第十一天
备份恢复
mysql数据损坏类型
- 物理损坏
- 磁盘损坏:硬件,磁道坏,dd,格式化
- 文件损坏:数据文件损坏,redo损坏
- 逻辑损坏
- drop
- delete
- truncate
- update
DBA运维人员在备份、恢复的职责
- 设计备份、容灾策略
- 备份策略
- 备份工具选择
- 备份周期设计
- 备份监控方法
- 容灾策略
- 备份:什么备份
- 架构:高可用,延迟从库,灾备库
- 备份策略
- 定期的备份、容灾检查
- 定期的故障恢复演练
- 数据损坏时的快速准确恢复
- 数据迁移工作
mysql常用备份工具
- 逻辑备份方式
- mysqldump(MDP)
- 数据量较少,使用它。100G以内
- 可读性比较强,压缩比高,节省空间。不需要下载安装
- 备份时间相对较长。恢复时间长
- mydumper
- load data in file
- 主从方式(replication)
- mysqldump(MDP)
- 物理备份方式
- mysql enterprise backup(企业版)
- percona Xtrabackup(PBK,XBK)
mysqldump(MDP)应用
- 介绍
- 逻辑备份工具。备份的是sql语句
- innodb可以采取快照备份的方式。开启一个独立的事务,获取当前最新的一致性快照。将快照数据,放在临时表中,转换成sql(create table,create table ,insert),保存到sql文件中
- 非innodb表,需要锁表备份。触发FTWRL,全局锁表。转换成sql(create table,create table ,insert),保存到sql文件中
- ==核心参数==
- 连接参数
- -u
- -p
- -h
- -P
- -S
- 备份参数
- -A 全备
- -B 备份1个或多个库
- 备份==高级参数==
- ==--master-data=2==
- 备份时自动记录binlog信息
- 自动锁表和解锁
- 配合single transaction可以减少锁表时间
- ==--single-transaction==
- 对于innodb引擎备份时,开启一个独立事务,获取一致性快照进行备份
- -R -E --triggers
- --max_allowed_packet=64M
- 最大可以设置:128M
- 这个是针对客户端的,不是对server端的
- ==select @@max_allowed_packet;==
- 服务器端默认:4M
- ==--master-data=2==
- 连接参数
mkdir -p /data/backup
chown -R mysql.mysql /data/*
mysqldump -uroot -pxxx -S /tmp/mysql.sock -A > /data/backup/full.sql
mysqldump -uroot -pxxx -B world test > /data/backup/db.sql
### 备份库中单个表,多个表
mysqldump -uroot -pxxx database_name table_name1 table_name2 > /data/backup/table.sql
### 下面参数很重要,生产必备命令
mysqldump -uroot -pxxx -S /tmp/mysql.sock -A --master-data=2 --single-transaction -R -E --triggers --max_allowed_packet=64M > /data/backup/full.sql
基于mysqldump+binlog故障恢复案列
案列场景:
基础环境:centos7.6+mysql 5.7.28,lnmt网站业务,数据量100G(备份大概1个小时以内,不是固态盘),每天5-10M数据增长
备份策略:mysqldump每天全备,binlog定时备份
故障模拟:周三上午10点数据故障,例如:核心业务库被误删除
恢复思路:
- 挂维护页
- 找测试库
- 恢复周二全备
- 截取周二全备到周三上午10点误删除之前的binlog,并恢复
- 测试业务功能正常
- 恢复业务
- 故障库导回原生产
- 直接用测试库承担生产,先跑着
### 故障模拟演练 #### 1.准备数据 create database backup; use backup; create table t1 (id int); insert into t1 values(1),(2),(3); commit; rm -rf /backup/* #### 2.周二23:00全备 mysqldump -uroot -p123 -A -R -E --triggers --set-gtid-purged=OFF --master-data=2 --single-transaction --max_allowed_packet=64M|gzip > /backup/full_$(date +%F).sql.gz #### 3.模拟周二 23:00到周三 10点之间数据变化 use backup; insert into t1 values(11),(22),(33); commit; create table t2 (id int); insert into t2 values(11),(22),(33); #### 4.模拟故障,删除表(只是模拟,不代表生产操作) drop database backup; ### 恢复过程 #### 1.准备临时数据库 systemctl start mysqld3307 #### 2.准备备份 #####(1)准备全备: cd /backup gunzip full_2018-10-17.sql.gz ######(2)截取二进制日志 -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000036',MASTER_LOG_POS=793; mysqlbinlog --skip-gtids --include-gtids='3ca79ab5-3e4d-11e9-a709-000c293b577e:6-7' /data/binlog/mysql-bin.000036 >/backup/bin.sql #### 3.恢复备份到临时库 mysql -S /data/3307/mysql.sock set sql_log_bin=0; source /backup/full_2018-10-17.sql; source /backup/bin.sql; #### 4.将故障表导出并恢复到生产 mysqldump -S /data/3307/mysql.sock backup t1 -R -E --triggers --set-gtid-purged=OFF --master-data=2 --single-transaction --max_allowed_packet=64M >/backup/t1.sql mysql -uroot -p123 set sql_log_bin=0; use backup; source /backup/t1.sql; set sql_log_bin=1;
实现所有表的单独备份
### 提示:
#### information_schema.tables
mysqldump -uroot -p123 world city -A -R -E --triggers --set-gtid-purged=OFF --master-data=2 --single-transaction --max_allowed_packet=64M >/backup/world_city.sql
select concat("mysqldump -uroot -p123 ",table_schema," ",table_name," --master-data=2 --single-transaction --set-gtid-purged=0 -R -E --triggers --max_allowed_packet=64M>/backup/",table_schema,"_",table_name,".sql") from information_schema.tables where table_schema not in ('sys','information_schema','performance_schema');
压缩备份并添加时间戳
mysqldump -uroot -p123 -A -R -E --triggers --master-data=2 --single-transaction|gzip > /backup/full_$(date +%F).sql.gz
mysqldump -uroot -p123 -A -R -E --triggers --master-data=2 --single-transaction|gzip > /backup/full_$(date +%F-%T).sql.gz
### mysqldump备份的恢复方式(在生产中恢复要谨慎,恢复会删除重复的表)
set sql_log_bin=0;
source /backup/full_2018-06-28.sql
### 注意:
1、mysqldump在备份和恢复时都需要mysql实例启动为前提。
2、一般数据量级100G以内,大约15-45分钟可以恢复,数据量级很大很大的时候(PB、EB)
3、mysqldump是覆盖形式恢复的方法。
### 一般我们认为,在同数据量级,物理备份要比逻辑备份速度快.
逻辑备份的优势:
1、可读性强
2、压缩比很高
模拟故障案例并恢复
### 需求: 利用全备+binlog回复数据库误删除之前。
#### 故障模拟及恢复:
##### 1. 模拟周一23:00的全备
mysqldump -uroot -p -A -R -E --triggers --master-data=2 --single-transaction --set-gtid-purged=OFF --max_allowed_packet=64M>/data/backup/full.sql
##### 2. 模拟白天的数据变化
Master [(none)]>create database day1 charset utf8;
Master [(none)]>use day1
Master [day1]>create table t1(id int);
Master [day1]>insert into t1 values(1),(2),(3);
Master [day1]>commit;
Master [world]>update city set countrycode='CHN';
Master [world]>commit;
##### 模拟磁盘损坏:
[root@db01 data]# rm -rf /data/mysql/data/*
##### 3. 恢复故障
[root@db01 data]# pkill mysqld
[root@db01 data]# \rm -rf /data/mysql/data/*
##### 4. 恢复思路
######1.检查备份可用性
######2.从备份中获取二进制日志位置
######3.根据日志位置截取需要的二进制日志
######4.初始化数据库,并启动
######5.恢复全备
######6.恢复二进制日志
==从mysqldump 全备中获取 库和表的备份==
### 1、获得表结构
sed -e'/./{H;$!d;}' -e 'x;/CREATE TABLE `city`/!d;q' full.sql>createtable.sql
### 2、获得INSERT INTO 语句,用于数据的恢复
grep -i 'INSERT INTO `city`' full.sqll >data.sql &
### 3.获取单库的备份
sed -n '/^-- Current Database: `world`/,/^-- Current Database: `/p' all.sql >world.sql
percona xtrabackup(XBK、Xbackup)
安装
### 安装依赖包
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL libev
### 下载软件并安装
wget https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.12/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.12-1.el7.x86_64.rpm
#### https://www.percona.com/downloads/XtraBackup/Percona-XtraBackup-2.4.4/binary/redhat/6/x86_64/percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm
yum -y install percona-xtrabackup-24-2.4.4-1.el7.x86_64.rpm
介绍
物理备份工具,拷贝数据文件。原生态支持全备和增量
对于非Innodb表(比如 myisam)是,锁表cp数据文件,属于一种温备份。
- binlog只读,FTWRL,触发全局锁
- 拷贝非innodb表的数据
- 解锁
- 对于Innodb的表(支持事务的),不锁表,拷贝数据页,最终以数据文件的方式保存下来,把一部分redo和undo一并备走,属于热备方式。
- checkpoint,将已提交的数据页刷新到磁盘。记录一个LSN
- 拷贝innodb表相关的文件(ibdata1,frm,ibd......)
- 备份期间产生新的数据变化的redo也会备份走
4.再次统计LSN,写入到专用文件 5.记录二进制日志位置记录下来
- 所有备份文件统一存放在一个目录下
==xbk备份逻辑==
- checkpoint ,记录LSN号
- information_schema.xxx
- 拷贝innodb文件,过程中发生的新变化redo也会被保存,保存至备份路径
- binlog只读,FTWRL(global read lock)
- 拷贝non_innodb,拷贝完成后解锁
- 生成备份相关的信息文件,binlog,LSN
- 刷新last LSN
- 完成备份
XBK应用
-
前提
数据库启动
能连上数据库
vi /etc/my.cnf [client] socket=/tmp/mysql.sock [mysqld] datadir=/xxx ### xtrabackup默认会读取这行参数服务器端的工具,这个工具只能放在服务器端上
-
全备
- ==innobackupex --user=root --password=123 /data/xbk==
- ==innobackupex --user=root --password=123 --no-timestamp /data/xbk/full_`date +%F`==
-
备份结果的部分文件
-
-rw-r----- 1 root root 24 Jun 29 09:59 xtrabackup_binlog_info -rw-r----- 1 root root 119 Jun 29 09:59 xtrabackup_checkpoints -rw-r----- 1 root root 489 Jun 29 09:59 xtrabackup_info -rw-r----- 1 root root 2560 Jun 29 09:59 xtrabackup_logfile ### xtrabackup_binlog_info :(备份时刻的binlog位置) [root@db01 full]# cat xtrabackup_binlog_info mysql-bin.000003 536749 79de40d3-5ff3-11e9-804a-000c2928f5dd:1-7 记录的是备份时刻,binlog的文件名字和当时的结束的position,可以用来作为截取binlog时的起点。 ### xtrabackup_checkpoints : backup_type = full-backuped from_lsn = 0 上次所到达的LSN号(对于全备就是从0开始,对于增量有别的显示方法) to_lsn = 160683027 备份开始时间(ckpt)点数据页的LSN last_lsn = 160683036 备份结束后,redo日志最终的LSN compact = 0 recover_binlog_info = 0 (1)备份时刻,立即将已经commit过的,内存中的数据页刷新到磁盘(CKPT).开始备份数据,数据文件的LSN会停留在to_lsn位置。 (2)备份时刻有可能会有其他的数据写入,已备走的数据文件就不会再发生变化了。 (3)在备份过程中,备份软件会一直监控着redo的undo,如果一旦有变化会将日志也一并备走,并记录LSN到last_lsn。 从to_lsn ----》last_lsn 就是,备份过程中产生的数据变化.
-
==全备的恢复(XBK)==
破坏
pkill mysqld
rm -rf /data/3306/*
==准备备份(Prepared)==
### 将redo进行重做,已提交的写到数据文件,未提交的使用undo回滚掉。模拟了CSR的过程
innobackupex --apply-log /backup/xbk/full......
恢复备份
### 前提:
#### 1、被恢复的目录是空
#### 2、被恢复的数据库的实例是关闭
cp -a /backup/xbk/full....../* /data/3306/
chown -R mysql.mysql /data/*
/etc/init.d/mysqld start
XBK的增量备份恢复
备份
- 增量必须依赖于全备
- 每次增量都是参照上次备份的LSN号码(xtrabackup checkpoint),在此基础上变化的数据页,备份走,
- 并且会将备份过程中产生新的变化的redo一并备份走
恢复
- 将所有需要inc备份,按顺序合并到全备中
- 并且需要将每个备份进行prepare
==增量备份实战==
### 1.删掉原来备份
略.
### 2.全备(周日)
innobackupex --user=root --password --no-timestamp /backup/full >&/tmp/xbk_full.log
### 3.模拟周一数据变化
db01 [(none)]>create database cs charset utf8;
db01 [(none)]>use cs
db01 [cs]>create table t1 (id int);
db01 [cs]>insert into t1 values(1),(2),(3);
db01 [cs]>commit;
### 4.第一次增量备份(周一)
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/backup/full /backup/inc1 &>/tmp/inc1.log
### 5.模拟周二数据
db01 [cs]>create table t2 (id int);
db01 [cs]>insert into t2 values(1),(2),(3);
db01 [cs]>commit;
### 6.周二增量
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/backup/inc1 /backup/inc2 &>/tmp/inc2.log
### 7.模拟周三数据变化
db01 [cs]>create table t3 (id int);
db01 [cs]>insert into t3 values(1),(2),(3);
db01 [cs]>commit;
db01 [cs]>drop database cs;
### 8.恢复到周三误drop之前的数据状态
####恢复思路:
####1. 挂出维护页,停止当天的自动备份脚本
####2. 检查备份:周日full+周一inc1+周二inc2,周三的完整二进制日志
####3. 进行备份整理(细节),截取关键的二进制日志(从备份---误删除之前)
####4. 测试库进行备份恢复及日志恢复
####5. 应用进行测试无误,开启业务
####6. 此次工作的总结
==恢复过程==
### 1. 检查备份
1afe8136-601d-11e9-9022-000c2928f5dd:7-9
### 2. 备份整理(apply-log)+合并备份(full+inc1+inc2)
#### (1) 全备的整理
innobackupex --apply-log --redo-only /data/backup/full
#### (2) 合并inc1到full中
innobackupex --apply-log --redo-only --incremental-dir=/data/backup/inc1 /data/backup/full
#### (3) 合并inc2到full中
innobackupex --apply-log --incremental-dir=/data/backup/inc2 /data/backup/full
#### 最后一次整理全备
innobackupex --apply-log /data/backup/full
### 3. 截取周二 23:00 到drop 之前的 binlog
mysqlbinlog --skip-gtids --include-gtids='1afe8136-601d-11e9-9022-000c2928f5dd:7-9' /data/binlog/mysql-bin.000009 >/data/backup/binlog.sql
### 4.进行恢复
mkdir /data/mysql/data2 -p
cp -a * /data/mysql/data2
chown -R mysql. /data/*
systemctl stop mysqld
vim /etc/my.cnf
datadir=/data/mysql/data2
systemctl start mysqld
set sql_log_bin=0;
source /data/backup/binlog.sql
==小细节==
- 每次xbk恢复后,可以
reset master清除无用的gtid信息 - 每次故障恢复完后,立即做全备
- 如果出现增量合并不了怎么办?
- full+binlog方式恢复
第十二天
主从复制(replication)
介绍
- 两台或以上数据库实例,通过二进制日志,实现数据的“同步”关系。(不是真的同步,是异步的关系)
前提
- 两台以上mysql实例 ,server_id,server_uuid不同
- 主库开启二进制日志
- 专用的复制用户
- 保证主从开启之前的某个时间点,从库数据是和主库一致(补课)
- 告知从库,复制user,passwd,IP port,以及复制起点(change master to)
- 线程(三个):Dump thread , IO thread , SQL thread 开启(start slave)
==搭建(单机多实例主从复制)==
### 1.清理主库数据
rm -rf /data/3307/data/*
### 2.重新初始化3307
mysqld --initialize-insecure --user=mysql --basedir=/app/mysql --datadir=/data/3307/data
### 3.修改my.cnf ,开启二进制日志功能
vim /data/3307/my.cnf
log_bin=/data/3307/data/mysql-bin
### 4.启动所有节点
systemctl start mysqld3307
systemctl start mysqld3308
systemctl start mysqld3309
ps -ef |grep mysqld
mysql 3684 1 4 09:59 ? 00:00:00 /app/mysql/bin/mysqld --defaults-file=/data/3307/my.cnf
mysql 3719 1 7 09:59 ? 00:00:00 /app/mysql/bin/mysqld --defaults-file=/data/3308/my.cnf
mysql 3754 1 8 09:59 ? 00:00:00 /app/mysql/bin/mysqld --defaults-file=/data/3309/my.cnf
mysql -S /data/3307/mysql.sock -e "select @@server_id"
mysql -S /data/3308/mysql.sock -e "select @@server_id"
mysql -S /data/3309/mysql.sock -e "select @@server_id"
### 5.主库中创建复制用户
mysql -S /data/3307/mysql.sock
>grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
>select user,host from mysql.user;
### 6.备份主库并恢复到从库
mysqldump -S /data/3307/mysql.sock -A --master-data=2 --single-transaction -R -E --triggers >/backup/full.sql
#### -- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=653;
mysql -S /data/3308/mysql.sock
>source /backup/full.sql;
### 7.告知从库关键复制信息(从库)
#### ip port user password binlog position
mysql -S /data/3308/mysql.sock
>help change master to;
>CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=653,
MASTER_CONNECT_RETRY=10;
### 8. 开启主从专用线程(从库)
>start slave ;
### 9.检查复制状态(从库)
>show slave status \G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#### 如果搭建不成功,可以执行以下命令(从库),从6-8步骤重新来过
>stop slave;
>reset slave all;
主从复制原理
主从中涉及的资源
- 文件
- 主库:binlog文件
- 从库
- relay-log文件(默认文件名==`hostname`-relay-bin.000001==):存储接受的binlog
- ==手动定义==
- ==show variables like ''%relay%'';==
- ==relay_log_basename=/data/3308/data/db01-relay-bin==
- ==手动定义==
- master.info:连接主库的信息,已经接受binlog位置点信息
- ==show variables like ''%master%'';==
- ==master_info_repository=FILE/TABLE==
- relay.info(relay-log.info):记录从库回放到的relay-log的位置点
- ==relay_log_info_repository=FILE/TABLE==
- relay-log文件(默认文件名==`hostname`-relay-bin.000001==):存储接受的binlog
- 线程
- 主库:binlog_dump_Thread
- 用来接受从库请求,并且投递binlog给从库
- ==show processlist;==
- 从库
- io线程:请求binlog日志,接受binlog日志
- sql线程:回放relay日志
- 主库:binlog_dump_Thread
==原理==
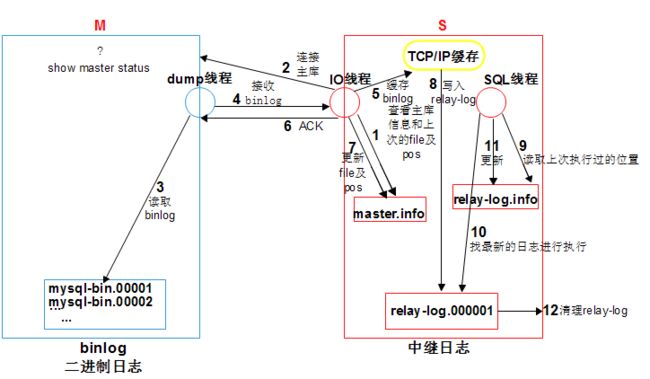
文字说明:
1. **S:**change master to 时,ip, port, user, password ,binlog position写入到**master.info**进行记录
- start slave 时,从库会启动IO线程和SQL线程
- IO_T,读取master.info信息,获取主库信息连接主库
- M:会生成一个准备binlog DUMP线程,来响应从库
- IO_T根据master.info记录的binlog文件名和position号,请求主库DUMP最新日志
- M:DUMP线程检查主库的binlog日志,如果有新的,TP(传送)给从从库的IO_T
- IO_T将收到的日志存储到了TCP/IP 缓存,立即返回ACK给主库 ,主库工作完成
- IO_T将缓存中的数据,存储到relay-log日志文件,更新master.info文件里的binlog 文件名和postion,IO_T工作完成
- SQL_T读取relay-log.info文件,获取到上次执行到的relay-log的位置,作为起点,回放relay-log
- SQL_T回放完成之后,会更新relay-log.info文件。
- relay-log会有自动清理的功能。
- ==relay_log_purge=on==
- 定期删除应用过的relay-log
细节:主库一旦有新的日志生成,会发送“信号”给binlog dump ,IO线程再请求
==上面图片上的7和8的顺序对调==
主从复制监控
主库
- show processlist;
- show slave host;
从库
- ==show slave status\G==
主从复制故障分析
主从中的线程管理
- start slave;
- stop slave;
- start slave io_thread;
- start slave sql_thread;
- stop slave io_thread;
- stop slave sql_thread;
解除从库身份
reset slave all;
show slave status \G
IO线程故障
故障原因
- 连接主库
- 网络、端口、防火墙
- 用户、密码、授权
- 主库连接数上限
- 版本不统一
- 请求日志,接受日志
- 主库二进制日志不完整:损坏,不连续
- 从库请求的起点问题
- 主从的server_id(server_uuid)相同
- relaylog问题
sql线程故障
回放relay-log中的日志。可以理解为执行relay-log sql
原因整理
- 创建的对象已经存在
- 需要操作的对象不存在
- 约束冲突
- 参数,版本
主库连接数上线,或者是主库太繁忙
> show slave staus \G
Last_IO_Errno: 1040
Last_IO_Error: error reconnecting to master '[email protected]:3307' - retry-time: 10 retries: 7
### 处理思路:
#### 拿复制用户,手工连接一下
mysql -urepl -p123 -h 10.0.0.51 -P 3307
mysql: [Warning] Using a password on the command line interface can be insecure.
ERROR 1040 (HY000): Too many connections
### 处理方法:
set global max_connections=300;
==sql线程故障的处理方法==
### 方法一:
stop slave;
set global sql_slave_skip_counter = 1;
#### 将同步指针向下移动一个,如果多次不同步,可以重复操作。
#### 使用这种方法,一定要保证此时故障数据是完全一致的,才能采用
#### 可以使用第三方工具,帮助我们检查主从数据一致,并可恶意修复主从不一致情况
#### pt工具,主从相关的===
start slave;
### 方法二:暴力方法,遇到自动跳过
/etc/my.cnf
slave-skip-errors = 1032,1062,1007
#### 常见错误代码:
#### 1007:对象已存在
#### 1032:无法执行DML
#### 1062:主键冲突,或约束冲突
### 但是,以上操作有时是有风险的,
### 最安全的做法就是备份恢复+重新构建主从---方法四(时间久)。把握一个原则,一切以主库为主.===
### 方法三:好===
#### 将从库进行反操作一下。重启线程
drop database xinzhan;
start slave sql_thread;
主从延时问题
- ==seconds_behind_master=0==
- 0秒,这个不能得出有或没有延时的情况
原因
- 外部
- 网络、主从硬件差异、版本差异、参数
- 内部
- 主库
- 二进制日志写入不及时
- 主库并发事务量大,主库可以并行,传送时是串行
- 主库发生了大事务,由于是串行传送,会产生阻塞后续的事务.
- 从库
- 从库默认情况下只有一个SQL,只能串行回放事务SQL
- 主库如果并发事务量较大,从库只能串行回放
- 主库发生了大事务,会阻塞后续的所有的事务的运行
- 主库
主库延时解决方案:
- 5.6 开始,开启GTID,实现了GC(group commit)机制,可以并行传输日志给从库IO
- 5.7 开始,不开启GTID,会自动维护匿名的GTID,也能实现GC,我们建议还是认为开启GTID
- 大事务拆成多个小事务,可以有效的减少主从延时.
从库延时解决方案:
- 5.6 版本开启GTID之后,加入了SQL多线程的特性,但是只能针对不同库(database)下的事务进行并发回放.
- 5.7 版本开始GTID之后,在SQL方面,提供了基于逻辑时钟(logical_clock),binlog加入了seq_no机制,真正实现了基于事务级别的并发回放,这种技术我们把它称之为MTS(enhanced multi-threaded slave).
- 大事务拆成多个小事务,可以有效的减少主从延时.
第十三天
延时从库
介绍
- 配置的一种特殊从库,人为配置从库和主库延时
- 一般企业建议3-6小时
数据库故障?
- 物理损坏:主从复制非常擅长解决物理损坏.
- 逻辑损坏:普通主从复制没办法解决逻辑损坏
延时从库:主库做了某项操作之后,从库延时多长时间回放(SQL)。可以处理逻辑损坏
配置延时从库
### SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行
### 一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间
mysql>stop slave;
mysql>CHANGE MASTER TO MASTER_DELAY = 300;
mysql>start slave;
mysql> show slave status \G
SQL_Delay: 300
SQL_Remaining_Delay: NULL
==应用==
### 故障模拟及恢复
#### 1.主库数据操作
create database relay charset utf8;
use relay
create table t1 (id int);
insert into t1 values(1);
drop database relay;
#### 2. 停止从库SQL线程
stop slave sql_thread;
#### 3. 找relaylog的截取起点和终点
##### 起点:
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 482
##### 终点:
show relaylog events in 'db01-relay-bin.000002'
| db01-relay-bin.000002 | 1046 | Xid | 7 | 2489 | COMMIT /* xid=144 */ |
| db01-relay-bin.000002 | 1077 | Anonymous_Gtid | 7 | 2554 | SET @@SESSION.GTID_NEXT= 'ANONYMOUS' |
mysqlbinlog --start-position=482 --stop-position=1077 /data/3308/data/db01-relay-bin.000002>/tmp/relay.sql
#### 4.从库恢复relaylog
source /tmp/relay.sql
#### 5.从库身份解除
stop slave;
reset slave all
过滤复制
主库
- show master status;
- binlog_do_db
- binlog_ignore_db
从库
- show slave status\G
- replicate_do_db
- replicate_ignore_db
实现过程
mysqldump -S /data/3307/mysql.sock -A --master-data=2 --single-transaction -R --triggers >/backup/full.sql
vim /backup/full.sql
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000002', MASTER_LOG_POS=154;
[root@db01 ~]# mysql -S /data/3309/mysql.sock
source /backup/full.sql
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000002',
MASTER_LOG_POS=154,
MASTER_CONNECT_RETRY=10;
start slave;
[root@db01 ~]# vim /data/3309/my.cnf
replicate_do_db=ppt
replicate_do_db=word
[root@db01 ~]# systemctl restart mysqld3309
### 主库:
Master [(none)]>create database word;
Query OK, 1 row affected (0.00 sec)
Master [(none)]>create database ppt;
Query OK, 1 row affected (0.00 sec)
Master [(none)]>create database excel;
Query OK, 1 row affected (0.01 sec)
半同步复制
- 主库执行新的事务,commit时,更新 show master status\G ,触发一个信号给
- binlog dump 接收到主库的 show master status\G信息,通知从库日志更新了
- 从库IO线程请求新的二进制日志事件
- 主库会通过dump线程传送新的日志事件,给从库IO线程
- 从库IO线程接收到binlog日志,当日志写入到磁盘上的relaylog文件时,给主库ACK_receiver线程
- ACK_receiver线程触发一个事件,告诉主库commit可以成功了
- 如果ACK达到了我们预设值的超时时间,半同步复制会切换为原始的异步复制.
在classic replication:传统异步非gtid复制工作模型下。会导致主从数据不一致情况。
在5.5版本为了保证主从数据的一致性问题,加入了半同步复制的组件(插件)
在主从结构中,都加入了半同步复制的插件
控制从库io是否将relaylog落盘,一旦落盘通过插件返回ack给主库ack_rec。接受到ack之后,主库的事务才能提交成功。在默认情况下,如果超过10秒没有返回ack,此次复制行为会切换为异步复制。
在5.6、5.7当中也加入了一些比较好的特性(after commit,after sync,无损...),也不能完全保证5个9以上的数据一致
如果生产业务比较关注==主从最终一致==。我们推荐可以使用==mgr的架构,或者pxc等一致性结构==
### 加载插件
#### 主:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
#### 从:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
### 查看是否加载成功:
show plugins;
### 启动:
#### 主:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
#### 从:
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
### 重启从库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
### 查看是否在运行
#### 主:
show status like 'Rpl_semi_sync_master_status';
#### 从:
show status like 'Rpl_semi_sync_slave_status';
### 这个是过渡的,可以不用操作
==GTID复制==
作用
- 主要保证主从复制中的高级的特性
GTID
- 5.6版本出现,没有默认开启
- 5.7中即使不开启,也有匿名的GTID的记录
- dump传输可以并行,sql线程并发回放提供了保障。5.7.17+的版本以后几乎都是GTID模式
配置过程
- 第一次开启的时候,读取relaylog的最后的gtid+读取==gtid_purge参数==,确认复制起点
### 清理环境
pkill mysqld
rm -rf /data/mysql/data/*
rm -rf /data/binlog/*3
### 准备配置文件
#### 主库db01:
cat > /etc/my.cnf <
EOF
#### slave1(db02):
cat > /etc/my.cnf <
EOF
#### slave2(db03):
cat > /etc/my.cnf <
EOF
####
gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates=1 --slave更新是否记入日志
### 初始化数据(三台)
mysqld --initialize-insecure --user=mysql --basedir=/data/mysql --datadir=/data/mysql/data
### 启动数据库
/etc/init.d/mysqld start
### 构建主从
### master:51
### slave:52,53
#### 51:
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
#### 52\53:
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123' ,
MASTER_AUTO_POSITION=1;
start slave;
##### MASTER_AUTO_POSITION=1
GTID从库误写入操作处理
### 查看监控信息
Last_SQL_Error: Error 'Can't create database 'oldboy'; database exists' on query. Default database: 'oldboy'. Query: 'create database oldboy'
Retrieved_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-3
Executed_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-2,
7ca4a2b7-4aae-11e9-859d-000c298720f6:1
#### 注入空事物的方法:
stop slave;
set gtid_next='99279e1e-61b7-11e9-a9fc-000c2928f5dd:3';
begin;commit;
set gtid_next='AUTOMATIC';
### 这里的xxxxx:N 也就是你的slave sql thread报错的GTID,或者说是你想要跳过的GTID。
### 最好的解决方案:重新构建主从环境
GTID 复制和普通复制的区别
(0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover
(1)额外功能参数(3个)
(2)change master to 的时候不再需要binlog 文件名和positio号,MASTER_AUTO_POSITION=1;
(3)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的 GTID号
(4) mysqldump备份时,默认会将备份中包含的事务操作,以以下方式
SET @@GLOBAL.GTID_PURGED='8c49d7ec-7e78-11e8-9638-000c29ca725d:1';
告诉从库,我的备份中已经有以上事务,你就不用运行了,直接从下一个GTID开始请求binlog就行。
第十四天
MHA
介绍
高可用架构
(1)单活:MMM架构——mysql-mmm(google)
(2)单活:MHA架构——mysql-master-ha(日本DeNa),T-MHA
(3)多活:MGR ——5.7 新特性 MySQL Group replication(5.7.17) --->Innodb Cluster
(4)多活:MariaDB Galera Cluster架构,(PXC)Percona XtraDB Cluster、MySQL Cluster(Oracle rac)架构xenon???
Orchestrator???
https://www.cnblogs.com/konggg/category/1493418.html
https://www.zhihu.com/column/c_1212787509211766784
http://wubx.net/
https://www.cnblogs.com/fengjian2016/category/1029383.html
https://www.cnblogs.com/geek-ace/
https://www.cnblogs.com/zhoujinyi/
https://github.com/openark
https://www.cnblogs.com/gomysql/
高性能架构
读写分离架构(读性能较高)
- 代码级别
- MySQL proxy (Atlas,mysql router,proxySQL(percona),maxscale)、amoeba(taobao)、xx-dbproxy等。
分布式架构(读写性能都提高):
- 分库分表——cobar--->TDDL(头都大了),DRDS
- Mycat--->DBLE自主研发等
- NewSQL-->TiDB
==MHA架构工作原理==
主库宕机处理过程:
监控节点 (通过配置文件获取所有节点信息)
系统,网络,SSH连接性
主从状态,重点是主库选主
(1) 如果判断从库(position或者GTID),数据有差异,最接近于Master的slave,成为备选主
(2) 如果判断从库(position或者GTID),数据一致,按照配置文件顺序,选主.
(3) 如果设定有权重(candidate_master=1),按照权重强制指定备选主.默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效.
如果check_repl_delay=0的化,即使落后很多日志,也强制选择其为备选主
数据补偿
(1) 当SSH能连接,从库对比主库GTID 或者position号,立即将二进制日志保存至各个从节点并且应用(save_binary_logs )
(2) 当SSH不能连接, 对比从库之间的relaylog的差异(apply_diff_relay_logs)Failover
将备选主进行身份切换,对外提供服务
其余从库和新主库确认新的主从关系应用透明(VIP)
故障切换通知(send_reprt)
二次数据补偿(binlog_server)
自愈自治(待开发...)
MHA高可用架构介绍
1主2从,master:db01 slave:db02 db03 :
MHA 高可用方案软件构成
- Manager软件:选择一个从节点安装
- Node软件:
所有节点都要安装
MHA软件构成
Manager工具包主要包括以下几个工具:
- masterha_manger 启动MHA
- masterha_check_ssh 检查MHA的SSH配置状况
- masterha_check_repl 检查MySQL复制状况
- masterha_master_monitor 检测master是否宕机
- masterha_check_status 检测当前MHA运行状态
- masterha_master_switch 控制故障转移(自动或者手动)
- masterha_conf_host 添加或删除配置的server信息
Node工具包主要包括以下几个工具:
- save_binary_logs 保存和复制master的二进制日志
- apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的
- purge_relay_logs 清除中继日志(不会阻塞SQL线程)
- 这些工具通常由MHA Manager的脚本触发,无需人为操作
==MHA环境搭建==
### 1.规划
主库: 51 node
从库:
52 node
53 node manager
### 2.配置关键程序软连接
#### 2.之前,需要准备环境(略。1主2从GTID)
ln -s /data/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /data/mysql/bin/mysql /usr/bin/mysql
### 3.配置各节点互信
#### db01:
rm -rf /root/.ssh
ssh-keygen
cd /root/.ssh
mv id_rsa.pub authorized_keys
scp -r /root/.ssh 10.0.0.52:/root
scp -r /root/.ssh 10.0.0.53:/root
#### 各节点验证
#### db01:
ssh 10.0.0.51 date
ssh 10.0.0.52 date
ssh 10.0.0.53 date
#### db02:
ssh 10.0.0.51 date
ssh 10.0.0.52 date
ssh 10.0.0.53 date
#### db03:
ssh 10.0.0.51 date
ssh 10.0.0.52 date
ssh 10.0.0.53 date
### 4.安装软件
mha官网:https://code.google.com/archive/p/mysql-master-ha/
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
#### 所有节点安装node软件依赖包
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
#### 所有节点创建mha需要的用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
#### Manager软件安装(db03)
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
### 5.配置文件准备(db03)
#### 创建配置文件目录
mkdir -p /etc/mha
#### 创建日志目录
mkdir -p /var/log/mha/app1
#### 编辑mha配置文件
#### app1.cnf表示是这个业务的名字
vim /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/usr/local/bin/master_ip_failover
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
### 6.状态检查
#### 互信检查
masterha_check_ssh --conf=/etc/mha/app1.cnf
Fri Apr 19 16:39:34 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Apr 19 16:39:34 2019 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Fri Apr 19 16:39:34 2019 - [info] Reading server configuration from /etc/mha/app1.cnf..
Fri Apr 19 16:39:34 2019 - [info] Starting SSH connection tests..
Fri Apr 19 16:39:35 2019 - [debug]
Fri Apr 19 16:39:34 2019 - [debug] Connecting via SSH from [email protected](10.0.0.51:22) to [email protected](10.0.0.52:22)..
Fri Apr 19 16:39:34 2019 - [debug] ok.
Fri Apr 19 16:39:34 2019 - [debug] Connecting via SSH from [email protected](10.0.0.51:22) to [email protected](10.0.0.53:22)..
Fri Apr 19 16:39:35 2019 - [debug] ok.
Fri Apr 19 16:39:36 2019 - [debug]
Fri Apr 19 16:39:35 2019 - [debug] Connecting via SSH from [email protected](10.0.0.52:22) to [email protected](10.0.0.51:22)..
Fri Apr 19 16:39:35 2019 - [debug] ok.
Fri Apr 19 16:39:35 2019 - [debug] Connecting via SSH from [email protected](10.0.0.52:22) to [email protected](10.0.0.53:22)..
Fri Apr 19 16:39:35 2019 - [debug] ok.
Fri Apr 19 16:39:37 2019 - [debug]
Fri Apr 19 16:39:35 2019 - [debug] Connecting via SSH from [email protected](10.0.0.53:22) to [email protected](10.0.0.51:22)..
Fri Apr 19 16:39:35 2019 - [debug] ok.
Fri Apr 19 16:39:35 2019 - [debug] Connecting via SSH from [email protected](10.0.0.53:22) to [email protected](10.0.0.52:22)..
Fri Apr 19 16:39:36 2019 - [debug] ok.
Fri Apr 19 16:39:37 2019 - [info] All SSH connection tests passed successfully.
#### 主从状态检查
[root@db03 ~]# masterha_check_repl --conf=/etc/mha/app1.cnf
Fri Apr 19 16:40:50 2019 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Apr 19 16:40:50 2019 - [info] Reading application default configuration from /etc/mha/app1.cnf..
Fri Apr 19 16:40:50 2019 - [info] Reading server configuration from /etc/mha/app1.cnf..
Fri Apr 19 16:40:50 2019 - [info] MHA::MasterMonitor version 0.56.
Fri Apr 19 16:40:51 2019 - [info] GTID failover mode = 1
Fri Apr 19 16:40:51 2019 - [info] Dead Servers:
Fri Apr 19 16:40:51 2019 - [info] Alive Servers:
Fri Apr 19 16:40:51 2019 - [info] 10.0.0.51(10.0.0.51:3306)
Fri Apr 19 16:40:51 2019 - [info] 10.0.0.52(10.0.0.52:3306)
Fri Apr 19 16:40:51 2019 - [info] 10.0.0.53(10.0.0.53:3306)
Fri Apr 19 16:40:51 2019 - [info] Alive Slaves:
Fri Apr 19 16:40:51 2019 - [info] 10.0.0.52(10.0.0.52:3306) Version=5.7.20-log (oldest major version between slaves) log-bin:enabled
Fri Apr 19 16:40:51 2019 - [info] GTID ON
Fri Apr 19 16:40:51 2019 - [info] Replicating from 10.0.0.51(10.0.0.51:3306)
Fri Apr 19 16:40:51 2019 - [info] 10.0.0.53(10.0.0.53:3306) Version=5.7.20-log (oldest major version between slaves) log-bin:enabled
Fri Apr 19 16:40:51 2019 - [info] GTID ON
Fri Apr 19 16:40:51 2019 - [info] Replicating from 10.0.0.51(10.0.0.51:3306)
Fri Apr 19 16:40:51 2019 - [info] Current Alive Master: 10.0.0.51(10.0.0.51:3306)
Fri Apr 19 16:40:51 2019 - [info] Checking slave configurations..
Fri Apr 19 16:40:51 2019 - [info] read_only=1 is not set on slave 10.0.0.52(10.0.0.52:3306).
Fri Apr 19 16:40:51 2019 - [info] read_only=1 is not set on slave 10.0.0.53(10.0.0.53:3306).
Fri Apr 19 16:40:51 2019 - [info] Checking replication filtering settings..
Fri Apr 19 16:40:51 2019 - [info] binlog_do_db= , binlog_ignore_db=
Fri Apr 19 16:40:51 2019 - [info] Replication filtering check ok.
Fri Apr 19 16:40:51 2019 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking.
Fri Apr 19 16:40:51 2019 - [info] Checking SSH publickey authentication settings on the current master..
Fri Apr 19 16:40:51 2019 - [info] HealthCheck: SSH to 10.0.0.51 is reachable.
Fri Apr 19 16:40:51 2019 - [info]
10.0.0.51(10.0.0.51:3306) (current master)
+--10.0.0.52(10.0.0.52:3306)
+--10.0.0.53(10.0.0.53:3306)
Fri Apr 19 16:40:51 2019 - [info] Checking replication health on 10.0.0.52..
Fri Apr 19 16:40:51 2019 - [info] ok.
Fri Apr 19 16:40:51 2019 - [info] Checking replication health on 10.0.0.53..
Fri Apr 19 16:40:51 2019 - [info] ok.
Fri Apr 19 16:40:51 2019 - [warning] master_ip_failover_script is not defined.
Fri Apr 19 16:40:51 2019 - [warning] shutdown_script is not defined.
Fri Apr 19 16:40:51 2019 - [info] Got exit code 0 (Not master dead).
MySQL Replication Health is OK.
### 7.开启MHA(DB03)
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
### 8.查看MHA状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:4719) is running(0:PING_OK), master:10.0.0.51
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.51 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 51 |
+---------------+-------+
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.52 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 52 |
+---------------+-------+
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.53 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 53 |
+---------------+-------+
MHA Failover过程原理
高可用:最擅长的是为我们解决物理损坏
- 启动manager
- 调用masterha_manager脚本启动manager程序
- 监控
- 通过masterha_master_monitor心跳检测脚本,数据库节点,主要监控主库
- 默认探测4次,每隔(==ping_interval=2==)秒,如果主库还没有心跳,认为主库宕机,进入failover过程
- 选主
- 优先级(主观),如果在节点配置时,加入==candidate_master=1==参数
- 如果备选主,日志量落后master太多(后master 100M的relay logs的话),也不会被选择为新主
- 可以通过==check_repl_delay=0==,不检查日志落后的情况
- 日志量最接近主库
- 日志量一样,配置文件顺序
- 优先级(主观),如果在节点配置时,加入==candidate_master=1==参数
- 日志补偿
- ssh能连上,通过==save_binary_logs==立即保存缺失部分的日志到从库(/var/tmp目录下)并恢复
- ssh不能连,两个从库进行relay log日志diff(==apply_diff_relay_logs==)差异补偿
- 主从身份切换,所有从库取消和原有主库的复制关系(stop slave ;reset slave all)。新主库和剩余从库重新构建主从关系
- 故障库自动被剔除集群(==master_conf_host==配置信息去掉)
- MHA是一次性的高可用,failover后,manger自动退出
不足的地方:
- 数据补偿
- 自动提醒
- 自愈功能(待开发)
- 应用透明(vip)
==MHA+K8S+Operator官方==
==8.0 MGR+MYSQLSH==
应用透明vip功能
### master_ip_failover_script=/usr/local/bin/master_ip_failover
### 注意:/usr/local/bin/master_ip_failover,必须事先准备好
vi /usr/local/bin/master_ip_failover
#### 修改一下几行
my $vip = '10.0.0.55/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
vi /etc/mha/app1.cnf
#### 添加这一行
master_ip_failover_script=/usr/local/bin/master_ip_failover
dos2unix /usr/local/bin/master_ip_failover
dos2unix: converting file /usr/local/bin/master_ip_failover to Unix format ...
chmod +x /usr/local/bin/master_ip_failover
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
==binlog server==
### binlogserver配置:
#### 找一台额外的机器,必须要有5.6以上的版本,支持gtid并开启,我们直接用的第二个slave(db03)
vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=10.0.0.53
master_binlog_dir=/data/mysql/binlog
mkdir -p /data/mysql/binlog
chown -R mysql.mysql /data/*
#### 修改完成后,将主库binlog拉过来(从000001开始拉,之后的binlog会自动按顺序过来)
cd /data/mysql/binlog -----》必须进入到自己创建好的目录
mysqlbinlog -R --host=10.0.0.51 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
#### ==拉取日志的起点,需要按照目前从库的已经获取到的二进制日志点为起点==
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
邮件提箱
### 1. 准备邮件脚本
####(1)准备发邮件的脚本(上传 email_2019-最新.zip中的脚本,到/usr/local/bin/中)
####(2)将准备好的脚本添加到mha配置文件中,让其调用
#### 可以自己用python发邮件写的脚本
### 2. 修改manager配置文件,调用邮件脚本
vi /etc/mha/app1.cnf
report_script=/usr/local/bin/send
### 3. 停止MHA
masterha_stop --conf=/etc/mha/app1.cnf
### 4. 开启MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
测试mha failover功能
宕掉主库
- 查看vip
- 主从状态
- 查看邮件
- 切换日志
- 故障库是否剔除
- masterha_manager+mysqlbinlog停掉
==故障修复思路==
- 排查进程状态
- ps -ef|gerp manager
- masterha_check_status --conf=/etc/mha/app1.cnf
- 检查配置文件中的节点情况
- cat /etc/mha/app1.cnf
- 如果节点已经被移除,说明切换过程已经大部分成功
- 如果节点还在,证明切换过程在中间卡住
- 看日志
- ==cat /var/log/mha/app1/manager==
- 修复故障库
- /etc/init.d/mysqld start
- .......
- 修复主从
- 将故障库修好后,手动加入已有的主从中,作为从库
- 将配置文件修复(配置文件节点信息还在,可忽略)
- 检查ssh互信和repl的主从关系
- masterha_check_ssh --conf=/etc/mha/app1.cnf
- masterha_check_repl --conf=/etc/mha/app1.cnf
- 修复binlogserver
- cd /data/mysql/binlog
- rm -rf ./*
- mysqlbinlog -R --host=10.0.0.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
- 10.0.0.52为啥不是10.0.0.51
- 检查主节点的vip的状态
- 如果不在,再手工生成一下
- 启动mha
- nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
- masterha_check_status --conf=/etc/mha/app1.cnf
atlas
Atlas是由 Qihoo 360, Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。
它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。
360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。
下载地址:https://github.com/Qihoo360/Atlas/releases
注意:
1、Atlas只能安装运行在64位的系统上
2、Centos 5.X安装 Atlas-XX.el5.x86_64.rpm,Centos 6.X安装Atlas-XX.el6.x86_64.rpm。
3、后端mysql版本应大于5.1,建议使用Mysql 5.6以上
自动分表
使用Atlas的分表功能时,首先需要在配置文件test.cnf设置tables参数。
tables参数设置格式:数据库名.表名.分表字段.子表数量,
比如:你的数据库名叫school,表名叫stu,分表字段叫id,总共分为2张表,那么就写为school.stu.id.2,如果还有其他的分表,以逗号分隔即可。
### 安装配置(安装在db03)
yum install -y Atlas*
cd /usr/local/mysql-proxy/conf
mv test.cnf test.cnf.bak
vi test.cnf
[mysql-proxy]
admin-username = user
admin-password = pwd
proxy-backend-addresses = 10.0.0.55:3306
proxy-read-only-backend-addresses = 10.0.0.51:3306,10.0.0.53:3306
pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098=
daemon = true
keepalive = true
event-threads = 8
log-level = message
log-path = /usr/local/mysql-proxy/log
sql-log=ON
proxy-address = 0.0.0.0:33060
admin-address = 0.0.0.0:2345
charset=utf8
### 启动atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test start
ps -ef |grep proxy
### 生产用户要求
####开发人员申请一个应用用户 app( select update insert) 密码123456,要通过10网段登录
#### 1. 在主库中,创建用户
grant select ,update,insert on *.* to app@'10.0.0.%' identified by '123456';
#### 2. 在atlas中添加生产用户
/usr/local/mysql-proxy/bin/encrypt 123456 ---->制作加密密码
vim test.cnf
pwds = repl:3yb5jEku5h4=,mha:O2jBXONX098=,app:/iZxz+0GRoA=
### 重启atlas
/usr/local/mysql-proxy/bin/mysql-proxyd test restart
mysql -uapp -p123456 -h 10.0.0.53 -P 33060
功能测试
### 测试读操作:
mysql -umha -pmha -h 10.0.0.53 -P 33060
db03 [(none)]>select @@server_id;
### 测试写操作:
mysql> begin;select @@server_id;commit;
==atlas基本管理==
### 1.连接管理接口(db03)
mysql -uuser -ppwd -h127.0.0.1 -P2345
### 2.打印帮助
mysql> select * from help;
### 3.查询后端所有节点信息
mysql> SELECT * FROM backends ;
+-------------+----------------+-------+------+
| backend_ndx | address | state | type |
+-------------+----------------+-------+------+
| 1 | 10.0.0.55:3306 | up | rw |
| 2 | 10.0.0.51:3306 | up | ro |
| 3 | 10.0.0.53:3306 | up | ro |
+-------------+----------------+-------+------+
3 rows in set (0.00 sec)
### 4.动态删除节点
REMOVE BACKEND 3;
### 5.动态添加节点
ADD SLAVE 10.0.0.53:3306;
### 6.保存配置到配置文件
save config;
### 7.上线或下线节点
set online $backend_id;
set offline $backend_id;
### 8.查看用户
select * from pwds;
### 9. 添加用户
add pwd username:password;
#### username 必须在主从库上都有,上面的password是明文,怎么变为密文
#### /usr/local/mysql-proxy/bin/encrypt password
关于读写分离建议
- mysql-router ---mysql官方
- proxysql---percona
- maxscale---mariadb
mycat


基础环境准备
- 两台虚机db01,db02
- 每台创建四个mysql实例:3307、3308、3309、3310
### 1.删除历史环境
pkill mysqld
rm -rf /data/330*
mv /etc/my.cnf /etc/my.cnf.bak
### 2.创建相关目录初始化数据
mkdir /data/33{07..10}/data -p
mysqld --initialize-insecure --user=mysql --datadir=/data/3307/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3308/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3309/data --basedir=/app/mysql
mysqld --initialize-insecure --user=mysql --datadir=/data/3310/data --basedir=/app/mysql
### 3.准备配置文件和启动脚本
#### ========db01==============
cat >/data/3307/my.cnf</data/3308/my.cnf</data/3309/my.cnf</data/3310/my.cnf</etc/systemd/system/mysqld3307.service</etc/systemd/system/mysqld3308.service</etc/systemd/system/mysqld3309.service</etc/systemd/system/mysqld3310.service</data/3307/my.cnf</data/3308/my.cnf</data/3309/my.cnf</data/3310/my.cnf</etc/systemd/system/mysqld3307.service</etc/systemd/system/mysqld3308.service</etc/systemd/system/mysqld3309.service</etc/systemd/system/mysqld3310.service< 10.0.0.52:3307
10.0.0.51:3309 ------> 10.0.0.51:3307
10.0.0.52:3309 ------> 10.0.0.52:3307
10.0.0.52:3308 <-----> 10.0.0.51:3308
10.0.0.52:3310 -----> 10.0.0.52:3308
10.0.0.51:3310 -----> 10.0.0.51:3308
### 6.分片规划及配置
#### shard1:
Master:10.0.0.51:3307
slave1:10.0.0.51:3309
Standby Master:10.0.0.52:3307
slave2:10.0.0.52:3309
##### db02
mysql -S /data/3307/mysql.sock -e "grant replication slave on *.* to repl@'10.0.0.%' identified by '123';"
mysql -S /data/3307/mysql.sock -e "grant all on *.* to root@'10.0.0.%' identified by '123' with grant option;"
##### db01
mysql -S /data/3307/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3307, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3307/mysql.sock -e "start slave;"
mysql -S /data/3307/mysql.sock -e "show slave status\G"
mysql -S /data/3309/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_PORT=3307, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3309/mysql.sock -e "start slave;"
mysql -S /data/3309/mysql.sock -e "show slave status\G"
##### db02
mysql -S /data/3307/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_PORT=3307, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3307/mysql.sock -e "start slave;"
mysql -S /data/3307/mysql.sock -e "show slave status\G"
mysql -S /data/3309/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3307, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3309/mysql.sock -e "start slave;"
mysql -S /data/3309/mysql.sock -e "show slave status\G"
#### shard2:
Master:10.0.0.52:3308
slave1:10.0.0.52:3310
Standby Master:10.0.0.51:3308
slave2:10.0.0.51:3310
##### db01
mysql -S /data/3308/mysql.sock -e "grant replication slave on *.* to repl@'10.0.0.%' identified by '123';"
mysql -S /data/3308/mysql.sock -e "grant all on *.* to root@'10.0.0.%' identified by '123' with grant option;"
##### db02
mysql -S /data/3308/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_PORT=3308, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3308/mysql.sock -e "start slave;"
mysql -S /data/3308/mysql.sock -e "show slave status\G"
mysql -S /data/3310/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3308, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3310/mysql.sock -e "start slave;"
mysql -S /data/3310/mysql.sock -e "show slave status\G"
##### db01
mysql -S /data/3308/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3308, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3308/mysql.sock -e "start slave;"
mysql -S /data/3308/mysql.sock -e "show slave status\G"
mysql -S /data/3310/mysql.sock -e "CHANGE MASTER TO MASTER_HOST='10.0.0.51', MASTER_PORT=3308, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';"
mysql -S /data/3310/mysql.sock -e "start slave;"
mysql -S /data/3310/mysql.sock -e "show slave status\G"
### 7.检测主从状态
mysql -S /data/3307/mysql.sock -e "show slave status\G"|grep "Running:"
mysql -S /data/3308/mysql.sock -e "show slave status\G"|grep "Running:"
mysql -S /data/3309/mysql.sock -e "show slave status\G"|grep "Running:"
mysql -S /data/3310/mysql.sock -e "show slave status\G"|grep "Running:"
#### 注:如果中间出现错误,在每个节点进行执行以下命令,然后重复第6点
mysql -S /data/3307/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3308/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3309/mysql.sock -e "stop slave; reset slave all;"
mysql -S /data/3310/mysql.sock -e "stop slave; reset slave all;"
- schema拆分及业务分库
- 垂直拆分-分库分表
- 水平拆分-分片
企业代表产品(mysql分布式架构)
360 Atlas-Sharding
Alibaba cobar
Mycat---==DBLE==
Heisenberg
Oceanus
Vitess
OneProxy
DRDS
mycat安装(db01)
### 1.安装java运行环境
yum install -y java
### 2.下载并安装mycat
#### Mycat-server-xxxxx.linux.tar.gz
#### http://dl.mycat.org.cn/1.6.7.4/Mycat-server-1.6.7.4-release/
tar xf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
### 3.启动和连接
#### 配置环境变量
vim /etc/profile
export PATH=/application/mycat/bin:$PATH
source /etc/profile
#### 启动
mycat start
#### 连接mycat:
mysql -uroot -p123456 -h 127.0.0.1 -P8066
mycat软件结构
-
bin:程序目录
- mycat程序,启动和关闭mycat
- 中间件
-
conf:配置相关目录
-
==schema.xml 主配置文件==
cd /application/mycat/conf mv schema.xml schema.xml.bak vim schema.xml#### 数据主机DH,读写分离和高可用 select user() ##### 主##### 从
rule.xml 分片配置
server.xml mycat服务相关配置(mysql -uroot -p123456 -h 127.0.0.1 -P8066)
-
-
logs:日志相关目录
- wrapper.log mycat启动日志
- mycat.log mycat详细工作日志
参数介绍
-
balance
- balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上。
- balance="1",全部的readHost与standby writeHost参与select语句的负载均衡,简单的说,
当双主双从模式(M1->S1,M2->S2,并且M1与 M2互为主备),正常情况下,M2,S1,S2都参与select语句的负载均衡。 - balance="2",所有读操作都随机的在writeHost、readhost上分发。
-
writeType
- writeType="0", 所有写操作发送到配置的第一个writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为主,切换记录在配置文件中:dnindex.properties .
- writeType=“1”,所有写操作都随机的发送到配置的writeHost,但不推荐使用
-
switchType
- -1 表示不自动切换
- 1 默认值,自动切换
- 2 基于MySQL主从同步的状态决定是否切换 ,心跳语句为 show slave status
datahost
maxCon="1000":最大的并发连接数
minCon="10" :mycat在启动之后,会在后端节点上自动开启的连接线程
-
tempReadHostAvailable="1"
- 针对一主一从,如果双主双从就不需要了
应用前环境准备和配置(db01)
### 1.用户创建及数据库导入,上面的操作后用户已经有了
#### db01:
mysql -S /data/3307/mysql.sock
grant all on *.* to root@'10.0.0.%' identified by '123';
source /root/world.sql
mysql -S /data/3308/mysql.sock
grant all on *.* to root@'10.0.0.%' identified by '123';
source /root/world.sql
### 2.配置文件处理(读写分离)
cd /application/mycat/conf
mv schema.xml schema.xml.bak
vim schema.xml
select user()
#### 重启mycat
mycat restart
#### 读写分离测试
mysql -uroot -p -h 127.0.0.1 -P8066
show variables like 'server_id';
begin;
show variables like 'server_id';
### 3.配置读写分离及高可用
[root@db01 conf]# mv schema.xml schema.xml.rw
[root@db01 conf]# vim schema.xml
select user()
#### 真正的 writehost:负责写操作的writehost
#### standby writeHost :和readhost一样,只提供读服务
####当写节点宕机后,后面跟的readhost也不提供服务,这时候standby的writehost就提供写服务,后面跟的readhost提供读服务
#### 测试:
mysql -uroot -p123456 -h 127.0.0.1 -P 8066
show variables like 'server_id';
#### 读写分离测试
mysql -uroot -p -h 127.0.0.1 -P8066
show variables like 'server_id';
show variables like 'server_id';
show variables like 'server_id';
begin;
show variables like 'server_id';
#### 对db01 3307节点进行关闭和启动,测试读写操作
==垂直分表==
select user()
select user()
### 创建测试库和表:
mysql -S /data/3307/mysql.sock -e "create database taobao charset utf8;"
mysql -S /data/3308/mysql.sock -e "create database taobao charset utf8;"
mysql -S /data/3307/mysql.sock -e "use taobao;create table user(id int,name varchar(20))";
mysql -S /data/3308/mysql.sock -e "use taobao;create table order_t(id int,name varchar(20))"
==水平拆分(表)==
概念
- 分片策略
- 范围分片
- 取模
- 枚举
- 日期
- hash
- 分片键:作为分片条件的列
范围分片==auto-sharding-long==
vim schema.xml
select user()
select user()
vim rule.xml
...
id
rang-long
...
autopartition-long.txt
vim autopartition-long.txt
# range start-end ,data node index
# K=1000,M=10000.
#0-500M=0
#500M-1000M=1
#1000M-1500M=2
# 或以下写法
# 0-10000000=0
# 10000001-20000000=1
0-10=0
11-20=1
### 创建测试表:
mysql -S /data/3307/mysql.sock -e "use taobao;create table t3 (id int not null primary key auto_increment,name varchar(20) not null);"
mysql -S /data/3308/mysql.sock -e "use taobao;create table t3 (id int not null primary key auto_increment,name varchar(20) not null);"
## 测试:
#### 重启mycat
mycat restart
mysql -uroot -p123456 -h 127.0.0.1 -P 8066
insert into t3(id,name) values(1,'a');
insert into t3(id,name) values(2,'b');
insert into t3(id,name) values(3,'c');
insert into t3(id,name) values(4,'d');
insert into t3(id,name) values(11,'aa');
insert into t3(id,name) values(12,'bb');
insert into t3(id,name) values(13,'cc');
insert into t3(id,name) values(14,'dd');
取模分片==mod-long==
vim schema.xml
vim rule.xml
2
### 准备测试环境
#### 创建测试表:
mysql -S /data/3307/mysql.sock -e "use taobao;create table t4 (id int not null primary key auto_increment,name varchar(20) not null);"
mysql -S /data/3308/mysql.sock -e "use taobao;create table t4 (id int not null primary key auto_increment,name varchar(20) not null);"
### 重启mycat
mycat restart
### 测试:
mysql -uroot -p123456 -h10.0.0.51 -P8066
use TESTDB
insert into t4(id,name) values(1,'a');
insert into t4(id,name) values(2,'b');
insert into t4(id,name) values(3,'c');
insert into t4(id,name) values(4,'d');
#### 分别登录后端节点查询数据
mysql -S /data/3307/mysql.sock -e "select * from taobao.t4;"
mysql -S /data/3308/mysql.sock -e "select * from taobao.t4;"
枚举分片==sharding-by-intfile==
vim schema.xml
vim rule.xml
name
hash-int
partition-hash-int.txt
1
0
vim partition-hash-int.txt
bj=0
sh=1
DEFAULT_NODE=1
### columns 标识将要分片的表字段,algorithm 分片函数, 其中分片函数配置中,mapFile标识配置文件名称
### 准备测试环境
mysql -S /data/3307/mysql.sock -e "use taobao;create table t5 (id int not null primary key auto_increment,name varchar(20) not null);"
mysql -S /data/3308/mysql.sock -e "use taobao;create table t5 (id int not null primary key auto_increment,name varchar(20) not null);"
### 重启mycat
mycat restart
mysql -uroot -p123456 -h10.0.0.51 -P8066
use TESTDB
insert into t5(id,name) values(1,'bj');
insert into t5(id,name) values(2,'sh');
insert into t5(id,name) values(3,'bj');
insert into t5(id,name) values(4,'sh');
insert into t5(id,name) values(5,'tj');
### 分别登录后端节点查询数据
mysql -S /data/3307/mysql.sock -e "select * from taobao.t5;"
mysql -S /data/3308/mysql.sock -e "select * from taobao.t5;"
==DBLE自己研究==
mycat+双主双从
==mycat+mha==
==mycat+pxc==
mycat全局表
a b c d join t select t1.name ,t.x from t1 join t select t2.name ,t.x from t2 join t select t3.name ,t.x from t3 join t使用场景:
如果你的业务中有些数据类似于数据字典,比如配置文件的配置,
常用业务的配置或者数据量不大很少变动的表,这些表往往不是特别大,而且大部分的业务场景都会用到,那么这种表适合于Mycat全局表,无须对数据进行切分,要在所有的分片上保存一份数据即可。
- Mycat 在Join操作中,业务表与全局表进行Join聚合会优先选择相同分片内的全局表join,避免跨库Join,
- 在进行数据插入操作时,mycat将把数据分发到全局表对应的所有分片执行,
- 在进行数据读取时候将会随机获取一个节点读取数据。
vim schema.xml
### 后端数据准备
mysql -S /data/3307/mysql.sock
use taobao
create table t_area (id int not null primary key auto_increment,name varchar(20) not null);
mysql -S /data/3308/mysql.sock
use taobao
create table t_area (id int not null primary key auto_increment,name varchar(20) not null);
### 重启mycat
mycat restart
### 测试:
mysql -uroot -p123456 -h10.0.0.52 -P8066
use TESTDB
insert into t_area(id,name) values(1,'a');
insert into t_area(id,name) values(2,'b');
insert into t_area(id,name) values(3,'c');
insert into t_area(id,name) values(4,'d');
E-R分片
为了防止跨分片join,可以使用E-R模式
A join B
on a.xx=b.yy
join C
on A.id=C.id1.png
vim schema.xml
### rule的分片策略可以自己定义,如果rule有同名的,最好改名,然后添加rule.xml部分内容
第十五天
nosql-redis
RDBMS :MySQL,Oracle ,MSSQL,PG
NoSQL :not only sql---第二代数据库架构
- 非关系型,非结构化,半结构化
- 缓存数据库
- redis
- memcached
- tair
- 文档类
- mongodb
- es
- 列存储
- hbase
- 图形存储
- neo4j
NewSQL:分布式数据库架构---第三代数据库架构转型
数据类型丰富 (笔试、面试)*****
支持持久化 (笔试、面试) *****
多种内存分配及回收策略
支持事务 (面试) ****
消息队列、消息订阅
支持高可用 ****
支持分布式分片集群 (面试) *****
缓存穿透\雪崩(笔试、面试) *****
Redis API **
redis功能介绍
- 数据类型丰富 (笔试、面试)
- 支持持久化 (笔试、面试)
- 多种内存分配及回收策略
- 支持事务 (面试)
- 消息队列、消息订阅
- 支持高可用
- 支持分布式分片集群 (面试)
- 缓存穿透\雪崩(笔试、面试)
- Redis API
企业缓存产品介绍
Memcached:
- 优点:高性能读写、单一数据类型、支持客户端式分布式集群、一致性hash、多核结构、多线程读写性能高。
- 缺点:无持久化、节点故障可能出现缓存穿透、分布式需要客户端实现、跨机房数据同步困难、架构扩容复杂度高
Redis:
优点:高性能读写、多数据类型支持、数据持久化、高可用架构、支持自定义虚拟内存、支持分布式分片集群、单线程读写性能极高
缺点:多线程读写较Memcached慢,所以更适合单机多实例的环境
新浪、京东、直播类平台、网页游戏
结论:memcache与redis在读写性能的对比
- memcached 适合,多用户访问,每个用户少量的rw
- redis 适合,少用户访问,每个用户大量rw
Tair:
- 优点:高性能读写、支持三种存储引擎(ddb、rdb、ldb)、支持高可用、支持分布式分片集群、支撑了几乎所有淘宝业务的缓存。
- 缺点:单机情况下,读写性能较其他两种产品较慢
redis使用场景
Memcached:多核的缓存服务,更加适合于多用户并发访问次数较少的应用场景
Redis:单核的缓存服务,单节点情况下,更加适合于少量用户,多次访问的应用场景。
Redis一般是==单机多实例架构,配合redis集群==出现。
redis安装部署
### 下载:
wget http://download.redis.io/releases/redis-3.2.12.tar.gz
### 解压:上传至 /data
tar xzf redis-3.2.12.tar.gz
mv redis-3.2.12 redis
### 安装:
yum -y install gcc automake autoconf libtool make
cd redis
make
### 环境变量:
vim /etc/profile
export PATH=/data/redis/src:$PATH
source /etc/profile
### 启动:
redis-server &
### 连接测试:
redis-cli
127.0.0.1:6379> set num 10
OK
127.0.0.1:6379> get num
10
redis基本管理操作
### 1.基础配置文件介绍
mkdir /data/6379
cat > /data/6379/redis.conf<redis安全配置
### redis默认开启了保护模式,只允许本地回环地址登录并访问数据库。
#### 禁止protected-mode
#### protected-mode yes/no (保护模式,是否只允许本地访问)
###(1)Bind :指定IP进行监听
vim /data/6379/redis.conf
bind 10.0.0.51 127.0.0.1
###(2)增加requirepass {password}
vim /data/6379/redis.conf
requirepass 123456
redis-cli shutdown
redis-server /data/6379/redis.conf
netstat -lnp|grep 63
### ---------验证-----
#### 方法一:
redis-cli -a 123456
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> exit
#### 方法二:
redis-cli
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> set a b
redis-cli -a 123 -h 10.0.0.51 -p 6379
10.0.0.51:6379> set b 2
OK
在线查看和修改配置
CONFIG GET *
CONFIG GET requirepass
CONFIG GET r*
CONFIG SET requirepass 123
config set maxmemory 128M
config rewrite
### 上面是这个写入配置文件
redis持久化
- rdb
- 可以在指定的时间间隔内生成数据集的 时间点快照(point-in-time snapshot)。新快照会覆盖旧快照
- 优点:速度快,适合于用做备份,主从复制也是基于RDB持久化功能实现的。
- 缺点:会有数据丢失
- aof(append-only log file)
- 记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集。
- AOF 文件中的命令全部以 Redis 协议的格式来保存,新命令会被追加到文件的末尾。
- 优点:可以最大程度保证数据不丢
- 缺点:日志记录量级比较大,持久化时间较长
### rdb持久化核心配置参数:
vim /data/6379/redis.conf
dir /data/6379
dbfilename dump.rdb
save 900 1
save 300 10
save 60 10000
配置分别表示:
900秒(15分钟)内有1个更改
300秒(5分钟)内有10个更改
60秒内有10000个更改
### AOF持久化配置
appendonly yes
appendfsync always
appendfsync everysec
appendfsync no
是否打开aof日志功能
每1个命令,都立即同步到aof
每秒写1次
写入工作交给操作系统,由操作系统判断缓冲区大小,统一写入到aof.
vim /data/6379/redis.conf
appendonly yes
appendfsync everysec
面试: redis 持久化方式有哪些?有什么区别?
- rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
- aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
redis数据类型
-
string
应用场景:会话缓存、计数器(微博数,粉丝数,订阅、礼物)
#### 增 set mykey "test" 为键设置新值,并覆盖原有值 getset mycounter 0 设置值,取值同时进行 setex mykey 10 "hello" 设置指定 Key 的过期时间为10秒,在存活时间可以获取value setnx mykey "hello" 若该键不存在,则为键设置新值 mset key3 "zyx" key4 "xyz" 批量设置键 #### 删 del mykey 删除已有键 #### 改 append mykey "hello" 若该键并不存在,返回当前 Value 的长度;该键已经存在,返回追加后 Value的长度 incr mykey 值增加1,若该key不存在,创建key,初始值设为0,增加后结果为1 decrby mykey 5 值减少5 setrange mykey 20 dd 把第21和22个字节,替换为dd, 超过value长度,自动补0 #### 查 exists mykey 判断该键是否存在,存在返回 1,否则返回0 get mykey 获取Key对应的value strlen mykey 获取指定 Key 的字符长度 ttl mykey 查看一下指定 Key 的剩余存活时间(秒数) getrange mykey 1 20 获取第2到第20个字节,若20超过value长度,则截取第2个和后面所有的 mget key3 key4 批量获取键
-
hash
-
==应用场景:数据库缓存==
- mysql的热点表数据,灌入到redis hash类型
### 存数据: hmset stu id 101 name zhangsan age 20 gender m hmset stu1 id 102 name zhangsan1 age 21 gender f ### 取数据: HMGET stu id name age gender HMGET stu1 id name age gender select concat("hmset city_",id," id ",id," name ",name," countrycode ",countrycode," district ",district," population ",population) from city limit 10 into outfile '/tmp/hmset.txt' ### 增 hset myhash field1 "s" 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s ,若存在会覆盖原value hsetnx myhash field1 s 若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s, 若字段field1存在,则无效 hmset myhash field1 "hello" field2 "world 一次性设置多个字段 ### 删 hdel myhash field1 删除 myhash 键中字段名为 field1 的字段 del myhash 删除键 ### 改 hincrby myhash field 1 给field的值加1 ### 查 hget myhash field1 获取键值为 myhash,字段为 field1 的值 hlen myhash 获取myhash键的字段数量 hexists myhash field1 判断 myhash 键中是否存在字段名为 field1 的字段 hmget myhash field1 field2 field3 一次性获取多个字段 hgetall myhash 返回 myhash 键的所有字段及其值 hkeys myhash 获取myhash 键中所有字段的名字 hvals myhash 获取 myhash 键中所有字段的值
-
-
list
应用场景:微信朋友圈,即时消息展示;
### 增 lpush mykey a b 若key不存在,创建该键及与其关联的List,依次插入a ,b, 若List类型的key存在,则插入value中 lpushx mykey2 e 若key不存在,此命令无效, 若key存在,则插入value中 linsert mykey before a a1 在 a 的前面插入新元素 a1 linsert mykey after e e2 在e 的后面插入新元素 e2 rpush mykey a b 在链表尾部先插入b,在插入a rpushx mykey e 若key存在,在尾部插入e, 若key不存在,则无效 rpoplpush mykey mykey2 将mykey的尾部元素弹出,再插入到mykey2 的头部(原子性的操作) ### 删 del mykey 删除已有键 lrem mykey 2 a 从头部开始找,按先后顺序,值为a的元素,删除数量为2个,若存在第3个,则不删除 ltrim mykey 0 2 从头开始,索引为0,1,2的3个元素,其余全部删除 ### 改 lset mykey 1 e 从头开始, 将索引为1的元素值,设置为新值 e,若索引越界,则返回错误信息 rpoplpush mykey mykey 将 mykey 中的尾部元素移到其头部 ### 查 lrange mykey 0 -1 取链表中的全部元素,其中0表示第一个元素,-1表示最后一个元素。 lrange mykey 0 2 从头开始,取索引为0,1,2的元素 lrange mykey 0 0 从头开始,取第一个元素,从第0个开始,到第0个结束 lpop mykey 获取头部元素,并且弹出头部元素,出栈 lindex mykey 6 从头开始,获取索引为6的元素 若下标越界,则返回nil
-
set
社交类的平台,好友系统。共同好友,二度好友
### 增 sadd myset a b c 若key不存在,创建该键及与其关联的set,依次插入a ,b,若key存在,则插入value中,若a 在myset中已经存在,则插入了 d 和 e 两个新成员。 ### 删 spop myset 尾部的b被移出,事实上b并不是之前插入的第一个或最后一个成员 srem myset a d f 若f不存在, 移出 a、d ,并返回2 ### 改 smove myset myset2 a 将a从 myset 移到 myset2, ### 查 sismember myset a 判断 a 是否已经存在,返回值为 1 表示存在。 smembers myset 查看set中的内容 scard myset 获取Set 集合中元素的数量 srandmember myset 随机的返回某一成员 sdiff myset1 myset2 myset3 1和2得到一个结果,拿这个集合和3比较,获得每个独有的值 sdiffstore diffkey myset myset2 myset3 3个集和比较,获取独有的元素,并存入diffkey 关联的Set中 sinter myset myset2 myset3 获得3个集合中都有的元素 sinterstore interkey myset myset2 myset3 把交集存入interkey 关联的Set中 sunion myset myset2 myset3 获取3个集合中的成员的并集 sunionstore unionkey myset myset2 myset3 把并集存入unionkey 关联的Set中
-
sorted-set
排行榜
### 增 zadd myzset 2 "two" 3 "three" 添加两个分数分别是 2 和 3 的两个成员 ### 删 zrem myzset one two 删除多个成员变量,返回删除的数量 ### 改 zincrby myzset 2 one 将成员 one 的分数增加 2,并返回该成员更新后的分数 ### 查 zrange myzset 0 -1 WITHSCORES 返回所有成员和分数,不加WITHSCORES,只返回成员 zrank myzset one 获取成员one在Sorted-Set中的位置索引值。0表示第一个位置 zcard myzset 获取 myzset 键中成员的数量 zcount myzset 1 2 获取分数满足表达式 1 <= score <= 2 的成员的数量 zscore myzset three 获取成员 three 的分数 zrangebyscore myzset 1 2 获取分数满足表达式 1 < score <= 2 的成员 #-inf 表示第一个成员,+inf最后一个成员 #limit限制关键字 #2 3 是索引号 zrangebyscore myzset -inf +inf limit 2 3 返回索引是2和3的成员 zremrangebyscore myzset 1 2 删除分数 1<= score <= 2 的成员,并返回实际删除的数量 zremrangebyrank myzset 0 1 删除位置索引满足表达式 0 <= rank <= 1 的成员 zrevrange myzset 0 -1 WITHSCORES 按位置索引从高到低,获取所有成员和分数 #原始成员:位置索引从小到大 one 0 two 1 #执行顺序:把索引反转 位置索引:从大到小 one 1 two 0 #输出结果: two one zrevrange myzset 1 3 获取位置索引,为1,2,3的成员 #相反的顺序:从高到低的顺序 zrevrangebyscore myzset 3 0 获取分数 3>=score>=0的成员并以相反的顺序输出 zrevrangebyscore myzset 4 0 limit 1 2 获取索引是1和2的成员,并反转位置索引
mysql--->canal--->redis
(1)
set name zhangsan
(2)
MSET id 101 name zhangsan age 20 gender m
等价于以下操作:
SET id 101
set name zhangsan
set age 20
set gender m
(3)计数器
每点一次关注,都执行以下命令一次
127.0.0.1:6379> incr num
显示粉丝数量:
127.0.0.1:6379> get num
暗箱操作:
127.0.0.1:6379> INCRBY num 10000
(integer) 10006
127.0.0.1:6379> get num
"10006"
127.0.0.1:6379> DECRBY num 10000
(integer) 6
127.0.0.1:6379> get num
"6"
存数据:
hmset stu id 101 name zhangsan age 20 gender m
hmset stu1 id 102 name zhangsan1 age 21 gender f
取数据:
HMGET stu id name age gender
HMGET stu1 id name age gender
select concat("hmset city_",id," id ",id," name ",name," countrycode ",countrycode," district ",district," population ",population) from city limit 10 into outfile '/tmp/hmset.txt'
微信朋友圈:
127.0.0.1:6379> LPUSH wechat "today is nice day !"
127.0.0.1:6379> LPUSH wechat "today is bad day !"
127.0.0.1:6379> LPUSH wechat "today is good day !"
127.0.0.1:6379> LPUSH wechat "today is rainy day !"
127.0.0.1:6379> LPUSH wechat "today is friday !"
[5,4,3,2,1]
0 1 2 3 4
[e,d,c,b,a]
0 1 2 3 4
127.0.0.1:6379> lrange wechat 0 0
1) "today is friday !"
127.0.0.1:6379> lrange wechat 0 1
1) "today is friday !"
2) "today is rainy day !"
127.0.0.1:6379> lrange wechat 0 2
1) "today is friday !"
2) "today is rainy day !"
3) "today is good day !"
127.0.0.1:6379> lrange wechat 0 3
127.0.0.1:6379> lrange wechat -2 -1
1) "today is bad day !"
2) "today is nice day !"
127.0.0.1:6379> sadd lxl pg1 jnl baoqiang gsy alexsb
(integer) 5
127.0.0.1:6379> sadd jnl baoqiang ms bbh yf wxg
(integer) 5
127.0.0.1:6379> SUNION lx jnl
1) "baoqiang"
2) "yf"
3) "bbh"
4) "ms"
5) "wxg"
127.0.0.1:6379> SUNION lxl jnl
1) "gsy"
2) "yf"
3) "alexsb"
4) "bbh"
5) "jnl"
6) "pg1"
7) "baoqiang"
8) "ms"
9) "wxg"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> SINTER lxl jnl
1) "baoqiang"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> SDIFF jnl lxl
1) "wxg"
2) "yf"
3) "bbh"
4) "ms"
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379>
127.0.0.1:6379> SDIFF lxl jnl
1) "jnl"
2) "pg1"
3) "gsy"
4) "alexsb"
127.0.0.1:6379> zadd topN 0 smlt 0 fskl 0 fshkl 0 lzlsfs 0 wdhbx 0 wxg
(integer) 6
127.0.0.1:6379> ZINCRBY topN 100000 smlt
"100000"
127.0.0.1:6379> ZINCRBY topN 10000 fskl
"10000"
127.0.0.1:6379> ZINCRBY topN 1000000 fshkl
"1000000"
127.0.0.1:6379> ZINCRBY topN 100 lzlsfs
"100"
127.0.0.1:6379> ZINCRBY topN 10 wdhbx
"10"
127.0.0.1:6379> ZINCRBY topN 100000000 wxg
"100000000"
127.0.0.1:6379> ZREVRANGE topN 0 2
1) "wxg"
2) "fshkl"
3) "smlt"
127.0.0.1:6379> ZREVRANGE topN 0 2 withscores
1) "wxg"
2) "100000000"
3) "fshkl"
4) "1000000"
5) "smlt"
6) "100000"
127.0.0.1:6379>
redis消息模式
消息模式是为了帮助解决在架构中,资源有效利用方面提供有效的协调
redis的消息模式有两种形式:消息队列、发布订阅
发布订阅
- SUBSCRIBE channel [channel ...]
- 订阅频道,可以同时订阅多个频道
- PUBLISH channel msg
- 将信息 message 发送到指定的频道 channel
- UNSUBSCRIBE [channel ...]
- 取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道
- PSUBSCRIBE pattern [pattern ...]
- 订阅一个或多个符合给定模式的频道,每个模式以 * 作为匹配符,比如 it* 匹配所 有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有 以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类
- PUNSUBSCRIBE [pattern [pattern ...]]
- 退订指定的规则, 如果没有参数则会退订所有规则
- PUBSUB subcommand [argument [argument ...]]
- 查看订阅与发布系统状态
### 注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线。
### 发布订阅例子:
窗口1:
127.0.0.1:6379> SUBSCRIBE baodi
窗口2:
127.0.0.1:6379> PUBLISH baodi "jin tian zhen kaixin!"
### 订阅多频道:
窗口1:
127.0.0.1:6379> PSUBSCRIBE wang*
窗口2:
127.0.0.1:6379> PUBLISH wangbaoqiang "jintian zhennanshou "
redis事务
redis的事务是基于队列实现的。redis是乐观锁机制,仅实现原子性的保证,属于弱事务支持
mysql的事务是基于事务日志和悲观锁机制、mvcc、isolation等机制一起保证实现的,强事务支持。
### 开启事务功能时(multi)
multi
command1
command2
command3
command4
exec
discard
#### 4条语句作为一个组,并没有真正执行,而是被放入同一队列中。
#### 如果,这时执行discard,会直接丢弃队列中所有的命令,而不是做回滚。
#### 当执行exec时,对列中所有操作,要么全成功要么全失败
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> set a b
QUEUED
127.0.0.1:6379> set c d
QUEUED
127.0.0.1:6379> exec
1) OK
2) OK
redis乐观锁实现(模拟买票)
### 发布一张票
set ticket 1
#### 窗口1:
watch ticket
multi
set ticket 0 1---->0
#### 窗口2:
multi
set ticket 0
exec
窗口1:
exec
redis的key的通过操作和服务器管理命令
KEYS * keys a keys a* 查看已存在所有键的名字 ****
TYPE 返回键所存储值的类型 ****
EXPIRE\ PEXPIRE 以秒\毫秒设定生存时间 ***
TTL\ PTTL 以秒\毫秒为单位返回生存时间 ***
PERSIST 取消生存时间设置 ***
DEL 删除一个key
EXISTS 检查是否存在
RENAME 变更KEY名
### 例子:
127.0.0.1:6379> set name zhangsan
127.0.0.1:6379> EXPIRE name 60
(integer) 1
127.0.0.1:6379> ttl name
(integer) 57
127.0.0.1:6379> set a b ex 60
OK
127.0.0.1:6379> ttl a
127.0.0.1:6379> PERSIST a
(integer) 1
127.0.0.1:6379> ttl a
(integer) -1
==服务器管理命令==
- info
- info memory
- info cpu
- info replication
- 剩下看下面的shell
- config
- nohup redis-cli -a 1 -h ip -p 6379 monitor>> /tmp/redis-mon.log &
Info
Client list
Client kill ip:port
config get *
CONFIG RESETSTAT 重置统计
CONFIG GET/SET/rewrite 动态修改
Dbsize
FLUSHALL 清空所有数据
select 1
FLUSHDB 清空当前库
MONITOR 监控实时指令
SHUTDOWN 关闭服务器
min-slaves-to-write 1
min-slaves-max-lag 3
redis主从复制
redis master/slave replication(master-replica)
原理
- 副本库通过slaveof 10.0.0.51 6379命令,连接主库,并发送``SYNC`给主库
- 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库
- 副本库接收后会应用RDB快照
- 主库会陆续将中间产生的新的操作,保存并发送给副本库
- 到此,我们主复制集就正常工作了
- 再此以后,主库只要发生新的操作,都会以
命令传播的形式自动发送给副本库.- 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在.
- 如果发生主从关系断开时,从库数据没有任何损坏,在下次重连之后,从库发送PSYNC给主库
- 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
主从数据一致性保证
- min-slaves-to-write 1
- min-slaves-max-lag 3
主库是否要开启持久化
如果不开有可能,主库重启操作,造成所有主从数据丢失!
主从复制操作
### 1、环境:
#### 准备两个或两个以上redis实例
mkdir /data/638{0..2}
### 2.配置文件示例:
cat >> /data/6380/redis.conf <> /data/6381/redis.conf <> /data/6382/redis.conf <