sql数据类型,约束以及单表查询
嘎嘎学撒
- 数据类型
- 约束条件
- DML 数据操作语句
-
- 一、插入数据INSERT
- 二、更新数据UPDATE
- 三、删除数据DELETE
- 四、MySQL单表查询
- 五、关键词
数据类型
常见的数据类型
数值类型:
整数类型 TINYINT SMALLINT MEDIUMINT INT BIGINT
整型可以指定是有符号的和无符号的,默认是有符号的
可以通过UNSIGNED来说明某个字段是无符号的。
浮点数类型 FLOAT DOUBLE
字符串类型:
CHAR系列 CHAR VARCHAR
BINARY系列 BINARY VARBINARY
枚举类型: ENUM
集合类型: SET
时间和日期类型:
DATE TIME DATETIME TIMESTAMP YEAR
基本上主要分为数值类型,浮点数类型,字符串类型和其他类型的
注意事项:
# 整数类型
int(5) # 这个的话,指定int显示5位,并不是说 int 只能插入5位 在我测试的时候,创建表字段的时候 int 制定了 3 位 ,但是查看表结构的时候,mysql8.0版本以上显示不了,5版本的可以显示
# 上面这个6位以上的也可以添加,也不受影响
# 浮点型
float(5,3) # 这个的制定了精读,整数两位,小数三位,(5,3) 这个5表示一共有这么多位,3 表示小数有三位
# 浮点数和定点数都可以用类型名称后加(M,D)的方式来表示,(M,D)表示一共显示M位数字(整数位
+小数位),其中D位于小数点后面,M和D又称为精度和标度。
# 如上,添加一个 5.4567 在数据库中会显示 5.458 失去精度的时候四舍五入
# CHAR、VARCHAR
# 作用:用于存储用户的姓名、爱好、发布的文章等
# CHAR 列的长度固定为创建表时声明的长度: 0 ~ 255
# VARCHAR 列中的值为可变长字符串,长度: 0 ~ 65535
# 注:在检索的时候,CHAR列删除了尾部的空格,而VARCHAR则保留这些空格
# 字符串类型
# ENUM类型即枚举类型、集合类型SET测试
# 字段的值只能在给定范围中选择
# 常见的是单选按钮和复选框
enum # 单选 只能在给定的范围内选一个值,如性别 sex 男male/女female
set # 多选 在给定的范围内可以选择一个或一个以上的值(爱好1,爱好2,爱好3...)
约束条件
约束条件 说明
- NULL 标识是否允许为空,默认为NULL。
- NOT NULL 标识该字段不能为空,可以修改。
- UNIQUE KEY (UK) 标识该字段的值是唯一的,可以为空,一个表中可以有多个UNIQUE KEY
- DEFAULT 为该字段设置默认值
- UNSIGNED 无符号,正数
- PRIMARY KEY (PK) 标识该字段为该表的主键,可以唯一的标识记录,不可以为空
- AUTO_INCREMENT 标识该字段的值自动增长(整数类型,而且为主键) 自增键,每张表只能一个字段为自增
- UNIQUE + NOT NULL 唯一,不能为空
- FOREIGN KEY (FK) 标识该字段为该表的外键,实现表与表(父表主键/子表1外键/子表2外键)之间的关联
- ZEROFULL 补全0 适合int制定显示位数的时候
DML 数据操作语句
在MySQL管理软件中,可以通过SQL语句中的DML语言来实现数据的操作,包括使用INSERT实现数据
的插入、DELETE实现数据的删除以及UPDATE实现数据的更新。
更新数据 insert
更新数据 update
删除数据 delete
一、插入数据INSERT
1. 插入完整数据(顺序插入)
语法一:
INSERT INTO 表名(字段1,字段2,字段3…字段n) VALUES (值1,值2,值3…值n);
语法二:
INSERT INTO 表名 VALUES (值1,值2,值3…值n);
2. 指定字段插入数据
语法:
INSERT INTO 表名(字段2,字段3…) VALUES (值2,值3…);
3. 插入多条记录
语法:
INSERT INTO 表名 VALUES
(值1,值2,值3…值n),
(值1,值2,值3…值n),
(值1,值2,值3…值n);
4. 插入查询结果
语法:
INSERT INTO 表1(字段1,字段2,字段3…字段n)
SELECT (字段1,字段2,字段3…字段n) FROM 表2
WHERE …;
二、更新数据UPDATE
语法:
UPDATE 表名 SET 字段1=值1,字段2=值2 WHERE CONDITION;
三、删除数据DELETE
语法:
DELETE FROM 表名
WHERE CONITION;
示例:
DELETE FROM mysql.user
WHERE authentication_string=’’;
delete from 表名 WHERE 条件;
四、MySQL单表查询
SELECT 字段名称,字段名称2 from 表名 条件
# 避免重复DISTINCT
SELECT DISTINCT post FROM employee5;
# 定义显示格式
# CONCAT() 函数用于连接字符串
SELECT CONCAT(name, ' annual salary: ', salary*14) AS Annual_salary FROM employee5;
五、关键词
# where
select * from 表名 where 条件
el:
select * from so where id = 1
# 上面这个sql语句的意思是 查询 so表中 id =1 的全部信息
# 多条件查询使用 and 链接 el:
select * from so where id = 1 and sex = '男'
# 上面这个sql语句的意思是 查询 so表中 id =1 和 sex = ‘男’ 的全部信息
-----------------------------------------------------------------
# BETWEEN AND
select * from 表名 where 字段名 between x and y
el:
select * from so where id between 1 and 10
# 查询so表中 id范围在 1 到 10 之间的所有信息
-----------------------------------------------------------------
# IS NULL
select * from 表名 where 字段名 is null
select * from 表名 where 字段名 is not null
select * from 表名 where 字段名 = ''
el:
SELECT * FROM e WHERE name IS NULL;
# 上面 查询e表中name为空的所有信息
SELECT * FROM e WHERE name IS NOT NULL;
# 上面 查询e表中name为不为空的所有信息
SELECT * FROM e WHERE name='';
# 上面 查询e表中name为‘’(空字符串,并不是 null)的所有信息
NULL说明:
1、等价于没有任何值、是未知数。
2、NULL与0、空字符串、空格都不同,NULL没有分配存储空间。
3、对空值做加、减、乘、除等运算操作,结果仍为空。
4、比较时使用关键字用“is null”和“is not null”。
5、排序时比其他数据都小,所以NULL值总是排在最前。
-----------------------------------------------------------------
# 关键字IN集合查询
SELECT name, salary FROM employee5 WHERE salary=4000 OR salary=5000 OR salary=6000 OR salary=9000;
# 上面这个等同于下面这个sql语句 in的意思是只要salary满足其中一个,则将符合的记录查询出来
SELECT name, salary FROM employee5 WHERE salary IN (4000,5000,6000,9000) ;
# 下面则是查询salary不等于 4000,5000,6000,9000的记录
SELECT name, salary FROM employee5 WHERE salary NOT IN (4000,5000,6000,9000) ;
-----------------------------------------------------------------
# 排序查询 order by
select * from 表名 order by 字段 asc(默认值,可不写) # 默认是升序排序
select * from 表名 order by 字段 desc # 降序排序
# 某表通过某个字段降序/升序进行排序查询
-----------------------------------------------------------------
# limit 限制查询结果的返回数量 也被称为分页查询
select * from 表名 limit n,m
el:
select * from a limit 3,3;
# 查询a表中从第四条数据开始的三条数据
limit 3,3
# 第一个 3 偏移量 偏移量为0的时候是从第一条数据开始显示的
# 第二个3是显示几条数据
----------------------------------------------------------------
# 分组查询
# GROUP BY和GROUP_CONCAT()函数一起使用
select group_concat(name), class_id from student group by class_id;
# 这个的话,你们自己试一试,很厉害的
select group_concat(字段1), 字段2 from student group by 字段2;
# 为 字段2 进行分组
# 练习的表 下面是sql语句
CREATE TABLE company.employee5(
id int primary key AUTO_INCREMENT not null,
name varchar(30) not null,
sex enum('male','female') default 'male' not null,
hire_date date not null,
post varchar(50) not null,
job_description varchar(100),
salary double(15,2) not null,
office int,
dep_id int
);
insert into company.employee5(name,sex,hire_date,post,job_description,salary,office,dep_id) values
('jack','male','20180202','instructor','teach',5000,501,100),
('tom','male','20180203','instructor','teach',5500,501,100),
('robin','male','20180202','instructor','teach',8000,501,100),
('alice','female','20180202','instructor','teach',7200,501,100),
('tianyun','male','20180202','hr','hrcc',600,502,101),
('harry','male','20180202','hr',NULL,6000,502,101),
('emma','female','20180206','sale','salecc',20000,503,102),
('christine','female','20180205','sale','salecc',2200,503,102),
('zhuzhu','male','20180205','sale',NULL,2200,503,102),
('gougou','male','20180205','sale','',2200,503,102);
# 可以试试下面这个分组查询的sql语句
SELECT dep_id,GROUP_CONCAT(name) FROM employee5 GROUP BY dep_id;
SELECT dep_id,GROUP_CONCAT(name) as emp_members FROM employee5 GROUP BY dep_id;
---------------------------------------------------------------------
# 模糊查询(通配符)
# % 所有字符
SELECT * from employee5 WHERE salary like '%20%';
---------------------------------------------------------------------
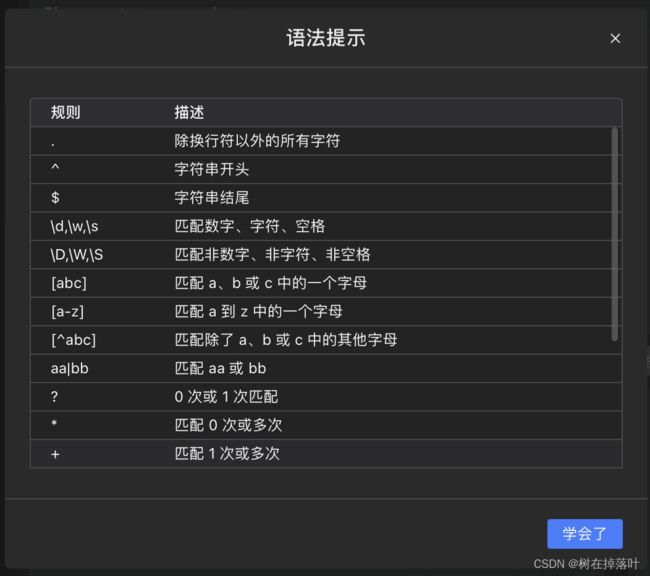
# 正则查询 后面有一个简单的正则表达式的规则,可以了解了解
SELECT * FROM employee5 WHERE salary regexp '72+';
SELECT * FROM employee5 WHERE name REGEXP '^ali';
SELECT * FROM employee5 WHERE name REGEXP 'yun$';
SELECT * FROM employee5 WHERE name REGEXP 'm{2}';
---------------------------------------------------------------------
# 函数
count()
max()
min()
avg()
database()
user()
now()
sum()
password()
正则规则