SeqMRI train process
SeqMRI train process
- LOUPE大体流程
- train的过程
-
- 从初始化mask到得到zero-filled image
- reconstruction过程
- 怎么得到mask
- sequential网络
LOUPE大体流程
LOUPE(
(samplers): ModuleList(
(0): LOUPESampler(
(gen_mask): LineConstrainedProbMask()
)
)
(reconstructor): LOUPEUNet(
(down_sample_layers): ModuleList(
(0): ConvBlock(in_chans=2, out_chans=64, drop_prob=0.0)
(1): ConvBlock(in_chans=64, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=128, out_chans=256, drop_prob=0.0)
(3): ConvBlock(in_chans=256, out_chans=512, drop_prob=0.0)
)
(conv): ConvBlock(in_chans=512, out_chans=512, drop_prob=0.0)
(up_sample_layers): ModuleList(
(0): ConvBlock(in_chans=1024, out_chans=256, drop_prob=0.0)
(1): ConvBlock(in_chans=512, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=256, out_chans=64, drop_prob=0.0)
(3): ConvBlock(in_chans=128, out_chans=64, drop_prob=0.0)
)
(conv2): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(32, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
)
in loup_envs_ocmr.py
train_data, val_data, test_data = self._create_datasets()

display_data = [val_data[i] for i in range(0, len(val_data))]
in real_ocmr_data.py
return self.transform(
kspace,
torch.zeros(kspace.shape[1]),
target,
fname.name
)

in loup_envs_ocmr.py
train_loader, val_loader, test_loader, display_loader

train_loupe_ocme.py
policy = NonRLTrainer(args, env, torch.device(args.device))

non_rl.py
def _train_loupe(self):
for epoch in range(self.start_epoch, self.end_epoch):
self.epoch = epoch
train_loss, train_time = self.train_epoch()
def train_epoch(self):
self.model.train()
losses = []
targets, preds = [], []
metrics = Metrics(METRIC_FUNCS)
avg_loss = 0.
start_epoch = start_iter = time.perf_counter()
global_step = self.epoch * len(self.train_loader)
for iter, data in enumerate(self.train_loader):
# self.scheduler.step()
# input: [batch_size, num_channels, height, width] denoted as NCHW in other places
# label: label of the current image (0~9 for mnist/fashion-mnist) default: -1
# target: a copy of the input image for computing reconstruction loss in [NCHW]
kspace, _, input, label, *ignored= data
# adapt data to loupe
target = input.clone().detach()
target = transforms.complex_abs(target).unsqueeze(1)
input = input.to(self.options.device)
target = target.to(self.options.device)
kspace = kspace.to(self.options.device)
# label = label.to(self.options.device)
"""if self.options.noise_type == 'gaussian':
kspace = transforms.add_gaussian_noise(self.options, kspace, mean=0., std=self.options.noise_level)
"""
pred_dict = self.model(target, kspace)
if (self.epoch == 0 or (self.epoch+1) % 1 == 0) and iter == 0:
data_for_vis_name = 'train_epoch={}_iter={}'.format(str(self.epoch+1), str(iter+1))
self.model.visualize_and_save(self.options, self.epoch, data_for_vis_name)
output = pred_dict['output']
target_dict = {'target': target, 'label': label, 'kspace': kspace}
meta = {'entropy_weight': self.options.entropy_weight, 'recon_weight': self.options.recon_weight,
'kspace_weight': self.options.kspace_weight,
'uncertainty_weight': self.options.uncertainty_weight if 'uncertainty_weight' in self.options.__dict__ else 0}
loss, log_dict = self.model.loss(pred_dict, target_dict, meta, self.options.loss_type)
self.optimizer.zero_grad()
loss.backward()
# torch.nn.utils.clip_grad_norm_(self.model.parameters(), 10)
self.optimizer.step()
self.writer.add_scalar('Train_Loss', loss.item(), global_step + iter)
losses.append(loss.item())
# target: 16*1*32*32
# output: 16*1*32*32
if isinstance(output, list):
output = output[-1]
target = target.cpu().detach().numpy()
pred = output.cpu().detach().numpy()
if iter % self.options.report_interval == 0:
self.logger.info(
f'Epoch = [{1 + self.epoch:3d}/{self.options.num_epochs:3d}] '
f'Iter = [{iter:4d}/{len(self.train_loader):4d}] '
f'Time = {time.perf_counter() - start_iter:.4f}s',
)
for key, val in log_dict.items():
print('{} = {}'.format(key, val))
start_iter = time.perf_counter()
for t, p in zip(target, pred):
metrics.push(t, p)
print(metrics)
self.writer.add_scalar('Train_MSE', metrics.means()['MSE'], self.epoch)
self.writer.add_scalar('Train_NMSE', metrics.means()['NMSE'], self.epoch)
self.writer.add_scalar('Train_PSNR', metrics.means()['PSNR'], self.epoch)
self.writer.add_scalar('Train_SSIM', metrics.means()['SSIM'], self.epoch)
return np.mean(np.array(losses)), time.perf_counter() - start_epoch
self.scheduler.step(epoch)
dev_loss, mean_sparsity, dev_time = self.evaluate()
def evaluate(self):
self.model.eval()
losses = []
sparsity = []
targets, preds = [], []
metrics = Metrics(METRIC_FUNCS)
start = time.perf_counter()
with torch.no_grad():
for iter, data in enumerate(self.dev_loader):
# input: [batch_size, num_channels, height, width] denoted as NCHW in other places
# label: label of the current image (0~9 for mnist/fashion-mnist) default: -1
# target: a copy of the input image for computing reconstruction loss in [NCHW]
kspace, _, input, label, *ignored = data
# adapt data to loupe
target = input.clone().detach()
target = transforms.complex_abs(target).unsqueeze(1)
input = input.to(self.options.device)
target = target.to(self.options.device)
kspace = kspace.to(self.options.device)
# label = label.to(self.options.device)
pred_dict = self.model(target, kspace)
if (self.epoch == 0 or (self.epoch+1) % 1 == 0) and iter == 0:
data_for_vis_name = 'eval_epoch=' + str(self.epoch+1)
self.model.visualize_and_save(self.options, self.epoch, data_for_vis_name)
output = pred_dict['output']
# only use the last reconstructed image to compute loss
if isinstance(output, list):
output = output[-1]
target_dict = {'target': target, 'label': label, 'kspace':kspace}
meta = {'entropy_weight': self.options.entropy_weight, 'recon_weight': self.options.recon_weight,
'uncertainty_weight': 0, 'kspace_weight': self.options.kspace_weight}
loss, log_dict = self.model.loss(pred_dict, target_dict, meta, self.options.loss_type)
mask = pred_dict['mask']
sparsity.append(torch.mean(mask).item())
losses.append(loss.item())
# target: 16*1*32*32
# output: 16*1*32*32
target = target.cpu().numpy()
pred = output.cpu().numpy()
for t, p in zip(target, pred):
metrics.push(t, p)
print(metrics)
self.writer.add_scalar('Dev_MSE', metrics.means()['MSE'], self.epoch)
self.writer.add_scalar('Dev_NMSE', metrics.means()['NMSE'], self.epoch)
self.writer.add_scalar('Dev_PSNR', metrics.means()['PSNR'], self.epoch)
self.writer.add_scalar('Dev_SSIM', metrics.means()['SSIM'], self.epoch)
self.writer.add_scalar('Dev_Loss', np.mean(losses), self.epoch)
return np.mean(losses), np.mean(sparsity), time.perf_counter() - start

loss在loupe.py
def loss(self, pred_dict, target_dict, meta, loss_type):
"""
Args:
pred_dict:
output: reconstructed image from downsampled kspace measurement
energy: negative entropy of the probability mask
mask: the binazried sampling mask (used for visualization)
target_dict:
target: original fully sampled image
meta:
recon_weight: weight of reconstruction loss
entropy_weight: weight of the entropy loss (to encourage exploration)
"""
target = target_dict['target']
pred = pred_dict['output']
energy = pred_dict['energy']
if loss_type == 'l1':
reconstruction_loss = F.l1_loss(pred, target, size_average=True)
elif loss_type == 'ssim':
reconstruction_loss = -torch.mean(compute_ssim_torch(pred, target))
elif loss_type == 'psnr':
reconstruction_loss = - torch.mean(compute_psnr_torch(pred, target))
else:
raise NotImplementedError
entropy_loss = torch.mean(energy)
loss = entropy_loss * meta['entropy_weight'] + reconstruction_loss * meta['recon_weight']
log_dict = {'Total Loss': loss.item(), 'Entropy': entropy_loss.item(), 'Reconstruction': reconstruction_loss.item()}
return loss, log_dict
一直循环def _train_loupe(self):直到epoch结束
train的过程
从初始化mask到得到zero-filled image
pred_dict = self.model(target, kspace)
我这里设的batch_size=1,
所以target(1, 1, 256, 256) , target.min()=0, target.max()=1
kspace(1, 256, 256, 2)
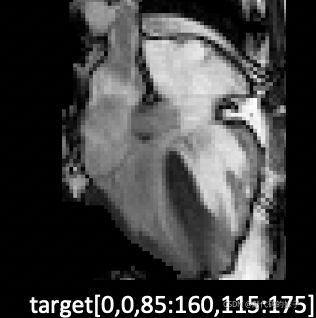
non_rl.py中的 pred_dict = self.model(target, kspace)跳到loupe.py中的 masked_kspace, mask, neg_entropy, data_to_vis_sampler = self.samplers[0](kspace, self.sparsity)
又跳到samplers.py中的prob_mask = self.gen_mask(kspace)又跳到layer.py中的 logits = self.mask
mask = torch.sigmoid(self.slope * logits).view(1, 1, self.mask.shape[0], 1)

logits = self.mask
mask = torch.sigmoid(self.slope * logits).view(1, 1, self.mask.shape[0], 1) #252
if self.preselect:
if self.preselect_num % 2 ==0:
zeros = torch.zeros(1, 1, self.preselect_num // 2, 1).to(input.device) #(1,1,2,1)
mask = torch.cat([zeros, mask, zeros], dim=2) #(1,1,256,1)----》get prob_mask
samplers.py
else:
rescaled_mask = self.rescale(prob_mask, sparsity) #跳到layers.py 得到(1,1,256,1)
if self.training:
binarized_mask = self.binarize(rescaled_mask)#跳到layers.py中的ThresholdRandomMaskSigmoidV1 得到(1,1,256,1)60个1

layers.py
def RescaleProbMap(batch_x, sparsity):
"""
Rescale Probability Map
given a prob map x, rescales it so that it obtains the desired sparsity
if mean(x) > sparsity, then rescaling is easy: x' = x * sparsity / mean(x)
if mean(x) < sparsity, one can basically do the same thing by rescaling
(1-x) appropriately, then taking 1 minus the result.
"""
batch_size = len(batch_x) #我设置的batch_size=1
ret = []
for i in range(batch_size):
x = batch_x[i:i+1] #batch_x (1,1,256,1), x (1,1,256,1)
xbar = torch.mean(x) #0.4692
r = sparsity / (xbar) #0.234375/0.4692 =0.4995
beta = (1-sparsity) / (1-xbar) # 1.4425
# compute adjucement
le = torch.le(r, 1).float() #1
ret.append(le * x * r + (1-le) * (1 - (1 - x) * beta))
return torch.cat(ret, dim=0) #遍历batch_size最后concat,这里我设的1,所以这里最后cat是(1,1,256,1)
layers.py
class ThresholdRandomMaskSigmoidV1(Function):
def __init__(self):
"""
Straight through estimator.
The forward step stochastically binarizes the probability mask.
The backward step estimate the non differentiable > operator using sigmoid with large slope (10).
"""
super(ThresholdRandomMaskSigmoidV1, self).__init__()
@staticmethod
def forward(ctx, input):
batch_size = len(input)
probs = []
results = []
for i in range(batch_size):
x = input[i:i+1]
count = 0
while True:
prob = x.new(x.size()).uniform_()
result = (x > prob).float()
if torch.isclose(torch.mean(result), torch.mean(x), atol=1e-3):
break
count += 1
if count > 1000:
print(torch.mean(prob), torch.mean(result), torch.mean(x))
assert 0
probs.append(prob)
results.append(result)
results = torch.cat(results, dim=0)
probs = torch.cat(probs, dim=0)
ctx.save_for_backward(input, probs)
return results
……………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………
samplers.py
else: #preselect_num_one_side=2
binarized_mask[..., :self.preselect_num_one_side, :] = 1
binarized_mask[..., -self.preselect_num_one_side:, :] = 1 #把前两个和后两个都变成了1,一共64个1
neg_entropy = self._mask_neg_entropy(rescaled_mask) #(1,1,256,1).ax=0,min=-0.6931
masked_kspace = binarized_mask * kspace

reconstruction过程
loupe.py中的 recon = self.reconstructor(zero_filled_recon, 0)跳到reconstructor.py中的
def forward(self, input, old_recon=None, eps=1e-8):
else:
output = input
LOUPEUNet(
(down_sample_layers): ModuleList(
(0): ConvBlock(in_chans=2, out_chans=64, drop_prob=0.0)
(1): ConvBlock(in_chans=64, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=128, out_chans=256, drop_prob=0.0)
(3): ConvBlock(in_chans=256, out_chans=512, drop_prob=0.0)
)
(conv): ConvBlock(in_chans=512, out_chans=512, drop_prob=0.0)
(up_sample_layers): ModuleList(
(0): ConvBlock(in_chans=1024, out_chans=256, drop_prob=0.0)
(1): ConvBlock(in_chans=512, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=256, out_chans=64, drop_prob=0.0)
(3): ConvBlock(in_chans=128, out_chans=64, drop_prob=0.0)
)
(conv2): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(32, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
怎么得到mask
loup.py
masked_kspace, mask, neg_entropy, data_to_vis_sampler = self.samplers[0](kspace, self.sparsity)
samplers.py
def forward(self, kspace, sparsity): #sparsity=0.234375
# kspace: NHWC
# sparsity (float)
prob_mask = self.gen_mask(kspace)
layers.py
class LineConstrainedProbMask(nn.Module):
"""
A learnable probablistic mask with the same shape as the kspace measurement.
The mask is constrinaed to include whole kspace lines in the readout direction
"""
def __init__(self, shape=[32], slope=5, preselect=False, preselect_num=2):
super(LineConstrainedProbMask, self).__init__()
else:
length = shape[0] #32
self.preselect_num = preselect_num #2
self.preselect = preselect #False
self.slope = slope #5
init_tensor = self._slope_random_uniform(length)
self.mask = nn.Parameter(init_tensor)
def forward(self, input, eps=1e-10):
"""
Args:
input (torch.Tensor): Input tensor of shape NHWC
Returns:
(torch.Tensor): Output tensor of shape NHWC
"""
logits = self.mask
mask = torch.sigmoid(self.slope * logits).view(1, 1, self.mask.shape[0], 1)
if self.preselect:
if self.preselect_num % 2 ==0:
zeros = torch.zeros(1, 1, self.preselect_num // 2, 1).to(input.device)
mask = torch.cat([zeros, mask, zeros], dim=2)
else:
raise NotImplementedError()
return mask
def _slope_random_uniform(self, shape, eps=1e-2): #shape=32
"""
uniform random sampling mask with the shape as half of the kspace measurement
"""
temp = torch.zeros([shape[0], shape[1]//2]).uniform_(eps, 1-eps)
# logit with slope factor
return -torch.log(1./temp-1.) / self.slope
sequential网络
INFO:activemri.baselines.non_rl:SequentialUnet(
(reconstructor): LOUPEUNet(
(down_sample_layers): ModuleList(
(0): ConvBlock(in_chans=2, out_chans=64, drop_prob=0.0)
(1): ConvBlock(in_chans=64, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=128, out_chans=256, drop_prob=0.0)
(3): ConvBlock(in_chans=256, out_chans=512, drop_prob=0.0)
)
(conv): ConvBlock(in_chans=512, out_chans=512, drop_prob=0.0)
(up_sample_layers): ModuleList(
(0): ConvBlock(in_chans=1024, out_chans=256, drop_prob=0.0)
(1): ConvBlock(in_chans=512, out_chans=128, drop_prob=0.0)
(2): ConvBlock(in_chans=256, out_chans=64, drop_prob=0.0)
(3): ConvBlock(in_chans=128, out_chans=64, drop_prob=0.0)
)
(conv2): Sequential(
(0): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
(1): Conv2d(32, 1, kernel_size=(1, 1), stride=(1, 1))
(2): Conv2d(1, 1, kernel_size=(1, 1), stride=(1, 1))
)
)
(sampler): Sampler(
(mask_net): KspaceLineConstrainedSampler(
(conv_last): Sequential(
(0): Linear(in_features=327680, out_features=512, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=512, out_features=512, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=512, out_features=512, bias=True)
(7): ReLU(inplace=True)
(8): Linear(in_features=512, out_features=256, bias=True)
)
)
)
)