初识ebpf
介绍eBPF技术
当代计算机系统中,性能、安全性和可观察性是至关重要的关键因素。为了应对这些挑战,Linux 内核引入了一种名为eBPF(extended Berkeley Packet Filter)的强大技术。eBPF 不仅仅是一种网络数据包过滤器,它是一种可编程的内核技术,可以用于解决各种各样的问题,从网络性能优化到安全审计。本文将深入介绍eBPF技术,包括其起源、基本概念、工作原理、应用领域和相关工具。
在当今计算机领域,Linux 内核是一个广泛使用的操作系统内核,而eBPF是 Linux 内核中的一项创新技术,它具有广泛的用途,可以用于改善系统性能、提高安全性、监控和审计系统行为。eBPF 能够实现高性能和可编程性,使其成为解决多种问题的理想选择。
eBPF的起源
eBPF 最初起源于 Berkeley Packet Filter(BPF),后来演化为 extended BPF,随着时间的推移,它已经成为 Linux 内核的一部分。BPF 最早是由 Steven McCanne 和 Van Jacobson 在 1992 年创建的,用于数据包捕获和过滤。extended BPF 允许用户编写更复杂的程序,而不仅仅是数据包过滤,从而扩展了其应用范围。
eBPF的基本概念
eBPF 提供了一个基于寄存器的虚拟机,可以执行内核中嵌入的程序,这些程序通常称为 BPF 程序。这些程序使用一种特殊的指令集,可以访问内核数据和功能,并在内核中执行。eBPF 具有以下基本概念:
BPF 程序:eBPF 程序是由用户编写的程序,使用 BPF 指令集执行。它们通常编译成字节码并加载到内核中。
BPF 虚拟机:eBPF 程序在 BPF 虚拟机中执行,这是一个安全且受限的执行环境,可以在内核中运行用户定义的代码。
BPF 地址空间:eBPF 程序可以访问内核的地址空间,包括数据结构和函数。
Hook Points:eBPF 可以绑定到内核的挂钩点(hook points),这些挂钩点允许程序拦截和修改内核事件。
eBPF的工作原理
eBPF 工作原理涉及以下步骤:
1、用户编写 eBPF 程序,通常使用高级语言(如C)编写,并使用 BPF 编译器编译成字节码。
2、编译后的程序加载到内核中,然后通过 BPF 虚拟机执行。程序可以连接到内核的挂钩点(hook points),例如网络数据包处理、系统调用等。
3、在运行时,eBPF 程序可以访问内核数据和事件,并根据需求执行自定义逻辑。
4、eBPF 程序可以生成输出,或者修改内核状态,以实现各种用途,例如性能优化、安全审计、监控和跟踪。
这里有详细的文档:https://man7.org/linux/man-pages/man7/bpf-helpers.7.html
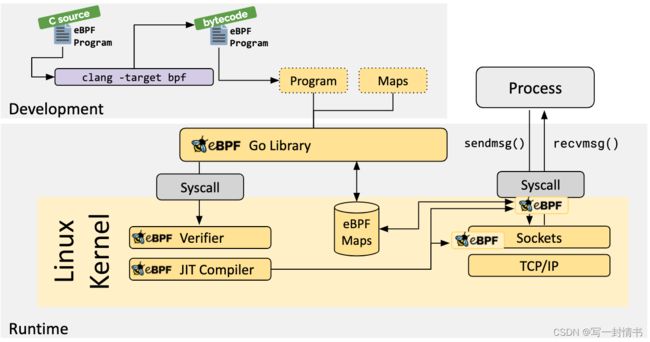
eBPF的应用领域
eBPF 具有多个应用领域,包括但不限于:
网络性能优化
eBPF 可以用于实现高性能的网络数据包过滤、转发和路由。它可以用于改善网络性能、诊断网络问题,并支持各种网络应用。
安全审计和监控
eBPF 可以用于监控系统的安全性,跟踪恶意行为,检测入侵,并生成审计日志。它可以帮助系统管理员保持对系统安全性的可见性。
容器和云原生环境
eBPF 在容器和云原生环境中得到了广泛的应用。它可以用于监控容器的性能、安全性和行为,以及在多个容器之间实现网络隔离和路由。
性能分析和跟踪
eBPF 可以用于性能分析和跟踪,帮助开发人员识别和解决性能问题。它可以跟踪系统调用、函数执行时间、资源利用率等。
eBPF工具和库
为了更好地利用eBPF技术,开发人员和系统管理员可以使用各种工具和库,包括以下几种:
bpftrace
bpftrace 是一个高级工具,用于跟踪和诊断系统性能问题。它提供了一种简洁的语法,用于编写eBPF脚本,以捕获和分析系统事件。
BCC(BPF Compiler Collection)
BCC 是一个工具集,提供了许多用于eBPF开发的工具和示例程序。它包括各种用于网络分析、性能分析和安全监控的工具。
libbpf
libbpf 是一个库,用于编写eBPF程序的用户空间工具。它提供了与内核交互的功能,以及加载和执行eBPF程序的能力。
开始你的第一个 BPF 程序
BPF 程序的编译,一般使用 LLVM.LLVM 是一种 genreal-purpose 的编译器,LLVM 可以emit 不同的字节码。在本章中,LLVM 将生成 bpf 的字节码,然后我们会 load 到内核的虚拟中。
内核提供了一个系统调用,专门用于 load bpf 的程序,除了 load bpf 的程序,这个系统调用,还可以有一些其他的操作,后面我们会看到它的用法,接下来,我们来看下 Hello world:
#include 编译命令
clang -O2 -target bpf -c bpf_program.c -I /usr/include/x86_64-linux-
gnu/ -o bpf_program.o
我们使用 SEC 属性,告诉 BPF VM,我们想在什么时候运行我们写的这个程序。在上面的代码中,我们指定在 kernel 调用到 execve 的时候,来调用我们自己写的程序。即:SEC 中定义的是一个 Tracepoints,是 kernel 预先定义好的,允许开发者,在这里 injet 进去自己的代码。那你可能会问,我怎么知道都有哪些 tracepoints 呢?这个可以在/sys/kernel/debug/tracing/events/syscalls/这个目录下找到系统预留的所有的tracepoints.
另外,我们需要使用指定 GPL 的协议。因为 kernel 本身就是 GPL 的。我们使用
bpf_trace_printk 来 打 印 在 内 核 中 生 成 的 日 志 。 当 然 你 也 可 以 通 过
/sys/kernel/debug/tracing/trace_pipe 来查看内核的日志。
我们需要一份源码来编译 libbpf
git clone --depth 1 git://kernel.ubuntu.com/ubuntu/ubuntu-bionic.git
可以将源码拷贝到/kernel-src 目录下,然后编译 libbpf
sudo mv ubuntu-bionic /kernel-src
cd /kernel-src/tools/lib/bpf
sudo make && sudo make install prefix=/usr/local
现在我们有了 bpf 的代码,需要一个程序把它 load 到内核中。
#include "bpf_load.h"
#include Makefile
CLANG = clang
EXECABLE = monitor-exec
BPFCODE = bpf_program
BPFTOOLS = /home/king/share/ubuntu-bionic/samples/bpf
BPFLOADER = $(BPFTOOLS)/bpf_load.c
CCINCLUDE += -I/home/king/share/ubuntu-
bionic/tools/testing/selftests/bpf
LOADINCLUDE += -I/home/king/share/ubuntu-bionic/samples/bpf
LOADINCLUDE += -I/home/king/share/ubuntu-bionic/tools/lib
LOADINCLUDE += -I/home/king/share/ubuntu-bionic/tools/perf
LOADINCLUDE += -I/home/king/share/ubuntu-bionic/tools/include
LIBRARY_PATH = -L/usr/local/lib64
BPFSO = -lbpf
.PHONY: clean $(CLANG) bpfload build
clean:
rm -f *.o *.so $(EXECABLE)
build: ${BPFCODE.c} ${BPFLOADER}
$(CLANG) -O2 -target bpf -c $(BPFCODE:=.c) $(CCINCLUDE) -o
${BPFCODE:=.o}
bpfload: build
clang -o $(EXECABLE) -lelf $(LOADINCLUDE) $(LIBRARY_PATH)
$(BPFSO) \
$(BPFLOADER) loader.c
$(EXECABLE): bpfload
.DEFAULT_GOAL := $(EXECABLE)
make

每执行一个 ls 就会有一行打印信息

bpftrace工具简介
bpftrace进行内核跟踪
#### bpftrace 命令行操作
单行命令工具:
bpftrace -e 'program'
bpftrace直接跟-e选项后面加单行命令,一些示例,比如:
bpftrace -e 'BEGIN { printf("Hello world!\n"); }'
bpftrace -e 'kprobe:vfs_read { @[tid] = count();}'
bpftrace -e 'kprobe:vfs_read /pid == 123/ { @[tid, comm] = count();}'
bpftrace -e 't:block:block_rq_insert { @[kstack] = count(); }'
单行命令工具可以按ctrl-c也结束,只有结束后才会打印输出结果。
#### bpftrace 编写脚本工具
bpftrace支持脚本编写,只需要在其实出添加#!/usr/local/bin/bpftrace,会被认为是一个bpftrace脚本。
#!/usr/local/bin/bpftrace
// this program times vfs_read()
kprobe:vfs_read
{
@start[tid] = nsecs;
}
retprobe:vfs_read
/@start[tid]/
{
$duration_us = (nsecs - @start[tid]) / 1000;
@us = hist($duration_us);
delete(@start[tid]);
}
#### debug调试
bpftrace -d
bpftrace -v
bpftrace语法结构
bpftrace编程语言参考了awk的语法,基础结构:
probes /filter/ { actions }
它是一种事件驱动的运行方式。
probes表示的就是事件,包括tracepoint、kprobe、kretprobe、uprobe等等。除了这些跟踪点,还有两个特殊的事件BEGIN、END,用于在脚本开始处和结束处执行。
filter表示的是过滤条件,当一个事件触发时,会先判断该条件,满足条件才会执行后面的action行为。
action表示的具体执行的操作。
示例:
bpftrace -e 'kprobe:vfs_read /pid == 123/ { @[tid, comm] = count();}'
#### bpftrace 脚本变量
内部变量(built-in)
uid: 用户id。
tid: 线程id
pid: 进程id。
cpu: cpu id。
cgroup:cgroup id.
probe: 当前的trace点。
comm: 进程名字。
nsecs: 纳秒级别的时间戳。
kstack:内核栈描述
curtask:当前进程的task_struct地址。
args: 获取该kprobe或者tracepoint的参数列表
arg0: 获取该kprobe的第一个变量,tracepoint不可用
arg1: 获取该kprobe的第二个变量,tracepoint不可用
arg2: 获取该kprobe的第三个变量,tracepoint不可用
retval: kretprobe中获取函数返回值
args->ret: kretprobe中获取函数返回值
备注:
bpftrace -lv tracepoint:syscalls:sys_enter_read
这个命令-lv可以用来查看一个tracepoint对应的参数都有哪些。
自定义临时变量
以"$"标志起始来定义和引用一个变量
$x = 1
Map变量
map变量是用于内核向用户空间传递数据的一种存储结构,定义方式是以"@"符号作为其实标记。
这个map可以有单个key或者多个key:
@path[tid] = nsecs
@path[pid, $fd] =nsecs
bpftrace默认在结束时会打印从内核接收到的map变量。
#### 函数
exit():退出bpftrace程序
str(char *):转换一个指针到string类型
system(format[, arguments ...]):运行一个shell命令
join(char *str[]):打印一个字符串列表并在每个前面加上空格,比如可以用来输出args->argv
ksym(addr):用于转换一个地址到内核symbol
kaddr(char *name):通过symbol转换为内核地址
print(@m [, top [, div]]):可选择参数打印map中的top n个数据,数据可选择除以一个div值
#### map函数
bpftrace内构的一些map函数,用于传递数据给map变量,注意接收他们的变量是map类型。常用的包括:
count():用于计算次数
sum(int n):用于累加计算
avg(int n):用于计算平均值
min(int n):用于计算最小值
max(int n):用于计算最大值
hist(int n):数据分布直方图(范围为2的幂次增长)
lhist(int n):数据线性直方图
delete(@m[key]):删除map中的对应的key数据
clear(@m):删除map中的所有数据
zero(@m):map中的所有值设置为0
#### 附件
常用的一些单行命令示例:
bpftrace -e 'tracepoint:block:block_rq_i* { @[probe] = count(); } interval:s:1 { print(@); clear(@); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret > 0/ { @bytes = sum(args->ret); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ret = hist(args->ret); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @ret = lhist(args->ret, 0, 1000, 100); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret < 0/ { @[- args->ret] = count(); }'
bpftrace -e 'kprobe:vfs_* { @[probe] = count(); } END { print(@, 5); clear(@); }'
bpftrace -e 'kprobe:vfs_read { @start[tid] =nsecs; } kretprobe:vfs_read /@start[tid]/ { @ms[comm] = sum(nsecs - @start[tid]); delete(@start[tid]); } END { print(@ms, 0, 1000000); clear(@ms); clear(@start); }'
bpftrace -e 'k:vfs_read { @[pid] = count(); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { printf("%s -> %s\n", comm, str(args->filename)); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_openat { printf("%s %s\n", comm, str(args->filename)); }'
bpftrace -e 'tracepoint:raw_syscalls:sys_enter {@[comm] = count(); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_* {@[probe] = count(); }'
bpftrace -e 'tracepoint:raw_syscalls:sys_enter {@[pid, comm] = count(); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret/ { @[comm] = sum(args->ret); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
bpftrace -e 'tracepoint:block:block_rq_issue { printf("%d %s %d\n", pid, comm, args->bytes); }'
bpftrace -e 'software:major-faults:1 { @[comm] = count(); }'
bpftrace -e 'software:faults:1 { @[comm] = count(); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_clone { printf("-> clone() by %s PID %d\n", comm, pid); } tracepoint:syscalls:sys_exit_clone { printf("<- clone() return %d, %s PID %d\n", args->ret, comm, pid); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_setuid { printf("setuid by PID %d (%s), UID %d\n", pid, comm, uid); }'
bpftrace -e 'tracepoint:syscalls:sys_exit_setuid { printf("setuid by %s returned %d\n", comm, args->ret); }'
bpftrace -e 'tracepoint:block:block_rq_insert { printf("Block I/O by %s\n", kstack); }'
bpftrace -e 'tracepoint:syscalls:sys_enter_connect /pid == 123/ { printf("PID %d called connect()\n", $1); }'
bpftrace -e 'tracepoint:timer:hrtimer_start { @[ksym(args->function)] = count(); }'
bpftrace -e 't:syscalls:sys_enter_read { @reads = count(); } interval:s:5 { exit(); }'
bpftrace -e 'kprobe:vfs_read {@ID = pid;} interval:s:2 {printf("ID:%d\n", @ID);}'
这只是简介,留下个以后详细学习的地址:
地址1
地址2
结论
eBPF 技术已经成为 Linux 内核中的一个强大工具,用于解决性能、安全性和可观察性等各种挑战。通过可编程性和灵活性,eBPF 为开发人员和系统管理员提供了解决问题的新途径,为未来的系统优化和安全性提供了更多的机会。