Java8实战-总结36
Java8实战-总结36
- 重构、测试和调试
-
- 调试
-
- 查看栈跟踪
- 使用日志调试
- 小结
重构、测试和调试
调试
调试有问题的代码时,程序员的兵器库里有两大老式武器,分别是:
- 查看栈跟踪
- 输出日志
查看栈跟踪
程序突然停止运行(比如突然抛出一个异常),这时首先要调查程序在什么地方发生了异常以及为什么会发生该异常。这时栈帧就非常有用。程序的每次方法调用都会产生相应的调用信息,包括程序中方法调用的位置、该方法调用使用的参数、被调用方法的本地变量。这些信息被保存在栈帧上。
程序失败时,会得到它的栈跟踪,通过一个又一个栈帧,可以了解程序失败时的概略信息。换句话说,通过这些能得到程序失败时的方法调用列表。这些方法调用列表最终会帮助发现问题出现的原因。
Lambda表达式和栈跟踪
不幸的是,由于Lambda表达式没有名字,它的栈跟踪可能很难分析。在下面这段简单的代码中,刻意地引入了一些错误:
import java.util.*;
public class Debugging {
public static void main(String[] args) {
List<Point> points = Arrays.asList(new Point(12, 2), null);
points.stream().map(p -> p.getX()).forEach(System.out::println);
}
}
运行这段代码会产生下面的栈跟踪:
Exception in thread "main" java.lang.NullPointerException
at Debugging.lambda$main$0(Debugging.java:6)
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.Spliterators$ArraySpliterator.forEachRemaining(Spliterators.java:948)
…
这段程序当然会失败,因为Points列表的第二个元素是空(null)。
这时的程序实际是在试图处理一个空引用。由于Stream流水线发生了错误,构成Stream流水线的整个方法调用序列都暴露在你面前了。不过,你留意到了吗?栈跟踪中还包含下面这样类似加密的内容:
at Debugging.lambda$main$0(Debugging.java:6)
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
这些表示错误发生在Lambda表达式内部。由于Lambda表达式没有名字,所以编译器只能为它们指定一个名字。这个例子中,它的名字是lambda$main$0,看起来非常不直观。如果使用了大量的类,其中又包含多个Lambda表达式,这就成了一个非常头痛的问题。
即使使用了方法引用,还是有可能出现栈无法显示你使用的方法名的情况。将之前的Lambda表达式p-> p.getX()替换为方法引用reference Point::getX也会产生难于分析的栈跟踪:
points.stream().map(Point::getX).forEach(System.out::println);
Exception in thread "main" java.lang.NullPointerException
at Debugging$$Lambda$5/284720968.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
…
注意,如果方法引用指向的是同一个类中声明的方法,那么它的名称是可以在栈跟踪中显示的。比如,下面这个例子:
import java.util.*;
public class Debugging{
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3);
numbers.stream().map(Debugging::divideByZero).forEach(System.out::println);
}
public static int divideByZero(int n) {
return n / 0;
}
}
方法divideByZero在栈跟踪中就正确地显示了:
Exception in thread "main" java.lang.ArithmeticException: / by zero
at Debugging.divideByZero(Debugging.java:10)
at Debugging$$Lambda$1/999966131.apply(Unknown Source)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
…
总的来说,需要特别注意,涉及Lambda表达式的栈跟踪可能非常难理解。
使用日志调试
假设试图对流操作中的流水线进行调试,该从何入手呢?可以像下面的例子那样,使用forEach将流操作的结果日志输出到屏幕上或者记录到日志文件中:
List<Integer> numbers = Arrays.asList(2, 3, 4, 5);
numbers.stream()
.map(x -> x + 17)
.filter(x -> x % 2 == 0)
.limit(3)
.forEach(System.out::println);
这段代码的输出如下:
20
22
一旦调用forEach,整个流就会恢复运行。到底哪种方式能更有效地帮助我们理解Stream流水线中的每个操作(比如map、filter、limit)产生的输出?
这就是流操作方法peek大显身手的时候。peek的设计初衷就是在流的每个元素恢复运行之前,插入执行一个动作。但是它不像forEach那样恢复整个流的运行,而是在一个元素上完成操作之后,它只会将操作顺承到流水线中的下一个操作。下图解释了peek的操作流程。下面的这段代码中,使用peek输出了Stream流水线操作之前和操作之后的中间值:
List<Integer> result = numbers.stream()
.peek(x -> System.out.println("from stream: " + x))
.map(x -> x + 17)
.peek(x -> System.out.println("after map: " + x))
.filter(x -> x % 2 == 0)
.peek(x -> System.out.println("after filter: " + x))
.limit(3)
.peek(x -> System.out.println("after limit: " + x))
.collect(toList());
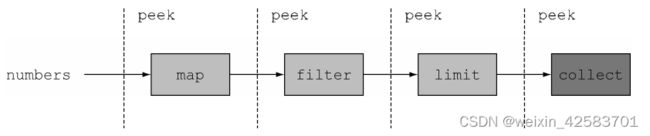
通过peek操作能清楚地了解流水线操作中每一步的输出结果:
from stream: 2
after map: 19
from stream: 3
after map: 20
after filter: 20
after limit: 20
from stream: 4
after map: 21
from stream: 5
after map: 22
after filter: 22
after limit: 22
小结
-
Lambda表达式能提升代码的可读性和灵活性。
-
如果你的代码中使用了匿名类,尽量用
Lambda表达式替换它们,但是要注意二者间语义的微妙差别,比如关键字this,以及变量隐藏。 -
跟
Lambda表达式比起来,方法引用的可读性更好 。 -
尽量使用
Stream API替换迭代式的集合处理。 -
Lambda表达式有助于避免使用面向对象设计模式时容易出现的僵化的模板代码,典型的比如策略模式、模板方法、观察者模式、责任链模式,以及工厂模式。 -
即使采用了
Lambda表达式,也同样可以进行单元测试,但是通常应该关注使用了Lambda表达式的方法的行为。 -
尽量将复杂的
Lambda表达式抽象到普通方法中。 -
Lambda表达式会让栈跟踪的分析变得更为复杂。 -
流提供的
peek方法在分析Stream流水线时,能将中间变量的值输出到日志中,是非常有用的工具。