YOLOv7改进:CBAM注意力机制
目录
1.介绍
1.1、论文的出发点
1.2、论文的主要工作
1.3、CBAM模块的具体介绍
2.YOLOv7改进
2.1yaml 配置文件如下
2.2common.py配置
2.3yolo.py配置
1.介绍
1.1、论文的出发点
cnn基于其丰富的表征能力,极大地推动了视觉任务的完成,为了提高cnn网络的性能,最近的研究主要聚焦在网络的三个重要因素:深度、宽度和基数。除了这些因素,作者还研究了网络架构的一个不同方面——注意力。注意力研究的目标是通过使用注意机制来增加表现能力:关注重要的特征,并抑制不必要的特征。在本文中,作者提出了一个新的网络模块,名为“卷积块注意模块”(CBAM),该模块用来强调这两个主要维度上的有意义的特征:通道和空间轴,该模块实现方式是通过学习强调或抑制哪些信息,有效地帮助信息在网络中流动。
1.2、论文的主要工作
1. 提出了一种简单而有效的注意力模块(CBAM),可广泛应用于增强cnn的表示能力。
2. 作者验证了该注意模块的有效性,通过广泛的消融试验。
3. 通过插入CBAM,作者验证了在多个基准测试(ImageNet-1K, MS COCO,和VOC 2007)上,各种网络的性能都得到了极大的改善。
1.3、CBAM模块的具体介绍
CBAM注意力机制是由通道注意力机制(channel)和空间注意力机制(spatial)组成。
传统基于卷积神经网络的注意力机制更多的是关注对通道域的分析,局限于考虑特征图通道之间的作用关系。CBAM从 channel 和 spatial 两个作用域出发,引入空间注意力和通道注意力两个分析维度,实现从通道到空间的顺序注意力结构。空间注意力可使神经网络更加关注图像中对分类起决定作用的像素区域而忽略无关紧要的区域,通道注意力则用于处理特征图通道的分配关系,同时对两个维度进行注意力分配增强了注意力机制对模型性能的提升效果。
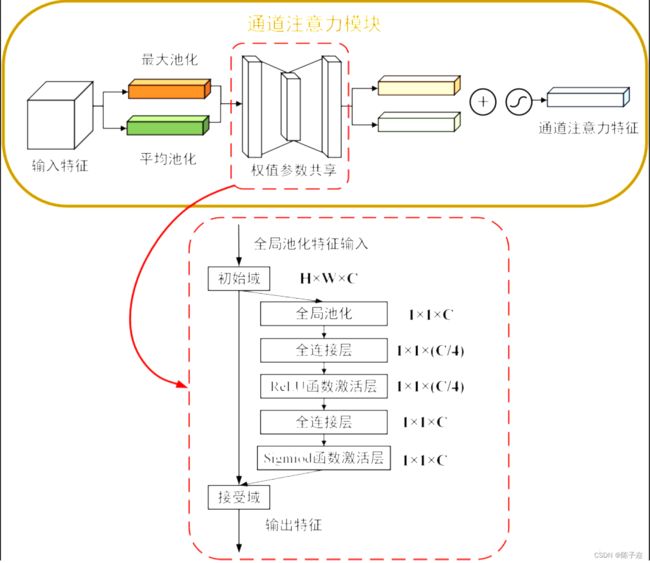
CBAM中的通道注意力机制模块流程图如下。先将输入特征图分别进行全局最大池化和全局平均池化,对特征映射基于两个维度压缩,获得两张不同维度的特征描述。池化后的特征图共用一个多层感知器网络,先通过一个全连接层下降通道数,再通过另一个全连接恢复通道数。将两张特征图在通道维度堆叠,经过 sigmoid 激活函数将特征图的每个通道的权重归一化到0-1之间。将归一化后的权重和输入特征图相乘。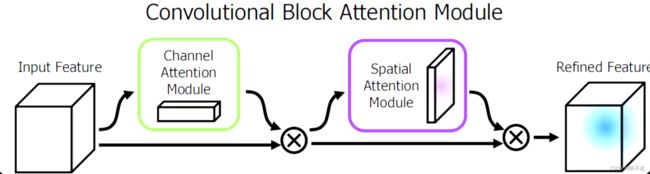
该模块有两个顺序子模块:通道(Channel)和空间(Spatial)。
1. Channel attention modul
目的:利用特征的通道间关系生成通道注意图。
方法:通道维度不变,压缩输入特征图的空间维度。
2. Spatial attention module

目的:利用特征间的空间关系生成空间注意图。
方法:空间维度不变,压缩通道维度。
步骤:
(1)AP和MP操作:首先特征图F'使用AP(average pooling)和MP(max pooling)操作得到两个1*H*W的特征图。
(2)拼接和卷积:将它们拼接在一起得到一个2*H*W的特征图,再通过一个7x7的卷积重新得到1*H*W的特征图。
(3)sigmoid:最后,通过一个sigmoid函数,得到包含空间注意力的特征图。原文中没有给予这个特征图命名符,为了方便将其称之为z。
2.YOLOv7改进
2.1yaml 配置文件如下
# YOLOv7 , GPL-3.0 license
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov7 backbone by yoloair
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, CNeB, [128]],
[-1, 1, Conv, [256, 3, 2]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]],
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]],
[-1, 1, CNeB, [1024]],
[-1, 1, Conv, [256, 3, 1]],
]
# yolov7 head by yoloair
head:
[[-1, 1, SPPCSPC, [512]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[31, 1, Conv, [256, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3C2, [128]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[18, 1, Conv, [128, 1, 1]],
[[-1, -2], 1, Concat, [1]],
[-1, 1, C3C2, [128]],
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, CBAM, [128]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 44], 1, Concat, [1]],
[-1, 1, C3C2, [256]],
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 39], 1, Concat, [1]],
[-1, 3, C3C2, [512]],
# 检测头 -----------------------------
[49, 1, RepConv, [256, 3, 1]],
[55, 1, RepConv, [512, 3, 1]],
[61, 1, RepConv, [1024, 3, 1]],
[[62,63,64], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]
2.2common.py配置
./models/common.py文件增加以下模块
class ChannelAttentionModule(nn.Module):
def __init__(self, c1, reduction=16):
super(ChannelAttentionModule, self).__init__()
mid_channel = c1 // reduction
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.shared_MLP = nn.Sequential(
nn.Linear(in_features=c1, out_features=mid_channel),
nn.LeakyReLU(0.1, inplace=True),
nn.Linear(in_features=mid_channel, out_features=c1)
)
self.act = nn.Sigmoid()
#self.act=nn.SiLU()
def forward(self, x):
avgout = self.shared_MLP(self.avg_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
maxout = self.shared_MLP(self.max_pool(x).view(x.size(0),-1)).unsqueeze(2).unsqueeze(3)
return self.act(avgout + maxout)
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.act = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.act(self.conv2d(out))
return out
class CBAM(nn.Module):
def __init__(self, c1,c2):
super(CBAM, self).__init__()
self.channel_attention = ChannelAttentionModule(c1)
self.spatial_attention = SpatialAttentionModule()
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
2.3yolo.py配置
在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m is CBAM:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2]