python爬虫详细实例总结
1robots协议
隐匿身份:高匿商业代理–TOR(洋葱路由)
2.爬虫的分类:通用爬虫–定向爬虫
3.爬虫程序的一般步骤
URL -- Universal Resource Locator
URI -- Universal Resource Identifier
URI = URL + URN
协议://用户名:口令@域名或IP地址:端口/路径1/路径2/资源名称
HTTP / HTTPS -- 超文本传输协议
HTTP请求 --> 服务器
请求行 - 命令(GET/POST) 资源路径 协议版本
请求头 - 键值对
空行
消息体 - 发给服务的数据
HTTP响应 <-- 服务器
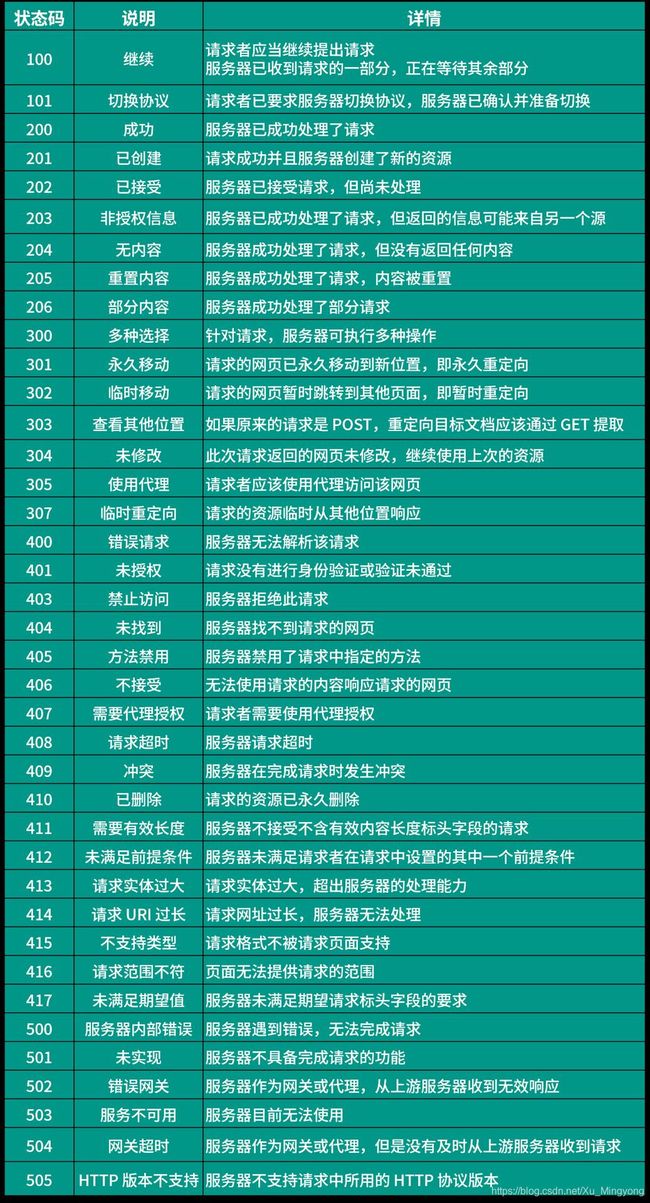
响应行 - 协议版本 响应状态码
响应头 - 键值对
- content-type:MIME
- textml
- application/json
- text/xml
- applicationf
- image/jpeg
- image/png
空行
消息体 - 服务器返回的数据
1)抓取页面
urllib - python原生库(难用)
requests - 第三方库
- get() / post() -->Response -->text/content/json()
- Session -->get() / post() (高级用法)
aiohttp / httpx
import requests
session = requests.Session()
# session.verify = False
session.headers.update(
{
'User-Agent': ''
}
)
res = session.get('https://movie.douban.com/top250')
# print(res.status_code) # 状态码
# print(res.content) # 内容
2)解析页面
正则表达式 --> re
CSS选择器解析 --> beautifulsoup4 / pyquery
XPath解析 --> 标签语言的查询语法 --> lxml
3)数据持久化
CSV --> csv --> writer() --> csvwriter --> writerow/writerows
Excel --> openpyxl --> Workbook() --> Worksheet --> add_sheet --> cell --> save()
数据库
-关系型数据库 --> MySQL / Oracle / SQLServer / DB2 / PostgreSQL
-NoSQL / NewSQL数据库
分布式文件系统 --> Hadoop --> HDFS + MapReduce / Spark --> Java / Scala / Python --> Hive --> SQL
- GFS --> Google File System
- TFS --> Taobap File System
- TFS --> Tencent File System
实例1
import re
import openpyxl
import requests
from openpyxl.cell import Cell
from openpyxl.styles import Font, Alignment
session = requests.Session()
# session.verify = False
session.headers.update(
{
'User-Agent': ''
}
)
res = session.get('https://www.sohu.com')
# pattern = re.compile(r'')
pattern = re.compile(r'.*?)".*?title="(?P.*?)".*?>' )
# 其中?P<名字> 给分组命名
# finditer方法会返回一个迭代器对象
iter_obj = pattern.finditer(res.text)
# 创建一个工作簿
wb = openpyxl.Workbook()
# 获取第一个工作表
sheet = wb.active
sheet.title = '搜狐新闻'
# 修改表头单元格的宽度和高度
sheet.row_dimensions[1].height = 35
sheet.column_dimensions['A'].width = 80
sheet.column_dimensions['B'].width = 120
# 向单元格写入数据
sheet.cell(1, 1, '标题')
sheet.cell(1, 2, '链接')
# 修改指定单元格的样式
font = Font(size=18, name='华文楷体', bold=True, color='ff0000')
alignment = Alignment(horizontal='center', vertical='center')
for col_index in 'AB':
curr_cell = sheet[f'{col_index}1'] # type: Cell
curr_cell.font = font
curr_cell.alignment = alignment
# 通过对迭代器对象的循环遍历可以获得Match对象
for index, matcher in enumerate(iter_obj):
# # 获取整个a标签
# print(matcher.group())
# # 获取捕获组的内容
# print(matcher.group('bar'))
# print(matcher.group('foo'))
sheet.cell(index + 2, 1, matcher.group('bar'))
sheet.cell(index + 2, 2, matcher.group('foo'))
# 保存工作簿
wb.save('files/爬虫数据文件.xlsx')
# 通过对迭代器对象的循环遍历可以获得Match对象
# for matcher in iter_obj:
# # 获取整个a标签
# print(matcher.group())
# # 获取捕获组的内容
# print(matcher.group(1))
# print(matcher.group(2))
# #根据正则表达式匹配a标签的href和title属性得到一个列表
# anchors_list = pattern.findall(res.text)
# for href, title in anchors_list:
# print(href)
# print(title)
4.HTML页面的结构
超文本标签语言 -- 所有的内容都放在标签下
- 标签:承载内容
- CSS(Cascading Style Sheet):页面渲染
选择器 --> 样式属性名:样式属性值
- 标签选择器
- 类选择器
- ID选择器
- 父子选择器:div>p
- 后代选择器:div p
- 兄弟选择器:div - p
- 相邻兄弟选择器:div + p
- 伪类/伪元素:a:visited / p:first-letter
- JavaScript(JS):交互式行为
5.解析页面的三种方式
正则表达式解析 --> re
- 直接调用re模块的函数
- search --> Match
- findall --> list[str]
- finditer --> iterator --> Match --> group()
- 创建Pattern对象,给对象发消息
- compile --> Pattern
- search --> Match --> group()
- findall / finditer
# CSS选择器解析
- BeautifulSoup --> beautifulsoup4 --> bs4
- PyQuery --> pip install pyquery --> 有jQuery使用经验
# XPath解析
# -lxml --> pip install lxml
6.数据持久化
# CSV文件
# Excel文件
# 数据库
# 大数据平台
实例2
from selenium.webdriver import Chrome, ChromeOptions
# 1.创建谷歌浏览器的配置对象
options = ChromeOptions()
# 1)添加取消测试环境选项
options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 2)取消图片加载
# options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
browser = Chrome(options=options)
# 破解selenium反爬的重要代码
# 防止selenium被监测
# 先修改js,再加载js
browser.execute_cdp_cmd(
"Page.addScriptToEvaluateOnNewDocument",
{
"source": "Object.defineProperty(navigator, 'webdriver', {get: () => undefined})"
}
)
browser.get('https://www.baidu.com')
browser.implicitly_wait(10)
anchor = browser.find_element_by_css_selector('#s-top-left > a:nth-child(7)')
# 通过WebElement对象的is_displayed方法判定元素是否可见
# 注意:不可见的超链接一般都不能访问,因为它极有可能是一个诱使爬虫访问的蜜罐链接
print(anchor.is_displayed())
# 该标签的尺寸
print(anchor.size)
# 该标签在当前页面的位置
print(anchor.location)
# 浏览器窗口截图
browser.get_screenshot_as_file('files/baidu.png')
光学文字识别
import easyocr
reader = easyocr.Reader(['ch_sim', 'en'], gpu=False)
print(reader.readtext('files/idcard.jpg', detail=0))
从页面上抠图
from PIL import Image as img
from PIL import ImageFilter
from PIL.Image import Image
image = img.open('files/idcard.jpg') # type: Image
print(image.size)
# 使用滤镜处理图片
emboss_image = image.filter(ImageFilter.EMBOSS)
emboss_image.show()
# 抠图
head = image.crop((320, 50, 460, 235))
# # 显示图片
head.show()
# 保存图片
# head.save('files/head.jpg')
7.常见的反爬方式及破解
请求头检查
- User-Agent
- Referer --> 网站防盗链接
- Accept
- Accept-Language
- Accept-Encoding
限速和封禁IP
- 商业IP代理 --> 蘑菇代理 / 芝麻代理 / 快代理 / 阿布云代理
- 代理池(提前放置好一堆代理,有对应的维护机制,能够动态替换掉失效代理)
身份验证
- 服务器如何识别你是否登录?
- 从请求中获取用户的身份标识
- 对于登录成功的用户,服务器通常会将用户身份标识写入浏览器本地存储
- Cookie
- localStorage / sessionStorage
- IndexedDB
--> 下次请求要带上自己的身份标识(修改请求头、修改Cookie信息)
- Cookie池(提前准备好多个登录用户的身份信息,轮换着使用)
动态内容
- 抓取接口
- 浏览器开发者工具 --> Network --> Fetch/XHR(异步请求)
- 专业(HTTP)抓包工具
- Charles / Fiddler --> 将它设置为浏览器的代理
- WireShark --> Ethereal --> 协议分析工具
- Selenium WebDriver --> 用代码驱动浏览器
- Puppeteer --> Pyppeteer --> Chromium
爬虫蜜罐
- Selenium --> WebElement --> is_displayed()
验证码
CAPTCHA --> 图灵测试
OCR --> Optical Character Recognition
teseract --> pytesseract
- easyocr
- 打码平台
字体反爬
JS加密和混淆
8.加速爬取的方式
并发编程
- 多线程
- Thread(target=..., args=(...,...)) --> start()
- 继承Thread,重写run()方法 --> 创建自定义类的对象 --> start()
- ThreadPoolExecutor() --> submit(fn,...) / map(fn,[...])
- 多进程
- Prcoess(target=..., args=(...,...)) --> start()
- 继承Thread,重写run()方法 --> 创建自定义类的对象 --> start()
- ThreadPoolExecutor() --> submit(fn,...) / map(fn,[...])
- 异步编程(异步IO)
- I/O密集型任务 --> 大量的操作都是输入输出的操作,需要CPU运算很少
- 计算密集型任务 --> 大量的操作都是需要CPU做运算,I/O中断很少发生
官方的CPython因为是用C语言实现的Python解释器,因为C语言底层申请和释放内存的操作
并不是线程安全的,所有在Python解释器中引入了GIL(全局解释器锁)。因为GIL的存在,
CPython中的多线程并不能够发挥CPU多核的优势。在处理计算密集型任务时,应该考虑使用
多进程,因为每个进程都有自己的GIL,每个进程可以在不同的核上运转起来,这样才能发挥
CPU多核特性的优势。
分布式爬虫
一台机器必然有能力的极限,为了突破这个极限,我们可以选择将单机结构变成一个多机结构,这个多机结构就是一个分布式系统
如何协调多个机器的行为,让他们可以互相协作,共同完成一个目标?
数据中转站
要点:一般会通过部署Redis数据库(KV数据库),通过这个数据库保存待爬取的页面、
爬取过的页面、有可能还要保存一些数据,这样多个运行爬虫程序的计算机,就可能彼此
协调行为,最终达成一个共同的目标。
9.爬虫框架的应用
框架 ---> 把项目开发中常用功能和样板代码全部都封装好了,你可以专注于核心问题,
而不要再次编写重复的样板代码,重复的去实现之前已经实现过无数次的功能。
~ Scrapy ---> 命令行工具 ---> 创建爬虫项目
- 安装:pip install scrapy
- 创建Scrapy项目:scrapy startproject demo
- 创建一个蜘蛛:scrapy genspider douban movie.douban.com
- 编写蜘蛛代码:
class DoubanSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
sel = Selector(response)
movie_items = sel.css('#content > div > div.article > ol > li')
for movie_sel in movie_items:
item = MovieItem()
item['title'] = movie_sel.css('.title::text').extract_first()
item['score'] = movie_sel.css('.rating_num::text').extract_first()
item['motto'] = movie_sel.css('.inq::text').extract_first()
yield item
- 修改配置文件:
- USER-AGENT
- DOWNLOAD_DELAY
- CONCURRENT_REQUESTS
- 运行一个蜘蛛:scrapy crawl douban
~ scrapy crawl douban -o douban.csv
~ scrapy crawl douban -o douban.json
~ PySpider