初识Java 11-2 函数式编程
目录
高阶函数
闭包
函数组合
柯里化和部分求值
本笔记参考自: 《On Java 中文版》
高阶函数
||| 高阶函数的定义:一个能接受函数作为参数或能把函数当返回值的函数。
把函数当返回值的情况:
import java.util.function.Function;
interface FuncSS extends Function {
}
public class ProduceFunction {
static FuncSS produce() {
return s -> s.toLowerCase();
}
public static void main(String[] args) {
FuncSS f = produce();
System.out.println(f.apply("ABCDEF"));
}
} 程序执行的结果是:
![]()
这里的produce()就是高阶函数。
- 使用继承,可以为接口创建别名;
- 使用lambda表达式,可以在方法中创建并返回一个函数。
要接受并使用函数,方法必须在其函数列表中正确描述函数类型(把函数当作参数):
import java.util.function.Function;
class One {
}
class Two {
}
public class ConsumeFunction {
static Two consume(Function onetwo) {
return onetwo.apply(new One());
}
public static void main(String[] args) {
Two two = consume(one -> new Two());
}
} 同时,我们也可以通过所接受的函数生成一个新的函数:
import java.util.function.Function;
class I {
@Override
public String toString() {
return "类I";
}
}
class O {
@Override
public String toString() {
return "类O";
}
}
public class TransformFunction {
static Function transform(Function in) {
return in.andThen(o -> {
System.out.println(o);
return o;
});
}
public static void main(String[] args) {
Function f2 = transform(i -> {
System.out.println(i);
return new O();
});
O o = f2.apply(new I());
}
} 程序执行的结果是:

这里,transform()生成了一个与传入函数签名相同的函数,但这是可以按照需要进行更改的。
在transform()方法内部调用了Function接口中的andThen()方法,这个方法专门为操作函数设计。andThen()会在in函数调用之后调用(与之相对的,还有一个compose()方法,会在in函数之前调用)。
transform()最终传出了一个新函数,这个函数结合了in的动作和andThen()参数的动作。
闭包
若一个lambda表达式使用了其作用域之外的变量,那么在返回该函数时,会发生什么?也就是说,当我们调用这个函数时,函数所引用的“外部”变量会变成什么?若语言能够解决这一问题,就说这门语言支持闭包(又称支持语法作用域)。
Java 8提供了有限但可用的闭包支持。下面的例子中,函数会访问一个对象字段和一个方法参数:
import java.util.function.IntSupplier;
public class Closure1 {
int i;
IntSupplier makeFun(int x) {
return () -> x + i++;
}
}这里还需要提到第二个概念,变量捕获。变量捕获是指在一个方法中定义的变量可以访问到另一个方法中的同名变量。这也被称为外部变量。这一概念主要是为了支持内部类访问外部类的成员变量。在上述例子中,makeFun()捕获了变量i。
此时,i是一个对象中的变量,在我们调用makeFun()后,该对象可能还存在。另外,若对同一个对象调用多次makeFun(),最终将会有多个函数共享同样的i的储存空间:
import java.util.function.IntSupplier;
public class SharedStorage {
public static void main(String[] args) {
Closure1 c1 = new Closure1();
IntSupplier f1 = c1.makeFun(0);
IntSupplier f2 = c1.makeFun(0);
IntSupplier f3 = c1.makeFun(0);
System.out.println(f1.getAsInt());
System.out.println(f2.getAsInt());
System.out.println(f3.getAsInt());
}
}程序执行的结果是:
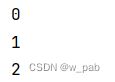
若i是makeFun()中的局部变量时,情况就变了。因为一旦makeFun()执行完毕,i就会被回收。但此时依旧可以编译:
import java.util.function.IntSupplier;
public class Closure2 {
IntSupplier makeFun(int x) {
int i = 0;
return () -> x + i;
}
}在这里,makeFun()返回的IntSupplier就是在i和x上构建的闭包,因此调用函数时,两个变量都会有效。但若在这里对i进行像i++这样的操作,就会引发编译错误:

编译器提示我们需要将x和i标记为最终变量,这样我们就无法对任何变量进行增加操作了:
import java.util.function.IntSupplier;
public class Closure4 {
IntSupplier makeFun(final int x) {
final int i = 0;
return () -> x + i;
}
}当然,在上述这个例子中即使没有final,代码依旧可以正常工作。这就体现了“实际上的最终变量”这一术语,这个术语是为Java 8创建的,其意思是,即使没有显式声明最终变量,但仍然可以用最终变量的方式来对待一个变量——只要不修改它即可。
另外,即使在返回时的lambda表达式中没有修改变量,而在方法的其他地方进行了修改,依旧会引发报错:

所谓的“实际上的最终变量”,要求我们不对这些变量进行修改。当然,实际上我们可以这样修改Closure5.java中的问题:在闭包中使用x和i之前,对其进行赋值:
import java.util.function.IntSupplier;
public class Closure6 {
IntSupplier makeFun(int x) {
int i = 0;
i++;
x++;
final int iFinal = i;
final int xFinal = x;
return () -> xFinal + iFinal;
}
}iFinal和xFinal在赋值后没有进行修改,所以这里实际上并不需要final修饰。
另外,即使使用的是引用,编译器也会看出问题:

不过倒是可以使用List:
import java.util.ArrayList;
import java.util.List;
import java.util.function.Supplier;
public class Closure8 {
Supplier> makeFun() {
final List ai = new ArrayList<>();
ai.add(1);
return () -> ai;
}
public static void main(String[] args) {
Closure8 c8 = new Closure8();
List
l1 = c8.makeFun().get(),
l2 = c8.makeFun().get();
System.out.println(l1);
System.out.println(l2);
l1.add(42);
l2.add(96);
System.out.println(l1);
System.out.println(l2);
}
} 程序执行的结果是:

这次的修改成功了。因为每次调用makeFun()时,都会创建并返回一个全新的ArrayList。这意味着没有变量是被共享的,每个生成的闭包都有自己单独的ArrayList,不会互相干扰。
对上述示例而言,即使引用ai没有被final修饰也没有问题。对引用使用final,只是保证这个对象引用本身不会被重新赋值。
若只修改所指对象的内容,Java是可以接受的,前提是没有其他人获得该对象的引用。否则就意味着不止一个实体可以修改同一个对象,这会造成混乱。
现在再看Closure1.java,在这里i的修改没有引发报错:
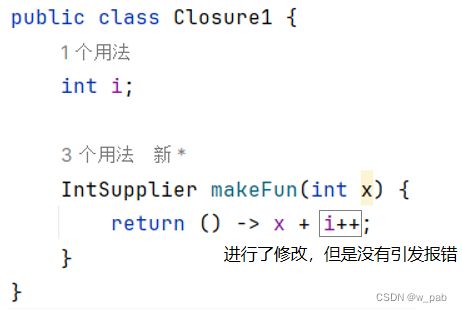
理由显而易见,因为i是外围类的成员,即使它不是最终变量,或“实际上的最终变量”。
注意:应该考虑的是,lambda表达式捕获的变量是“实际上的最终变量”。若变量是某个对象中的一个字段,因为这个字段有独立的生命周期,所以即使不通过特殊的捕获,在lambda表达式调用之后,这个变量依旧会存在。
内部类作为闭包
可以通过匿名内部类来实现上述示例:
import java.util.function.IntSupplier;
public class AnonymousClosure {
IntSupplier makeFun(int x) {
int i = 0;
// 同样不支持这种语句:
// i++;
// x++;
return new IntSupplier() {
@Override
public int getAsInt() {
return x + i;
}
};
}
}只要有内部类,就会存在闭包。在Java 8之前,内部类只能调用显式的最终变量。但Java 8放宽了这一规则,现在内部类可以使用“实际上的最终变量”。
函数组合
||| 函数组合:将多个函数结合使用,以创建新的函数。
函数组合通常被认为是函数式编程的一部分,之前使用andThen()方法的函数就是一个例子。除此之外,java.util.function中的一些接口也有支持函数组合的方法,这里介绍一些常见的方法:
| 方法 | 作用 |
|---|---|
| andThen(argument) | 先执行原始操作,再执行参数操作 |
| compose(argument) | 先执行参数操作,再执行原始操作 |
| and(argument) | 对原始谓词和参数谓词执行短路逻辑与(AND)计算 |
| or(argument) | 对原始谓词和参数谓词执行短路逻辑或(OR)计算 |
| negate() | 所得谓语为该谓语的逻辑取反 |
【例子1:Function的compose()和andThen()】
import java.util.function.Function;
public class FunctionComposition {
static Function f1 = s -> {
System.out.println(s);
return s.replace('A', '_');
},
f2 = s -> s.substring(3),
f3 = s -> s.toLowerCase(),
f4 = f1.compose(f2).andThen(f3);
public static void main(String[] args) {
System.out.println(f4.apply("GO AFTER ALL"));
}
} 程序执行的结果是:

程序会按照 f2、f1、f3、f4 的顺序进行程序执行。这里的重点在于,创建的新函数f4几乎可以像其他任何函数一样使用apply()。
当f1得到String时,因为compose(f2)的存在,f2会在f1之前被调用。
【例子2:Predicate(谓词)的逻辑运算】
import java.util.function.Predicate;
import java.util.stream.Stream;
public class PredicateComposition {
static Predicate
p1 = s -> s.contains(("bar")),
p2 = s -> s.length() < 5,
p3 = s -> s.contains("foo"),
p4 = p1.negate().and(p2).or(p3);
public static void main(String[] args) {
Stream.of("bar", "foobar", "foobaz", "fongopuckey")
.filter(p4)
.forEach(System.out::println);
}
} 程序执行的结果是:

p4接受了所有的谓词,并将其组合成了一个更加复杂的谓词,这个组合可以理解成:若这个String ①不包含"bar",②并且长度小于5,③或其中包含"foo",则结果为true。
上述程序使用了一个String对象的“流”。其中filter()会对每个对象进行筛选,决定它们的去留。而forEach()会将留下的对象交给println方法引用。
柯里化和部分求值
||| 柯里化:将一个接收多个参数的函数转变为一系列只接受一个参数的函数。
【例子】
import java.util.function.Function;
public class CurryingAndPartials {
// 未柯里化:
static String uncurried(String a, String b) {
return a + b;
}
public static void main(String[] args) {
System.out.println(uncurried("Hi ", "Ho"));
// 柯里化函数:
Function>
sum = a -> b -> a + b; // 在这条语句中,Function中包含了一个Function
Function // 通过柯里化提供了一个参数,由此来创建一个新函数
hi = sum.apply("Hi ");
System.out.println(hi.apply("Ho"));
// 应用
Function sumHi = sum.apply("Hup ");
System.out.println(sumHi.apply("Ho"));
System.out.println(sumHi.apply("Hei"));
}
} 程序执行的结果是:

柯里化的目的是通过提供一个参数来创建一个新函数,以此获得一个“参数化函数”和剩下的“自由参数”。在这里,有两个参数的函数变为了一个单参数的函数。
还可以再添一层,对三个参数的函数进行柯里化:
import java.util.function.Function;
public class Curry3Args {
public static void main(String[] args) {
Function>>
sum = a -> b -> c -> a + b + c;
Function>
hi = sum.apply("Hi ");
Function ho = hi.apply("Ho ");
System.out.println(ho.apply("Hup"));
}
} 程序执行的结果是:
![]()
在处理基本类型和装箱时,还可以使用适当的函数式接口:
import java.util.function.IntFunction;
import java.util.function.IntUnaryOperator;
public class CurriedIntAdd {
public static void main(String[] args) {
IntFunction
curriedIntAdd = a -> b -> a + b;
IntUnaryOperator add4 = curriedIntAdd.apply(4);
System.out.println(add4.applyAsInt(5));
}
} lambda表达式和方法引用并不能将Java变成函数式语言,它们只是提供了对函数式编程风格的更多支持。