shell脚本学习教程(一)
shell脚本学习
- 一、什么是 Shell?
-
- 1. shell概述
- 2. Shell 的分类
- 3. 第一个shell脚本
- 4. 多命令执行
- 二、Shell 变量
-
- 3.1 变量的命名规则
- 3.2 变量的特殊符号
- 3.3 用户自定义变量
- 3.4 环境变量
- 3.5 位置参数变量
- 3.6 预定义变量
- 3.7 接受键盘输入
- 三、Shell 运算符
-
- 3.1 算术运算符
- 3.2 关系运算符
- 3.3 逻辑运算符
- 3.4 赋值运算符
- 3.5 位运算符
- 四、流程控制
-
- 4.1 条件语句 - if语句
- 4.2 循环语句 - for循环
- 4.3 循环语句 - while循环
- 4.4 case语句
- 4.5 控制流程 - break和continue
- 五、函数
-
- 5.1 Shell函数定义
-
- 5.1.1 function关键字函数定义
- 5.1.2 紧凑形式函数定义
- 5.2 函数的调用
- 5.3 函数参数
- 5.4 函数返回值
- 5.5 局部变量
- 5.6 实际示例
-
- 5.6.1 计算阶乘
- 5.6.2 查找文件
- 六、字符截取、替换和处理命令
-
- 6.1 常见的字符处理
-
- 6.1.1 字符串长度
- 6.1.2 截取子字符串
- 6.1.3 删除前缀
- 6.1.4 删除后缀
- 6.1.5 转换为小写
- 6.1.6 转换为大写
- 6.1.7 字符串替换(第一个匹配)
- 6.1.8 字符串替换(全部匹配)
- 6.1.9 提取子串匹配
- 6.2 正则表达式和通配符
-
- 6.2.1 正则表达式和通配符之间的区别
- 6.2.2 常用的正则表达式
- 6.3 字符截取、替换和处理命令
-
- 6.3.1 cut命令
- 6.3.2 awk命令
- 6.3.3 sed命令
- 6.4 sort、uniq、wc 命令
-
- 6.4.1 sort命令
- 6.4.2 uniq命令
- 6.4.3 wc命令
- 6.5 管道(Pipeline)
- 6.6 grep命令
- 7. 输入输出重定向
-
- 7.1 Linux标准输入
- 7.2 输入重定向
- 7.3 输出重定向
- 7.4 /dev/null
一、什么是 Shell?
1. shell概述
Shell 是一个计算机操作系统中的命令行界面(CLI),它允许用户与操作系统进行交互,并执行各种任务和操作。Shell 还是一种脚本编程语言,允许用户编写脚本来自动化任务和执行一系列命令
在 Linux 和 Unix 操作系统中,Shell 是用户与操作系统内核之间的中间层,它接受用户输入的命令,并将这些命令传递给内核执行。用户可以通过键盘输入命令,然后 Shell 解释和执行这些命令。Shell 还负责处理输入和输出、环境变量、文件操作等
一些常见的 Shell 包括 Bash(Bourne-Again Shell)、Zsh(Z Shell)、Fish(Friendly Interactive Shell)等,每种 Shell 都有其自己的特性和功能。Bash 是 Linux 和 macOS 上最常见的默认 Shell
Shell 的主要用途包括:
- 执行命令和程序:用户可以在 Shell 中输入命令来运行程序、管理文件、查看系统状态等
- 脚本编程:用户可以编写 Shell 脚本,将一系列命令和操作组合在一起,以实现自动化任务
- 管道和重定向:Shell 允许用户将命令的输出传递给其他命令,以及将输入和输出重定向到文件或设备
- 环境变量管理:Shell 允许用户设置和管理环境变量,这些变量影响了用户和程序的运行环境
- 流程控制:Shell 支持条件语句、循环和分支,允许用户编写复杂的脚本逻辑
2. Shell 的分类
Shell 编程跟 JavaScript、php 编程一样,需要能编写代码的文本编辑器和一个能解释执行的脚本解释器
Linux 的 Shell 种类众多,常见的有:
- Bourne Shell(/usr/bin/sh或/bin/sh)
- Bourne Again Shell(/bin/bash)
- C Shell(/usr/bin/csh)
- K Shell(/usr/bin/ksh)
- Shell for Root(/sbin/sh)
本教程关注的是 Bash,也就是 Bourne Again Shell,由于易用和免费,Bash 在日常工作中被广泛使用。同时,Bash 也是大多数Linux 系统默认的 Shell。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以 #!/bin/sh同样也可以改为 #!/bin/bash
#! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序
3. 第一个shell脚本
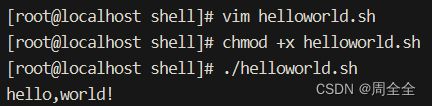
# 1. vim helloworld.sh 是打开一个文本编辑器(Vim)并创建或打开名为 "helloworld.sh" 的文件的命令
vim helloworld.sh
# 2. echo "hello, world!" 是一个 Shell 命令。作用是在终端上打印 "hello, world!"
echo "hello,world!"
# 3. 用于为一个文件赋予可执行权限
chmod +x helloworld.sh
# 4. 运行这个脚本的命令
./helloworld.sh
- 执行效果如下:
4. 多命令执行
| 多命令执行符 | 作用 | 格式 |
|---|---|---|
| ; | 多个命令顺序执行,命令之间没有任何逻辑联系 | 命令1 ; 命令2 |
| && | 当命令1正确执行(退出状态码为0)时,才会执行命令2;否则命令2不会执行 | 命令1 && 命令2 |
| || | 当命令1执行不正确(退出状态码不为0)时,才会执行命令2;否则命令2不会执行 | 命令1 || 命令2 |
多命令执行示例:
-
分号(;)用于多个命令顺序执行,命令之间没有逻辑联系:
$ command1 ; command2 ; command3示例:
$ ls ; echo "Hello" ; date上述命令将依次执行
ls命令(列出当前目录的内容)、echo命令(打印 “Hello”),和date命令(显示当前日期和时间)。 -
逻辑与(&&)操作符用于只有在前一个命令正确执行时才执行下一个命令:
$ command1 && command2示例:
$ rm file.txt && echo "File deleted successfully"上述命令首先尝试删除
file.txt文件,如果删除成功,则执行echo命令以显示 “File deleted successfully”。如果文件删除失败(命令1执行不正确),则echo命令不会执行。 -
逻辑或(||)操作符用于只有在前一个命令执行不正确时才执行下一个命令:
$ command1 || command2示例:
$ find /tmp -name "file.txt" || echo "File not found"上述命令首先尝试在
/tmp目录中查找名为 “file.txt” 的文件。如果找到了文件(命令1执行正确),则不会执行echo命令。如果文件未找到(命令1执行不正确),则echo命令会执行以显示 “File not found”。
二、Shell 变量
3.1 变量的命名规则
在 Shell 脚本中,变量是用来存储和操作数据的关键元素。正确的变量命名是编写清晰、可读和健壮脚本的关键。下面是 Shell 变量的命名规则:
-
变量名称可以包含:
- 字母(大写或小写):a 到 z 或 A 到 Z。
- 数字:0 到 9(但变量名称不能以数字开头)。
- 下划线
_。
-
变量名称必须以字母或下划线开头。不允许以数字开头。
-
变量名称是区分大小写的,因此
$myVar和$myvar是两个不同的变量。 -
避免使用 Shell 的保留关键字(例如,if、while、for 等)作为变量名
-
推荐使用有意义的、描述性的变量名称,以提高脚本的可读性。
-
常见的命名风格:
-
驼峰命名法(Camel Case):第一个单词以小写字母开始,后续单词的首字母大写
例如:myVariableName,thisIsCamelCase. -
下划线命名法(Snake Case):所有字母小写,单词之间用下划线
_分隔。
例如:my_variable_name,this_is_snake_case.
-
示例:
以下是一些示例,演示了不同的变量命名规则:
# 驼峰命名法示例
myVariableName="Hello, World!"
thisIsCamelCase="这是一个驼峰命名"
anotherCamelCaseVariable="这是另个驼峰命名"
# 下划线命名法示例
my_variable_name="Hello, World!"
this_is_snake_case="这是下划线命名"
another_snake_case_variable="这是另一个下划线命名"
正确的变量命名规则是 Shell 脚本编程的基础之一,有助于编写可维护和易读的代码,减少错误和提高代码质量
3.2 变量的特殊符号
-
$:美元符号用于引用变量的值。
示例:myVar="Hello" echo $myVar # 输出:Hello
-
*:星号通配符,用于匹配零个或多个字符。
示例:ls *.txt # 列出所有以 ".txt" 结尾的文件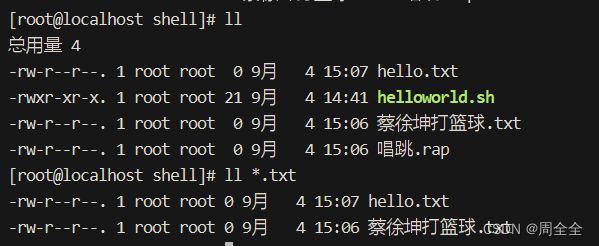
-
?:问号通配符,用于匹配一个任意字符。
示例:ls file?.txt # 列出类似 "file1.txt"、"fileA.txt" 的文件
-
[ ]:方括号用于定义字符集,可以匹配方括号中的任何一个字符。
示例:ls [aeiou]* # 列出以元音字母开头的文件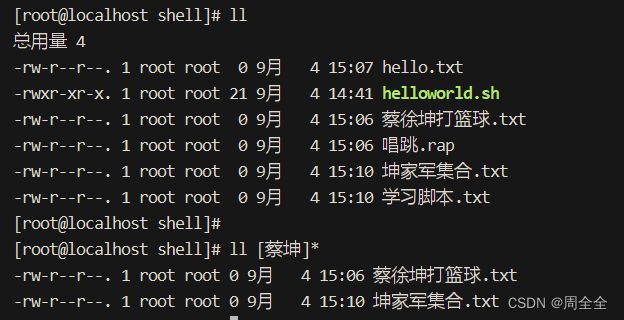
-
{ }:大括号用于创建命令序列或扩展字符串。
示例:echo {A,B,C} # 输出:A B C
-
|:竖线用于将一个命令的输出传递给另一个命令,形成管道。
示例:cat file.txt | grep "pattern" # 在文件中搜索模式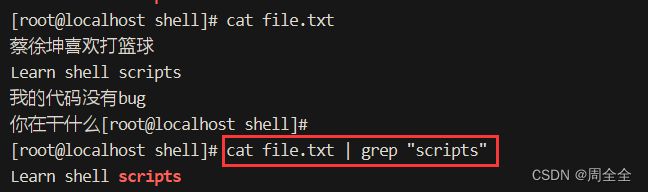
-
;:分号用于分隔多个命令,允许在一行上执行多个命令。
示例:command1; command2 # 依次执行两个命令
-
&&:逻辑与运算符,用于执行两个命令,并且只有在第一个命令成功后才执行第二个命令。
示例:make && make install # 如果 make 成功,则执行 make install -
||:逻辑或运算符,用于执行两个命令,并且只有在第一个命令失败后才执行第二个命令。
示例:command1 || echo "command1 failed" # 如果 command1 失败,则输出提示 -
\>:大于符号用于重定向命令的输出到文件。
示例:echo "Hello, World!" > output.txt # 将文本写入文件

- >>:双大于符号用于追加命令的输出到文件。
示例:
echo "More text" >> output.txt # 追加文本到文件

- <:小于符号用于重定向文件的内容作为命令的输入。
示例:
command < input.txt # 使用文件内容作为输入执行命令
- `:反引号用于执行命令并将其输出作为字符串。
示例:
currentDate=`date` # 获取当前日期并存储为字符串
3.3 用户自定义变量
变量由Shell脚本编写者定义,并用于存储特定任务或计算的中间结果,作用域为当前Shell进程或脚本。
1. 定义变量:
在Shell脚本中,可以使用等号(=)来定义变量。变量名不应该包含空格,并且通常使用大写字母,以便与系统环境变量区分开。
myVar="Hello, World"
2. 赋值变量:
要给变量赋值,只需使用等号(=)进行赋值操作。
myVar="New Value"
3. 使用变量:
要使用变量的值,需要在变量前加上美元符号($)。
echo $myVar
4. 字符串拼接:
可以将变量与字符串拼接在一起。
greeting="Hello"
name="John"
echo "$greeting, $name!"
示例:
[root@localhost shell]# NAME="cxk"
[root@localhost shell]# DOING="play-basketball"
[root@localhost shell]# echo $NAME $DOING
cxk play-basketball
[root@localhost shell]# echo "$NAME,$DOING!!!"
cxk,play-basketball!!!
5. 导出变量:
如果要将变量导出到当前Shell的环境中,以便其他子进程也可以访问它,可以使用export命令。
export myVar="Exported Value"
6. 只读变量:
可以将变量设置为只读,以防止其值被修改。
readonly myVar="This variable is read-only"
示例:
[root@localhost shell]# var='cxk'
[root@localhost shell]# echo $var
cxk
[root@localhost shell]# var='rap'
[root@localhost shell]# echo $var
rap
[root@localhost shell]# readonly var='ikun'
[root@localhost shell]# echo $var
ikun
[root@localhost shell]# var='cxk'
-bash: var: 只读变量
7. 删除变量:
使用unset命令可以删除变量。
unset myVar
示例:
[root@localhost shell]# setVar='temp'
[root@localhost shell]# echo $setVar
temp
[root@localhost shell]# unset setVar
[root@localhost shell]# echo $setVar
8. 最佳实践:
- 使用有意义的变量名,以提高代码的可读性。
- 使用双引号引用变量,以处理包含空格或特殊字符的字符串。
- 避免使用全大写字母来定义非环境变量,以避免与系统环境变量冲突。
- 在使用变量之前,检查它是否已定义,以避免意外错误。
- 使用
readonly来防止不应更改的变量被意外修改。 - 使用
export来使变量在子进程中可用。 - 添加注释来解释变量的用途,以提高代码的可维护性。
3.4 环境变量
1. 什么是环境变量?
环境变量是在操作系统级别存储的键值对,用于存储配置信息、路径、用户首选项等。Shell环境变量对于控制和配置系统行为非常重要
2. 查看环境变量:
使用echo命令和美元符号($)来查看特定环境变量的值
例如输出当前用户的home目录路径:
echo $HOME
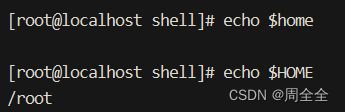
3. 设置环境变量:
要设置环境变量,可以使用export命令:
export MY_VARIABLE="Hello"
这将创建一个名为MY_VARIABLE的环境变量,并将其值设置为"Hello"。请注意,这个变量在当前Shell会话中可用。
4. 持久环境变量:
要使环境变量持久存在,通常会将其添加到shell配置文件中,例如.bashrc或.bash_profile(对于Bash shell)。这样,变量会在每次启动新Shell会话时自动设置。
5. 查看所有环境变量:
要查看所有已定义的环境变量,可以使用env命令:
env
或者使用printenv命令:
printenv
6. 删除环境变量:
要删除环境变量,可以使用unset命令:
unset MY_VARIABLE
7. 使用环境变量:
环境变量在脚本中非常有用,可以用于存储配置信息或路径,例如:
# 使用环境变量
echo "home路径的环境变量地址: $HOME"
8. 系统预定义环境变量:
操作系统和Shell预定义了一些环境变量,如PATH、HOME、USER等,可以使用它们来访问系统信息或配置。
9. 导入环境变量:
导入环境变量意味着将环境变量从一个外部文件或源中加载到当前Shell会话中,以使它们在当前会话中可用。通常用于从文件中加载配置信息、设置环境变量或执行其他脚本之前,以确保所需的环境变量已经定义
在Shell中,有多种方式可以导入环境变量:
-
使用
source命令或.(点号): 这两个命令用于执行指定文件中的命令,并将结果应用到当前Shell会话。通常用于加载环境变量文件,例如.env文件。source .env # 或者 . .env其中
.env是包含环境变量定义的文件。执行这些命令后,.env文件中定义的环境变量将在当前Shell会话中生效。 -
使用
export命令: 如果希望将环境变量导入到当前Shell会话,并使其在子进程中可用,可以使用export命令:export MY_VARIABLE="Hello"这将在当前Shell会话中创建一个名为
MY_VARIABLE的环境变量,并使其在当前会话及其子进程中可用。 -
通过
~/.bashrc或~/.bash_profile: 如果要在每次启动新的Bash Shell会话时自动导入环境变量,可以将其添加到用户主目录下的.bashrc或.bash_profile文件中。这样,环境变量将在每次登录时自动设置。例如,可以在
.bashrc文件中添加如下行来导入环境变量:source /path/to/myenvfile
10. 最佳实践:
- 使用有意义的变量名,以提高代码的可读性。
- 避免覆盖系统预定义的环境变量,以免引发不必要的问题。
- 在需要敏感信息(如密码)时,避免在环境变量中存储它们,因为环境变量通常不是安全的存储方式。
3.5 位置参数变量
- 这些变量用于在Shell脚本中获取命令行参数。
$0表示脚本的名称,$1表示第一个参数,$2表示第二个参数,以此类推。- 示例:
script.sh arg1 arg2 # 在脚本内部可以使用 $0、$1、$2 获取参数
3.6 预定义变量
- Shell 提供了一些特殊的预定义变量,用于获取有关Shell和系统的信息。
- 例如,
$HOME表示当前用户的主目录,$PWD表示当前工作目录。 - 示例:
echo "当前用户的主目录是 $HOME"
3.7 接受键盘输入
- 这些变量用于从用户接受键盘输入。
- 例如,
read命令用于将用户的输入存储在指定的变量中。 - 示例:
echo "请输入您的姓名:" read userName echo "您输入的姓名是:$userName"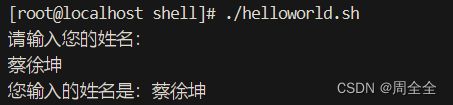
三、Shell 运算符
以下是Shell脚本中常见的运算符的语法和示例
| 运算符类型 | 运算符 | 语法示例 | 示例 |
|---|---|---|---|
| 算术运算符 | 加法 | result=$((a + b)) |
5 + 2 结果为 7 |
| 减法 | result=$((a - b)) |
5 - 2 结果为 3 |
|
| 乘法 | result=$((a * b)) |
5 * 2 结果为 10 |
|
| 除法 | result=$((a / b)) |
10 / 3 结果为 3 |
|
| 取余 | result=$((a % b)) |
15 % 7 结果为 1 |
|
| 关系运算符 | 相等 | [ "$a" -eq "$b" ] |
5 -eq 5 为真 |
| 不等于 | [ "$a" -ne "$b" ] |
5 -ne 2 为真 |
|
| 大于 | [ "$a" -gt "$b" ] |
5 -gt 2 为真 |
|
| 小于 | [ "$a" -lt "$b" ] |
5 -lt 10 为真 |
|
| 大于等于 | [ "$a" -ge "$b" ] |
5 -ge 5 为真 |
|
| 小于等于 | [ "$a" -le "$b" ] |
5 -le 10 为真 |
|
| 逻辑运算符 | 与运算 | [ "$a" -gt 0 ] && [ "$a" -lt 10 ] |
5 > 0 且 5 < 10 为真 |
| 或运算 | [ "$a" -eq 0 ] || [ "$a" -eq 10 ] |
5 = 0 或 5 = 10 为假 |
|
| 非运算 | ! [ "$a" -eq 5 ] |
5 = 5 为假 |
|
| 赋值运算符 | 赋值 | x=10 |
x 等于 10 |
| 加法赋值 | x=$((x + 5)) |
x 加 5 后 x 等于 15 |
|
| 减法赋值 | y=$((y - 5)) |
y 减 5 后 y 等于 15 |
|
| 位运算符 | 按位与 | result=$((a & b)) |
5 & 3 结果为 1 |
| 按位或 | result=$((a | b)) |
5 | 3 结果为 7 |
|
| 按位异或 | result=$((a ^ b)) |
5 ^ 3 结果为 6 |
|
| 按位取反 | result=$((~a)) |
~5 结果为 -6 |
|
| 左移位 | result=$((a << 2)) |
5 << 2 结果为 20 |
|
| 右移位 | result=$((a >> 1)) |
5 >> 1 结果为 2 |
3.1 算术运算符
注意:在Shell中,如果想要执行变量 a 和 b 的加法运算,需要使用特定的语法来实现它。直接键入 $a+$b 不会被Shell解释为加法运算,因为Shell将它视为一个未找到的命令。
要执行加法运算,可以使用expr命令或$((...))表达式。以下是两种方法的示例:
-
方法1: 使用
expr命令a=1 b=2 result=$(expr $a + $b) echo "a + b = $result" -
方法2: 使用
$((...))表达式a=1 b=2 result=$((a + b)) echo "a + b = $result"
用于执行数学运算。支持的算术运算符有+、-、*、/、%。
# 语法:result=$((expression))
a=5
b=2
# 加法
result=$((a + b)) # 结果是7
# 减法
result=$((a - b)) # 结果是3
# 乘法
result=$((a * b)) # 结果是10
# 除法
result=$((a / b)) # 结果是2
# 取余
result=$((a % b)) # 结果是1
3.2 关系运算符
用于比较两个值之间的关系。支持的关系运算符有-eq、-ne、-gt、-lt、-ge、-le。
# 语法:[ expression ]
# 注意:方括号内的空格是必需的!
a=5
b=10
# 相等
if [ "$a" -eq "$b" ]; then
echo "$a 等于 $b"
else
echo "$a 不等于 $b"
fi
# 不等于
if [ "$a" -ne "$b" ]; then
echo "$a 不等于 $b"
else
echo "$a 等于 $b"
fi
# 大于
if [ "$a" -gt "$b" ]; then
echo "$a 大于 $b"
else
echo "$a 不大于 $b"
fi
# 小于
if [ "$a" -lt "$b" ]; then
echo "$a 小于 $b"
else
echo "$a 不小于 $b"
fi
# 大于等于
if [ "$a" -ge "$b" ]; then
echo "$a 大于等于 $b"
else
echo "$a 小于 $b"
fi
# 小于等于
if [ "$a" -le "$b" ]; then
echo "$a 小于等于 $b"
else
echo "$a 大于 $b"
fi
3.3 逻辑运算符
用于执行逻辑操作。支持的逻辑运算符有&&(逻辑与)、||(逻辑或)、!(逻辑非)。
# 语法:command1 && command2
# command2 仅在 command1 返回真(退出状态码为0)时执行
# 与运算
if [ "$a" -gt 0 ] && [ "$a" -lt 10 ]; then
echo "$a 大于0并且小于10"
else
echo "$a 不满足条件"
fi
# 或运算
if [ "$a" -eq 0 ] || [ "$a" -eq 10 ]; then
echo "$a 等于0或等于10"
else
echo "$a 不满足条件"
fi
# 非运算
if ! [ "$a" -eq 5 ]; then
echo "$a 不等于5"
else
echo "$a 等于5"
fi
3.4 赋值运算符
用于给变量赋值。支持的赋值运算符有=``+=、-=、*=、/=、%=。
# 语法:variable operator expression
x=10
y=20
# 赋值
x=5
y=10
# 加法并赋值
x=$((x + 5)) # x 现在等于10
# 减法并赋值
y=$((y - 5)) # y 现在等于15
3.5 位运算符
用于执行位操作。支持的位运算符有&(按位与)、|(按位或)、^(按位异或)、~(按位取反)、<<(左移)、>>(右移)。
# 语法:result=$((expression))
a=5
b=3
# 按位与
result=$((a & b)) # 结果是1
# 按位或
result=$((a | b)) # 结果是7
# 按位异或
result=$((a ^ b)) # 结果是6
# 按位取反
result=$((~a)) # 结果是-6
# 左移
result=$((a << 2)) # 结果是20
# 右移
result=$((a >> 1)) # 结果是2
四、流程控制
Shell脚本中的流程控制结构包括条件语句(if语句)、循环语句(for循环、while循环)、case语句等。以下是每种流程控制结构的详细语法和使用示例:
4.1 条件语句 - if语句
-
if语句用于在特定条件下执行不同的命令。语法如下:if [ condition ]; then # 条件为真时执行的命令 else # 条件为假时执行的命令 fi -
示例:
#!/bin/bash x=10 if [ $x -eq 10 ]; then echo "x 等于 10" else echo "x 不等于 10" fi
4.2 循环语句 - for循环
-
for循环用于遍历列表中的元素执行一系列命令。语法如下:for variable in list; do # 在每次迭代中执行的命令 done -
示例:
#!/bin/bash fruits=("apple" "banana" "cherry") for fruit in "${fruits[@]}"; do echo "水果:$fruit" done
4.3 循环语句 - while循环
-
while循环用于在条件为真时执行一系列命令,直到条件为假为止。语法如下:while [ condition ]; do # 当条件为真时执行的命令 done -
示例:
#!/bin/bash count=1 while [ $count -le 5 ]; do echo "循环次数:$count" ((count++)) done
4.4 case语句
-
case语句用于根据不同的条件执行不同的命令。语法如下:case expression in pattern1) # 匹配 pattern1 时执行的命令 ;; pattern2) # 匹配 pattern2 时执行的命令 ;; *) # 默认情况下执行的命令 ;; esac -
示例:
#!/bin/bash fruit="apple" case $fruit in "apple") echo "这是苹果" ;; "banana") echo "这是香蕉" ;; *) echo "这不是苹果或香蕉" ;; esac
4.5 控制流程 - break和continue
-
break用于退出循环。 -
continue用于跳过当前循环的剩余部分并继续下一次迭代。 -
示例:
#!/bin/bash for i in {1..5}; do if [ $i -eq 3 ]; then continue fi echo "循环次数:$i" if [ $i -eq 4 ]; then break fi done
五、函数
Shell函数是一种强大的工具,它允许将一组命令和逻辑封装到一个可重用的单元中,以执行特定的任务或计算。在本文中将深入研究Shell函数的详细语法和提供多个实际示例,来更好地理解和使用它们。
5.1 Shell函数定义
Shell函数可以使用两种不同的语法形式,分别是使用function关键字和使用紧凑形式。
5.1.1 function关键字函数定义
function function_name {
# 函数体,包括命令和逻辑
# 可以接受参数
# 可以使用局部变量
# 可以返回一个值
}
5.1.2 紧凑形式函数定义
function_name() {
# 函数体
}
5.2 函数的调用
函数定义后,就可以在脚本中任何需要的地方调用它。调用函数时,只需使用其名称后跟所需的参数
语法:
function_name argument1 argument2
简单的函数的调用示例
# 定义一个函数,用于打印欢迎消息
welcome() {
echo "欢迎来到Shell函数示例!"
}
# 调用函数
welcome
5.3 函数参数
函数可以接受参数,这使得函数更加通用和灵活。在函数内部可以使用$1、$2、$3等变量来引用传递给函数的参数。这些变量分别表示第一个参数、第二个参数、第三个参数,以此类推。
让我们看一个接受参数的函数示例:
# 定义一个函数,接受两个参数并打印它们
print_arguments() {
echo "第一个参数: $1"
echo "第二个参数: $2"
}
# 调用函数,并传递两个参数
print_arguments "Hello" "World"
print(){
echo "你的名字:$1"
echo "你的爱好:$2"
}
print "蔡徐坤" "打篮球"
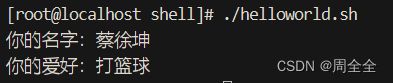
5.4 函数返回值
Shell函数可以返回一个值,这使得函数能够执行计算并将结果传递回主程序。要返回一个值,可以使用return语句,然后在主程序中使用$?来获取返回值。
计算两个数字之和并返回结果的函数示例:
# 定义一个函数,计算两个数字之和并返回结果
add_numbers() {
local sum=$(( $1 + $2 ))
return $sum
}
# 调用函数,并获取返回值
add_numbers 5 7
result=$?
echo "5 + 7 的和是:$result"
5.5 局部变量
在Shell函数中,可以使用local关键字来创建局部变量。局部变量仅在函数内部可见,不会影响全局作用域的变量。这是非常有用的,因为它允许在函数内部使用变量而不担心与其他部分的代码发生冲突。
局部变量的函数示例:
# 定义一个函数,演示局部变量
my_function() {
local local_variable="局部变量"
echo "在函数内部:$local_variable"
}
local_variable="全局变量"
my_function
echo "在函数外部:$local_variable"
fun(){
echo "全局变量值:$var"
local var="局部变量"
echo "局部变量赋值后:$var"
}
var="全局变量"
fun

5.6 实际示例
5.6.1 计算阶乘
计算给定数字的阶乘,阶乘是一个正整数的乘积,从1到该整数的所有正整数的乘积。
# 定义一个函数,计算给定数字的阶乘
calculate_factorial() {
local number=$1
local result=1
if [ $number -lt 0 ]; then
echo "输入必须是非负整数。"
return 1
fi
for (( i=1; i<=number; i++ )); do
result=$((result * i))
done
echo "$number 的阶乘是:$result"
return 0
}
# 调用函数,计算阶乘
calculate_factorial 5
calculate_factorial 0
calculate_factorial -3
5.6.2 查找文件
文件系统中查找特定文件并返回文件的路径
# 定义一个函数,查找文件并返回路径
find_file() {
# 接受两个参数:文件名和搜索目录
local file_name=$1
local search_dir=$2
# 检查是否提供了有效的文件名和搜索目录
if [ -z "$file_name" ] || [ -z "$search_dir" ]; then
echo "请输入文件名和搜索目录。"
return 1 # 返回错误代码1表示参数不足或无效
fi
# 使用`find`命令在指定目录中查找文件
local result=$(find "$search_dir" -name "$file_name")
# 检查是否找到文件
if [ -z "$result" ]; then
echo "未找到文件 '$file_name'。"
return 1 # 返回错误代码1表示未找到文件
else
echo "文件 '$file_name' 的路径是:$result"
return 0 # 返回成功代码0表示找到文件
fi
}
# 调用函数,查找文件
find_file "example.txt" "/path/to/search" # 查找存在的文件
find_file "missing.txt" "/path/to/search" # 查找不存在的文件
find_file "" "/path/to/search" # 无效的参数:文件名为空
六、字符截取、替换和处理命令
6.1 常见的字符处理
6.1.1 字符串长度
语法:
${#string}
示例:
string="Hello, World!"
length=${#string}
echo "字符串的长度为:$length" # 输出 "字符串的长度为:13"
6.1.2 截取子字符串
语法:
${string:起始位置:长度}
示例:
string="Hello, World!"
substring="${string:0:5}" # 从位置0开始截取5个字符
echo "$substring" # 输出 "Hello"
6.1.3 删除前缀
语法:
${string#前缀}
示例:
string="/path/to/file.txt"
without_prefix="${string#/path/}" # 删除前缀 "/path/"
echo "$without_prefix" # 输出 "to/file.txt"
6.1.4 删除后缀
语法:
${string%后缀}
示例:
string="/path/to/file.txt"
without_suffix="${string%.txt}" # 删除后缀 ".txt"
echo "$without_suffix" # 输出 "/path/to/file"
6.1.5 转换为小写
语法:
${string,,}
示例:
string="Hello, World!"
lowercase="${string,,}" # 转换为小写
echo "小写: $lowercase" # 输出 "小写: hello, world!"
6.1.6 转换为大写
语法:
${string^^}
示例:
string="Hello, World!"
uppercase="${string^^}" # 转换为大写
echo "大写: $uppercase" # 输出 "大写: HELLO, WORLD!"
6.1.7 字符串替换(第一个匹配)
语法:
${string/要替换的子串/替换为的字符串}
示例:
string="姓名:name,age:20,height:159cm,艺名:name"
replaced="${string/name/cxk}" # 替换第一个 "name" 为 "cxk"
echo "$replaced" # 输出 "姓名:cxk,age:20,height:159cm,艺名:name"

6.1.8 字符串替换(全部匹配)
语法:
${string//要替换的子串/替换为的字符串}
示例:
string="姓名:name,age:20,height:159cm,艺名:name"
replaced="${string//name/cxk}" # 替换所有的 "apples" 为 "bananas"
echo "$replaced" # 输出 "I love bananas, bananas are great!"

6.1.9 提取子串匹配
语法:
[[ $string =~ 正则表达式 ]]
匹配结果:${BASH_REMATCH[n]}
示例:
string="我的邮箱 [email protected]"
# 使用正则表达式来匹配字符串中的邮箱地址,并将匹配结果存储在`BASH_REMATCH`数组中,然后提取出匹配的邮箱地
if [[ $string =~ [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4} ]]; then
email="${BASH_REMATCH[0]}"
echo "匹配到的邮箱地址是:$email"
fi

6.2 正则表达式和通配符
6.2.1 正则表达式和通配符之间的区别
-
正则表达式(Regular Expressions):
- 正则表达式是一种强大的
模式匹配工具,根据模式来匹配文本中的字符串。它是一种包含匹配,因此可以匹配字符串中的任何位置。 - 在Linux中,命令如
grep、awk、sed等通常支持正则表达式。可以使用正则表达式来搜索、替换、过滤文本等。 - 正则表达式的语法丰富,允许执行高级的文本操作,如捕获、分组、重复匹配等。
示例:
- 使用
grep查找所有包含数字的行:grep '[0-9]' file.txt
- 正则表达式是一种强大的
-
通配符(Wildcard):
- 通配符用于匹配文件名。它是一种完全匹配,只匹配符合特定模式的文件名,不考虑文件内容。
- 在Linux中,命令如
ls、find、cp等通常支持通配符。通配符用于查找或操作文件,而不是文件中的文本。 - 通配符包括
*(匹配零个或多个字符)、?(匹配一个字符)、[...](匹配字符范围)等。
示例:
- 使用
ls列出所有以.txt结尾的文件:ls *.txt
总结:
- 正则表达式用于文本处理,支持更高级的匹配和操作。
- 通配符用于文件名匹配,是一种基本的文件选择工具。
6.2.2 常用的正则表达式
| 正则表达式模式 | 描述 | 使用示例 |
|---|---|---|
^pattern |
匹配以pattern开头的行。 |
grep '^Error' file.txt 匹配以"Error"开头的行。 |
pattern$ |
匹配以pattern结尾的行。 |
grep 'end$' file.txt 匹配以"end"结尾的行。 |
. |
匹配任何单个字符,除了换行符。 | grep 'a.b' file.txt 匹配 “aab”、“axb” 等。 |
* |
匹配前一个字符或子表达式的零个或多个实例。 | grep 'go*gle' file.txt 匹配 “ggle”、“google”、“gooogle” 等。 |
+ |
匹配前一个字符或子表达式的一个或多个实例。 | grep 'go+gle' file.txt 匹配 “google”、“gooogle” 等,但不匹配 “ggle”。 |
? |
匹配前一个字符或子表达式的零个或一个实例。 | grep 'colou?r' file.txt 匹配 “color” 和 “colour”。 |
[abc] |
匹配字符集中的任何一个字符。 | grep '[aeiou]' file.txt 匹配包含元音字母的行。 |
[0-9] |
匹配任何一个数字。 | grep '[0-9]' file.txt 匹配包含数字的行。 |
[^abc] |
匹配不在字符集中的任何一个字符。 | grep '[^0-9]' file.txt 匹配不包含数字的行。 |
\d |
匹配任何一个数字字符,等同于[0-9]。 |
grep '\d' file.txt 匹配包含数字的行。 |
\D |
匹配任何一个非数字字符,等同于[^0-9]。 |
grep '\D' file.txt 匹配不包含数字的行。 |
\w |
匹配任何一个单词字符(字母、数字或下划线),等同于[a-zA-Z0-9_]。 |
grep '\w' file.txt 匹配包含单词字符的行。 |
\W |
匹配任何一个非单词字符,等同于[^a-zA-Z0-9_]。 |
grep '\W' file.txt 匹配不包含单词字符的行。 |
\s |
匹配任何一个空白字符(空格、制表符、换行符等)。 | grep '\s' file.txt 匹配包含空白字符的行。 |
\S |
匹配任何一个非空白字符。 | grep '\S' file.txt 匹配不包含空白字符的行。 |
(pattern) |
创建一个捕获组,用于捕获匹配的文本。 | grep 'a\(bc\)*d' file.txt 匹配 “ad”、“abcd”、“abcbcd” 等。 |
| ` | ` | 逻辑或操作符,匹配两个模式中的任何一个。 |
.* |
匹配零个或多个任意字符,通常用于匹配整行文本。 | grep '.*pattern.*' file.txt 匹配包含 “pattern” 的行。 |
6.3 字符截取、替换和处理命令
6.3.1 cut命令
cut命令用于从文本行中剪切或提取字段。默认情况下,cut使用制表符(Tab)作为字段分隔符,但可以通过-d选项指定其他分隔符。它通常用于提取或删除文本文件中的特定列。
基本用法:
cut [OPTIONS] [FILE]
-
剪切文件中的第2列:
cut -f2 input.txt
-
使用逗号作为分隔符剪切第1和第3列:
cut -d',' -f1,3 input.csv
-
以特定字符作为字段分隔符,剪切第1列:
cut -d',' -f1 /etc/passwd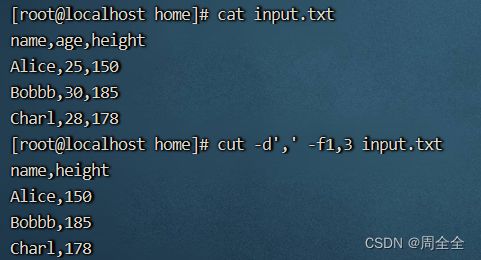
-
剪切每行的前5个字符:
cut -c1-5 input.txt
6.3.2 awk命令
awk是一个强大的文本处理工具,它可以执行复杂的文本处理操作,包括文本提取、计算、条件筛选等。awk将文本分割成字段,并允许对字段进行操作。它的灵活性使其成为处理结构化文本数据的理想工具。
基本用法:
awk 'pattern { action }' [FILE]
-
显示文件的第2列和第3列:
awk '{print $2, $3}' input.txt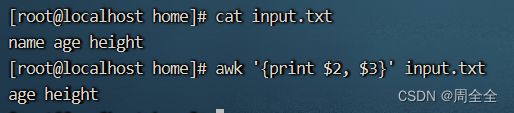
-
计算文件中所有数字的总和:
awk '{ sum += $1 } END { print sum }' input.txt
-
使用逗号作为分隔符,打印第1列和第3列:
awk -F',' '{print $1, $3}' input.csv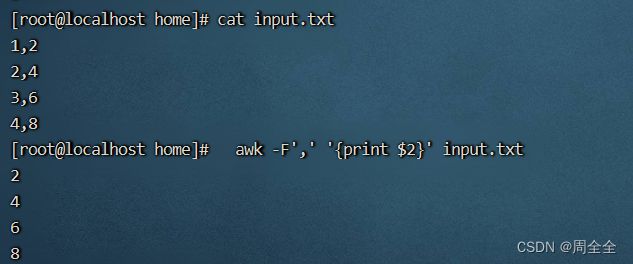
-
打印包含特定模式的行:
awk '/pattern/ {print}' input.txt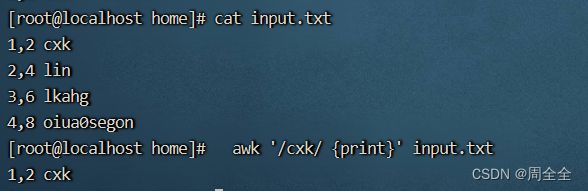
6.3.3 sed命令
sed(流编辑器)用于对文本进行基本的编辑和转换,如替换、删除、插入和替换。sed可以通过正则表达式来匹配和操作文本,通常在管道中与其他命令一起使用。
基本用法:
sed [OPTIONS] 's/pattern/replacement/' [FILE]
-
替换文本文件中的所有"old"为"new":
sed 's/old/new/g' input.txt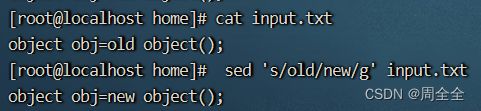
-
删除包含特定字符串的行:
sed '/pattern/d' input.txt
-
在每行的开头插入文本:
sed 's/^/Prefix /' input.txt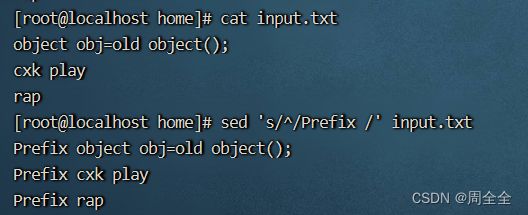
-
将文件中的所有字母转换为大写:
sed 's/[a-z]/\U&/g' input.txt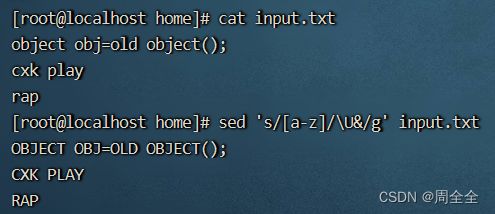
6.4 sort、uniq、wc 命令
sort、uniq和wc是在Linux和Unix系统上常用的命令,用于排序、去重和统计文本数据。
6.4.1 sort命令
sort命令用于对文本文件的行进行排序。默认情况下,它按照字典顺序对文本行进行排序,但可以使用不同的选项来进行数字排序、逆序排序等。
基本用法:
sort [OPTIONS] [FILE]
-
对文件进行排序并将结果输出到标准输出:
sort input.txt
-
对文件进行数字排序(例如,按数值大小而不是字典顺序):
sort -n input.txt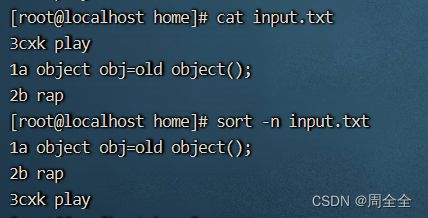
-
对文件进行逆序排序:
sort -r input.txt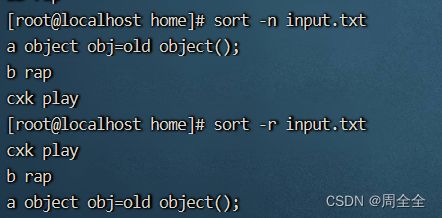
6.4.2 uniq命令
uniq命令用于从已排序的文本数据中去重重复的行。它通常与sort命令结合使用,以确保重复行相邻。
基本用法:
uniq [OPTIONS] [FILE]
-
从文件中去重重复的行:
sort input.txt | uniq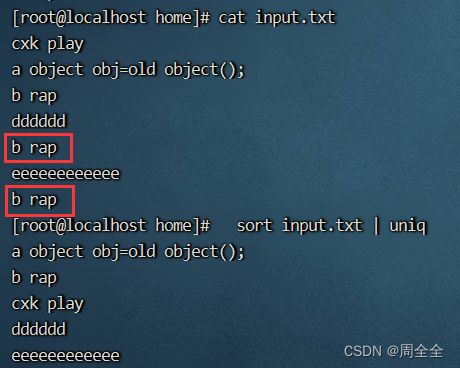
-
显示去重后的行以及它们重复的次数:
sort input.txt | uniq -c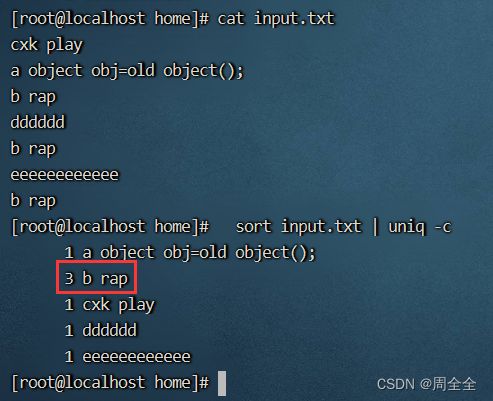
6.4.3 wc命令
wc命令用于统计文本文件的行数、字数和字符数。
基本用法:
wc [OPTIONS] [FILE]
-
统计文件的行数、单词数和字符数:
wc input.txt
-
仅统计行数:
wc -l input.txt
-
仅统计单词数:
wc -w input.txt
-
仅统计字符数:
wc -c input.txt
6.5 管道(Pipeline)
管道(Pipeline)是在Unix和类Unix操作系统中广泛使用的强大工具,它允许将一个命令的输出直接传递给另一个命令,以便进行复杂的数据处理和筛选。
管道(Pipeline)语法:
command1 | command2
command1:第一个命令的输出将被传递给第二个命令。command2:接收来自command1的输入并进行处理的第二个命令。
6.6 grep命令
grep命令用于在文本中搜索匹配指定模式的行
grep命令语法:
grep [选项] 模式 [文件...]
选项:可以是一些可选的标志,用于控制搜索的行为。模式:要搜索的文本模式或正则表达式。文件:要在其中搜索模式的一个或多个文件。如果省略文件参数,则grep将从标准输入中读取数据。
- 搜索文件中包含特定字符串的行:
grep "search_term" filename.txt
- 搜索多个文件中包含特定字符串的行:
grep "search_term" file1.txt file2.txt
- 搜索目录中所有文件包含特定字符串的行:
grep "search_term" /path/to/directory/*
- 搜索多个文件并显示匹配行的行号:
grep -n "search_term" file1.txt file2.txt
- 忽略大小写进行搜索:
grep -i "search_term" filename.txt
- 使用正则表达式进行高级搜索(例如,查找以"abc"开头的行):
grep "^abc" filename.txt
- 逆向搜索,即只显示不匹配模式的行:
grep -v "search_term" filename.txt
- 递归搜索目录中的文件:
grep -r "search_term" /path/to/directory/
- 搜索匹配模式的行并统计匹配的次数:
grep -c "search_term" filename.txt
7. 输入输出重定向
7.1 Linux标准输入
| 类型 | 设备 | 设备名 | 文件描述符 | 类型 |
|---|---|---|---|---|
| 标准输入(stdin) | 键盘 | /dev/stdin | 0 | 标准输入 |
| 标准输出(stdout) | 显示器 | /dev/stdout | 1 | 标准输出 |
| 标准错误输出(stderr) | 显示器 | /dev/stderr | 2 | 标准错误输出 |
7.2 输入重定向
| 类型 | 符号(语法) | 功能 |
|---|---|---|
| 标准输入 | 命令 < 文件1 | 命令将文件1的内容作为标准输入设备 |
| 标识符限定输入 | 命令 << 标识符 | 命令将标准输入中读入内容,直到遇到“标识符”分隔符为止 |
| 输入输出重定向 | 命令 < 文件1 > 文件2 | 命令将文件1的内容作为标准输入,将文件2作为标准输出。 |
7.3 输出重定向
| 类型 | 符号 | 作用 |
|---|---|---|
| 标准输出重定向(覆盖) | 命令 > 文件 | 以覆盖方式,将命令的正确输出内容输出到指定的文件或设备中 |
| 标准输出重定向(追加) | 命令 >> 文件 | 以追加方式,将命令的正确输出内容输出到指定的文件或设备中 |
| 标准错误输出重定向(覆盖) | 错误命令 2> 文件 | 以覆盖方式,将命令的错误输出输出到指定的文件或设备中 |
| 标准错误输出重定向(追加) | 错误命令 2>> 文件 | 以追加方式,将命令的错误输出输出到指定的文件或设备中 |
| 同时保存标准输出和标准错误输出(覆盖) | 命令 > 文件 2>&1 | 以覆盖方式,将正确输出和错误输出都保存到同一个文件中 |
| 同时保存标准输出和标准错误输出(追加) | 命令 >> 文件 2>&1 | 以追加方式,将正确输出和错误输出都保存到同一个文件中 |
| 同时保存标准输出和标准错误输出(覆盖) | 命令 &> 文件 | 以覆盖方式,将正确输出和错误输出都保存到同一个文件中 |
| 同时保存标准输出和标准错误输出(追加) | 命令 &>> 文件 | 以追加方式,将正确输出和错误输出都保存到同一个文件中 |
| 分别保存正确输出和错误输出 | 命令 > 文件1 2> 文件2 | 将正确输出保存到文件1中,将错误输出保存到文件2中 |
7.4 /dev/null
如果希望执行某个命令,但不希望在屏幕上显示输出结果,可以将输出重定向到 /dev/null 文件中,从而将输出完全丢弃。
示例:
command > /dev/null
这个命令将命令的标准输出重定向到 /dev/null 文件,以完全丢弃输出。