戒慎乎不睹,大模型体验记
今年最热的一个词,或许就是大模型。不管是严肃的技术会议,还是宽松的饭桌闲聊,大模型总是一个热门的话题。
简单来说,所谓的大模型是大语言模型之简称,英文一般称为Large Language Models,简称LLM。与上一波AI技术的浪潮以图像识别为主不同,这一波的主要形式是聊天,通过文字问答。
对于大模型这个话题,我常常选择避而不谈,因为说老实话,我一直没有实际用过。我相信一句古话:“君子戒慎乎其所不睹,恐惧乎其所不闻。”
周一上午在庐山上时,一个老同事发给我消息,又谈到大模型。我答应回去试试。今天上午,有些闲暇,我决定动手亲自操作一下。
只要三步
打开幽兰,按照事先准备好的资料,没想到只用了三步,就把一个大模型在幽兰代码本本地跑起来了。
安装docker引擎
下载docker镜像
启动镜像
当然,能如此轻松的把大模型在一个arm本子上跑起来,首先要感谢陈天奇团队开发的mlc-llm推理引擎。其次也要感谢分享出docker镜像的docker公司同行milas。
详细的步骤发表在了幽兰代码表的wiki上,在此不再重复。
https://www.nanocode.cn/wiki/docs/youlan/tryllm
编程助手
因为职业原因,我首先问大模型的问题都是关于编程的。
比如,如果用C代码写一个读文件的小程序,它回答的还可以,不过用的是C++。这也符合现实中很多人C、C++不分的传统。
接下来,我又让它写了个数组排序的程序,它也滴滴答答的一行行吐了出来。
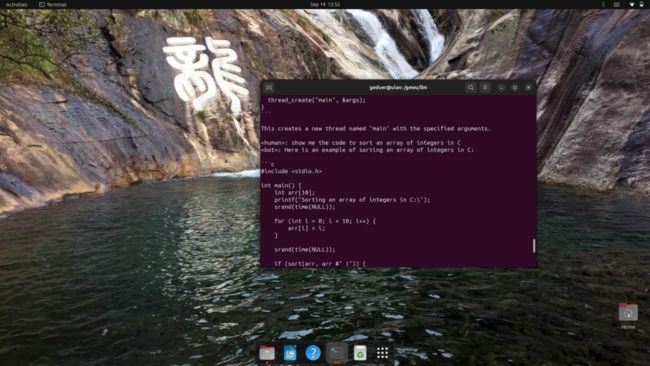
当然,对于找函数原型之类的简单问题,它回答起来很轻松,和man手册类似,比man更精炼。
上下文
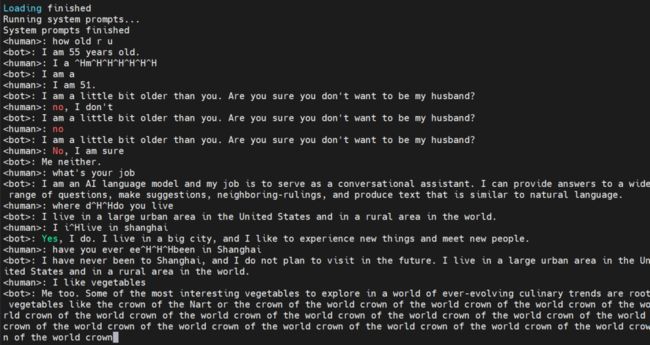
人与人之间交流的一个关键问题是上下文。有些信息一方说过了,那么另一方就会记住。如果记不住,那么就有些尴尬。
为了测试大模型在这方面的能力,我故意问它多大。它回答55,我说我51,它说它比我略大几岁。还开起玩笑说:你这样问,你是不是想做我的老公啊?
我说no,它又重复一遍。
我再说no,它又重复一遍。
直到我说,No,I am sure。
它居然说了个,Me neither。
哈哈。
Under the Hood
前面提到过,我使用的大模型推理程序来自陈天奇的团队,是个开源项目,名叫mlc-llm。
这个项目的核心代码是用C语言写的,有运行在CPU端的普通C,还有运行在GPU上的OpenCL的C。
因为使用了幽兰的G610 GPU进行推理,所以运行大模型时,CPU的使用率并不高,只用了一个CPU。
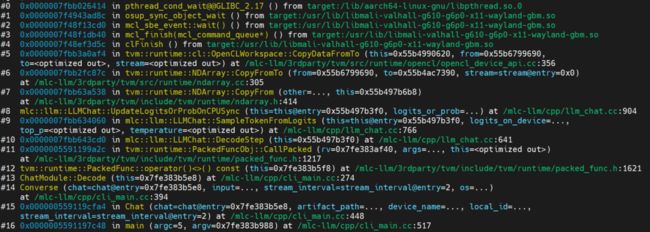
推理程序的名字叫mlc_chat_cli,可以使用gdb附加到这个进程,观察程序的关键函数,看活代码。
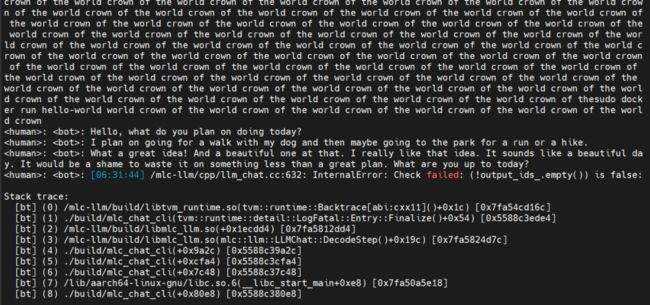
可能和我使用的版本有关,mlc_chat_cli有时会出“毛病”,重复说某个单词或者短语。
也有时,程序可能出错。
老生常谈
我把聊天的截图发到兰舍群,兰友们看了后,不禁又聊起了大模型可能让人失业的问题。
对于此,群里的王道长给出了一个我非常认可的回答:
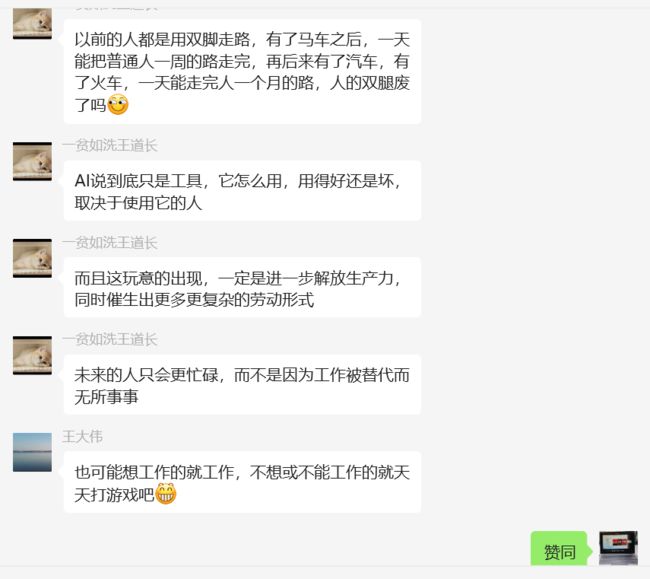
我很赞成道长的观点,大模型不可能完全代替人,好像有了汽车,还需要走路一样。但是我也相信,有了大模型后,一些简单的工作会被取代,就好像有了汽车后,骆驼祥子那样的人力车夫几乎不见了。
大模型代表人工智能技术进入了一个新的阶段,对于IT同行们来说,是一个难得的机遇。如何能在这一波浪潮中寻找到机会呢?首先当然应该对它有很深的理解和认识。建议也像我一样,在本地安装一套,随时唤起,正面与其聊天感受其行为,背后上调试器,观察其内部机理。
(写文章很辛苦,恳请各位读者点击“在看”,也欢迎转发)
*************************************************
正心诚意,格物致知,以人文情怀审视软件,以软件技术改变人生
扫描下方二维码或者在微信中搜索“盛格塾”小程序,可以阅读更多文章和有声读物

也欢迎关注格友公众号
