且将改好的profile也发给其他虚拟机
[root@gree2 hadoop]# xsync /etc/profilexs

你的每台虚拟机soft下都有呢

第一次启动集群服务
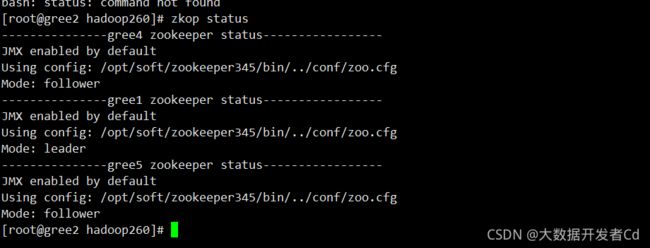
[root@gree2 soft]# zkop start
[root@gree2 soft]# zkop status
表示成功
2. 启动journalnode
[root@gree2 soft]# hadoop-daemon.sh start journalnode
[root@gree2 soft]# ssh gree4 "source /etc/profile; hadoop-daemon.sh start journalnode"
[root@gree2 soft]# ssh gree1 "source /etc/profile; hadoop-daemon.sh start journalnode"
将gree2格式化后的hadooptmp文件同步到gree4
[root@gree2 soft]# hadoop namenode -format
[root@gree2 hadoop260]# scp -r ./hadooptmp/ root@gree4:/opt/soft/hadoop260/
4.初始化zookeeper
[root@gree2 hadoop260]# hdfs zkfc -formatZK
5.启动HDFS
[root@gree2 hadoop260]# start-dfs.sh
6.启动yarn
[root@gree6 hadoop260]# start-yarn.sh
[root@gree6 hadoop260]# jqop jps

表示最终成功呢