面试04——整理
1.抽象类怎么模拟接口
2.项目负责
3.线程与进程
4.List list =new Arraylist(Array.aslist(“a”,“b”,“c”,“d”));
for(s:list){
s.equls(“a”){
s.removes()
}
}
5.io 异常关闭 应该在哪里关闭
6.public class test{
private int value;
public void get(int x){
this.value=x
}
public void increment(){
++this.value;
}
}
7.设备怎么管理,设备是从哪里来的。
设备怎么接受我们发送的消息。
项目文档
接口文档有软件自动生成
kafka组件有哪些
http https 区别
项目怎么部署部署流程
netty
explain
sql 索引怎么优化sql
悲观锁乐观锁
字符串反转 用revers 位与运算符
常用的容器类型
并发容器
jdk 动态代理,class文件缓存在内存,在运行时动态生成代理类进行处理的,只能基于接口进行代理。
cglib 动态代理,是通过继承代理,
还有就是jdk 只能接口进行代理,局限性
cglib 可以代理类
个人觉得局限性在与一个只能通过类进行代理类处理,但是呢cglib可以对方法,比如说一些逻辑组件处理,使用代理类处理。然后逻辑组件再用切面可以适配所有方法。我感觉很爽
所以一般我再写切面处理日志或者一些解耦的东西都是用cglib处理的
可见性
对于可见性,Java提供了volatile关键字来保证可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。
另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
有序性
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”(具体原理在下一节讲述)。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
volatile本质是在告诉jvm当前变量在寄存器中的值是不确定的,需要从主存中读取,synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住.
volatile仅能使用在变量级别,synchronized则可以使用在变量,方法.
volatile仅能实现变量的修改可见性,但不具备原子特性,而synchronized则可以保证变量的修改可见性和原子性.
volatile不会造成线程的阻塞,而synchronized可能会造成线程的阻塞.
volatile标记的变量不会被编译器优化,而synchronized标记的变量可以被编译器优化.
synchronized很强大,既可以保证可见性,又可以保证原子性,而volatile不能保证原子性!
出于运行速率的考虑,java编译器会把经常经常访问的变量放到缓存(严格讲应该是工作内存)中,读取变量则从缓存中读。但是在多线程编程中,内存中的值和缓存中的值可能会出现不一致。volatile用于限定变量只能从内存中读取,保证对所有线程而言,值都是一致的。但是volatile不能保证原子性,也就不能保证线程安全。
select * from (select * from 表名 order by 字段 desc limit 10) 临时表 order by 字段
1. 服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其他的微服务,这就是所谓的扇出。如果在扇出的链路上某个微服务的调用响应式过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统雪崩,所谓的”雪崩效应”。
2. 服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制,当扇出链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务响应正常后,恢复调用链路。
3. 服务降级
服务降级,就是当某个服务熔断之后,服务将不再被调用,此刻客户端需要执行备用的逻辑,返回一个缺省值。
synchronized
“就是因为synchronized性能低,有人就开发了ReentrantLock,大大提高了性能,其中涉及到了AQS高并发组件,用它来维护锁的状态等,这样就不需要利用操作系统来维护,减少上下文切换,做到了基本在Java级别上就能完成操作。里面还用了CAS,自旋等操作来提高性能。但是线程过…”
解释为什么jdk1.6以前synchronized是重量级锁,性能低下的原因?
为啥是重量级锁?
在这个版本之前,加锁的操作是涉及到操作系统进行互斥操作,就是会把当前线程挂起,然后操作系统进行互斥操作修改,由mutexLock来完成,之后才唤醒。操作系统来判断线程是否加锁,所以它是一个重量级操作。挂起、唤醒这两个操作进行了两次上下文切换,消耗CPU,降低性能。其实在这个版本之前已经考虑到CAS操作,但是默认是没有开启的。
当然,除了操作系统维护锁的状态使当前线程挂起外,只要是synchronized,一有竞争也会引起阻塞,阻塞和唤醒操作又涉及到了上下文操作,大量消耗CPU,降低性能。
ResultMap和ResultType的
ResultMap和ResultType的功能类似,但是ResultMap更强大一点,ResultMap可以实现将查询结果映射为复杂类型的pojo。
@Transactional失效场景
声明式事务失效的场景有很多,陈某这里只是罗列一下几种常见的场景。
底层数据库引擎不支持事务
如果数据库引擎不支持事务,则Spring自然无法支持事务。
在非public修饰的方法使用
@Transactional注解使用的是AOP,在使用动态代理的时候只能针对public方法进行代理
在整个事务的方法中使用try-catch,导致异常无法抛出,自然会导致事务失效。
方法中调用同类的方法
- 简单的说就是一个类中的
A方法(未标注声明式事务)在内部调用了B方法(标注了声明式事务),这样会导致B方法中的事务失效。
原始SSM项目,重复扫描导致事务失效
在原始的SSM项目中都配置了context:component-scan并且同时扫描了service层,此时事务将会失效。
按照Spring配置文件的加载顺序来说,会先加载Springmvc的配置文件,如果在加载Springmvc配置文件的时候把service也加载了,但是此时事务还没加载,将会导致事务无法成功生效。
juc包下四大并发工具
解决方法很简单,把扫描service层的配置设置在Spring配置文件或者其他配置文件中即可juc.CountDownLatch 闭锁
一个线程在等待一组线程后再恢复执行
ConcurrentHashMap
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作。并发控制使⽤synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但
是已经简化了属性,只是为了兼容旧版本;
JDK1.8的Nod节点中value和next都用volatile修饰,保证并发的可见性。
我们知道,当前的应用都离不开数据库,随着数据库中的数据越来越多,单表突破性能上限记录时,如MySQL单表上线估计在近千万条内,当记录数继续增长时,从性能考虑,则需要进行拆分处理。而拆分分为横向拆分和纵向拆分。一般来说,采用横向拆分较多,这样的表结构是一致的,只是不同的数据存储在不同的数据库表中。其中横向拆分也分为分库和分表。
为什么决定进行分库分表
\1. 根据业务类型,和业务容量的评估,来选择和判断是否使用分库分表。
\2. 当前数据库本事具有的能力,压力的评估。
\3. 数据库的物理隔离,例如减少锁的争用、资源的消耗和隔离等。
\4. 热点表较多,并且数据量大,可能会导致锁争抢,性能下降。
\5. 数据库的高并发,数据库的读写压力过大,可能会导致数据库或系统宕机。
\6. 数据库(MySQL5.7以下)连接数过高,会增加系统压力。
\7. 单表数据量大,如SQL使用不当,会导致io随机读写比例高。查询慢(大表上的B+树太大,扫描太慢,甚至可能需要4层B+树)
\8. 备份和恢复时间比较长。
作者:阿里技术
链接:https://www.zhihu.com/question/448775613/answer/1774351830
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1 什么是分库分表?
其实就是字面意思,很好理解:
- 分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
- 分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
2 为什么要分库分表?
关键字:提升性能、增加可用性。
从性能上看
随着单库中的数据量越来越大、数据库的查询QPS越来越高,相应的,对数据库的读写所需要的时间也越来越多。数据库的读写性能可能会成为业务发展的瓶颈。对应的,就需要做数据库性能方面的优化。本文中我们只讨论数据库层面的优化,不讨论缓存等应用层优化的手段。
如果数据库的查询QPS过高,就需要考虑拆库,通过分库来分担单个数据库的连接压力。比如,如果查询QPS为3500,假设单库可以支撑1000个连接数的话,那么就可以考虑拆分成4个库,来分散查询连接压力。
如果单表数据量过大,当数据量超过一定量级后,无论是对于数据查询还是数据更新,在经过索引优化等纯数据库层面的传统优化手段之后,还是可能存在性能问题。这是量变产生了质变,这时候就需要去换个思路来解决问题,比如:从数据生产源头、数据处理源头来解决问题,既然数据量很大,那我们就来个分而治之,化整为零。这就产生了分表,把数据按照一定的规则拆分成多张表,来解决单表环境下无法解决的存取性能问题。
从可用性上看
单个数据库如果发生意外,很可能会丢失所有数据。尤其是云时代,很多数据库都跑在虚拟机上,如果虚拟机/宿主机发生意外,则可能造成无法挽回的损失。因此,除了传统的 Master-Slave、Master-Master 等部署层面解决可靠性问题外,我们也可以考虑从数据拆分层面解决此问题。
此处我们以数据库宕机为例:
- 单库部署情况下,如果数据库宕机,那么故障影响就是100%,而且恢复可能耗时很长。
- 如果我们拆分成2个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是50%,还有50%的数据可以继续服务。
- 如果我们拆分成4个库,分别部署在不同的机器上,此时其中1个库宕机,那么故障影响就是25%,还有75%的数据可以继续服务,恢复耗时也会很短。
当然,我们也不能无限制的拆库,这也是牺牲存储资源来提升性能、可用性的方式,毕竟资源总是有限的。
二 如何分库分表
1 分库?分表?还是既分库又分表?
从第一部分了解到的信息来看,分库分表方案可以分为下面3种:


2 如何选择我们自己的切分方案?
如果需要分表,那么分多少张表合适?
由于所有的技术都是为业务服务的,那么,我们就先从数据方面回顾下业务背景。
比如,我们这个业务系统是为了解决会员的咨询诉求,通过我们的XSpace客服平台系统来服务会员,目前主要以同步的离线工单数据作为我们的数据源来构建自己的数据。
假设,每一笔离线工单都会产生对应一笔会员的咨询问题(我们简称:问题单),如果:
- 在线渠道:每天产生 3w 笔聊天会话,假设,其中50%的会话会生成一笔离线工单,那么每天可生成 3w * 50% = 1.5w 笔工单;
- 热线渠道:每天产生 2.5w 通电话,假设,其中80%的电话都会产生一笔工单,那么每天可生成 2.5w * 80% = 2w 笔/天;
- 离线渠道:假设离线渠道每天直接生成 3w 笔;
合计共 1.5w + 2w + 3w = 6.5w 笔/天
考虑到以后可能要继续覆盖的新的业务场景,需要提前预留部分扩展空间,这里我们假设为每天产生 8w 笔问题单。
除问题单外,还有另外2张常用的业务表:用户操作日志表、用户提交的表单数据表。
其中,每笔问题单都会产生多条用户操作日志,根据历史统计数据来可以看到,平均每个问题单大约会产生8条操作日志,我们预留一部分空间,假设每个问题单平均产生约10条用户操作日志。
如果系统设计使用年限5年,那么问题单数据量大约 = 5年 365天/年 8w/天 = 1.46亿,那么估算出的表数量如下:
- 问题单需要:1.46亿/500w = 29.2 张表,我们就按 32 张表来切分;
- 操作日志需要 :32 10 = 320 张表,我们就按 32 16 = 512 张表来切分。
如果需要分库,那么分多少库合适?
分库的时候除了要考虑平时的业务峰值读写QPS外,还要考虑到诸如双11大促期间可能达到的峰值,需要提前做好预估。
根据我们的实际业务场景,问题单的数据查询来源主要来自于阿里客服小蜜首页。因此,可以根据历史QPS、RT等数据评估,假设我们只需要3500数据库连接数,如果单库可以承担最高1000个数据库连接,那么我们就可以拆分成4个库。
3 如何对数据进行切分?
根据行业惯例,通常按照 水平切分、垂直切分 两种方式进行切分,当然,有些复杂业务场景也可能选择两者结合的方式。
(1)水平切分
这是一种横向按业务维度切分的方式,比如常见的按会员维度切分,根据一定的规则把不同的会员相关的数据散落在不同的库表中。由于我们的业务场景决定都是从会员视角进行数据读写,所以,我们就选择按照水平方式进行数据库切分。
(2)垂直切分
垂直切分可以简单理解为,把一张表的不同字段拆分到不同的表中。
比如:假设有个小型电商业务,把一个订单相关的商品信息、买卖家信息、支付信息都放在一张大表里。可以考虑通过垂直切分的方式,把商品信息、买家信息、卖家信息、支付信息都单独拆分成独立的表,并通过订单号跟订单基本信息关联起来。
也有一种情况,如果一张表有10个字段,其中只有3个字段需要频繁修改,那么就可以考虑把这3个字段拆分到子表。避免在修改这3个数据时,影响到其余7个字段的查询行锁定。
sql查询数据库最后10条记录并按降序排列
SELECT TOP 10 FROM 表名 ORDER BY 排序列 DESC;SQL的执行顺序先按照你的要求排序,然后才返回查询的内容。例如有一个名为ID自动增长的列,表中有100条数据,列的值得分别是1、2、3、4………9、99、100。那么查询加了DESC你得到的是91到100条,就是最后十条,如果加ASC你得到的将会是1到10,也就是最前面的那几条。记录如果说有先后的话 必然是根据某几个字段进行排序了的你反过来排序就变成求前10条记录了呗,把desc和 asc互换一下 (默认是 asc )oracle 的写法select * from (select * from tab order by col desc ) where rownum <= 10赞同最后10条降序与最前10条升序是一样的如果还想排序,那就按他们说的用临时表。select top 10 * from table 1 order by field1 into table #tempselect * from #temp order by field1 desc //查询结果放临时表select * top 10 from table1 order by field1 asc into tabl temp //再从临时表查询select * from temp order by field1 desc
一.git提交代码步骤
1.拉取远程的代码,先pull,查看有哪些差异。 git pull
2.备份自己的文件,把所有差异还原。
3.再次pull,成功后在具体的文件中,把自己的代码粘贴复制过去,再次pull。
4.提交代码到本地 git add . git commit -m ‘修改注释’
5.推送代码到远程
备注:(1)如果是新增的文件,需要先新增,再从第2步开始。
(2)第2/3步骤适用于不会解决冲突的人。
二.工作中常用的git命令
1.回退历史版本
(1)git log 查看提交记录 copy 历史版本id
(2)git reset --hard 复制的历史版本id
(3)如果是取消最近一次的commit 保留本地文件修改 git reset HEAD
(4)回退并推送至远程分支 git push -f origin master
2.回退某个文件
(1)到该文件的文件夹下,打开命令面板
(2)git log 文件名.文件格式
(3)git reset 版本号 文件名.文件格式
(4)如果还想远程也回退版本 git push -f
(5)如果需要放弃本地该文件的修改 git checkout .
3.删除缓存的远程分支列表
(1)git remote prune origin
(2)git fetch -p
(3)git checkout . && git clean -xdf 抛弃本地修改
4.创建分支
在哪个分支运行的命令,就是从哪个分支为基础拉新的分支。
(1)git checkout -b dev 创建dev分支并切换到dev分支
相当于 git branch dev 与 git checkout dev 两个命令
(2)git push origin dev 把dev分支推送至远程
(3)git branch --set-upstream-to origin/dev 把本地当前的分支与远程dev分支 然后就可以用git push 推送代码到远程dev分支了
5.合并分支
切换到想要合并其他分支的分支 一般为master
(1)git checkout master
(2)git merge dev 合并dev分支到master
(3)如果合并之后 dev分支没用了 ,删除dev分支 git branch -d dev
6.添加远程分支
fork代码到私人仓库,从私有仓库拉取的代码后,需要添加远程分支
git remote add 本地远程仓库名称(自己起的有意义能识别的名称) remote-http-adress(远程仓库的克隆地址)
比如远程仓库命名为 remoteApp 仓库地址为http://remote.com,那么命令为:git remote add remoteApp http://remote.com
7.拉取远程分支代码
git pull remoteName branchName
比如git pull remoteApp master
8.查看有哪些分支
git branch -a a可以理解为all 所有
9.git pull出现合并的提示消息,按照如下图片操作,忘记在哪个博客截图的图片了,非原创。
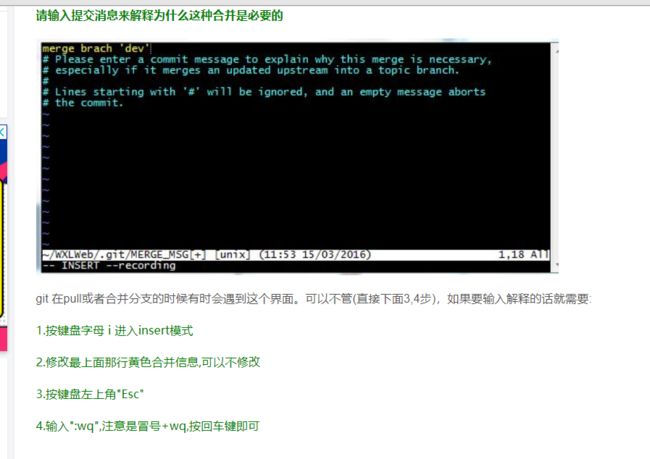
10.修改分支命名
(1)如果还没有推送到远程:git branch -m oldName newName
(2)已经推送到了远程:
1)重命名远程分支对于的本地分支 git branch -m oldName newName
2)删除远程分支 git push --delete origin oldName
3)上传新命名的本地分支 git push origin newName
4)把修改过后的本地分支与远程分支关联 git branch --set-upstream-to origin/newName
CAS
、对于资源竞争较少的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
2、对于资源竞争严重的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。以
死锁的条件
1、互斥条件:一个资源每次只能被一个进程使用;
2、请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放;
3、不剥夺条件:进程已获得的资源,在末使用完之前,不能强行剥夺;
4、循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系;
死锁概念及产生原理
概念: 多个并发进程因争夺系统资源而产生相互等待的现象。
原理: 当一组进程中的每个进程都在等待某个事件发生,而只有这组进程中的其他进程才能触发该事件,这就称这组进程发生了死锁。
本质原因:
1)、系统资源有限。
2)、进程推进顺序不合理。
死锁产生的4个必要条件
1、互斥: 某种资源一次只允许一个进程访问,即该资源一旦分配给某个进程,其他进程就不能再访问,直到该进程访问结束。
2、占有且等待: 一个进程本身占有资源(一种或多种),同时还有资源未得到满足,正在等待其他进程释放该资源。
3、不可抢占: 别人已经占有了某项资源,你不能因为自己也需要该资源,就去把别人的资源抢过来。
4、循环等待: 存在一个进程链,使得每个进程都占有下一个进程所需的至少一种资源。
当以上四个条件均满足,必然会造成死锁,发生死锁的进程无法进行下去,它们所持有的资源也无法释放。这样会导致CPU的吞吐量下降。所以死锁情况是会浪费系统资源和影响计算机的使用性能的。那么,解决死锁问题就是相当有必要的了。
避免死锁的几种方式:
设置加锁顺序
设置加锁时限
死锁检测
设置加锁顺序(线程按照一定的顺序加锁):
死锁发生在多个线程需要相同的锁,但是获得不同的顺序。
假如一个线程需要锁,那么他必须按照一定得顺序获得锁。
例如加锁顺序是A->B->C,现在想要线程C想要获取锁,那么他必须等到线程A和线程B获取锁之后才能轮到他获取。(排队执行,获取锁)
缺点:
按照顺序加锁是一种有效的死锁预防机制。但是,这种方式需要你事先知道所有可能会用到的锁,并知道他们之间获取锁的顺序是什么样的。
设置加锁时限:(超时重试)
在获取锁的时候尝试加一个获取锁的时限,超过时限不需要再获取锁,放弃操作(对锁的请求。)。
若一个线程在一定的时间里没有成功的获取到锁,则会进行回退并释放之前获取到的锁,然后等待一段时间后进行重试。在这段等待时间中其他线程有机会尝试获取相同的锁,这样就能保证在没有获取锁的时候继续执行比的事情。
缺点:
但是由于存在锁的超时,通过设置时限并不能确定出现了死锁,每种方法总是有缺陷的。有时为了执行某个任务。某个线程花了很长的时间去执行任务,如果在其他线程看来,可能这个时间已经超过了等待的时限,可能出现了死锁。
在大量线程去操作相同的资源的时候,这个情况又是一个不可避免的事情,比如说,现在只有两个线程,一个线程执行的时候,超过了等待的时间,下一个线程会尝试获取相同的锁,避免出现死锁。但是这时候不是两个线程了,可能是几百个线程同时去执行,大的基数让事件出现的概率变大,假如线程还是等待那么长时间,但是多个线程的等待时间就有可能重叠,因此又会出现竞争超时,由于他们的超时发生时间正好赶在了一起,而超时等待的时间又是一致的,那么他们下一次又会竞争,等待,这就又出现了死锁。
死锁检测:
当一个线程获取锁的时候,会在相应的数据结构中记录下来,相同下,如果有线程请求锁,也会在相应的结构中记录下来。当一个线程请求失败时,需要遍历一下这个数据结构检查是否有死锁产生。
例如:线程A请求锁住一个方法1,但是现在这个方法是线程B所有的,这时候线程A可以检查一下线程B是否已经请求了线程A当前所持有的锁,像是一个环,线程A拥有锁1,请求锁2,线程B拥有锁2,请求锁1。
当遍历这个存储结构的时候,如果发现了死锁,一个可行的办法就是释放所有的锁,回退,并且等待一段时间后再次尝试。
缺点:
这个这个方法和上面的超时重试的策略是一样的。但是在大量线程的时候问题还是会出现和设置加锁时限相同的问题。每次线程之间发生竞争。
预防死锁
还有一种解决方法是设置线程优先级,这样其中几个线程回退,其余的线程继续保持着他们获取的锁,也可以尝试随机设置优先级,这样保证线程的执行。
数据的锁定分为两种,第一种叫作悲观锁,第二种叫作乐观锁。
1、悲观锁,就是对数据的冲突采取一种悲观的态度,也就是说假设数据肯定会冲突,所以在数据开始读取的时候就把数据锁定住。【数据锁定:数据将暂时不会得到修改】
2、乐观锁,认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让用户返回错误的信息。让用户决定如何去做。
乐观锁
理解:
- 乐观锁是一种思想,具体实现是,表中有一个版本字段,第一次读的时候,获取到这个字段。处理完业务逻辑开始更新的时候,需要再次查看该字段的值是否和第一次的一样。如果一样更新,反之拒绝。
之所以叫乐观,因为这个模式没有从数据库加锁。
- 悲观锁是读取的时候为后面的更新加锁,之后再来的读操作都会等待。这种是数据库锁
乐观锁优点程序实现,不会存在死锁等问题。他的适用场景也相对乐观。阻止不了除了程序之外的数据库操作。
悲观锁是数据库实现,他阻止一切数据库操作。
再来说更新数据丢失,所有的读锁都是为了保持数据一致性。乐观锁如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户从新操作。悲观锁则会等待前一个更新完成。这也是区别。具体业务具体分析
MySQL的四种事务隔离级别
本文实验的测试环境:Windows 10+cmd+MySQL5.6.36+InnoDB
一、事务的基本要素(ACID)
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
**2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
**
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
二、事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
**1、事务隔离级别为读提交时,写数据只会锁住相应的行****
2*、事务隔离级别为可重复读时,如果检索条件有索引(包括主键索引)的时候,默认加锁方式是next-key 锁;如果****检索条件****没有索引,更新数据时会锁住整张表。一个间隙被事务加了锁,其他事务是不能在这个间隙插入记录的,这样可以防止幻读。*
3、事务隔离级别为串行化时,读写数据都会锁住整张表
4*、隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。*
Java并发编程:volatile关键字解析
如何保证Redis和数据库双写一致性的问题?
Redis在国内各大公司都很热门,比如新浪、阿里、腾讯、百度、美团、小米等。Redis也是大厂面试最爱问的,尤其是Redis客户端、Redis高级功能、Redis持久化和开发运维常用问题探讨、Redis复制的原理和优化策略、Redis分布式解决方案等。
关于Redis的这8问,你能答上来几个?
1、为什么使用Redis
项目中使用Redis,主要考虑性能和并发。如果仅仅是分布式锁这些,完全可以用中间件ZooKeeper等代替。
性能:
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用Redis做一个缓冲操作,让请求先访问到Redis,而不是直接访问数据库。
根据交互效果的不同,响应时间没有固定标准。在理想状态下,我们的页面跳转需要在瞬间解决,对于页内操作则需要在刹那间解决。
并发:
如下图所示,在大并发的情况下,所有的请求直接访问数据库,数据库会出现连接异常。这个时候,就需要使用Redis做一个缓冲操作,让请求先访问到Redis,而不是直接访问数据库。
2、使用Redis有什么缺点?
缓存和数据库双写一致性问题
缓存雪崩问题
缓存击穿问题
缓存的并发竞争问题
3、单线程的Redis为什么这么快?
你知道Redis是单线程工作模型吗?
纯内存操作
单线程操作,避免了频繁的上下文切换
采用了非阻塞I/O多路复用机制
4、Redis的数据类型及使用场景
(这5种类型你用到过几个?)
String:一般做一些复杂的计数功能的缓存;
Hash:单点登录;
List:做简单的消息队列的功能;
Set:做全局去重的功能;
SortedSet:做排行榜应用,取TOPN操作;延时任务;做范围查找。
5、Redis过期策略和内存淘汰机制?
正解:Redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定期删除+惰性删除是如何工作的呢?
采用定期删除+惰性删除就没其他问题了么?
6、Redis和数据库双写一致性问题
(最终一致性和强一致性)
如果对数据有强一致性要求,不能放缓存。
7、如何应对缓存穿透和缓存雪崩问题
缓存穿透:即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
缓存雪崩:即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
中小型的公司一般遇不到这些问题,但是大并发的项目,流量有几百万左右,这两个问题一定要深刻考虑。
8、如何解决Redis并发竞争Key问题?
这个问题大致就是,同时有多个子系统去set一个key。不太推荐使用redis的事务机制。
(1)如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可。
(2)如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.
期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法,比如利用队列,将set方法变成串行访问也可以。总之,灵活变通。
烟哥彩蛋
在面试中如果碰到下列问题,如何应用上本篇的知识呢?先明确一点,我推荐的是Redis Cluster。
OK,开始举例说明
问题1:懂Redis事务么?
正常版:Redis事务是一些列redis命令的集合,blabla…
高调版: 我们在生产上采用的是Redis Cluster集群架构,不同的key是有可能分配在不同的Redis节点上的,在这种情况下Redis的事务机制是不生效的。其次,Redis事务不支持回滚操作,简直是鸡肋!所以基本不用!
问题2:Redis的多数据库机制,了解多少?
正常版:Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,单机下的redis可以支持16个数据库(db0 ~ db15)
高调版: 在Redis Cluster集群架构下只有一个数据库空间,即db0。因此,我们没有使用Redis的多数据库功能!
问题3:Redis集群机制中,你觉得有什么不足的地方吗?
正常版: 不知道
高调版: 假设我有一个key,对应的value是Hash类型的。如果Hash对象非常大,是不支持映射到不同节点的!只能映射到集群中的一个节点上!还有就是做批量操作比较麻烦!
问题4:懂Redis的批量操作么?
正常版: 懂一点。比如mset、mget操作等,blabla
高调版: 我们在生产上采用的是Redis Cluster集群架构,不同的key会划分到不同的slot中,因此直接使用mset或者mget等操作是行不通的。
问题5:那在Redis集群模式下,如何进行批量操作?
正常版:不知道
高调版:这个问题其实可以写一篇文章了,改天写。这里说一种有一个很简单的答法,足够面试用。即:
如果执行的key数量比较少,就不用mget了,就用串行get操作。如果真的需要执行的key很多,就使用Hashtag保证这些key映射到同一台Redis节点上。简单来说语法如下
对于key为{foo}.student1、{foo}.student2,{foo}student3,这类key一定是在同一个redis节点上。因为key中“{}”之间的字符串就是当前key的hash tags, 只有key中{ }中的部分才被用来做hash,因此计算出来的redis节点一定是同一个!
ps:如果你用的是Proxy分片集群架构,例如Codis这种,会将mget/mset的多个key拆分成多个命令发往不同得Redis实例,这里不多说。我推荐答的还是Redis Cluster。
问题6:你们有对Redis做读写分离么?
正常版:没有做,至于原因额。。。额。。。额。。没办法了,硬着头皮扯~
高调版:不做读写分离。我们用的是Redis Cluster的架构,是属于分片集群的架构。而Redis本身在内存上操作,不会涉及IO吞吐,即使读写分离也不会提升太多性能,Redis在生产上的主要问题是考虑容量,单机最多10-20G,key太多降低Redis性能.因此采用分片集群结构,已经能保证了我们的性能。其次,用上了读写分离后,还要考虑主从一致性,主从延迟等问题,徒增业务复杂度。
list遍历并删除
public void testDel() {
List list = Lists.newArrayList();
list.add(1);
list.add(2);
list.add(2);
list.add(2);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Integer integer = iterator.next();
if (integer == 2)
iterator.remove();
}
}
LeetCode(3):无重复字符的最长子串
“SpringCloud和Dubbo都是当下流行的RPC框架,各自都集成了服务发现和治理组件。SpringCloud用Eureka,Dubbo用Zookeeper。”
单一应用架构,当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的 数据访问框架(ORM)是关键。
垂直应用架构,当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的 Web框架(MVC)是关键。
分布式服务架构,当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的 分布式服务框架(RPC)是关键。
流动计算架构当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的 资源调度和治理中心(SOA)是关键。
-
理解为啥说“http协议一般会使用JSON报文,消耗会更大”?可以解释一下吗?
-
数据底层是二进制流,直来直往快一些,无论是json还是xml都需要转换,会影响速率
-
json和xml这些都是字符了,而且里面的很多内容都是多余的,这种格式很直白但是效率不高,不如直接基于字节的协议
-
1、dubbo由于是二进制的传输,占用带宽会更少
2、springCloud是http协议传输,带宽会比较多,同时使用http协议一般会使用JSON报文,消耗会更大
3、dubbo的开发难度较大,原因是dubbo的jar包依赖问题很多大型工程无法解决
4、springcloud的接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级
5、dubbo的注册中心可以选择zk,redis等,springcloud的注册中心用eureka或者Consul
1、dubbo由于是二进制的传输,占用带宽会更少
2、springCloud是http协议传输,带宽会比较多,同时使用http协议一般会使用JSON报文,消耗会更大
3、dubbo的开发难度较大,原因是dubbo的jar包依赖问题很多大型工程无法解决
4、springcloud的接口协议约定比较自由且松散,需要有强有力的行政措施来限制接口无序升级
5、dubbo的注册中心可以选择zk,redis等,springcloud的注册中心用eureka或者Consul
————————————————
版权声明:本文为CSDN博主「程序大视界」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/xuri24/article/details/89283802
我搭建的kafka集群宕机
我搭建的kafka集群中包含3个节点,当我先随机杀掉两个节点时,第3个节点成为leader,整个集群仍然可用,当我再杀掉唯一的节点时,kafka集群不可用。
但是我发现应用程序的日志一直在重连最后宕机的leader,并没有重连之前两个宕机的节点。
然后,我恢复了先杀掉的两个kafka节点,此时kafka集群可用,但我发现kafka客户端仍然没有重连恢复的节点,而是一直保持与最后死掉leader的重连。
但是其他节点恢复后成为新的leader了,客户端也没有重连,也就造成了全部节点宕机进行恢复时,必须恢复最后宕机的leader,否则,kafka集群虽然已经可用,但是应用程序仍然无法正常使用。
不知道这个问题怎么解决。
Linux简介及****Ubuntu安装
Linux,免费开源,多用户多任务系统。基于Linux有多个版本的衍生。RedHat、Ubuntu、Debian
安装VMware或VirtualBox虚拟机。具体安装步骤,找百度。
再安装Ubuntu。具体安装步骤,找百度。
安装完后,可以看到Linux系统的目录结构,见链接http://www.cnblogs.com/laov/p/3409875.html
常用指令
ls 显示文件或目录
-l 列出文件详细信息l(list)
-a 列出当前目录下所有文件及目录,包括隐藏的a(all)
mkdir 创建目录
-p 创建目录,若无父目录,则创建p(parent)
cd 切换目录
touch 创建空文件
echo 创建带有内容的文件。
cat 查看文件内容
cp 拷贝
mv 移动或重命名
rm 删除文件
-r 递归删除,可删除子目录及文件
-f 强制删除
find 在文件系统中搜索某文件
wc 统计文本中行数、字数、字符数
grep 在文本文件中查找某个字符串
rmdir 删除空目录
tree 树形结构显示目录,需要安装tree包
pwd 显示当前目录
ln 创建链接文件
more、less 分页显示文本文件内容
head、tail 显示文件头、尾内容
ctrl+alt+F1 命令行全屏模式
系统管理命令
stat 显示指定文件的详细信息,比ls更详细
who 显示在线登陆用户
whoami 显示当前操作用户
hostname 显示主机名
uname 显示系统信息
top 动态显示当前耗费资源最多进程信息
ps 显示瞬间进程状态 ps -aux
du 查看目录大小 du -h /home带有单位显示目录信息
df 查看磁盘大小 df -h 带有单位显示磁盘信息
ifconfig 查看网络情况
ping 测试网络连通
netstat 显示网络状态信息
man 命令不会用了,找男人 如:man ls
clear 清屏
alias 对命令重命名 如:alias showmeit=“ps -aux” ,另外解除使用unaliax showmeit
kill 杀死进程,可以先用ps 或 top命令查看进程的id,然后再用kill命令杀死进程。
打包压缩相关命令
gzip:
bzip2:
tar: 打包压缩
-c 归档文件
-x 压缩文件
-z gzip压缩文件
-j bzip2压缩文件
-v 显示压缩或解压缩过程 v(view)
-f 使用档名
例:
tar -cvf /home/abc.tar /home/abc 只打包,不压缩
tar -zcvf /home/abc.tar.gz /home/abc 打包,并用gzip压缩
tar -jcvf /home/abc.tar.bz2 /home/abc 打包,并用bzip2压缩
当然,如果想解压缩,就直接替换上面的命令 tar -cvf / tar -zcvf / tar -jcvf 中的“c” 换成“x” 就可以了。
关机/重启机器
shutdown
-r 关机重启
-h 关机不重启
now 立刻关机
halt 关机
reboot 重启
Linux管道
将一个命令的标准输出作为另一个命令的标准输入。也就是把几个命令组合起来使用,后一个命令除以前一个命令的结果。
例:grep -r “close” /home/* | more 在home目录下所有文件中查找,包括close的文件,并分页输出。
Linux软件包管理
dpkg (Debian Package)管理工具,软件包名以.deb后缀。这种方法适合系统不能联网的情况下。
比如安装tree命令的安装包,先将tree.deb传到Linux系统中。再使用如下命令安装。
sudo dpkg -i tree_1.5.3-1_i386.deb 安装软件
sudo dpkg -r tree 卸载软件
注:将tree.deb传到Linux系统中,有多种方式。VMwareTool,使用挂载方式;使用winSCP工具等;
APT(Advanced Packaging Tool)高级软件工具。这种方法适合系统能够连接互联网的情况。
依然以tree为例
sudo apt-get install tree 安装tree
sudo apt-get remove tree 卸载tree
sudo apt-get update 更新软件
sudo apt-get upgrade
将.rpm文件转为.deb文件
.rpm为RedHat使用的软件格式。在Ubuntu下不能直接使用,所以需要转换一下。
sudo alien abc.rpm
vim使用
vim三种模式:命令模式、插入模式、编辑模式。使用ESC或i或:来切换模式。
命令模式下:
:q 退出
:q! 强制退出
:wq 保存并退出
:set number 显示行号
:set nonumber 隐藏行号
/apache 在文档中查找apache 按n跳到下一个,shift+n上一个
yyp 复制光标所在行,并粘贴
h(左移一个字符←)、j(下一行↓)、k(上一行↑)、l(右移一个字符→)
用户及用户组管理
/etc/passwd 存储用户账号
/etc/group 存储组账号
/etc/shadow 存储用户账号的密码
/etc/gshadow 存储用户组账号的密码
useradd 用户名
userdel 用户名
adduser 用户名
groupadd 组名
groupdel 组名
passwd root 给root设置密码
su root
su - root
/etc/profile 系统环境变量
bash_profile 用户环境变量
.bashrc 用户环境变量
su user 切换用户,加载配置文件.bashrc
su - user 切换用户,加载配置文件/etc/profile ,加载bash_profile
更改文件的用户及用户组
sudo chown [-R] owner[:group] {File|Directory}
例如:还以jdk-7u21-linux-i586.tar.gz为例。属于用户hadoop,组hadoop
要想切换此文件所属的用户及组。可以使用命令。
sudo chown root:root jdk-7u21-linux-i586.tar.gz
文件权限管理
三种基本权限
R 读 数值表示为4
W 写 数值表示为2
X 可执行 数值表示为1

如图所示,jdk-7u21-linux-i586.tar.gz文件的权限为-rw-rw-r–
-rw-rw-r–一共十个字符,分成四段。
第一个字符“-”表示普通文件;这个位置还可能会出现“l”链接;“d”表示目录
第二三四个字符“rw-”表示当前所属用户的权限。 所以用数值表示为4+2=6
第五六七个字符“rw-”表示当前所属组的权限。 所以用数值表示为4+2=6
第八九十个字符“r–”表示其他用户权限。 所以用数值表示为4
所以操作此文件的权限用数值表示为664
更改权限
sudo chmod [u所属用户 g所属组 o其他用户 a所有用户] [+增加权限 -减少权限] [r w x] 目录名
例如:有一个文件filename,权限为“-rw-r----x” ,将权限值改为"-rwxrw-r-x",用数值表示为765
sudo chmod u+x g+w o+r filename
上面的例子可以用数值表示
sudo chmod 765 filename
首先,说大概说一下事务传播行为,随后讲事务失效,具体分析同一个类里方法调用造成事务失效的情况,再到事务传播行为应该在不同类的事务方法传播,最后讲会如何传播。
0. 事务传播行为大概认识
什么叫事务传播行为?听起来挺高端的,其实很简单。
即然是传播,那么至少有两个东西,才可以发生传播。单体不存在传播这个行为。
事务传播行为(propagation behavior)指的就是当一个事务方法被另一个事务方法调用时,这个事务方法应该如何进行。
例如:methodA事务方法调用methodB事务方法时,methodB是继续在调用者methodA的事务中运行呢,还是为自己开启一个新事务运行,这就是由methodB的事务传播行为决定的。
我后面还会进一步分析,先别急。在具体深入讲这个传播行为前。我必须先把失效给讲了。
1.事务失效的几种可能
不生效的原因是AOP导致的,重新组建字节码的时候,没有办法再次判断嵌套里面的那个方法是否有注解,这是AOP相关问题,与本文阐述的事务本身无关,但是其特性会让人觉得是spring事务自身的问题
1、标注事务的方法不是public的
2、你的异常类型不是unchecked异常
如果我想check异常也想回滚怎么办,需要注解上面写明异常类型即可
@Transactional(rollbackFor=Exception.class)
1
类似的还有norollbackFor,自定义不回滚的异常
3、数据库引擎要支持事务,如果是MySQL,注意表要使用支持事务的引擎,比如innodb,如果是myisam,事务是不起作用的
4、是否开启了对注解的解析
<tx:annotation-driven transaction-manager="transactionManager" proxy-target-class="true"/>
5、spring是否扫描到你这个包,如下是扫描到org.test下面的包
<context:component-scan base-package="org.test" >context:component-scan>
6、检查是不是同一个类中的方法调用(如a方法调用同一个类中的b方法)
这点非常重要,同一个类的方法调用,会导致事务无效。
7、UNCHECKED异常是不是被你catch住了
2.为什么同一个类的方法调用会导致事务无效呢
下面这段代码,事务会失效,并不会回滚。
原因就在addUser(“13522203330”);
其实是this.addUser(“13522203330”);
而这个THIS,并不是被SPRING 用CGLIB增强的类。也就是没有被代理,自然没有做事务了。
@Service
public class TransactionalAopServiceImpl implements TransactionalAopService {
@Autowired
private OrderDao orderDao;
@Autowired
private UserDao userDao;
public void addOrder() {
orderDao.insert(OrderModel.builder()
.userId("YK_002") //游客编号
.phone("13522203330")
.orderId("ORDER_2018042602")
.amount(10000L)
.build());
//默开用户
System.out.println("--->"+this.getClass());
addUser("13522203330");
}
@Transactional
public void addUser(String phone) {
userDao.insert(UserModel.builder().userName("zhangsan").userPhone(phone).build());
throw new RuntimeException();
}
}
破解方法
在调用addUser(……)之前添加下面的代码
TransactionalAopService service = (TransactionalAopService) AopContext.currentProxy(); //获取代理对象
service.addUser("13522203330"); //通过代理对象调用addUser,做异步增强
这里还不算完,如果就这样运行,那肯定会报错。
在@EnableAspectJAutoProxy添加属性值。
@EnableAspectJAutoProxy(exposeProxy = true)
建议可以先看我的AOP那章,究其源头是在于THIS 和SERVICE 是不同的类了。
如果对代理对象和当前对象有点懵的话,可以加上下面的两行代码:
System.out.println("------>代理对象:"+service.getClass());
System.out.println("------>当前对象:"+this.getClass());
得到的结果:
------>代理对象:class com.minuor.aop.impl.TransactionalAopServiceImpl$$EnhancerBySpringCGLIB$$9de92f4b //可以看出来是CGLB动态代理
------>当前对象:class com.minuor.aop.impl.TransactionalAopServiceImpl
情况二:addOrder和addUser方法上都添加@Transactional
这种情况下,是可以回滚的,但是不太清楚是在哪个事务回滚,也不太清楚@Transactional是都有效,还是其中一个有效。但是可以模拟,那就是定义三个异常,分别是OrderException、UserException、OtherException,然后在两个方法上指定回滚异常类。通过抛出不同的异常来看具体的结果。
@Transactional修改
@Transactional(rollbackFor = OrderException.class, noRollbackFor = RuntimeException.class) //addOrder方法上
@Transactional(rollbackFor = UserException.class, noRollbackFor = RuntimeException.class) //addUser方法上
执行结果分析
1、抛OtherException异常,没有回滚,order、user数据都成功录入到数据库中;
2、抛UserException异常,没有回滚,order、user数据都成功录入到数据库中,这里可以看的出来addUser方法上的@Transactional注解是无效的;
3、抛OrderException异常,回滚成功,order、user数据都没有录入到数据库中,addOrder方法上的@Transactional有效。
这样的结果加上动态代理原理的分析不难得出结果,addUser方法的代理增强被绕过,只是普通的一个方法调用,而且这个方法是包含在addOrder方法事务内的。
3.所以事务传播行为应该在不同类的方法间传播,有了这个基础后,我们看传播行为的问题
1.PROPAGATION_REQUIRED
我们为User1Service和User2Service相应方法加上Propagation.REQUIRED属性。
User1Service方法:
@Service
public class User1ServiceImpl implements User1Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void addRequired(User1 user){
user1Mapper.insert(user);
}
}
User2Service方法:
@Service
public class User2ServiceImpl implements User2Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void addRequired(User2 user){
user2Mapper.insert(user);
}
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void addRequiredException(User2 user){
user2Mapper.insert(user);
throw new RuntimeException();
}
}
1.1 场景一
此场景外围方法没有开启事务。
验证方法1:
@Override
public void notransaction_exception_required_required(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequired(user2);
throw new RuntimeException();
}
验证方法2:
@Override
public void notransaction_required_required_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiredException(user2);
}
分别执行验证方法,结果:

image.png
结论:通过这两个方法我们证明了在外围方法未开启事务的情况下Propagation.REQUIRED修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
1.2 场景二
外围方法开启事务,这个是使用率比较高的场景。
验证方法1:
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void transaction_exception_required_required(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequired(user2);
throw new RuntimeException();
}
验证方法2:
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void transaction_required_required_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiredException(user2);
}
验证方法3:
@Transactional
@Override
public void transaction_required_required_exception_try(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
try {
user2Service.addRequiredException(user2);
} catch (Exception e) {
System.out.println("方法回滚");
}
}
分别执行验证方法,结果:

image.png
结论:以上试验结果我们证明在外围方法开启事务的情况下Propagation.REQUIRED修饰的内部方法会加入到外围方法的事务中,所有Propagation.REQUIRED修饰的内部方法和外围方法均属于同一事务,只要一个方法回滚,整个事务均回滚。
2.PROPAGATION_REQUIRES_NEW
我们为User1Service和User2Service相应方法加上Propagation.REQUIRES_NEW属性。
User1Service方法:
@Service
public class User1ServiceImpl implements User1Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addRequiresNew(User1 user){
user1Mapper.insert(user);
}
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void addRequired(User1 user){
user1Mapper.insert(user);
}
}
User2Service方法:
@Service
public class User2ServiceImpl implements User2Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addRequiresNew(User2 user){
user2Mapper.insert(user);
}
@Override
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void addRequiresNewException(User2 user){
user2Mapper.insert(user);
throw new RuntimeException();
}
}
2.1 场景一
外围方法没有开启事务。
验证方法1:
@Override
public void notransaction_exception_requiresNew_requiresNew(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequiresNew(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiresNew(user2);
throw new RuntimeException();
}
验证方法2:
@Override
public void notransaction_requiresNew_requiresNew_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequiresNew(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiresNewException(user2);
}
分别执行验证方法,结果:

image.png
结论:通过这两个方法我们证明了在外围方法未开启事务的情况下Propagation.REQUIRES_NEW修饰的内部方法会新开启自己的事务,且开启的事务相互独立,互不干扰。
2.2 场景二
外围方法开启事务。
验证方法1:
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void transaction_exception_required_requiresNew_requiresNew(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiresNew(user2);
User2 user3=new User2();
user3.setName("王五");
user2Service.addRequiresNew(user3);
throw new RuntimeException();
}
验证方法2:
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void transaction_required_requiresNew_requiresNew_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiresNew(user2);
User2 user3=new User2();
user3.setName("王五");
user2Service.addRequiresNewException(user3);
}
验证方法3:
@Override
@Transactional(propagation = Propagation.REQUIRED)
public void transaction_required_requiresNew_requiresNew_exception_try(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addRequired(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addRequiresNew(user2);
User2 user3=new User2();
user3.setName("王五");
try {
user2Service.addRequiresNewException(user3);
} catch (Exception e) {
System.out.println("回滚");
}
}
分别执行验证方法,结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Sf0V0cXW-1647064945227)(https:upload-images.jianshu.io/upload_images/10803273-259e414ddf146e03.png?imageMogr2/auto-orient/strip|imageView2/2/w/889/format/webp)]
image.png
结论:在外围方法开启事务的情况下Propagation.REQUIRES_NEW修饰的内部方法依然会单独开启独立事务,且与外部方法事务也独立,内部方法之间、内部方法和外部方法事务均相互独立,互不干扰。
3.PROPAGATION_NESTED
我们为User1Service和User2Service相应方法加上Propagation.NESTED属性。
User1Service方法:
@Service
public class User1ServiceImpl implements User1Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.NESTED)
public void addNested(User1 user){
user1Mapper.insert(user);
}
}
User2Service方法:
@Service
public class User2ServiceImpl implements User2Service {
//省略其他...
@Override
@Transactional(propagation = Propagation.NESTED)
public void addNested(User2 user){
user2Mapper.insert(user);
}
@Override
@Transactional(propagation = Propagation.NESTED)
public void addNestedException(User2 user){
user2Mapper.insert(user);
throw new RuntimeException();
}
}
3.1 场景一
此场景外围方法没有开启事务。
验证方法1:
@Override
public void notransaction_exception_nested_nested(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addNested(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addNested(user2);
throw new RuntimeException();
}
验证方法2:
@Override
public void notransaction_nested_nested_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addNested(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addNestedException(user2);
}
分别执行验证方法,结果:

image.png
结论:通过这两个方法我们证明了在外围方法未开启事务的情况下Propagation.NESTED和Propagation.REQUIRED作用相同,修饰的内部方法都会新开启自己的事务,且开启的事务相互独立,互不干扰。
3.2 场景二
外围方法开启事务。
验证方法1:
@Transactional
@Override
public void transaction_exception_nested_nested(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addNested(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addNested(user2);
throw new RuntimeException();
}
验证方法2:
@Transactional
@Override
public void transaction_nested_nested_exception(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addNested(user1);
User2 user2=new User2();
user2.setName("李四");
user2Service.addNestedException(user2);
}
验证方法3:
@Transactional
@Override
public void transaction_nested_nested_exception_try(){
User1 user1=new User1();
user1.setName("张三");
user1Service.addNested(user1);
User2 user2=new User2();
user2.setName("李四");
try {
user2Service.addNestedException(user2);
} catch (Exception e) {
System.out.println("方法回滚");
}
}
分别执行验证方法,结果:

image.png
4. REQUIRED,REQUIRES_NEW,NESTED异同
由“1.2 场景二”和“3.2 场景二”对比,我们可知:
NESTED和REQUIRED修饰的内部方法都属于外围方法事务,如果外围方法抛出异常,这两种方法的事务都会被回滚。但是REQUIRED是加入外围方法事务,所以和外围事务同属于一个事务,一旦REQUIRED事务抛出异常被回滚,外围方法事务也将被回滚。而NESTED是外围方法的子事务,有单独的保存点,所以NESTED方法抛出异常被回滚,不会影响到外围方法的事务。
由“2.2 场景二”和“3.2 场景二”对比,我们可知:
NESTED和REQUIRES_NEW都可以做到内部方法事务回滚而不影响外围方法事务。但是因为NESTED是嵌套事务,所以外围方法回滚之后,作为外围方法事务的子事务也会被回滚。而REQUIRES_NEW是通过开启新的事务实现的,内部事务和外围事务是两个事务,外围事务回滚不会影响内部事务。
关于线程池的回收
核心线程通常不会回收,java核心线程池的回收由allowCoreThreadTimeOut参数控制,默认为false,若开启为true,则此时线程池中不论核心线程还是非核心线程,只要其空闲时间达到keepAliveTime都会被回收。但如果这样就违背了线程池的初衷(减少线程创建和开销),所以默认该参数为false。
keepAliveTime是指当线程池中线程数量大于corePollSize时,此时存在非核心线程,keepAliveTime指非核心线程空闲时间达到的阈值会被回收。
corePoolSize:核心线程最大数量,通俗点来讲就是,线程池中常驻线程的最大数量。线程池新建线程的时候,如果当前线程总数小于corePoolSize,则新建的是核心线程;如果超过corePoolSize,则新建的是非核心线程。
cglib 和 jdk 代理的区别
具体来讲就三个步骤:
\1. 根据ClassLoader和Interface来获取接口类(前面已经讲了,类是由ClassLoader加载到JVM的,所以通过ClassLoader和Interface可以找到接口类)
2.获取构造对象;
3.通过构造对象和InvocationHandler生成实例,并返回,就是我们要的代理类。
Java动态代理优缺点:
优点:
1.Java本身支持,不用担心依赖问题,随着版本稳定升级;
2.代码实现简单;
缺点:
1.目标类必须实现某个接口,换言之,没有实现接口的类是不能生成代理对象的;
2.代理的方法必须都声明在接口中,否则,无法代理;
3.执行速度性能相对cglib较低;
Cglib原理:
1.通过字节码增强技术动态的创建代理对象;
2.代理的是代理对象的引用;
Cglib优缺点:
优点:
1.代理的类无需实现接口;
2.执行速度相对JDK动态代理较高;
缺点:
1.字节码库需要进行更新以保证在新版java上能运行;
2.动态创建代理对象的代价相对JDK动态代理较高;
Tips:
1.代理的对象不能是final关键字修饰的
限流的目的是通过对并发访问请求进行限速或者一个时间窗口内的的请求数量进行限速来保护系统
所谓重入锁,指的是以线程为单位,当一个线程获取对象锁之后,这个线程可以再次获取本对象上的锁,而其他的线程是不可以的。
run方法是Runnable接口中定义的,start方法是Thread类定义的。 所有实现Runnable的接口的类都需要重写run方法,run方法是线程默认要执行的方法,有底层源码可知是绑定操作系统的,也是线程执行的入口。 start方法是Thread类的默认执行入口,Thread又是实现Runnable接口的。要使线程Thread启动起来,需要通过start方法,表示线程可执行状态,调用start方法后,则表示Thread开始执行,此时run变成了Thread的默认要执行普通方法。 2)通过start()方法,直接调用run()方法可以达到多线程的目的 通常,系统通过调用线程类的start()方法来启动一个线程,此时该线程处于就绪状态,而非运行状态,这也就意味着这个线程可以被JVM来调度执行。在调度过程中,JVM会通过调用线程类的run()方法来完成试机的操作,当run()方法结束之后,此线程就会终止。 如果直接调用线程类的run()方法,它就会被当做一个普通的函数调用,程序中任然只有主线程这一个线程。也就是说,star()方法可以异步地调用run()方法,但是直接调用run()方法确实同步的,因此也就不能达到多线程的目的。 run()和start()的区别可以用一句话概括:单独调用run()方法,是同步执行;通过start()调用run(),是异步执行。
单线程的redis为什么达到每秒万级的处理速度?
- 纯内存访问,redis将所有数据都放在内存中,内存响应时间大约为100纳秒,这是redis达到每秒万级级别访问的重要基础。
- 非阻塞IO,redis使用epoll作为IO多路复用技术的实现,再加上redis自身事件处理模型将epoll中的链接、读写、关闭都转换为事件,不在网络IO上浪费过多的事件。
- 单线程避免了线程切换和竟态产生的消耗。
1.单线程简化数据结构和算法的实现。
2.单线程避免线程切换和竟态产生的消耗。
缺点:如果命令执行时间过程,会导致其它命令阻塞。
在使用线程池的时候,看到execute()与submit()方法。都可以使用线程池执行一个任务,但是两者有什么区别呢?
execute
void execute(Runnable command);
submit
Future submit(Callable task);
Future submit(Runnable task, T result);
Future submit(Runnable task);
相同点:
1 都可以执行任务
2 参数都支持runnable
不同点:
1 submit支持接收返回值 详见例1。
2 execute 任务里面的异常必须捕获,不能向上抛出;submit支持的Callable支持向上抛出异常,需要由返回值.get()来进行接收
【并发编程】公平锁与非公平锁的区别 - faylinn - 博客园 (cnblogs.com)
开始聊之前,我先大概说一下他们两者的定义,帮大家回顾或者认识一下。
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中。
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
我举个例子给他家通俗易懂的讲一下的,想了好几天终于在前天跟三歪去肯德基买早餐排队的时候发现了怎么举例了。
HTTP与HTTPS介绍
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息,HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息,因此,HTTP协议不适合传输一些敏感信息,比如:信用卡号、密码等支付信息。
为了解决HTTP协议的这一缺陷,需要使用另一种协议:安全套接字层超文本传输协议HTTPS,为了数据传输的安全,HTTPS在HTTP的基础上加入了SSL/TLS协议,SSL/TLS依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密。
HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全
HTTPS协议的主要作用可以分为两种:一种是建立一个信息安全通道,来保证数据传输的安全;另一种就是确认网站的真实性。
HTTPS和HTTP的主要区别
1、https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl/tls加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL/TLS+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
防止接口被人盗刷的一些感想
之前做的一个活动由于没做好并发和接口限制被人大量恶意请求,现在分享一些防止盗刷的经验
转载一篇CDSN的博客思路,有不错的借鉴思路,出处:https://blog.csdn.net/qq_29842085/article/details/79639351:
1 / 验证码(最简单有效的防护),采用点触验证,滑动验证或第三方验证码服务,普通验证码很容易被破解
2 / 频率,限制同设备,同IP等发送次数,单点时间范围可请求时长
3 / 归属地,检测IP所在地是否与手机号归属地匹配;IP所在地是否是为常在地
4 / 可疑用户,对于可疑用户要求其主动发短信(或其他主动行为)来验证身份
5 / 黑名单,对于黑名单用户,限制其操作,API接口直接返回success,1可以避免浪费资源,2混淆黑户判断
6 / 签名,API接口启用签名策略,签名可以保障请求URL的完整安全,签名匹配再继续下一步操作
7 / token,对于重要的API接口,生成token值,做验证
8 / https,启用https,https 需要秘钥交换,可以在一定程度上鉴别是否伪造IP
9 / 代码混淆,发布前端代码混淆过的包
10 / 风控,大量肉鸡来袭时只能受着,同样攻击者也会暴露意图,分析意图提取算法,分析判断是否为恶意 如果是则断掉;异常账号及时锁定;或从产品角度做出调整,及时止损。
11 / 数据安全,数据安全方面做策略,攻击者得不到有效数据,提高攻击者成本
12 / 恶意IP库,https://threatbook.cn/,过滤恶意IP
tips:
鉴别IP真伪(自己识别代理IP和机房IP成本略高,可以考虑第三方saas服务。由肉鸡发起的请求没辙,只能想其他方法)
手机号真伪(做空号检测,同样丢给供应商来处理,达不到100%准确率,效率感人,并且不是实时的,可以考虑选择有防攻击的运营商)
安全问题是长期的和攻击者斗智斗勇的问题,没有一劳永逸的解决方案,不断交锋,不断成长
接下来写一部分自己的实战感悟:
-
1、验证码是必须的,但是局限性很大。很多盗刷工具就直接通过工具批量获取验证码再输入到脚本中直接通过校验,这个只能稍微做一下拦截。
-
2、redis建立一个db0库专门用来存储ip访问次数和频率,把频率过高的ip拉黑。这个方式也有局限性,就是ip可以混淆,也是只能拦截一部分恶意请求。
-
3、前端代码混淆。建议做,成本低有效果。
-
4、带上简单token验证,能拦截一部分,token有效期可以设置短一点。
-
5、前后端签名校验。重要接口必须加上。
-
6、传参的时候记得不要直接把重要信息交给前端传,尽量后台做。
-
7、手机号黑名单。这个有供应商提供,不过收费标准有些是按条来的,项目数据量大而且预算有限的情况下不建议使用。
String、StringBuffer和StringBuilder的六大区别
String:适用于少量的字符串操作。
StringBuilder:适用于单线程下在字符串缓冲区进行大量操作。
StringBuffer:适用于多线程下在字符串缓冲区进行大量操作。
区别一:String是final类不能被继承且为字符串常量,而StringBuilder和StringBuffer均为字符串变量。
在Java中字符串使用String类进行表示,但是String类表示字符串有一个最大的问题:“字符串常量一旦声明则不可改变,而字符串对象可以改变,但是改变的是其内存地址的指向。”所以String类不适合于频繁修改的字符串操作上,所以在这种情况下,往往可以使用StringBuffer类,即StringBuffer类方便用户进行内容修改。
区别二:在String类中使用“+”作为数据的连接操作,而在StringBuffer类中使用append()方法(方法定义:public StringBuffer append(数据类型 变量))进行数据连接。
区别四:String类和StringBuilder、StringBuffer类的转换。
1.String类通过apend()方法转换成StringBuilder和StringBuffer类。
StringBuffer类和StringBuilder类通过to.String()方法转换成String类型
区别3:性能
既然 StringBuffer 是线程安全的,它的所有公开方法都是同步的,StringBuilder 是没有对方法加锁同步的,所以毫无疑问,StringBuilder 的性能要远大于 StringBuffer。
总结
StringBuffer 适用于用在多线程操作同一个 StringBuffer 的场景,如果是单线程场合 StringBuilder 更适合。
start()和run()的区别
run方法是Runnable接口中定义的,start方法是Thread类定义的。 所有实现Runnable的接口的类都需要重写run方法,run方法是线程默认要执行的方法,有底层源码可知是绑定操作系统的,也是线程执行的入口。 start方法是Thread类的默认执行入口,Thread又是实现Runnable接口的。要使线程Thread启动起来,需要通过start方法,表示线程可执行状态,调用start方法后,则表示Thread开始执行,此时run变成了Thread的默认要执行普通方法。 2)通过start()方法,直接调用run()方法可以达到多线程的目的 通常,系统通过调用线程类的start()方法来启动一个线程,此时该线程处于就绪状态,而非运行状态,这也就意味着这个线程可以被JVM来调度执行。在调度过程中,JVM会通过调用线程类的run()方法来完成试机的操作,当run()方法结束之后,此线程就会终止。 如果直接调用线程类的run()方法,它就会被当做一个普通的函数调用,程序中任然只有主线程这一个线程。也就是说,star()方法可以异步地调用run()方法,但是直接调用run()方法确实同步的,因此也就不能达到多线程的目的。 run()和start()的区别可以用一句话概括:单独调用run()方法,是同步执行;通过start()调用run(),是异步执行。
线程的run()方法是由java虚拟机直接调用的,如果我们没有启动线程(没有调用线程的start()方法)而是在应用代码中直接调用run()方法,那么这个线程的run()方法其实运行在当前线程(即run()方法的调用方所在的线程)之中,而不是运行在其自身的线程中,从而违背了创建线程的初衷;
redis单元素,最大存多少数据,list的话,每条可以最多存多少元素
你指的是String类型吧,在Redis中字符串类型的Value最多可以容纳的数据长度是512M
redis官方说最少单例能处理key:2.5亿个
zk分布式锁
- 锁的类型实现
独占锁:用znode来看做一把锁,通过create znode来实现。只有创建成功的才拥有这把锁。
时序锁:在znode的节点下面创建一些临时有序的节点。通过父节点distribute_lock来维持一份sequence,保证子节点创建时序,形成全局时序。
- redis锁和zk锁的区别redis的优点:
优点:
速度快
缺点:
在分布式情况下,redis主设置了key,但是没有同步的情况下,主挂了。导致其他线程也能正常上锁了。
zk锁的优点:
- 锁失效实现简单,临时的节点绑定的是client端,只要client端锻炼自动失效,不需要实现过期时间然后不需要关心业务时间。
- 锁不需要去循环轮询的方式去查看是不是可以获取锁,可以通过watch来实现。采用监听通知的模型。
缺点:
频繁的删除节点,性能不如redis
当然,由于轻量级锁天然瞄准不存在锁竞争的场景,如果存在锁竞争但不激烈,仍然可以用自旋锁优化,自旋失败后再膨胀为重量级锁。
kafka依赖zookeeper原因解析及应用场景
kafka简介:
kafka是一个发布订阅消息系统,由topic区分消息种类,每个topic中可以有多个partition,每个kafka集群有一个多个broker服务器组成,producer可以发布消息到kafka中,consumer可以消费kafka中的数据。kafka就是生产者和消费者中间的一个暂存区,可以保存一段时间的数据保证使用。
kafka+zookeeper
zookeeper作为解决分布式一致性问题的工具而被kafka依赖(分布式协调中心)。而分布式模式,即去中心化的集群模式,需要让消费者知道现在有哪些生产者(对于消费者而言,kafka就是生产者)是可用的。如果没了zk消费者如何知道呢?如果每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,效率就会变得很低。
Kafka使用zk的分布式协调服务,将生产者,消费者,消息储存(broker,用于存储信息,消息读写等)结合在一起。同时借助zk,kafka能够将生产者,消费者和broker在内的所有组件在无状态的条件下建立起生产者和消费者的订阅关系,实现生产者的负载均衡。
\1. broker在zk中注册
kafka的每个broker(相当于一个节点,相当于一个机器)在启动时,都会在zk中注册,告诉zk其brokerid,在整个的集群中,broker.id/brokers/ids,当节点失效时,zk就会删除该节点,就很方便的监控整个集群broker的变化,及时调整负载均衡。
\2. topic在zk中注册
在kafka中可以定义很多个topic,每个topic又被分为很多个分区。一般情况下,每个分区独立在存在一个broker上,所有的这些topic和broker的对应关系都有zk进行维护
\3. consumer(消费者)在zk中注册
1)注册新的消费者,当有新的消费者注册到zk中,zk会创建专用的节点来保存相关信息,路径ls /consumers/{group_id}/ [ids,owners,offset],Ids:记录该消费分组有几个正在消费的消费者,Owmners:记录该消费分组消费的topic信息,Offset:记录topic每个分区中的每个offset
2)监听消费者分组中消费者的变化 ,监听/consumers/{group_id}/ids的子节点的变化,一旦发现消费者新增或者减少及时调整消费者的负载均衡。
\4. kafka的应用场景
2)消息系统:解耦和生产者和消费者、缓存消息等。
4)运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告
Kafka的数据存储
一、基本概念
1、Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群;
2、Topic:一类消息,Kafka集群能够同时负责多个topic的分发;
3、Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队;
4、Segment:每个partition又由多个segment file组成;
5、offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息;
6、message:这个算是kafka文件中最小的存储单位,即是 a commit log。
二、存储位置及格式
1、存储位置
kafka数据的存储位置,在config/server.properties中的log.dirs中配置;
本次演示kafka的日志存储配置为:log.dirs=/tmp/kafka-logs
2、分区与存储方式的关系
partition是以文件的形式存储在文件系统中,比如,创建了一个名为kafkaData的topic,有4个partition,那么在Kafka的数据目录中(由配置文件中的log.dirs指定的)中就有这样4个目录: kafkaData-0, kafkaData-1,kafkaData-2,kafkaData-3,其命名规则为
3、每个数据目录的子目录都有xx.index ,xx.log ,xx.timeindex三个文件组成
**Leader:**指定主分区的broker id;
Replicas: 副本在那些机器上;
**Isr:**可以做为主分区的broker id;
5、Kafka高效文件存储设计特点
1)Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
(2)通过索引信息可以快速定位message和确定response的最大大小。
(3)通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
(4)通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小
Java中的锁概念
掌握Java中锁是Java多线程编程中绕不开的知识,只有知道理解Java各种锁才能在编码过程中灵活运用,写出更高效的多线程程序。而理解掌握锁的第一步,可从宏观上对比理解一下各种锁概念。
- 公平锁/非公平锁
- 可重入锁
- 独享锁/共享锁
- 互斥锁/读写锁
- 乐观锁/悲观锁
- 分段锁
- 偏向锁/轻量级锁/重量级锁
- 自旋锁
上面是很多锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计,下面总结的内容是对每个锁的名词进行一定的解释。
公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。
非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。
对于JavaReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。
对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。说的有点抽象,下面会有一个代码的示例。
对于JavaReentrantLock而言, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁。
对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。synchronized void setA() throws Exception{ Thread.sleep(1000); setB(); } synchronized void setB() throws Exception{ Thread.sleep(1000); }上面的代码就是一个可重入锁的一个特点,如果不是可重入锁的话,setB可能不会被当前线程执行,可能造成死锁。
独享锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。
共享锁是指该锁可被多个线程所持有。对于Java
ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
对于Synchronized而言,当然是独享锁。互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。
互斥锁在Java中的具体实现就是ReentrantLock
读写锁在Java中的具体实现就是ReadWriteLock乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。
悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。
乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。从上面的描述我们可以看出,悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。
悲观锁在Java中的使用,就是利用各种锁。
乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于
ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对
Synchronized。在Java 5通过引入锁升级的机制来实现高效Synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
关于线程池的回收
核心线程通常不会回收,java核心线程池的回收由allowCoreThreadTimeOut参数控制,默认为false,若开启为true,则此时线程池中不论核心线程还是非核心线程,只要其空闲时间达到keepAliveTime都会被回收。但如果这样就违背了线程池的初衷(减少线程创建和开销),所以默认该参数为false。
keepAliveTime是指当线程池中线程数量大于corePollSize时,此时存在非核心线程,keepAliveTime指非核心线程空闲时间达到的阈值会被回收。
corePoolSize:核心线程最大数量,通俗点来讲就是,线程池中常驻线程的最大数量。线程池新建线程的时候,如果当前线程总数小于corePoolSize,则新建的是核心线程;如果超过corePoolSize,则新建的是非核心线程。
反射就是获取运行时类对象,并且可以在运行时获取类的完整构造,并调用对应的方法。
f.setAccessible(true);得作用就是让我们在用反射时访问私有变量
1、kafka 集群中的服务器都叫做broker
2、kafka 有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker 服务器之间采用tcp 协议连接
3、kafka 中不同业务系统的消息可以通过topic 进行区分,而且每一个消息topic 都会被分区,以分担消息读写的负载
4、每一个分区都可以有多个副本,以防止数据的丢失
5、某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader 来更新
6、消费者可以分组(Consumer Group),比如有两个消费者组A 和B,共同消费一个topic:order_info,A 和B所消费的消息不会重复
比如order_info 中有100 个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49 号,B 组就消费50-99 号
//生产环境中也可以让多个consumer共同消费同一个topic中的数据,需要设置调整 //代码段可以实现
7、消费者在具体消费某个topic 中的消息时,可以指定起始偏移量
Kafka系列视频教程之Kafka核心基础 -博彬
为什么使用kafka
1、作为缓存
2、解(系统)耦合
3、时间小于10ms 基本上是一种实时的
他能简化,我们系统的设计,提示公司的开发速度,和效率
为何使用消息系统
解耦
在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
冗余
有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
扩展性
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
顺序保证
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka保证一个Partition内的消息的有序性。
缓冲
在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行———写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
kafka重要概念
介绍kafka的几个重要概念
Broker:消息中间件处理结点,一个Kafka的server节点就是一个broker,多个broker可以组成一个Kafka集群;
Topic:一类消息,例如page view日志、click日志等都可以以topic的形式存在,Kafka集群能够同时负责多个topic的分发;
Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队;
Segment:每个partition又由多个segment file组成;
offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息;
message:这个算是kafka文件中最小的存储单位,即是 a commit log。
topic:创建topic名称
partition:分区编号
offset:表示该partition已经消费了多少message
logsize:表示该paritition生产了多少的message
lag:表示有多少条message未被消费
owner:表示消费者
create:表示该partition创建时间
last seen:表示消费状态刷新最新时间
kafka的优点:
消息队列kafka特性 https://blog.csdn.net/qq_36236890/article/details/81174504
1、单机吞吐量:
10万级别,这是kafka最大的优势,就是他的吞吐量高,一般配合大数据类的系统来进行实施数据计算,日志采集等场景
2、topic数据对吞吐量的影响:
topic从几十个到上百个不等,但是topic越多,会很大程度的影响吞吐量,所以在同等机器下,kafka经量保证topic数量不要过度。如果要支撑大规模的topic的话,需要增加更多的集群资源。
3、时效性:
延迟控制在ms以内
4、可用性:
非常高,kafka是分布是的,一个数据多个副本,少数机器的宕机,不会丢数据,不会导致不可用
5、消息可靠性
经过参数优化配置,消息可以做到0丢失
6、功能支持
功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准
7、优劣势总结
kafka的特点其实很明显,就是仅仅提供较少的核心功能,但是提供较高的吞吐量,ms级别的延迟,较高的可用性以及可靠性,而且是分布式的,可以任意的扩展,同时kafka也是做好的是支撑少量的topic数量即可,保证其吞吐量,而且kafka唯一的一点劣势就是可能出现就消息的重复消费,那么对数据准确性会产生影响,在大数据领域中以及日志收集中,这点轻微可以忽略。
kafka的特性就是天然适合大数据实时计算以及日志的收集。
Kafka天生就是一个分布式的消息队列,它可以由多个broker组成,每个broker是一个节点;你创建一个topic,这个topic可以划分为多个partition,每个partition可以存在于不同的broker上,每个partition就放一部分数据。
5. 批处理
在很多情况下,系统的瓶颈不是 CPU 或磁盘,而是网络IO。
因此,除了操作系统提供的低级批处理之外,Kafka 的客户端和 broker 还会在通过网络发送数据之前,在一个批处理中累积多条记录 (包括读和写)。记录的批处理分摊了网络往返的开销,使用了更大的数据包从而提高了带宽利用率。
6. 数据压缩
Producer 可将数据压缩后发送给 broker,从而减少网络传输代价,目前支持的压缩算法有:Snappy、Gzip、LZ4。数据压缩一般都是和批处理配套使用来作为优化手段的。
小总结 | 下次面试官问我 kafka 为什么快,我就这么说
- partition 并行处理
- 顺序写磁盘,充分利用磁盘特性
- 利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
- 采用了零拷贝技术
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
机械硬盘的连续读写性能很好,但随机读写性能很差,这主要是因为磁头移动到正确的磁道上需要时间,随机读写时,磁头需要不停的移动,时间都浪费在了磁头寻址上,所以性能不高。衡量磁盘的重要主要指标是IOPS和吞吐量。
硬盘性能的制约因素是什么?如何根据磁盘I/O特性来进行系统设计?
硬盘内部主要部件为磁盘盘片、传动手臂、读写磁头和主轴马达。实际数据都是写在盘片上,读写主要是通过传动手臂上的读写磁头来完成。实际运行时,主轴让磁盘盘片转动,然后传动手臂可伸展让读取头在盘片上进行读写操作。磁盘物理结构如下图所示:
最通俗易懂的NIO原理解释
NIO最核心的三个组件
Channel 通道
Buffer 缓冲区
Selector 选择器
其中Channel对应以前的流,Buffer不是什么新东西,Selector是因为nio可以使用同步的非堵塞模式才加入的东西。
以前的流总是堵塞的,一个线程只要对它进行操作,其它操作就会被堵塞,也就相当于水管没有阀门,你伸手接水的时候,不管水到了没有,你就都只能耗在接水(流)上。
nio的Channel的加入,相当于增加了水龙头(有阀门),虽然一个时刻也只能接一个水管的水,但依赖轮换策略,在水量不大的时候,各个水管里流出来的水,都可以得到妥善接纳,这个关键之处就是增加了一个接水工,也就是Selector,他负责协调,也就是看哪根水管有水了的话,在当前水管的水接到一定程度的时候,就切换一下:临时关上当前水龙头,试着打开另一个水龙头(看看有没有水)。
当其他人需要用水的时候,不是直接去接水,而是事前提了一个水桶给接水工,这个水桶就是Buffer。也就是,其他人虽然也可能要等,但不会在现场等,而是回家等,可以做其它事去,水接满了,接水工会通知他们。
这其实也是非常接近当前社会分工细化的现实,也是统分利用现有资源达到并发效果的一种很经济的手段,而不是动不动就来个并行处理,虽然那样是最简单的,但也是最浪费资源的方式。
wait()和sleep()的区别
sleep()是使线程暂停执行一段时间的方法。wait()也是一种使线程暂停执行的方法。例如,当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。并且可以调用notify()方法或者notifyAll()方法通知正在等待的其他线程。notify()方法仅唤醒一个线程(等待队列中的第一个线程)并允许他去获得锁。notifyAll()方法唤醒所有等待这个对象的线程并允许他们去竞争获得锁。具体区别如下:
-
原理不同。sleep()方法是Thread类的静态方法,是线程用来控制自身流程的,他会使此线程暂停执行一段时间,而把执行机会让给其他线程,等到计时时间一到,此线程会自动苏醒。例如,当线程执行报时功能时,每一秒钟打印出一个时间,那么此时就需要在打印方法前面加一个sleep()方法,以便让自己每隔一秒执行一次,该过程如同闹钟一样。而wait()方法是object类的方法,用于线程间通信,这个方法会使当前拥有该对象锁的进程等待,直到其他线程调用notify()方法或者notifyAll()时才醒来,不过开发人员也可以给他指定一个时间,自动醒来。
-
对锁的 处理机制不同。由于sleep()方法的主要作用是让线程暂停执行一段时间,时间一到则自动恢复,不涉及线程间的通信,因此,调用sleep()方法并不会释放锁。而wait()方法则不同,当调用wait()方法后,线程会释放掉他所占用的锁,从而使线程所在对象中的其他synchronized数据可以被其他线程使用。
-
使用区域不同。wait()方法必须放在同步控制方法和同步代码块中使用,sleep()方法则可以放在任何地方使用。sleep()方法必须捕获异常,而wait()、notify()、notifyAll()不需要捕获异常。在sleep的过程中,有可能被其他对象调用他的interrupt(),产生InterruptedException。由于sleep不会释放锁标志,容易导致死锁问题的发生,因此一般情况下,推荐使用wait()方法。
三、NIO
同步非阻塞,服务器实现模式为一个线程可以处理多个请求(连接),客户端发送的连接请求都会注册到多路复用器selector上,多路复用器轮询到连接有IO请求就进行处理,JDK1.4开始引入。
应用场景:
NIO方式适用于连接数目多且连接比较短(轻操作) 的架构, 比如聊天服务器, 弹幕系统, 服务器间通讯,编程比较复杂。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-i8qkMhrT-1647064945235)(/Users/zeleishi/Documents/工作/授课/2103/第四阶段/day25Gitflow工作流+NIO/资料/img/c2.png)]
四、epoll模型
I/O多路复用底层主要用的Linux 内核·函数(select,poll,epoll)来实现,windows不支持epoll实现,windows底层是基于winsock2的select函数实现的(不开源)
| select | poll | epoll(jdk 1.5及以上) | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 底层实现 | 数组 | 链表 | 哈希表 |
| IO效率 | 每次调用都进行线性遍历,时间复杂度为O(n) | 每次调用都进行线性遍历,时间复杂度为O(n) | 事件通知方式,每当有IO事件就绪,系统注册的回调函数就会被调用,时间复杂度O(1) |
| 最大连接 | 有上限 | 无上限 | 无上限 |
Redis线程模型
Redis就是典型的基于epoll的NIO线程模型(nginx也是),epoll实例收集所有事件(连接与读写事件),由一个服务端线程连续处理所有事件命令。
Redis底层关于epoll的源码实现在redis的src源码目录的ae_epoll.c文件里,感兴趣可以自行研究。
随笔 - 641 文章 - 0 评论 - 34 阅读 - 76万
Redis的优势和特点
Redis的特点:
- 内存数据库,速度快,也支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
- 支持事务
Redis的优势:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。(事务)
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
Springboot***自动化配置:***
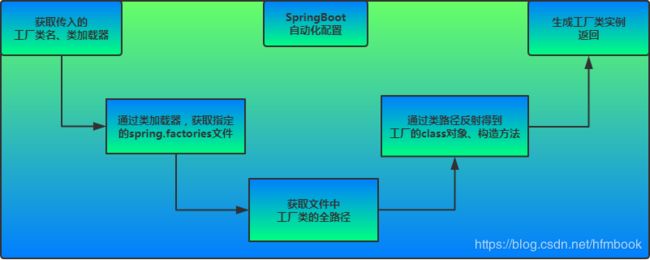
该配置模块的主要使用到了SpringFactoriesLoader,即Spring工厂加载器,该对象提供了loadFactoryNames方法,入参为factoryClass和classLoader,即需要传入上图中的工厂类名称和对应的类加载器,方法会根据指定的classLoader,加载该类加器搜索路径下的指定文件,即spring.factories文件,传入的工厂类为接口,而文件中对应的类则是接口的实现类,或最终作为实现类,所以文件中一般为如下图这种一对多的类名集合,获取到这些实现类的类名后,loadFactoryNames方法返回类名集合,方法调用方得到这些集合后,再通过反射获取这些类的类对象、构造方法,最终生成实例
启动:
每个SpringBoot程序都有一个主入口,也就是main方法,main里面调用SpringApplication.run()启动整个spring-boot程序,该方法所在类需要使用@SpringBootApplication注解,以及@ImportResource注解(if need),@SpringBootApplication包括三个注解,功能如下:@EnableAutoConfiguration:SpringBoot根据应用所声明的依赖来对Spring框架进行自动配置
@SpringBootConfiguration(内部为@Configuration):被标注的类等于在spring的XML配置文件中(applicationContext.xml),装配所有bean事务,提供了一个spring的上下文环境
@ComponentScan:组件扫描,可自动发现和装配Bean,默认扫描SpringApplication的run方法里的Booter.class所在的包路径下文件,所以最好将该启动类放到根包路径下|
设计模式
装饰器模式(装饰设计模式)详解 (biancheng.net)
spring boot 中使用到的设计模式
(10条消息) Spring/SpringBoot系列之Spring中涉及的9种设计模式【七】_fei1234456的博客-CSDN博客_springboot设计模式
List、Map、set的加载因子,默认初始容量和扩容增量
首先,这三个概念说下。初始大小,就是创建时可容纳的默认元素个数;加载因子,表示某个阀值,用0~1之间的小数来表示,当已有元素占比达到这个阀值后,底层将进行扩容操作;扩容方式,即指定每次扩容后的大小的规则,比如翻倍等。
当底层实现涉及到扩容时,容器或重新分配一段更大的连续内存(如果是离散分配则不需要重新分配,离散分配都是插入新元素时动态分配内存),要将容器原来的数据全部复制到新的内存上,这无疑使效率大大降低。
加载因子的系数小于等于1,意指 即当 元素个数 超过 容量长度*加载因子的系数 时,进行扩容。
另外,扩容也是有默认的倍数的,不同的容器扩容情况不同。
List 元素是有序的、可重复
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
构造方法摘要HashSet()
HashSet(int initialCapacity)
构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
HashSet hs=new HashSet(1);
所以可见 HashSet类,创建对象的时候是可以的制定容量的大小的 ,期中第二个就具有这个工功能。
Map是一个双列集合
HashMap:默认初始容量为16
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1 -->至于详细的原因可另行分析,或分析源代码)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Hashtable: 线程安全
默认初始容量为11
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍+1
如 Hashtable的容量为11,一次扩容后是容量为23
如果分布式锁的实现,还能再解决上面的三个问题,那么就可以算是一个相对完整的分布式锁了。然而,在实际的系统环境中,还会对分布式锁有更高级的要求。
- 可重入:线程中的可重入,指的是外层函数获得锁之后,内层也可以获得锁,ReentrantLock和synchronized都是可重入锁;衍生到分布式环境中,一般仍然指的是线程的可重入,在绝大多数分布式环境中,都要求分布式锁是可重入的。
- 惊群效应(Herd Effect):在分布式锁中,惊群效应指的是,在有多个请求等待获取锁的时候,一旦占有锁的线程释放之后,如果所有等待的方都同时被唤醒,尝试抢占锁。但是这样的情况会造成比较大的开销,那么在实现分布式锁的时候,应该尽量避免惊群效应的产生。
- 公平锁和非公平锁:不同的需求,可能需要不同的分布式锁。非公平锁普遍比公平锁开销小。但是业务需求如果必须要锁的竞争者按顺序获得锁,那么就需要实现公平锁。
- 阻塞锁和自旋锁:针对不同的使用场景,阻塞锁和自旋锁的效率也会有所不同。阻塞锁会有上下文切换,如果并发量比较高且临界区的操作耗时比较短,那么造成的性能开销就比较大了。但是如果临界区操作耗时比较长,一直保持自旋,也会对CPU造成更大的负荷。
kafka(一)-为什么选择kafka
作为开发人员,我们在选择一个框架或者工具时,我们都需要考虑些什么,我们不是头脑发热,一拍脑袋就它了,我们首先要认清这个框架或工具的作用是什么,能给我们带来什么样的好处,同时也要考虑带来什么样的负面结果,我们在使用时才能更好的扬其长避其短,kafka大家可能都不陌生,到底我们为什么选择kafka呢?
1.首先kafka是一个消息队列,作为消息队列一般会在很多场景中用到,如:
应用解耦
在系统交互时,有时我们很难一次性就设计出非常完善的接口,可能会随着业务发展,这些交互接口也会不断的变迁,如果我们的系统较多,系统间交互也较多,维护起来可能就是噩梦,这是可能就需要考虑引入一种基于数据的接口层(消息队列),这样各个系统可以独立的扩展或修改自己的处理过程,只要保证他们准守实现设计的数据格式约束。解耦的同时也提高了系统的稳定性(某个组件失效不会影响其他部分正常运行)和扩展性(可以横向扩展系统以增加处理消息的能力)。
异步处理
有时候我们的业务逻辑可能涉及到很多步骤,而且这些步骤可能上下关联性不是很强,如果我们串行执行时,总耗时=每个步骤耗时之和,如果我们让每个步骤并行处理,总耗时< 每个步骤耗时之和,在这里我们就可以引入消息队列,将每个处理步骤发送到消息队列,并且针对每个处理步骤都有对应的线程去监听,这样就能达到串行执行异步化转为并行执行,从而提高系统的的吞吐量。
流量削峰
在秒杀或抢购活动中,一般会因为流量暴增,应用因处理不过来而挂掉,此时一般会引入消息队列,这样流量会先进入消息队列,我们的应用再根据自己的实际处理能力来消费这些消息,从而达到缓解流量暴增对系统构成的压力
日志处理
有时我们需要采集日志,系统运行中会产生大量的日志,尤其是在流量高峰时,而这项日志需要存储在其他地方,一般进行其他的计算或处理,日志在写入磁盘此时,由于磁盘IO速度可能不是很快,会对系统造成压力,这时我们就可以引入比较高性能的消息队列(kafka往往会被用到),消息队列可以起到缓冲作用。
消息通信
消息队列一般都内置了高效的通信机制,有点对点通信,也有发布订阅式通信,因此也可以用在纯的消息通讯。
冗余存储
消息队列一般会把消息存储起来,只有消费完成后,才把消息删除,这样就防止了某些时候因为处理异常,而导致消息丢失的问题
2.在众多的消息中间件中,为什么选择kafka
Kafka最早是由LinkedIn公司开发的,作为其自身业务消息处理的基础,后LinkedIn公司将Kafka捐赠给Apache,现在已经成为Apache的一个顶级项目了,Kafka作为一个高吞吐的分布式的消息系统,是一个高性能跨语言分布式发布/订阅消息队列系统。
主要特性
- 快速持久化:可以在O(1)的系统开销下进行消息持久化;
- 高吞吐:在一台普通的服务器上既可以达到10W/s的吞吐速率;
- 完全的分布式系统:Broker、Producer和Consumer都原生自动支持分布式,自动实现负载均衡;
- 支持同步和异步复制两种高可用机制;
- 支持数据批量发送和拉取;
- 零拷贝技术(zero-copy):减少IO操作步骤,提高系统吞吐量;
- 数据迁移、扩容对用户透明;
- 无需停机即可扩展机器;
- 其他特性:丰富的消息拉取模型、高效订阅者水平扩展、实时的消息订阅、亿级的消息堆积能力、定期删除机制;
优点
- 客户端语言丰富:支持Java、.Net、PHP、Ruby、Python、Go等多种语言;
- 高性能:单机写入TPS约在100万条/秒,消息大小10个字节;
- 提供完全分布式架构,并有replica机制,拥有较高的可用性和可靠性,理论上支持消息无限堆积;
- 支持批量操作;
- 消费者采用Pull方式获取消息。消息有序,通过控制能够保证所有消息被消费且仅被消费一次;
- 有优秀的第三方KafkaWeb管理界面Kafka-Manager;
- 在日志领域比较成熟,被多家公司和多个开源项目使用。
缺点
- Kafka单机超过64个队列/分区时,Load时会发生明显的飙高现象。队列越多,负载越高,发送消息响应时间变长;
- 使用短轮询方式,实时性取决于轮询间隔时间;
- 消费失败不支持重试;
- 支持消息顺序,但是一台代理宕机后,就会产生消息乱序;
- 社区更新较慢。
附和其他MQ速度对比:

对于CAP理论,Eureka选择的是AP还是CP?它保证了一致性还是可用性?
1.CAP指的是 一致性(Consistency) ,可用性(Availability), 分区容错性(Partition tolerance) ,在分布式中,网络是不可控的,所以首先要保证 P ,然后在A和C之间做选择。 要么AP ,要么CP 。
2.Eureak选择AP 保证了可用性降低了一致性 , Nacos 默认 AP ,可以 CP和AP可以切换 , Zookeeper 就是 CP ; Redis AP
tail -f xxx.log ----实时刷新最新日志
tail -100f xxx.log --------实时刷新最新的100行日志
tail -100f xxx.log | grep [关键字] -------查找最新的一百行中与关键字匹配的行
tail -100f xxx.log | grep ‘2019-10-29 16:4[0-9]’ ------查找最新的100行中时间范围在2019-10-29 16:40-2019-10-29 16:49范围中的行
tail -1000f xxx.log | grep -A 5 [关键字] ----------查看最新的1000行中与关键字匹配的行加上匹配行后的
过前面的博客总结,可以知道的是,HashMap是有一个一维数组和一个链表组成,从而得知,在解决冲突问题时,hashmap选择的是链地址法。为什么HashMap会用一个数组这链表组成,当时给出的答案是从那几种解决冲突的算法中推论的,这里给出一个正面的理由:
1,为什么用了一维数组:数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难
2,为什么用了链表:链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易
而HashMap是两者的结合,用一维数组存放散列地址,以便更快速的遍历;用链表存放地址值,以便更快的插入和删除!
一 、环形链表的形成分析
那么,在HashMap中,到底是怎样形成环形链表的?这个问题,得从HashMap的resize扩容问题说起!
备注:本博客中所示源码,均为java 7版本
HashMap的扩容原理:
[java] view plain copy
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
当HashMap中的元素个数超过数组大小(数组总大小length,不是数组中个数size)loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过160.75=12(这个值就是代码中的threshold值,也叫做临界值)的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
再看源码中,关于扩容resize()的实现:
总得来说,就是拷贝旧的数据元素,从新新建一个更大容量的空间,然后进行数据复制!
那么关于环形链表的形成,则主要在这扩容的过程。当多个线程同时对这个HashMap进行put操作,而察觉到内存容量不够,需要进行扩容时,多个线程会同时执行resize操作,而这就出现问题了,问题的原因分析如下:
首先,在HashMap扩容时,会改变链表中的元素的顺序,将元素从链表头部插入。PS:说是为了避免尾部遍历,这一部分不是本博客的主要介绍内容,后面再说。
而环形链表就在这一时刻发生,以下模拟2个线程同时扩容。假设,当前hashmap的空间为2(临界值为1),hashcode分别为0和1,在散列地址0处有元素A和B,这时候要添加元素C,C经过hash运算,得到散列地址为1,这时候由于超过了临界值,空间不够,需要调用resize方法进行扩容,那么在多线程条件下,会出现条件竞争,模拟过程如下:
Java并发编程:volatile关键字解析
大家都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
也就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如下面的这段代码:
i = i + ``1``;
当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。