Jenkins实践——创建Pipeline的两种方式
点击蓝字关注我们
近期使用Jenkins帮业务团队搭建过一次Pipline,并将测试流程加入到了Pipline中,将搭建过程的做了简单记录。考虑到项目的保密性,该文章仅演示搭建步骤和工具使用,文中的代码均为伪代码

JenkinsPipeline简介与安装
1
了解Jenkins的人相信对pipeline都有所耳闻,pipeline是Jenkins2.0推出的一套Groovy DSL语法,将原本独立运行于多个Job或者多个节点的任务统一使用代码的形式进行管理和维护。
2
推荐使用docker镜像的方式安装Jenkinspipeline,因为Jenkins是用java编写的,需要安装java环境,配置环境变量等这些操作,有时候可能还会遇到jdk版本不兼容的问题。为了不让繁琐的安装过程浇灭我们的学习热忱,还是推荐用docker镜像的方式部署,安装步骤非常简单:
1
拉取JenkinsOcean镜像
docker pull jenkinsci/blueocean2
创建挂载目录
mkdir /var/jenkins_home3
启动Jenkins
docker run -d -p 8888:8080 -p 50000:50000 -v jenkins:/var/jenkins_home –v /etc/localtime:/etc/localtime --name jenkinsci-blueocean -d jenkinsci/blueocean如果你是使用以上步骤安装Jenkins,登录之后在页面的左侧导航栏就能看到如下所示的图标:
如果你已经安装了Jenkins普通版本,可以在【Manage Jenkins】——【ManagePlugins】中搜索BlueOcean安装,安装完之后同样在主界面做侧导航栏可以看到上图中的图标。
安装完成,我们就开始进入主题,使用两种不同的方式创建Pipeline。
经典模式下创建Pipeline
创建pipeline一共两种方式,第一种方式我们称之为传统方式,是使用Jenkins经典界面,通过自己编写PipelineScript来组织流水步骤的。下面用图示的方式简单介绍一下这种方式。
1.登录Jenkins,点击左侧的新建,创建新的构建任务。
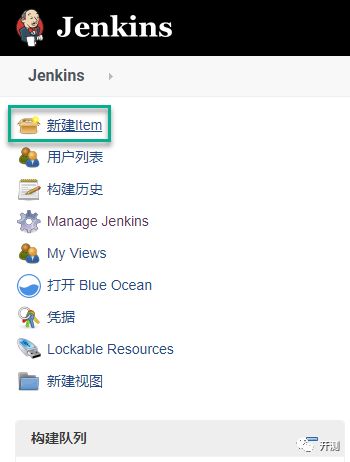
2.跳转到如下界面,输入自己的任务名称和描述信息之后,选择“流水线”选项并点击下方的确定按钮即创建了一个Pipeline任务。
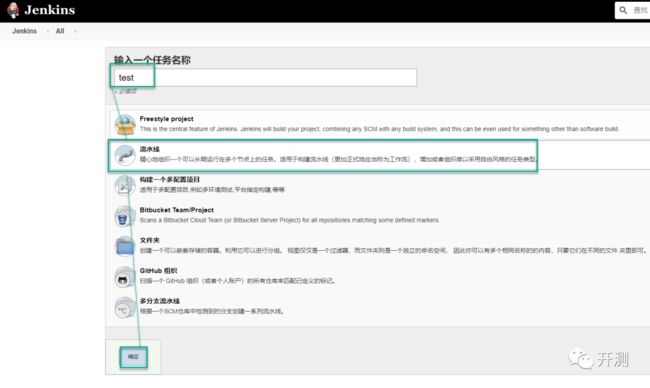
3.跳转到Pipeline的设置页面,我们可以看到有四个tab,我们会针对每一个tab做详细介绍。
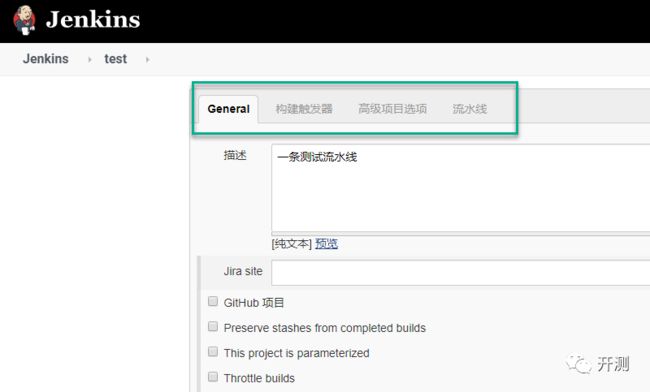
General
General是Pipeline的一些基本配置。名称,描述和一些基本设置。
以下简单介绍几个常用设置。其余没有介绍的设置项,大家可以参考Jenkins的官方文档或者帮助文档。
①.GitHub 项目
该pipeline的源代码托管在Github中,选中此选项,可以添加github中的项目地址

②.Preserve stashes from completed builds
想保留最近几次历史构建就可以勾选此项并填入想要保留的构建次数。每次构建都需要占不少的空间,因此不建议大量保存构建历史。
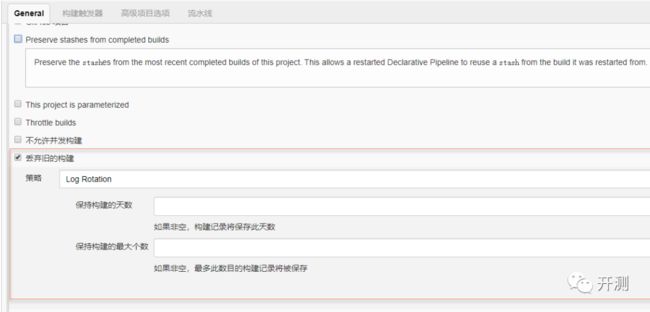
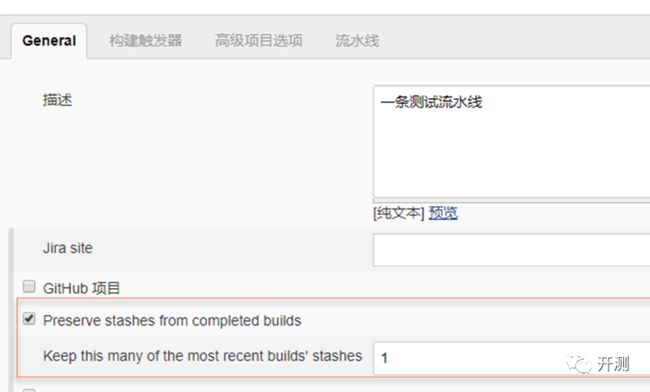 ③.丢弃旧的构建
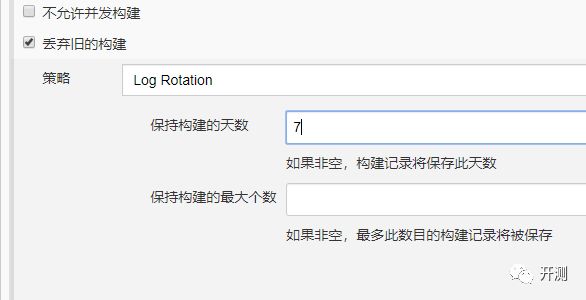
③.丢弃旧的构建
我这里设置了丢弃构建,仅保留最近一周的构建历史,不限定构建次数。
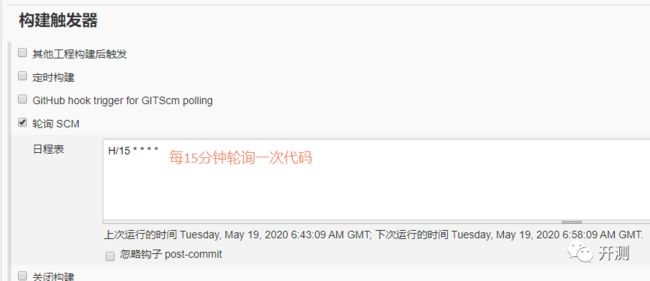
构建触发器
构建触发器很好理解,就是pipeline构建的触发条件。以下简单介绍一下各个触发条件。这些触发条件可以根据项目需要选择多个,组合使用。

我的代码托管在gitlab中,我希望在代码有更新时自动触发构建,所以选择了“轮询SCM”。
高级项目选项
这个是给项目设置一个展示名称,没有特殊作用,不需要过多关注。
流水线
这一部分是Pipeline的主要部分,在这一步我们将开始定义流水线
定义流水线使用的是Groovy脚本,保存脚本有两种方式,第一种是直接写在Jenkins工程中,另一种是存放在代码仓库项目目录下的Jenkinsfile中,实际项目中大多选择将脚本存放在项目目录中,但这仅限于项目数量不多的情况下使用。如果项目过多,Jenkinsfile散落在各个项目中,也会不便维护,这时候可以创建目录集中保存Jenkinsfile,便于查找和维护。
选择定义流水线的方式

我使用的是【PipelinescriptfromSCM】,只添加了代码仓库地址和令牌信息,其余保持默认。
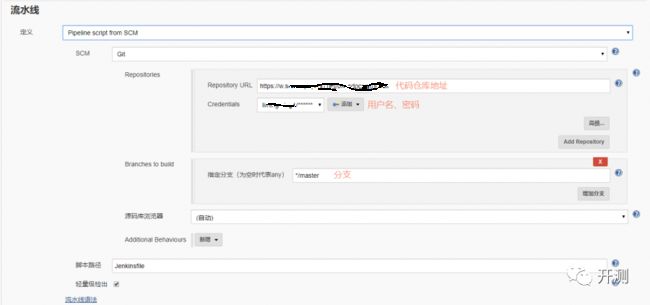
当然,在你考虑用这种方式创建流水线之前,你必须已经设计好的流水线的步骤,并且写好了可靠的Jenkinsfile。
Pipeline支持两种语法,一种是Declarative Pipeline(在Pipeline 2.5中引入)和Scripted Pipeline。Declarative Pipeline对用户来说,语法更严格,有固定的组织结构,更容易生成代码段,使其成为用户更理想的选择。Scripted pipeline更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展。由于篇幅有限所以在此只介绍使用最为广泛的Declarative Pipeline。
在写Jenkinsfile之前我们先来熟悉一些名词。
● Agent:在Jenkins集群中,一个agent相当于一个slave机器,接收并执行master机器分派的任务。
● Stage:Pipeline中的不同阶段,例如:“构建”,“测试”和“部署”。
● Step:步骤,Step是最基本的操作单元,小到创建一个目录,大到构建一个Docker镜像,由各类Jenkins Plugin提供。
下面是我编写的一个由【编译】——【编译Docker镜像】——【部署】——【测试】这几个阶段组成的一条流水线。不熟悉PipelineScript的同学,可以先熟悉一下语法,语法不是文章关注的重点。
pipeline {
agent any //agent 必须放在pipeline的顶层定义或stage中可选定义,放在stage中就是不同阶段使用
stages { //Pipeline 的主体部分,声明不同阶段,比如 构建,部署,测试
stage('Build') { //编译阶段
steps {
sh 'pwd'
git(url: 'https://xxx.xxx.xxx.xxx/xxxxxxxx/xxxxxxx', poll: true, credentialsId: '0000000-0000-0000-0000-000000000000') //拉取代码
echo '使用你的编译工具进行编译' //编译
archiveArtifacts(artifacts: 'testProject', onlyIfSuccessful: true) //编译制品归档
}
}
stage('Docker Build') //编译docker 镜像文件
agent any
steps {
unstash 'test'
sh "docker login"
sh "docker build"
sh "docker push "
sh "docker rmi"
}
}
stage('Deploy') { //部署阶段
agent { //在stage中特别声明agent,该stage就在声明的agent中去执行
docker {
image 'image_name'
}
}
steps { //执行步骤
sh "mkdir -p ~/.kube"
echo '添加部署步骤完成部署 '
echo '启动服务'
}
stage('Test') { //测试阶段
steps {
echo '测试阶段'
git(url: 'https://xxx.xxx.xxx.xxx/xxxxxxxx/xxxxxxx', poll: true, credentialsId: '0000000-0000-0000-0000-000000000000')
echo '执行测试用例'
}
}
}
environment { //环境变量,在satge中使用${variable name}来调用
image_name = 'testProject'
project_path = '../testProject'
K8S_CONFIG = credentials('jenkins-k8s-config')
GIT_TAG = sh(returnStdout: true,script: 'git describe --tags --always').trim()
}
}
值得注意的是,执行Pipeline的过程中会有一些中间产物,如apk包、docker镜像文件,这些统一叫做制品。制品会被保存在JenkinsWorkplace中,如果要使用制品,需要添加【制品归档】的步骤,这样就可以通过页面下载制品。
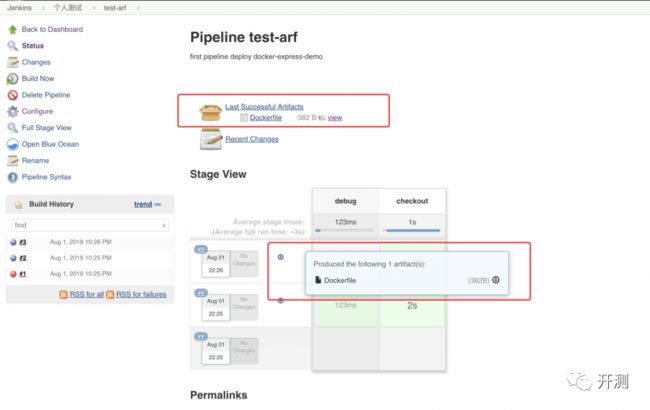
如此便可定义一条Pipeline,经典模式下创建Pipeline是使用最为广泛的一种方式。但是这种方式使用起来有一定门槛,那就是你必须熟悉PipelineScript的语法规则。那如果你说我是一个新手,并没有语言基础,是不是就不能自己创建Pipeline了?当然不是,下面要介绍的第二种方式,就不需要你手写代码了,Jenkins会自动帮你生成。
使用BlueOcean插件,创建pIpeline
还记得文章开头安装的BlueOcean插件吗?这个插件提供了一个可视化的界面,可以通过交互式的方式创建Pipeline,大大降低了使用门槛。下面我们就来体验一下吧!
在Jenkins主页,点击“打开BlueOcean”就可以进入如下界面
点击‘创建新的流水线’就跳转到了创建页面
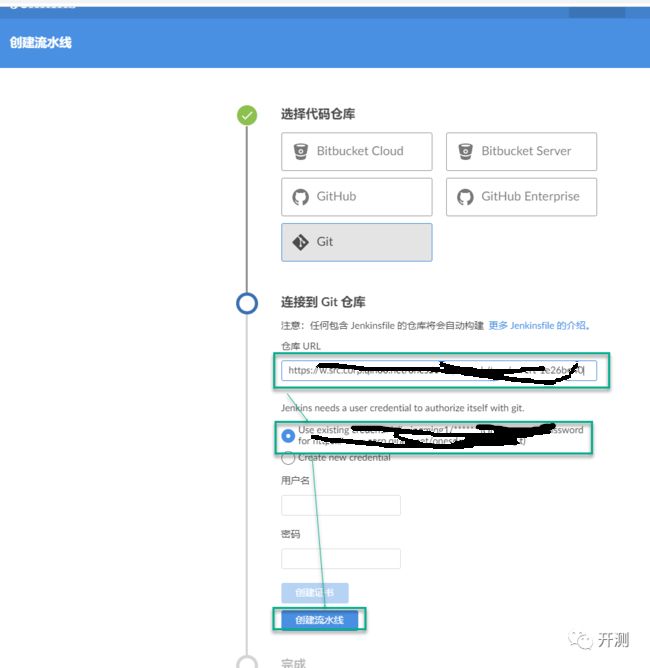
选择代码仓库,填入地址和令牌,创建一条流水线。
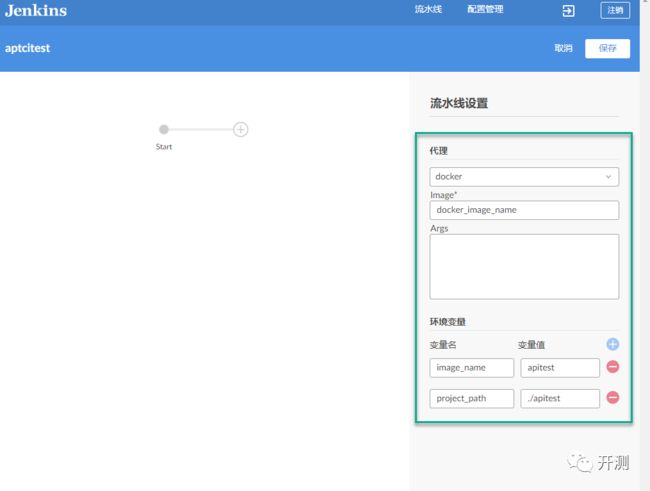
创建完之后,添加阶段,并根据你的需要添加不同的步骤。
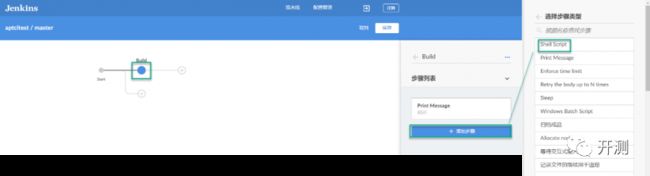
可视化创建Pipeline比较“傻瓜式”,操作起来非常简单,这里就不再详细介绍,有兴趣的小伙伴可以自己实操一下练一练。
需要注意的是,使用BlueOcean创建Pipeline会自动生成一个Jenkinsfile文件,最后会保存在代码仓库的项目目录下面。里面生成的步骤跟我们上面手写的Jenkinsfile一样。每次修改流水线工作流程并提交修改会修改一次Jenkinsfile,并在代码仓库中生成一条修改记录。
以上就是创建Pipeline的两种方式,各位小伙伴可根据自己项目的需要选择不同发方式。在项目数量比较少的情况下,可以使用BlueOcean来创建。如果项目很多或者Pipeline结构比较复杂,使用这种方法就会非常慢,而且Jenkinsfile散落在各个项目目录中,维护起来不方便,这时候更推荐使用经典模式自己写Jenkinsfile的方式创建和维护。
往期精彩回顾
花椒前端TypeScript实践总结
实习招聘|360云平台火热招聘中
360Stack裸金属服务器部署实践


360技术公众号
技术干货|一手资讯|精彩活动
扫码关注我们